






原型模式简介
原型模式(Prototype Pattern)用于创建重复的对象,同时又能保证性能,它属于创建型模式,既不属于工厂也不是直接New,而是以拷贝的方式创建对象。
这种设计模式实现了一个原型接口,该接口用于创建当前对象的克隆,当直接创建对象的代价比较大时,就采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建,我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库的调用。
原型模式通过克隆来创建新的对象,这种方式的优势是在运行的时候不需要知道具体的类,只需要一个实例对象就可以。
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
创建对象的时候不用构造函数,而是通过克隆原型的实例对象,使用现有的对象创建一个新的对象。
实现方式
原型模式包括三个角色:
- 原型接口(Prototype):定义了复制方法的接口,通常由Cloneable接口实现。
- 具体原型(ConcretePrototype):实现原型接口的类,实现具体的复制方法。
- 客户端(Client):使用具体原型类的实例来创建新的对象。
原型模式有两种实现方式,浅克隆和深克隆
1.浅克隆
浅克隆只会克隆对象本身以及其中的基本数据类型,而不会复制对象中的引用类型。使用浅拷贝虽然会为克隆的对象开辟一个新的存储空间,但是对象里面的引用类型还是指向的同一块区域。
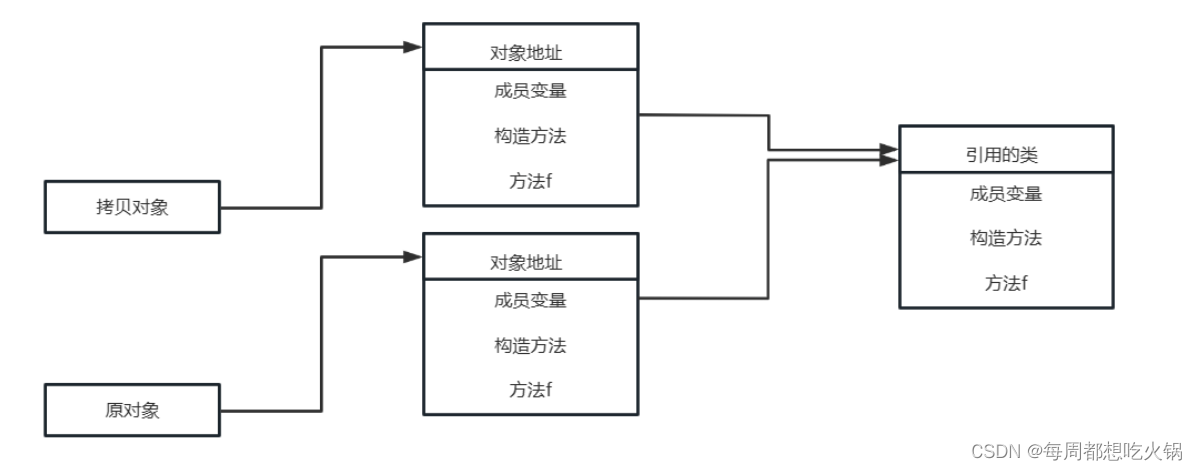
要想实现克隆就要满足两个条件:
- 重写Object类里的clone()方法,并修改为public,在clone方法中使用super.clone()来创建新的对象。
- 实现Cloneable接口,告诉jvm此类允许拷贝,否则会抛出CloneNotSupportedException异常
默认的clone方法就是浅拷贝,因为它并没有克隆对象中引用的其他对象。
一个浅克隆的例子:
public class User implements Cloneable{
private String username="李华";
private String password="1234";
private Address address=new Address();
public Address getAddress() {
return address;
}
public void setAddress(String city) {
this.address.setCity(city);
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
//重写clone方法
@Override
public User clone() throws CloneNotSupportedException {
return (User)super.clone();
}
public static void main(String[] args) throws CloneNotSupportedException {
User user1=new User();
user1.setAddress("beijing");
//浅拷贝
User user2=user1.clone();
System.out.println("user1 password: "+user1.password);
System.out.println("user1 city: "+user1.getAddress());
user2.setPassword("fjdk"); //改变user2的密码
user2.setAddress("shi"); //改变user2的地址
System.out.println("==========================");
System.out.println("user2 password: "+user2.password);
System.out.println("user1 password: "+user1.password);
System.out.println("user1 city: "+user1.getAddress());
System.out.println("user2 city: "+user2.getAddress());
}
}
class Address{
private String city;
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
return "Address{" +
"city='" + city + '\'' +
'}';
}
}
输出:

可以看到user2是从user1克隆来的,Address是一个引用类型,在更改user2的密码之后,user2的密码改变了,而user1的密码没有变,这就说明基本类型被克隆了一份,而更改了user2的address之后,user1的address也被改变了,这说明user1和user2的address还是同一个。引用类型并没有被克隆。
2.深克隆
深克隆会复制对象本身,基本类型变量以及引用类型变量,也就是说,被克隆出来的对象的引用类型变量和原对象中的引用类型变量指向不同的对象。
1、手动复制内部状态
在重写的克隆方法中为克隆的新对象新建引用类型变量,这样引用类型变量也会新建一份。
//重写clone方法
@Override
public User clone() throws CloneNotSupportedException {
try{
User user= (User) super.clone();
user.address=new Address();
return user;
}catch (CloneNotSupportedException e){
throw new RuntimeException("Error cloning object",e);
}
}
再次运行整个程序输出:

可以看出这次user1的address没有被改变。
2、序列化方式
使用序列化的方式要克隆的对象的类不用实现Cloneable接口,但是需要实现Serializable接口,同时对象中的引用类型变量的类也需要实现Serializable接口,声明对象是可序列化的情况下,才可以使用序列化的方式进行克隆。
public static User clone(User user) {
try{
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(user);
oos.close();
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
User user1 = (User) ois.readObject();
ois.close();
return user1;
}catch (Exception e){
throw new RuntimeException("Error cloning object",e);
}
}
再次运行刚才的程序发现,这次运行的结果也是深克隆,与上面截图相同,就不贴图了。
3、使用第三方包
在程序中导入commons-lang3-3.4.jar包,就是Apache Commons Lang. 这个库中有很多实用的方法,调用里面的clone()方法即可轻松完成深克隆。
User user2= SerializationUtils.clone(user1);
另外还有Google Guava库中也有clone方法完成深克隆。
总结
优点:
- 逃避构造函数的约束,原型模式可以避免复杂对象的创建过程,当对象的创建较为复杂的时候,可以利用原型模式轻松地创建和配置对象,而不必再执行大量的初始化和配置代码。
- 提高程序性能,在多数情况下,复制对象比创建新对象更快,原型模式通过复制现有对象创建新的对象,减少了创建新对象的成本,有助于提高性能。
缺点:
- 在有些情况下,原型对象可能无法克隆,可能是因为它的构造函数是私有的或者没有实现Cloneable接口,这种时候就无法使用原型模式。
- 改变一个对象的属性值,可能会造成另外一个对象的属性值的改变。
- 如果一个对象由多层嵌套结构,复制它可能会变得困难,可能会导致深度克隆问题。
注意事项:
1、深拷贝与浅拷贝: 在实现原型模式时,需要注意对象的拷贝方式。浅拷贝只复制对象的基本类型属性,而对象类型的属性仍然指向原对象的引用。深拷贝则会递归地复制对象的所有属性,包括对象类型的属性。如果你的原型对象包含对象类型的属性,确保使用深拷贝,以避免不同实例之间的引用冲突。
2、循环引用: 在实现深拷贝时,需要注意对象之间的循环引用问题。如果对象之间存在循环引用,可能导致无限递归和堆栈溢出。在实现深拷贝时,可以使用哈希表来存储已经复制过的对象,以避免重复复制和循环引用问题。
3、多线程安全: 在多线程环境下使用原型模式时,需要注意线程安全问题。在复制对象时,确保对原型对象进行同步,以避免在复制过程中发生数据不一致的问题。
4、维护成本: 原型模式可能会导致代码的维护成本增加。当原型对象的结构发生变化时,需要同时更新拷贝方法。此外,如果原型对象包含大量属性,实现深拷贝可能会变得复杂和繁琐。
5、对象初始化: 原型模式通过复制现有对象来创建新对象,这可能导致新对象的初始化问题。如果对象的初始化过程包含一些特定的逻辑,需要确保在复制对象时正确地执行这些逻辑。















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











