







- HDFS :负责储存数据
- 文件进行拆分 文件块
- 存储 拆分 文件块
补充: hdfs主要存储文件 大文件 不是说 不能存储小文件
存储小文件 影响hdfs 性能
- block 块:
- 文件拆分来的 : 按照块大小 进行拆分
- 属性
- 块大小 128M blocksize
- 块的副本数
- 伪分布式 1
- 完全分布式 3
本地文件大小:260M
块大小 :128M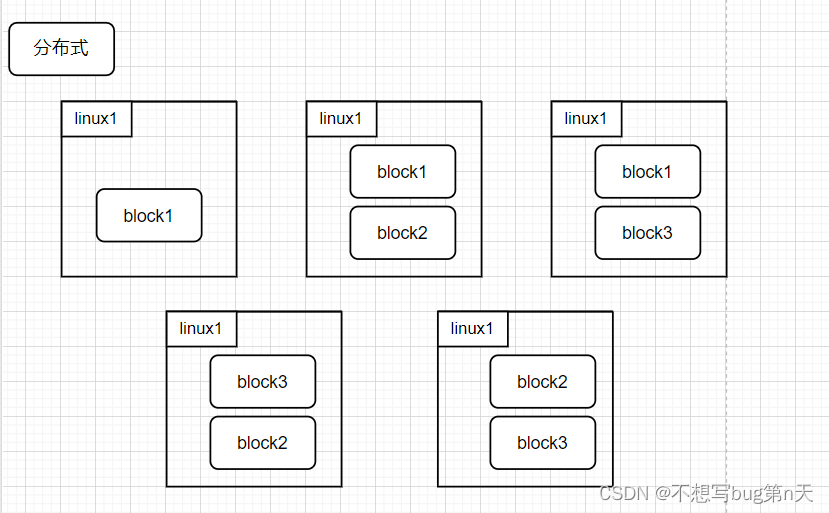
- 例
- 1. 一缸水 260L
一个瓶子 128L
第一个瓶子 128L
第二个瓶子 128L
第三个瓶子 4L - 2. 160M 2个副本 问:
①文件拆分了块正在hdfs上存了多少块
160M: 128M
32M
1+1= 2块 * 2 = 4块
②实际存储到hdfs存储的大小是多少
160M * 2 = 320 M
- 1. 一缸水 260L
- 大数据处理
- 1.input
hdfs一些文件
fs,open - 2.处理
- 3.output
1. 打印到控制台
2. 输出到hdfs上
- 1.input
- HDFS架构设计
三个角色:namenode 名称节点 nn- 1.文件名称
- 2.文件的目录结构
- 3.文件的属性、权限、创建时间、副本数据
- 4.blockmap块映射
不会永久持久化这个储存
是通过集群启动和运行是 dn定期发送 blockreprot给nn来进行
动态的维护这种映射关系 mem
一个文件 被切分 多个数据块 副本数 =》 数据节点
数据块对应分布在哪些节点上进行储存 - 作用:管理文件系统的命名空间 其实就是维护文件系统树的文件和文件夹
是以两种文件- 镜像文件 fsimage
- 编辑日志文件 editlogs
- secondery namenode 第二名称节点 snn
fsimage + 编辑日志文件 定期拿来进行合并
- datanode 数据节点 dn
- 1.存储数据块和数据块的校验
作用:1.每隔3s发送一次心跳给nn
2.每隔一定时间发送blockreport
- 1.存储数据块和数据块的校验
-
hdfs架构设计
- 1.hdfs
主从架构
生产上两个NameNode - 2.NameNode
- 文件元数据
- 文件的名称、权限、副本
- 文件路径、文件的信息
- 对外提供服务
- 负责映射块文件
- 文件元数据
- 3.DataNode
- 每个节点都有这个进程
- 负责存储数据块
- 负责文件的读写
- 1.hdfs















05-06
12-03
 360
360
360
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









