







-
目录
-
1.基本信息
-
1.flume
- 数据采集 :把数据采集到服务器上
- 数据收集 :把数据移动到指定位置
-
2.官网:flume.apache.org
-
3.结构

- collecting 采集/收集 source
- aggregating 聚合 channel
- moving 移动 sink
-
4.核心概念
- agent :source channel sink
- source : 采集数据
- channel :存储采集过来的数据
- sink :把采集过来的数据
-
-
2.部署
-
1.解压
- [hadoop@bigdata13 software]$ tar -zxvf apache-flume-1.9.0-bin.tar.gz -C ~/app/
- 软连接 :[hadoop@bigdata13 app]$ ln -s apache-flume-1.9.0-bin/ flume
-
2.环境变量
- [hadoop@bigdata13 app]$ vim ~/.bashrc
#FLUME_HOME export FLUME_HOME=/home/hadoop/app/flume export PATH=${PATH}:${FLUME_HOME}/bin - [hadoop@bigdata13 app]$ source ~/.bashrc
- [hadoop@bigdata13 app]$ vim ~/.bashrc
-
3.配置flume
- 路径:/home/hadoop/app/flume/conf
[hadoop@bigdata13 conf]$ cp flume-env.sh.template flume-env.sh
[hadoop@bigdata13 conf]$ vim flume-env.shexport JAVA_HOME=/home/hadoop/app/java
- 路径:/home/hadoop/app/flume/conf
-
4.使用flume
配置agent配置文件-
source
- avro 序列化框架 ****
- exec 日志文件 **
- spooling dir 日志文件 ***
- taildir Source 日志文件 ****
- Kafka Source **
- NetCat TCP port采集数据 **
- Custom 用户自己开发 *
-
channel
- Memory ****
- File ****
- JDBC *
- Kafka *
- Custom 用户自己开发 *
-
sink
- HDFS Sink ****
- Hive Sink ****
- Logger SInk **
- Avro Sink ****
- HBaseSinks *
- Kafka Sink ***
- Custom Sink 用户自己开发
-
1.生产上flume的使用场景-
1.采集log文件 到 hdfs
-
2.采集log文件 到 hive
-
3.采集log文件 到 kafka
-
4.采集kafka数据到hdfs
-
5.采集kafka数据到hive
-
6.采集数据到下一个agent
-
-
2.source :
-
1.netcat 采集端口数据 =》 学习 测试即可
-
2.日志文件
-
3.kafka数据
-
4.agent里面的数据
-
-
3.1 采集日志文件
-
1.exec :linux 命令进行采集数据
tail -f
tail -F 1.log ****
1.log => 1.log_tmp
1.log
-F = -f + retry -
2.spooldir
采集某个文件夹下面的文件 -
3.taildir
-
采集某个文件夹下面的文件
-
采集某个文件
-
断点续传
-
-
-
案例1 从指定端口中获取数据输出到控制台
-
通过flume从指定端口中 获取数据 输出到控制台?
agent:
source : NetCat TCP
channel : Memory
sink: Logger- 1.配置nc-mem-logger.conf文件
路径:/home/hadoop/project/flume
[hadoop@bigdata13 flume]$ vim nc-mem-logger.confa1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.channels.c1.type = memory a1.sinks.k1.type = logger a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 - 2.安装telnet
在root内:[root@bigdata13 ~]# yum install -y telnet - 3.启动flume
- 路径:/home/hadoop/app/flume/conf
flume-ng agent \ --name a1 \ --conf ${FLUME_HOME}/conf \ --conf-file /home/hadoop/project/flume/nc-mem-logger.conf \ -Dflume.root.logger=info,console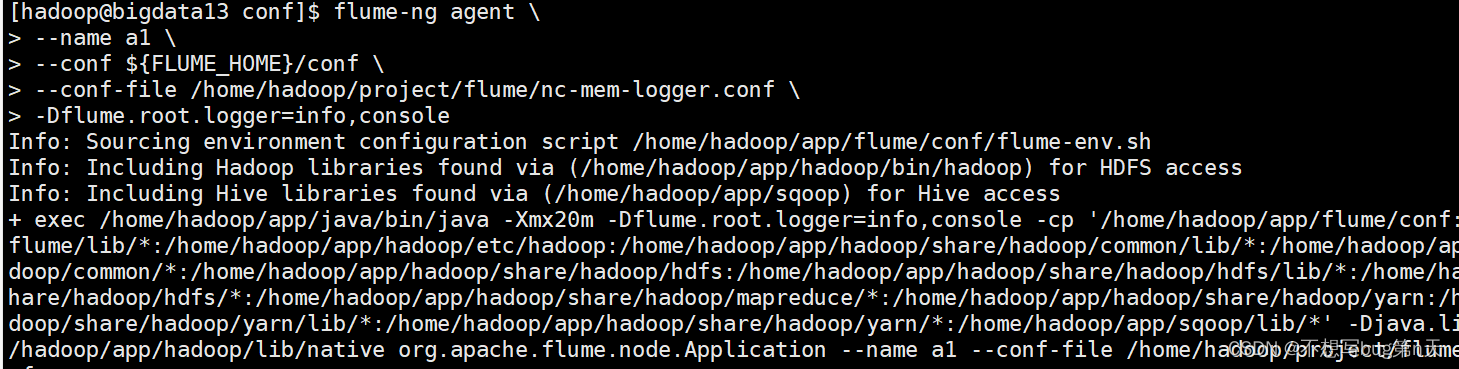
- 启动source: 发送数据
[hadoop@bigdata13 ~]$ telnet localhost 44444

- 路径:/home/hadoop/app/flume/conf
- 1.配置nc-mem-logger.conf文件
-
案例2 采集日志数据到控制台打印
-
采集日志数据到控制台打印 agent: source :exec channel : mem sink:logger
- 1.创建一个1.log文件
路径: /home/hadoop
[hadoop@bigdata13 ~]$ vim 1.log

- 2.配置nc-mem-logger.conf文件
路径:/home/hadoop/project/flume
[hadoop@bigdata13 flume]$ vim exec-mem-logger.confa1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /home/hadoop/1.log a1.channels.c1.type = memory a1.sinks.k1.type = logger a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 - 3.启动flume
路径:/home/hadoop/app/flume/confflume-ng agent \ --name a1 \ --conf ${FLUME_HOME}/conf \ --conf-file /home/hadoop/project/flume/exec-mem-logger.conf \ -Dflume.root.logger=info,console
- 1.创建一个1.log文件
-
案例3 采集指定文件夹的内容到控制台

-
需求: 采集指定文件夹的内容到控制台 ? source:spooldir channel : mem sink:logger
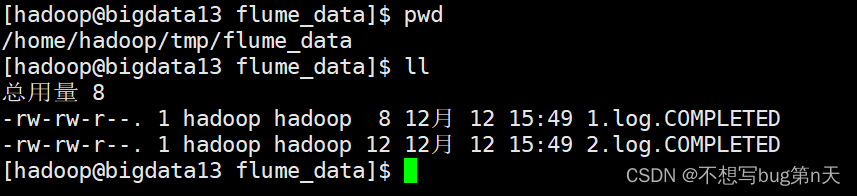
- 1.创建文件
路径:/home/hadoop/tmp/flume_data[hadoop@bigdata13 flume_data]$ echo "123" >> 1.log [hadoop@bigdata13 flume_data]$ echo "234" >> 1.log [hadoop@bigdata13 flume_data]$ ll 总用量 4 -rw-rw-r--. 1 hadoop hadoop 8 12月 12 15:49 1.log [hadoop@bigdata13 flume_data]$ vim 2.log [hadoop@bigdata13 flume_data]$ ll 总用量 8 -rw-rw-r--. 1 hadoop hadoop 8 12月 12 15:49 1.log -rw-rw-r--. 1 hadoop hadoop 12 12月 12 15:49 2.log [hadoop@bigdata13 flume_data]$ cat 2.log 22222 33333 - 2.agent
配置spool-mem-logger.conf文件
路径:/home/hadoop/project/flume
[hadoop@bigdata13 flume]$ vim spool-mem-logger.confa1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /home/hadoop/tmp/flume_data/ a1.channels.c1.type = memory a1.sinks.k1.type = logger a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 - 3.启动flume
路径:/home/hadoop/app/flume/confflume-ng agent \ --name a1 \ --conf ${FLUME_HOME}/conf \ --conf-file /home/hadoop/project/flume/spool-mem-logger.conf \ -Dflume.root.logger=info,console
-
追加文件
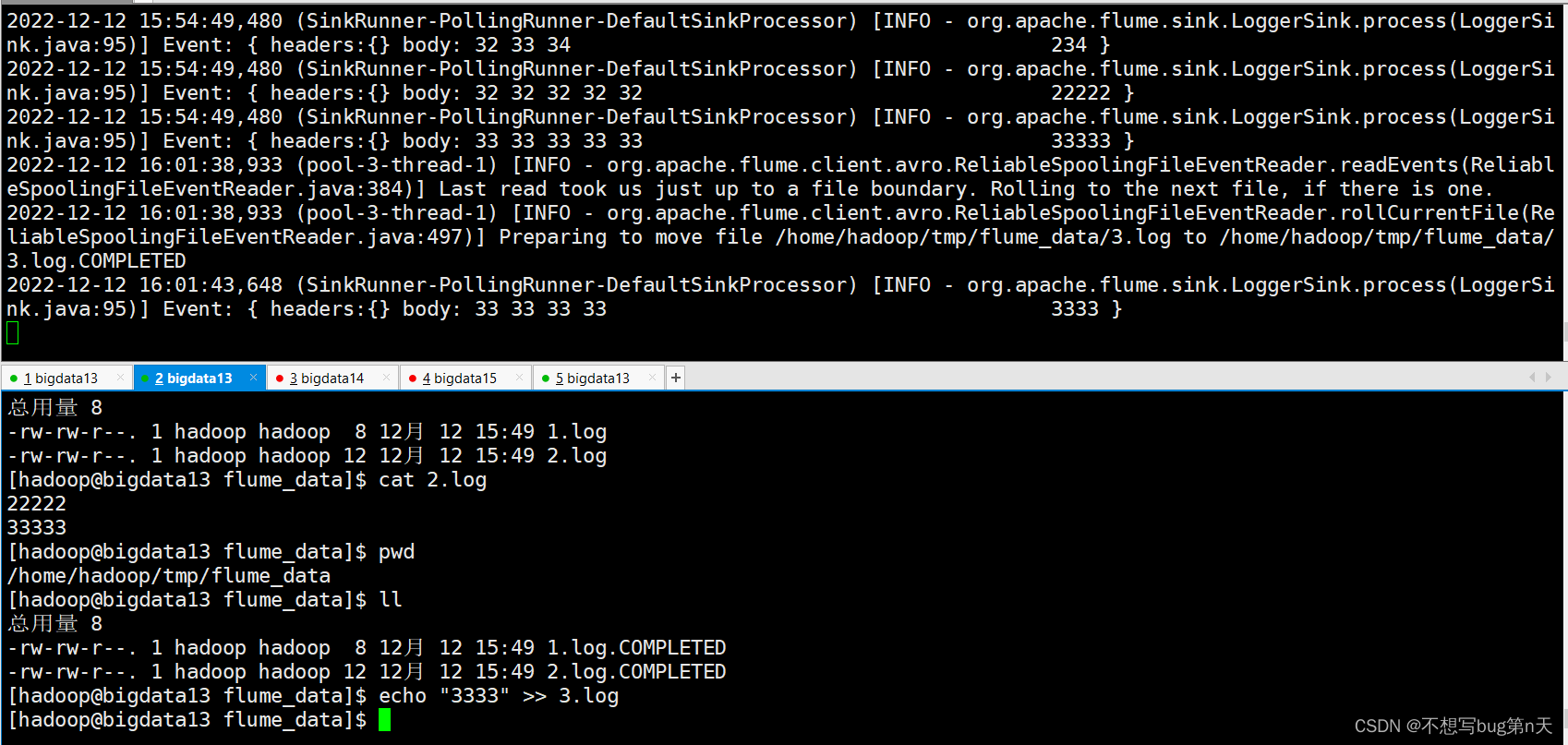
1.a1.sources.r1.spoolDir 目录下日志文件 已经采集完成 ,
那么 后续目录下 监控的这个文件内容发生更新 不会继续采集日志
flume 挂掉
spool 采集某个目录下,文件名 不运行重复
生产上 不能用。
-
案例4 采集指定文件以及文件夹的内容 到控制台
-
需求:采集指定文件以及文件夹的内容 到控制台 souce:tairdir channel : mem sink:logger mt.txt flume_data: 1.log 2.log 3.log
- 1.agent
配置taildir-mem-logger.conf文件
路径:/home/hadoop/project/flume
[hadoop@bigdata13 flume]$ vimtaildir-mem-logger.confa1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 f2 a1.sources.r1.filegroups.f1=/home/hadoop/tmp/mt.txt a1.sources.r1.filegroups.f2=/home/hadoop/tmp/flume_data/.*.log a1.channels.c1.type = memory a1.sinks.k1.type = logger a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 - 2.启动flume
路径:/home/hadoop/app/flume/confflume-ng agent \ --name a1 \ --conf ${FLUME_HOME}/conf \ --conf-file /home/hadoop/project/flume/taildir-mem-logger.conf \ -Dflume.root.logger=info,console
-
-
案例5 采集日志文件 输出hdfs
- 需求:
采集日志文件 输出hdfs ?
agent:
source :exec taildir
channel:mem
sink:hdfs - 1.agent
配置 taildir-mem-hdfs.conf文件
路径:/home/hadoop/project/flume
[hadoop@bigdata13 flume]$ vim taildir-mem-hdfs.confa1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1=/home/hadoop/tmp/1.log a1.channels.c1.type = memory a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path=hdfs://bigdata13:9000/flume/log/ a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 - 2.启动flume
路径:/home/hadoop/app/flume/confflume-ng agent \ --name a1 \ --conf ${FLUME_HOME}/conf \ --conf-file /home/hadoop/project/flume/taildir-mem-hdfs.conf \ -Dflume.root.logger=info,console
- 3.进入HDFD
https://bigdata13:9870
 无法查看内容(hdfs=》文件存储格式 不是text)
无法查看内容(hdfs=》文件存储格式 不是text)
-
1.内容查看问题
- text:
- 1.hdfs.fileType =》 DataStream
- 2.hdfs.writeFormat =》 Text
- 1.加入内容
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Texta1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1=/home/hadoop/tmp/1.log a1.channels.c1.type = memory a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path=hdfs://bigdata13:9000/flume/log/ a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=Text a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
2. 重新启动flume
-
3. 向1.log中插入数据
-
4. 刷新HDFS
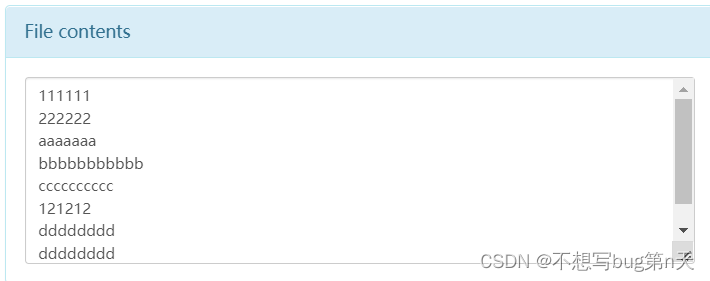
- text:
-
2.小文件问题
-
1.向1.log中插入1..100
for x in {1..100} do echo "dl2262,${x}" >> /home/hadoop/tmp/1.log sleep 0.1s done -
2.查看语句 [hadoop@bigdata13 tmp]$ tail -200f 1.log
-
3.hdfs


每个里十条
-
linux中一个文件 上传到hdfs后10个文件
出现小文件问题
-
-
4.小文件问题如何解决

-
1.文件滚动 hdfs.batchSize 【基本不用】
-
2.两大类
-
1.按照条数 文件发生滚动
hdfs.rollSize : 按照条数 -
2.按照时间 文件发送滚动
hdfs.roundUnit :时间滚动单元 second, minute or hour
hdfs.roundValue : 时间滚动具体值-
hdfs.round : 是否开启文件滚动 【必选】
-
-
3.hdfs.rollInterval : 按照时间进行文件滚动
hdfs.rollSize : 按照hdfs文件大小进行滚动
hdfs.rollCount : 按照hdfs文件 数据条数进行滚动
三个条件哪个先满足先执行哪个 -
删除HDFS中的目录 : [hadoop@bigdata13 tmp]$ hadoop fs -rm -r /flume/log/*
-
-
3.agent
[hadoop@bigdata13 flume]$ vim taildir-mem-hdfs-round.confa1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1=/home/hadoop/tmp/1.log a1.channels.c1.type = memory a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path=hdfs://bigdata13:9000/flume/log/ a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=Text #小文件滚动 a1.sinks.k1.hdfs.rollInterval=60 a1.sinks.k1.hdfs.rollSize=134217728 a1.sinks.k1.hdfs.rollCount=1000 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1- a1.sinks.k1.hdfs.rollInterval=60 时间到60s滚动
- a1.sinks.k1.hdfs.rollSize=134217728 内存到128M滚动
- a1.sinks.k1.hdfs.rollCount=1000 内容到1000条滚动
-
4.启动flume
flume-ng agent \ --name a1 \ --conf ${FLUME_HOME}/conf \ --conf-file /home/hadoop/project/flume/taildir-mem-hdfs-round.conf \ -Dflume.root.logger=info,console -
5.插入1000条数据
for x in {1..2000} do echo "dl2262,${x}" >> /home/hadoop/tmp/1.log sleep 0.1s done查看语句 [hadoop@bigdata13 tmp]$ tail -200f 1.log
-
6.查看HDFS
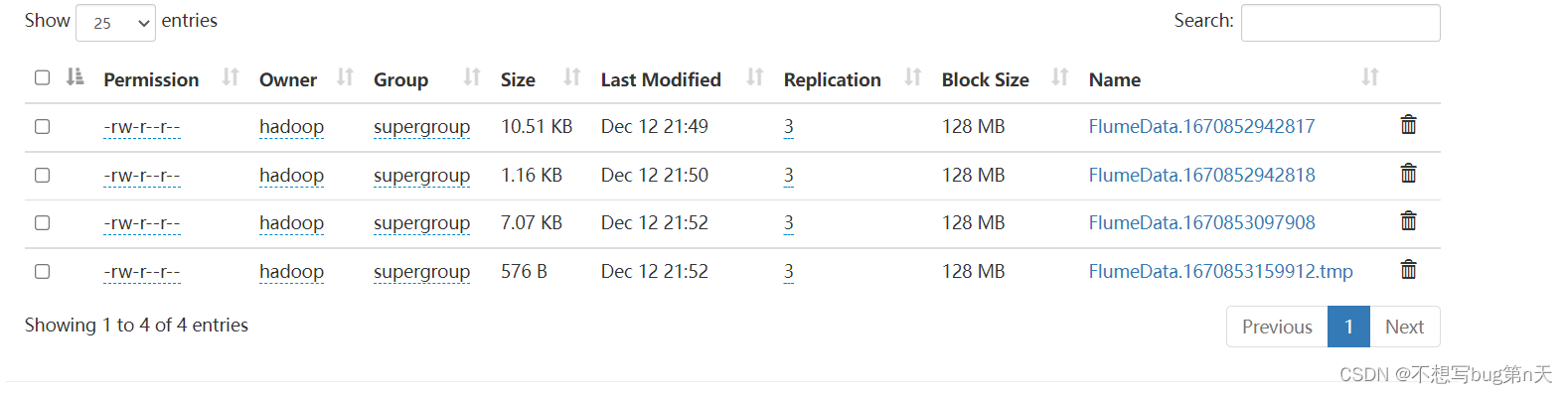
-
-
-














03-21
 1174
1174
1174
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









