






1、网上搜索下载Jacob
下载网址:JACOB - Java COM Bridge - Browse Files at SourceForge.net
2、解压文件夹
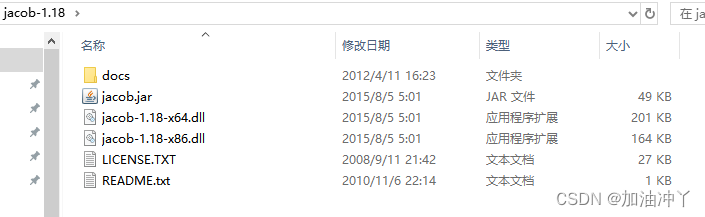
将图中的后缀为.dll文件复制到C盘下的Windows下
3、由于直接放置maven并不会好使,所以需要我们手动导入
将文件中的jar包导入到项目中
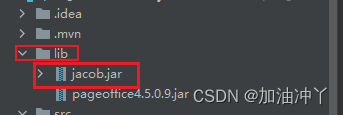
4、添加依赖并刷新
<!--添加本地的jacob.jar包-->
<dependency>
<groupId>com.jacob</groupId>
<artifactId>jacob</artifactId>
<version>1.18</version>
<scope>system</scope>
<systemPath>${basedir}/lib/jacob.jar</systemPath>
</dependency>5、添加工具类,模板的制作和我上一篇导word一样
public class XmlTemplate2Word {
/**
* 将xml模板转换为后缀为doc文件,本质仍是属于xml
* @param dataMap 需要填充到模板的数据
* @param templateFilePath 模板文件路径
* @param targetFilePath 目标文件保存路径
* @throws IOException
* @throws TemplateException
*/
public static void xml2XmlDoc(Map<String,Object> dataMap, String templateFilePath, String targetFilePath){
// 将模板文件路径拆分为文件夹路径和文件名称
String tempLetDir = templateFilePath.substring(0,templateFilePath.lastIndexOf("/"));
// 注意:templetFilePath.lastIndexOf("/")中,有的文件分隔符为:\ 要注意文件路径的分隔符
String templetName = templateFilePath.substring(templateFilePath.lastIndexOf("/")+1);
// 将目标文件保存路径拆分为文件夹路径和文件名称
String targetDir = targetFilePath.substring(0,targetFilePath.lastIndexOf("/"));
String targetName = targetFilePath.substring(targetFilePath.lastIndexOf("/")+1);
Configuration configuration = new Configuration();
configuration.setDefaultEncoding("UTF-8");
// 如果目标文件目录不存在,则需要创建
File file = new File(targetDir);
if(!file.exists()){
file.mkdirs();
}
try {
// 加载模板数据(从文件路径中获取文件,其他方式,可百度查找)
configuration.setDirectoryForTemplateLoading(new File(tempLetDir));
// 获取模板实例
Template template = configuration.getTemplate(templetName);
File outFile = new File(targetDir + File.separator + targetName);
//将模板和数据模型合并生成文件
Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"UTF-8"));
//生成文件
template.process(dataMap, out);
out.flush();
out.close();
}catch (TemplateException e){
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* xml形式的doc文件转换为Docx格式
* @param sourcePath 被转换文件的路径
* @param targetPath 目标文件路径
* @return
*/
public static void docToDocx(String sourcePath, String targetPath){
//Word.Application代表COM OLE编程标识,可查询MSDN得到
ActiveXComponent app = new ActiveXComponent("Word.Application");
//设置Word不可见
app.setProperty("Visible",false);
//调用Application对象的Documents属性,获得Documents对象
Dispatch docs = app.getProperty("Documents").toDispatch();
//Dispatch doc = Dispatch.call(docs,"Open",sourcePath,new Variant(false),new Variant(true)).getDispatch();
Dispatch doc = Dispatch.call(docs,"Open",sourcePath).getDispatch();
Dispatch.call(doc,"SaveAS",targetPath,12);
//关闭打开的Word文件
Dispatch.call(doc,"Close",false);
//关闭Word应用程序
app.invoke("Quit",0);
}
/**
* @Description: word文件转pdf文件
* @param sourcePath 被转换word文档路径
* @param targetPath 目标PDF文件路径路径
*/
public static boolean word2pdf(String sourcePath, String targetPath) {
ActiveXComponent app = null;
try {
app = new ActiveXComponent("Word.Application");
app.setProperty("Visible", false);
Dispatch docs = app.getProperty("Documents").toDispatch();
Dispatch doc = Dispatch.call(docs, "Open", sourcePath, false, true).toDispatch();
File tofile = new File(targetPath);
if (tofile.exists()) {
tofile.delete();
}
Dispatch.call(doc, "SaveAs", targetPath, 17); // word转PDF格式
Dispatch.call(doc, "Close", false);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
} finally {
if (app != null) {
app.invoke("Quit", 0); // 不保存待定的更改
}
}
}
}6、查询出数据源,添加模板位置,以及导出位置就成功啦














 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









