






 本文围绕Python展开,介绍了递归函数,包括直接和间接调用及终止条件;阐述递归在计算员工薪水等场景的应用,分回溯和递推阶段。还讲解了二分法、冒泡排序等算法,以及三元表达式、列表生成式、字典和集合生成式的使用。
本文围绕Python展开,介绍了递归函数,包括直接和间接调用及终止条件;阐述递归在计算员工薪水等场景的应用,分回溯和递推阶段。还讲解了二分法、冒泡排序等算法,以及三元表达式、列表生成式、字典和集合生成式的使用。
目录
一、递归函数
函数不仅可以嵌套定义,还可以嵌套调用,即在调用一个函数的过程中,函数内部又调用另一个函数,而函数的递归调用指的是在调用一个函数的过程中又直接或间接地调用该函数本身。
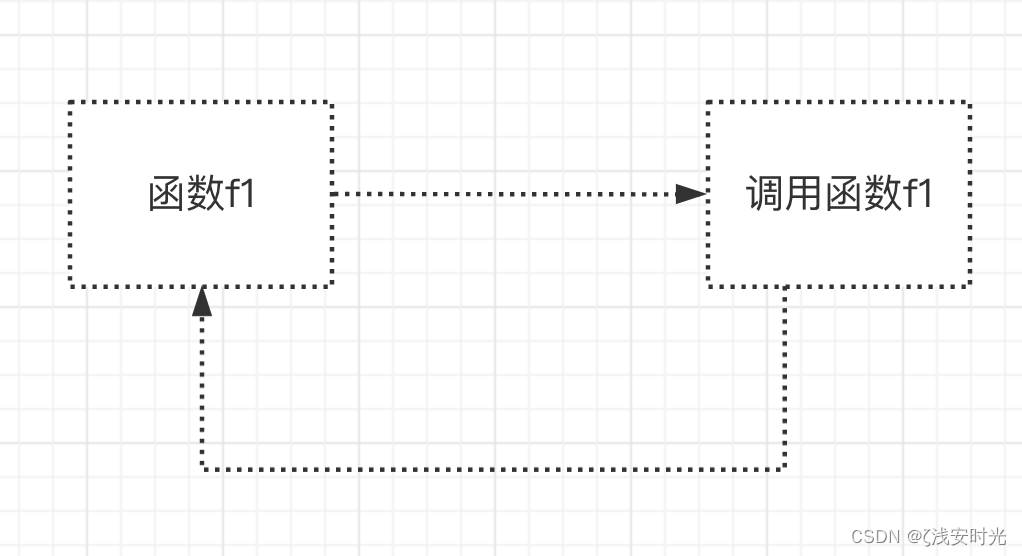
例如,在调用f1的过程中,又调用f1,这就是直接调用函数f1本身。
def f1():
print('from f1')
f1()
f1()配图:递归调用1
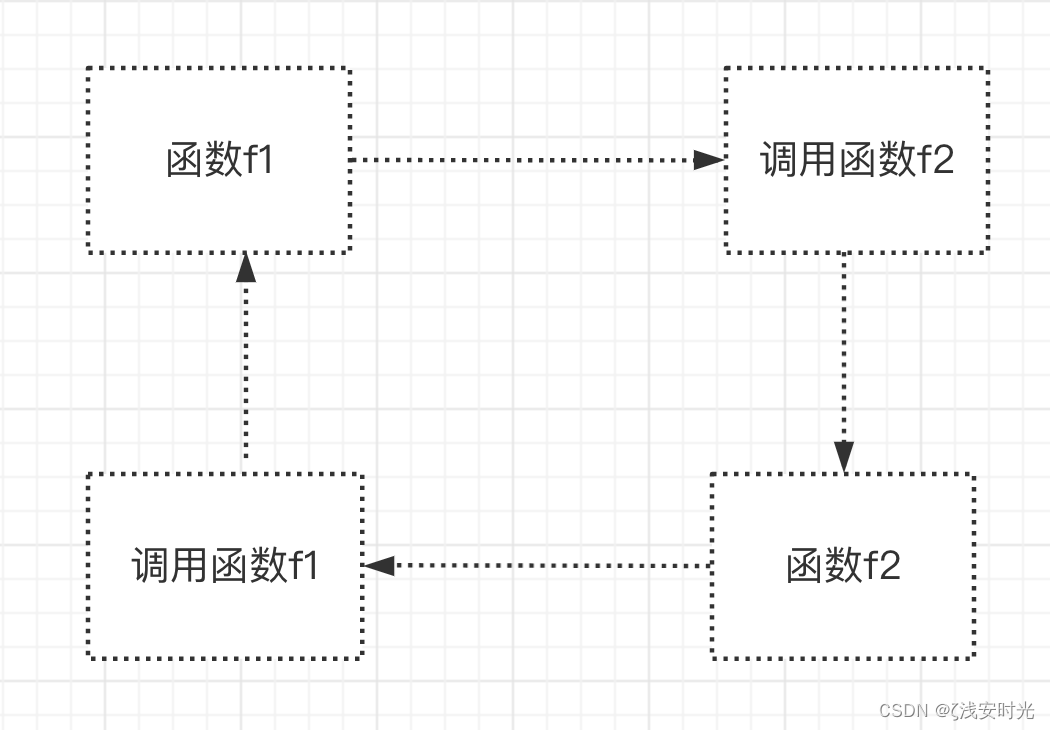
在调用f1的过程中,又调用f2,而在调用f2的过程中又调用f1,这就是间接调用函数f1本身。
def f1():
print('from f1')
f2()
def f2():
print('from f2')
f1()
f1()配图:递归调用2
从上图可以看出,两种情况下的递归调用都是一个无限循环的过程,但在python对函数的递归调用的深度做了限制,因而并不会像大家所想的那样进入无限循环,会抛出异常,要避免出现这种情况,就必须让递归调用在满足某个特定条件下终止。
#1. 可以使用sys.getrecursionlimit()去查看递归深度,默认值为1000,虽然可以使用
sys.setrecursionlimit()去设定该值,但仍受限于主机操作系统栈大小的限制
#2. python不是一门函数式编程语言,无法对递归进行尾递归优化。二、递归的使用场景
递归的原理和使用:
例:某公司四个员工坐在一起,问第四个人薪水,他说比第三个人多1000,问第三个人薪水,第他说比第二个人多1000,问第二个人薪水,他说比第一个人多1000,最后第一人说自己每月5000,请问第四个人的薪水是多少?
思路解析:
要知道第四个人的月薪,就必须知道第三个人的,第三个人的又取决于第二个人的,第二个人的又取决于第一个人的,而且每一个员工都比前一个多一千,数学表达式即:
salary(4)=salary(3)+1000
salary(3)=salary(2)+1000
salary(2)=salary(1)+1000
salary(1)=5000
总结为:
salary(n)=salary(n-1)+1000 (n>1)
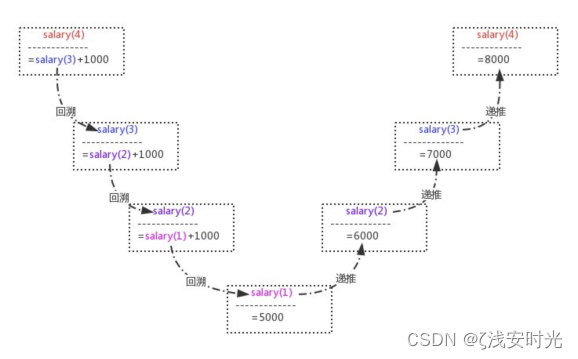
salary(1)=5000 (n=1)很明显这是一个递归的过程,可以将该过程分为两个阶段:回溯和递推。
回溯:通过最后一个结果往回寻找最开始的那个答案
递推:一层一层的往下寻找答案
在回溯阶段,要求第n个员工的薪水,需要回溯得到(n-1)个员工的薪水,以此类推,直到得到第一个员工的薪水,此时,salary(1)已知,因而不必再向前回溯了。然后进入递推阶段:从第一个员工的薪水可以推算出第二个员工的薪水(6000),从第二个员工的薪水可以推算出第三个员工的薪水(7000),以此类推,一直推算出第第四个员工的薪水(8000)为止,递归结束。需要注意的一点是,递归一定要有一个结束条件,这里n=1就是结束条件。
配图:回溯与递推
代码实现:
def salary(n):
if n==1:
return 5000
return salary(n-1)+1000
s=salary(4)
print(s) # 8000程序分析:
在未满足n==1的条件时,一直进行递归调用,即一直回溯,见图的左半部分。而在满足n==1的条件时,终止递归调用,即结束回溯,从而进入递推阶段,依次推导直到得到最终的结果。
递归本质就是在做重复的事情,所以理论上递归可以解决的问题循环也都可以解决,只不过在某些情况下,使用递归会更容易实现,比如有一个嵌套多层的列表,要求打印出所有的元素,代码实现如下
items=[[1,2],3,[4,[5,[6,7]]]]
def foo(items):
for i in items:
if isinstance(i,list): #满足未遍历完items以及if判断成立的条件时,一直进行递归调用
foo(i)
else:
print(i,end=' ')
foo(items) #打印结果1 2 3 4 5 6 7使用递归,我们只需要分析出要重复执行的代码逻辑,然后提取进入下一次递归调用的条件或者说递归结束的条件即可,代码实现起来简洁清晰。
三、算法
算法:就是解决问题的高效办法
算法中的二分法、冒泡排序、选择排序、堆排序等
1、二分法
二分法的原理:
1. 列表必须先排序(从小到大,从大到小)
2. 折半查找
2、二分法使用场景
在一个列表中查找某个数字是不是存在
l = [11, 2, 3, 43, 55, 67, 66, 23, 45, 45, 88, 99, ]"查找66这个数字是否在列表l中"
1. 实现功能
2. 快速找到
思路一:遍历列表l一个一个去比较,如果比较到了,就是找到了,否则,就是没找到
l = [11, 2, 3, 43, 55, 67, 66, 23, 45, 45, 88, 99, ]
for i in l:
if i == 66:
print('找到了')思路二:代码实现二分法(Python代码)
l = [11, 2, 3, 43, 55, 67, 66, 23, 45, 45, 88, 99, ]
# 1. 排序
l.sort()
print(l) # [2, 3, 11, 23, 43, 45, 45, 55, 66, 67, 88, 99]
# 2. 去列表的中间那个值,然后给66比较
target_num = 66
def my_half(l, target_num):
if len(l) == 0:
print('没找到')
return
# 3. 取的就是中间的那个索引
middle_index = len(l) // 2 # 向下取整 5 // 2 == 2 6 // 2 == 3
if target_num > l[middle_index]:
l_right = l[middle_index + 1:]
print(l_right) # [55, 66, 67, 88, 99]
my_half(l_right, target_num)
elif target_num < l[middle_index]:
l_left = l[:middle_index]
print(l_left) # [55, 66]
my_half(l_left, target_num)
else:
print('找到了') # 找到了
my_half(l, target_num)3、冒泡排序
3.1、冒泡排序简介
冒泡排序(Bubble Sort)是一种常见的排序算法,相对来说比较简单。
冒泡排序重复地走访需要排序的元素列表,依次比较两个相邻的元素,如果顺序(如从大到小或从小到大)错误就交换它们的位置。重复地进行直到没有相邻的元素需要交换,则元素列表排序完成。
在冒泡排序中,值最大(或最小)的元素会通过交换慢慢“浮”到元素列表的“顶端”。就像“冒泡”一样,所以被称为冒泡排序。
3.2、冒泡排序的原理
冒泡排序的原理如下:
1. 比较相邻的两个元素。如果第一个比第二个大则交换他们的位置(升序排列,降序则反过来)。
2. 从列表的开始一直到结尾,依次对每一对相邻元素都进行比较。这样,值最大的元素就通过交换“冒泡”到了列表的结尾,完成第一轮“冒泡”。
3. 重复上一步,继续从列表开头依次对相邻元素进行比较。已经“冒泡”出来的元素不用比较(一直比较到结尾也可以,已经“冒泡”到后面的元素即使比较也不需要交换,不比较可以减少步骤)。
4. 继续从列表开始进行比较,每轮比较会有一个元素“冒泡”成功。每轮需要比较的元素个数会递减,一直到只剩一个元素没有“冒泡”时(没有任何一对元素需要比较),则列表排序完成。
3.3、冒泡的三种算法
第一种算法
import random
# 生成10个随机数字
list1 = [random.randint(1, 1000) for _ in range(29)]
print(list1)
# 冒泡算法
# 前两种是拿第一位和后面的所有做对比,然后再拿第二位和后面所有做对比
# i代表遍历28轮,x代表被对比的数从第i+1位开始
for i in range(len(list1)-1):
for x in range(i+1,len(list1)):
# 对比两个数大小,如果前面比后面大,那么就交换位置
if list1[i] > list1[x]:
list1[x],list1[i] = list1[i],list1[x]
print(list1)
第二种算法
for i in range(len(list1)-1):
for x in range(len(list1)):
if i + x <= len(list1)-1:
if list1[i] > list1[i+x]:
list1[i+x],list1[i] = list1[i],list1[i+x]
print(list1)
第三种算法
#这种是从第一位开始,(相邻两位)上一位和下一位做对比,然后交换,一直对比28轮
#可以先从第二个for循环开始理解
for i in range(len(list1)-1):
for x in range(len(list1)-1):
if list1[x] > list1[x+1]:
list1[x+1],list1[x] = list1[x],list1[x+1]
print(list1)
所有的运行结果
[330, 563, 441, 468, 466, 406, 222, 77, 968, 128, 361, 256, 109, 109, 914, 761, 939, 885, 897, 808, 171, 810, 919, 377, 10, 294, 87, 768, 569]
[10, 77, 87, 109, 109, 128, 171, 222, 256, 294, 330, 361, 377, 406, 441, 466, 468, 563, 569, 761, 768, 808, 810, 885, 897, 914, 919, 939, 968]
[10, 77, 87, 109, 109, 128, 171, 222, 256, 294, 330, 361, 377, 406, 441, 466, 468, 563, 569, 761, 768, 808, 810, 885, 897, 914, 919, 939, 968]
[10, 77, 87, 109, 109, 128, 171, 222, 256, 294, 330, 361, 377, 406, 441, 466, 468, 563, 569, 761, 768, 808, 810, 885, 897, 914, 919, 939, 968]
四、三元表达式
写一个比较两个数大小的函数,返回大的
def my_max(a, b):
if a >b:
return a
else
return b对于只有二选一的情况,推荐使用三元表达式
语法结构:
res = 条件成立之后的结果 if 条件 else 条件不成立之后的结果
def my_max(a, b):
return a if a > b else b
res = my_max(1, 2)还支持嵌套,但不推荐写太多的嵌套,一般两层就够了,超过两层了,建议不这样写。
res = 2 if 2 > 10 else ( 10 if False else (100 if 10 > 5 else (2 if False else 1)))
print(res)五、列表生成式
1、把列表中得每一个名字后面都拼上后缀_SB
names_list = ['kevin', 'jerry', 'tank', 'oscar']方式一:遍历
names_list = ['kevin', 'jerry', 'tank', 'oscar']
# 把列表中得每一个名字后面都拼上后缀_SB
new_list = [] # 存放拼接之后的人名
for name in names_list:
# res = '%s_SB' % name
res = name + '_SB'
new_list.append(res)
print(new_list) # ['kevin_SB', 'jerry_SB', 'tank_SB', 'oscar_SB']方式二:列表生成式
# 列表生成式
res = [name + '_SB' for name in names_list]
print(res) # ['kevin_SB', 'jerry_SB', 'tank_SB', 'oscar_SB']2、列表中得每一个名字都拼接上后缀:_SB,除jerry之外
names_list = ['kevin', 'jerry', 'tank', 'oscar']方式一:for——continue
names_list = ['kevin', 'jerry', 'tank', 'oscar']
new_list = []
for name in names_list:
if name == 'jerry':
new_list.append(name)
continue
else:
new_list.append(name + '_SB')
print(new_list) # ['kevin_SB', 'jerry', 'tank_SB', 'oscar_SB'] 方式二:列表生成式
res = [name + '_SB' if name != 'jerry' else name for name in names_list]
print(res) # ['kevin_SB', 'jerry', 'tank_SB', 'oscar_SB']六、字典生成式,集合生成式
组装成一个字典
l1 = ['name', 'age', 'gender']
l2 = ['oscat', 18, 'male']方式一:遍历
d = {}
for i in range(len(l1)):
d[l1[i]] = l2[i]
print(d) # {'name': 'oscat', 'age': 18, 'gender': 'male'}方式二:enumarate(枚举)
可以从列表中拿到列表的索引和元素值
for i, j in enumerate(l1):
print(i, j)
# 结果
# 0 name
# 1 age
# 2 gender方式三:字典生成式
d = {l1[i]: l2[i] for i, j in enumerate(l1)}
print(d) # {'name': 'oscat', 'age': 18, 'gender': 'male'}集合生成式:
t = (i for i, j in enumerate(l1))
print(t)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









