







 本文探讨了正交矩阵在数据分析中的应用,如Procrustes问题、因子分析中的正交旋转、不平衡正交Procrustes问题,以及它们在最小二乘法、正交回归和机器学习特征选择中的作用。文中介绍了相关优化算法和问题的求解策略。
本文探讨了正交矩阵在数据分析中的应用,如Procrustes问题、因子分析中的正交旋转、不平衡正交Procrustes问题,以及它们在最小二乘法、正交回归和机器学习特征选择中的作用。文中介绍了相关优化算法和问题的求解策略。
在看这篇论文前先了解一点基础知识。
我们记得希腊英雄忒修斯在漫游中遇到过一个叫普罗克鲁提斯的人物,他的床铺适合所有旅行者。对那些太矮的人,他残忍地把他们伸直,对那些太高的人,他把他们砍成合适的尺寸。如果一个研究者满足于——像许多人一样——通过视觉判断宣布契合度很好,那么这个程序就会让自己成为一项残酷的壮举,使几乎任何数据都符合几乎任何假设!由于这种可能的倾向,我们给这个程序命名为Procrustes,因为这个参考描述了它的功能,无论是好是坏。Procrustes的另一个有用的作用是,一旦获得质心矩阵,就会将质心矩阵移动到一个近似正确的位置,在这个位置上,主要结构早已已知(基于一系列初始盲旋转)。具体来说,正交矩阵是一种特殊的矩阵,其特点是它的转置等于它的逆矩阵。在数学和物理学中,正交矩阵通常用于表示空间中的旋转操作。
在因子分析中,因子矩阵是由原始数据经过因子分析得到的。而假设矩阵则可能代表了某种特定的结构或模式。通过正交旋转因子矩阵,可以使旋转后的因子矩阵与假设矩阵最为接近,这通常意味着旋转后的因子矩阵更好地反映了原始数据的潜在结构或模式。因此,这句话的意思是,通过正交旋转操作,使因子矩阵更接近于某些特定的假设矩阵,从而更好地解释和理解原始数据。
正交 Procrustes 问题(OPP)是一个优化问题,它涉及到寻找一个正交矩阵,使得该矩阵与给定的矩阵之间的某种度量(如 Frobenius 范数)达到最小。在 Procrustes 问题中,给定两个矩阵 A 和 B,目标是找到一个正交矩阵 Q,使得 Q^T A Q 和 B 之间的某种度量(如 Frobenius 范数)达到最小。这个问题的应用领域包括统计、机器学习和生物信息学等。
正交 Procrustes 问题可以看作是 Procrustes 问题的特殊情况,其中 A 是正交矩阵。在这种情况下,问题变得更加简单,因为正交矩阵的转置等于其逆矩阵。解决正交 Procrustes 问题的方法通常包括迭代优化算法,如梯度下降法或共轭梯度法等。这些算法通过不断更新 Q 来逐步逼近最优解。需要注意的是,正交 Procrustes 问题可能存在多个最优解,因此找到的解可能不是唯一的。此外,对于大规模数据集,解决正交 Procrustes 问题可能需要较长的计算时间和较大的计算资源。
不平衡正交 Procrustes 问题是一个特殊的优化问题,它涉及到寻找一个正交矩阵,使得该矩阵与给定的矩阵之间的某种度量(如 Frobenius 范数)达到最小,同时考虑矩阵的不平衡性。
不平衡 Procrustes 问题是在 Procrustes 问题的基础上引入了不平衡性约束。具体来说,给定两个矩阵 A 和 B,其中 A 是一个不平衡矩阵(即其行或列的和或平均值不等于零),目标是在保持 Q 的正交性的前提下,最小化 Q^T A Q 和 B 之间的某种度量(如 Frobenius 范数)。
解决不平衡正交 Procrustes 问题的方法通常包括迭代优化算法,如梯度下降法或共轭梯度法等。这些算法通过不断更新 Q 来逐步逼近最优解。
需要注意的是,不平衡正交 Procrustes 问题可能存在多个最优解,因此找到的解可能不是唯一的。此外,对于大规模数据集,解决不平衡正交 Procrustes 问题可能需要较长的计算时间和较大的计算资源。
最小二乘法是一种数学优化技术,它通过最小化误差的平方和寻找数据的最佳函数匹配。这种方法可以用于曲线拟合和数据分析等领域。
正交回归(也称为 Deming 回归)是一种统计方法,用于确定两台仪器或两种方法是否提供可比较的测量值,或者确定两个连续变量之间的线性关系。与简单线性回归(最小二乘回归)不同,正交回归中的响应和预测变量都包含测量误差。在正交回归中,目标是最小化从数据点到拟合线的正交(垂直)距离。正交回归解决了在两个变量都包含测量误差时使用简单回归来确定可比性可能会出现的问题,因此变量的作用对结果几乎没有影响。
正交回归需要满足一些假设条件,包括预测变量和响应分别包含一个固定未知数量以及一个误差分量,误差项为独立的项,误差项的均值为零且包含恒定方差,以及预测变量和响应呈线性相关。正交回归方程为:Y=a+bX,其中a和b是回归系数,可以通过最小二乘法求得。在正交回归中,最佳拟合线是使加权距离最小的线,其中加权距离是数据点到拟合线之间的垂直距离。
Stiefel流形上的二次问题是几何优化领域的一个重要问题,它涉及到在Stiefel流形上寻找一个二次代价函数的最小值。Stiefel流形是一个高维的几何对象,它由满足某种约束条件的矩阵构成。二次代价函数的形式通常为f(X)=X^TAX+2b^TX+c,其中X是Stiefel流形上的一个矩阵,A、b和c是给定的常数矩阵和向量。该代价函数可以看作是矩阵X上的二次函数,因此称为二次代价函数。
假设我们有一个数据集,其中包含多个特征向量。每个特征向量都可以看作是数据点在特征空间中的一个位置。在机器学习中,我们通常会使用一些算法来对数据进行分类或回归等任务。在这些算法中,特征向量的重要性通常会通过一些指标来衡量,例如特征向量的权重、方差等。优势特征向量方向就是指在所有特征向量中,某个特征向量所代表的属性相对于其他属性而言具有更大的优势。这个优势可以是权重更大、方差更大等。在机器学习中,我们通常会选择具有较大优势的特征向量作为模型的输入,以获得更好的分类或回归效果。
紧凑QR分解是一种将矩阵分解为正交矩阵和上三角矩阵的方法。对于一个m×n的矩阵A,QR分解将其分解为一个m×m的正交矩阵Q和一个m×n的上三角矩阵R,使得A = QR。这种分解方法常用于数值计算,特别是求解线性方程组和求特征值。
奇异值分解是一种数据分析方法,它将一个矩阵分解为三个实矩阵的乘积形式,即U、V和D的乘积。其中U和V是正交矩阵,D是一个对角矩阵,对角线上的元素即为奇异值。
紧化SVD是指在进行SVD分解时,对奇异值矩阵Σ进行截断,只保留前k个最大的奇异值及其对应的左右奇异向量,而忽略其他小的奇异值。这样做的目的是为了降低计算的复杂度,同时保留矩阵的主要特征,使得在保留主要信息的同时减小矩阵的维度。在机器学习和数据降维等领域中,紧化SVD是一种常用的技术。
广义幂迭代方法(GPI)以随机初始猜测和简洁的计算步骤有效地求解正交最小二乘回归(OLSR)和UOPP。
1.幂次迭代法
幂次迭代法是一种求任意给定对称矩阵A∈Rm*m![]() 的主特征值及其相关特征向量的迭代算法,其中主特征值定义为在幅度上最大的特征值。幂次迭代可按以下步骤进行:
的主特征值及其相关特征向量的迭代算法,其中主特征值定义为在幅度上最大的特征值。幂次迭代可按以下步骤进行:
- 初始化。随机初始化一个向量ω
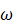 ∈Rm*1
∈Rm*1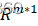 ,其在优势特征向量方向上有一个非零分量。
,其在优势特征向量方向上有一个非零分量。 - 更新m←Aω
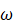
- 计算q = mm2
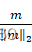 ;
; - 更新ω
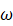 ←q.
←q. - 迭代执行步骤(2)-(4),直到收敛。
算法最主要是找出ω。![]() 其中m 是一个中间向量,用于存储 Aω
其中m 是一个中间向量,用于存储 Aω![]() 的结果。在步骤 (2) 中,m 被更新为 Aω
的结果。在步骤 (2) 中,m 被更新为 Aω![]() ,即矩阵 A 和向量ω
,即矩阵 A 和向量ω![]() 的乘积。q 是另一个中间向量,用于存储 m 的值。
的乘积。q 是另一个中间向量,用于存储 m 的值。
幂次迭代可以进一步扩展为正交迭代(也称为子空间迭代或同时迭代,正交迭代法是一种用于求解特征值和特征向量的迭代方法。在正交迭代法中,我们通常会得到一个矩阵W,它是特征向量的矩阵。)方法,以找到给定矩阵A的前k (k ≤![]() m)个优势特征值及其相关特征向量。正交迭代方法可以描述为以下迭代算法:
m)个优势特征值及其相关特征向量。正交迭代方法可以描述为以下迭代算法:
- 初始化。随机初始化W∈Rm*k
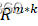 。
。 - 更新M←AW。
- 通过M的紧QR分解计算QR = M,其中Q∈Rm*k
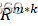 , R∈Rk*k
, R∈Rk*k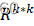 。
。 - 更新W←Q。
- 迭代执行步骤(2)-(4),直到收敛。
这个算法的目的可能是找到一个合适的矩阵W,使得经过多次迭代后,它能够近似于一个特定的矩阵(可能是与问题有关的特征向量矩阵)
显然,上述正交迭代法是一个归一化过程(归一化过程是对数据进行处理,将其缩放到指定的范围,例如[0,1]或[-1,1],以消除数据尺度的影响,使得不同特征之间具有可比性。),与幂次迭代法中的归一化过程类似。当矩阵A为正半定(psd) 时,正交迭代法等价于求解以下优化问题:
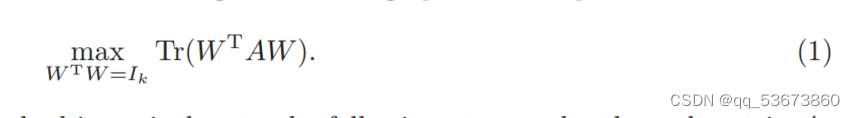 (正交迭代法的归一化过程通常涉及到正交变换,使得变换后的向量满足某种正交条件。
(正交迭代法的归一化过程通常涉及到正交变换,使得变换后的向量满足某种正交条件。
幂次迭代法的归一化过程则涉及到对向量进行幂运算,使其长度逐渐收敛到1。)
因此,在psd矩阵A下,正交迭代法等价于以下步骤:
- 初始化。随机初始化W∈Rm*k
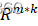 。
。 - 更新M←AW。
- 通过M的紧凑SVD方法计算USVT=M
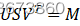 ,其中U∈Rm*k
,其中U∈Rm*k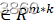 ,S∈Rk*k
,S∈Rk*k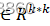 和V∈Rk*k
和V∈Rk*k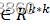 。
。 - 更新W←UVT
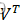 。
。 - 迭代执行步骤(2)-(4),直到收敛。
从观察中可以看出,上述算法的解WK与正交迭代法的解W在形式上不同,其中KKT![]() =Ik
=Ik![]() 。
。
2. Stiefel流形上的二次问题
Stiefel流形vm,k![]() 是矩阵W∈Rm*k
是矩阵W∈Rm*k![]() 的集合,其标准正交列为vm,k
的集合,其标准正交列为vm,k![]() = {W∈Rm*k
= {W∈Rm*k![]() : WTW
: WTW![]() = Ik
= Ik![]() }。
}。
在本节中,我们推导了一种新的方法来解开以下QPSM

式中W∈Rm*k![]() , B∈Rm*k
, B∈Rm*k![]() ,对称矩阵A∈Rm*m
,对称矩阵A∈Rm*m![]() 。为了解决问题(2),可以将(2)中的QPSM进一步放宽为
。为了解决问题(2),可以将(2)中的QPSM进一步放宽为
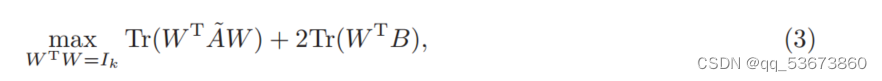
式中A![]() = αIm
= αIm![]() −A∈Rm*m
−A∈Rm*m![]() 。松弛参数α是一个任意常数,使得A
。松弛参数α是一个任意常数,使得A![]() 是一个正定矩阵。更具体地说,松弛参数α可以很容易地设置为A的主导特征值,并且可以通过前一节讨论的幂方法快速获得。代替拉格朗日乘子的方法来处理正交约束的优化问题,可以使用为Stiefel流形量身定制的几何优化算法。
是一个正定矩阵。更具体地说,松弛参数α可以很容易地设置为A的主导特征值,并且可以通过前一节讨论的幂方法快速获得。代替拉格朗日乘子的方法来处理正交约束的优化问题,可以使用为Stiefel流形量身定制的几何优化算法。
因此,问题(3)的拉格朗日函数可表示为
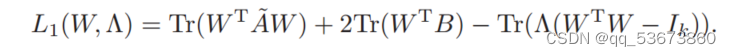
由式(4)可知,问题(3)的KKT条件为

这很难直接解决。因此,根据[15]和第2节提到的幂次迭代方法,我们可以提出如下迭代算法:
(1)初始化。随机初始化W∈Rm*k![]() 使WTW
使WTW![]() = Ik
= Ik![]() 。
。
(2)更新M∈Rm*k![]() ←2 A
←2 A![]() W + 2B。
W + 2B。
(3)通过求解以下问题计算W*![]() :
:

(4)更新W←W*![]() 。
。
(5)迭代执行步骤(2)-(4),直到收敛。
此外,通过以下推导可以得到问题(6)的封闭形式解。
完整的关于M的SVD是M = UΣVT![]() 和U∈Rm*m
和U∈Rm*m![]() ,Σ∈Rm*k ,V
,Σ∈Rm*k ,V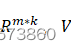 ∈Rk*k
∈Rk*k![]() ,然后我们有
,然后我们有
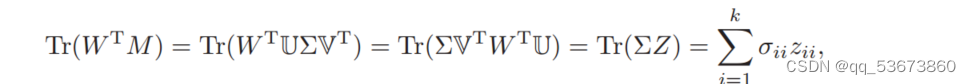
式中Z = VTWTU![]() ∈Rk*m
∈Rk*m![]() ,其中zii
,其中zii![]() 和σii
和σii![]() 分别为矩阵Z和Σ的(i, i)个元素。
分别为矩阵Z和Σ的(i, i)个元素。
注意ZZT![]() =Ik
=Ik![]() ,因此zii≤1
,因此zii≤1![]() 。另一方面,σii≥
。另一方面,σii≥![]() 0,因为σii
0,因为σii![]() 是矩阵m的奇异值,因此
是矩阵m的奇异值,因此
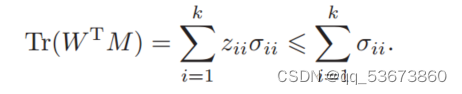
显然,当 zii![]() = 1, (i≤i≤k
= 1, (i≤i≤k![]() )时等式成立,也就是说,当矩阵Z = [Ik
)时等式成立,也就是说,当矩阵Z = [Ik![]() , 0]∈Rk*m
, 0]∈Rk*m![]() 时,Tr(WT
时,Tr(WT![]() M)达到最大值。回想一下,Z = VTWTU
M)达到最大值。回想一下,Z = VTWTU![]() ,因此问题(6)的最优解可以表示为
,因此问题(6)的最优解可以表示为

由于Eq.(7)是基于矩阵M的完整SVD,因此Eq.(7)可以通过矩阵M的紧化SVD重写为W = UVT![]() ,其中M = USVT
,其中M = USVT![]() , U∈Rk*m
, U∈Rk*m![]() S∈Rk*k
S∈Rk*k![]() , V∈Rk*k
, V∈Rk*k![]()
引理1。若对称矩阵A![]() ∈Rm*m
∈Rm*m![]() 是正定的(pd),则
是正定的(pd),则
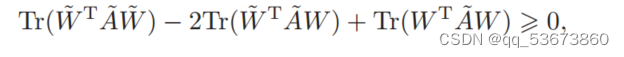
其中,w![]() ∈Rm*k
∈Rm*k![]() 和W∈Rm*k
和W∈Rm*k![]() 是任意矩阵。
是任意矩阵。
证明。由于矩阵A![]() 是正定的(pd),我们可以通过Cholesky分解重写为A
是正定的(pd),我们可以通过Cholesky分解重写为A![]() = LT
= LT![]() L。
L。
因此,我们对引理1有如下证明
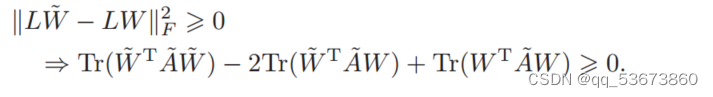
定理1。算法1在每次迭代中单调减小(2)中的目标函数的值,直到收敛。
证明。假设算法1中更新后的W为w![]() ,则有
,则有
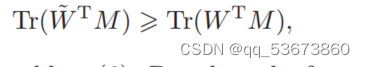
因为w![]() 是问题(6)的最优解。基于M = 2 A
是问题(6)的最优解。基于M = 2 A![]() W + 2B的事实,Eq.(8)可以进一步表示为
W + 2B的事实,Eq.(8)可以进一步表示为
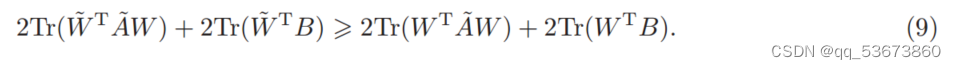
根据引理1和Eq.(9),我们可以推断
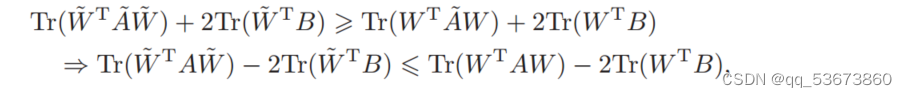
表明算法1在每次迭代中减小(2)中QPSM的目标值,直到算法收敛。
定理2。算法1收敛于QPSM问题(2)的一个局部极小值。
证明。由于算法1每次迭代都是以求解问题(6)为基础执行的,因此算法1求解的拉格朗日函数可以表示为
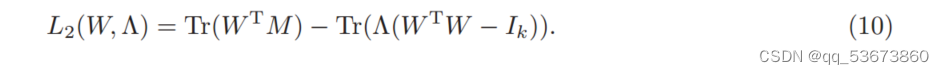
因此,算法1的解满足以下KKT条件:
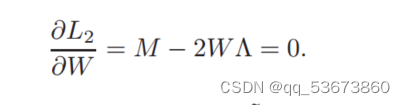
一般来说,在算法1下,矩阵M在每次迭代中都会被w![]() 更新。由于算法1收敛于最优解W,即由定理1可知w
更新。由于算法1收敛于最优解W,即由定理1可知w![]() = W,因此Eq.(11)可以进一步表示为M = 2A
= W,因此Eq.(11)可以进一步表示为M = 2A![]() W + 2B为
W + 2B为
通过(5)与(12)的比较,我们可以得出结论,算法1的解与问题(3)的解满足相同的KKT条件。
因此,算法1收敛于QPSM(2)的一个局部极小值,因为问题(2)和(3)是等价的。
3. Stiefel流形上二次问题的两个特例
3.1正交最小二乘回归
正交最小二乘回归(OLSR)可以写成

根据b的极值条件,我们可以得到
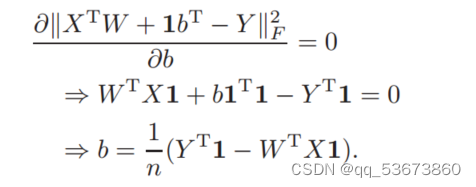
将上述结果代入b = 1n![]() (YT
(YT![]() 1−WT
1−WT![]() X1),可将式(13)简化为
X1),可将式(13)简化为

式中H =In![]() −1n
−1n ![]() 11T
11T![]() 。
。
因此,问题(14)可以进一步重新表述为

当A=XHXTB=XHY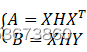 显然,Eq.(15)与(2)中的QPSM形式完全相同,因此,(13)中的OLSR可以通过算法1求解。
显然,Eq.(15)与(2)中的QPSM形式完全相同,因此,(13)中的OLSR可以通过算法1求解。
3.2不平衡正交直线问题
定义1。取Q∈Rm*k![]() , E∈Rn*m
, E∈Rn*m![]() , G∈Rn*k
, G∈Rn*k![]() 为优化问题命名
为优化问题命名

(1)平衡OPP当且仅当m = k;
(2)不平衡正交procrustes问题(UOPP)当且仅当m > k,特别是当Q作为列向量(k = 1)时,问题(16)退化为

这就是LSQE的最小二乘问题。
3.2.1重新讨论平衡正交直线问题
为了求解平衡的OPP (m = k),我们可以将Eq.(16)展开为
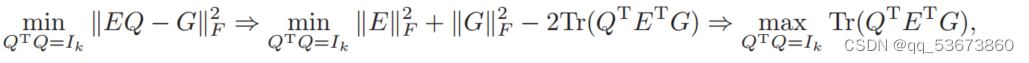
与处理ET![]() G = M的问题(6)相同
G = M的问题(6)相同
因此,平衡OPP具有封闭形式(7)的解析解。
3.2.2不平衡正交问题
当m > k时,UOPP(16)可展开为
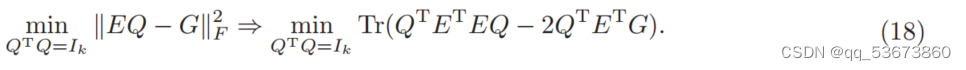
令ET![]() E = A, ET
E = A, ET![]() G = B,则Eq.(18)与QPSM(2)的形式完全相同。
G = B,则Eq.(18)与QPSM(2)的形式完全相同。
一般来说,QPSM不能改写为UOPP,而UOPP却可以改写为QPSM。因此,GPI方法比其他方法更通用,只能处理UOPP。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









