






Redis的线程模型
Redis6.X之前是纯单线程,Redis6.X之后引入多线程,Redis中的多线程用来处理网络请求,因为单线程不会出现线程安全问题所以,读写还是单线程操作。
为什么读写单线程但速度还很快?
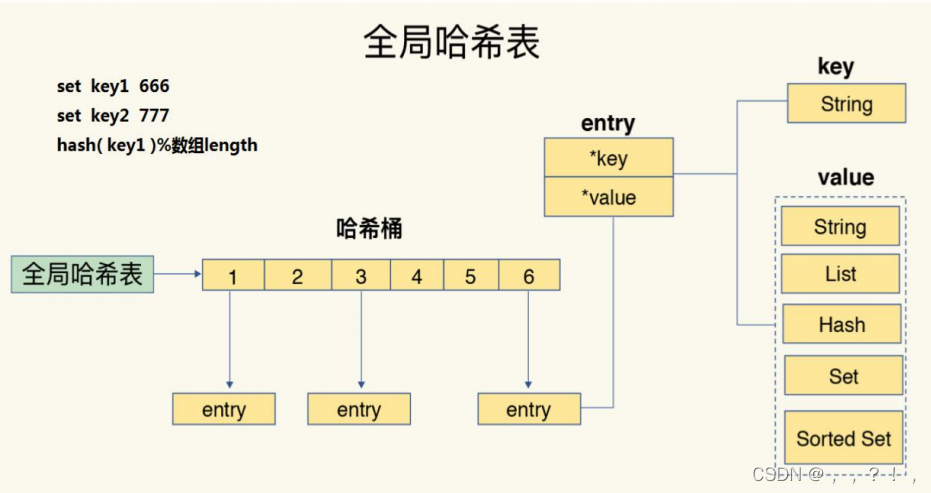
因为redis数据,平常存储在内存中,一旦机器故障可能数据就会丢失redis提供数据持久化机制. 持久化的作用主要是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
实现持久化的主要方式有两种,RDB 方式和AOF方式
RDB方式
RDB持久化的触发分为手动触发和自动触发两种,生成RDB文件,将数据存储在其中。重新启动redis服务时,会把dump.rdb文件内容还原回来.
手动触发
save命令和bgsave命令都可以生成RDB文件。
save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在Redis服务器阻塞期间,服务器不能处理任何命令请求。而bgsave命令会创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求。bgsave命令执行过程中,只有创建子进程时会阻塞服务器,而对于save命令,整个过程都会阻塞服务器,因此save已基本被废弃,线上环境要杜绝save的使用。
自动触发
配置中的save m n
自动触发最常见的情况是在配置文件中通过save m n,指定当m秒内发生n次变化时,会触发bgsave。例如,查看redis的默认配置文件(Linux下为redis根目录下的redis.conf),可以看到如下配置信息:
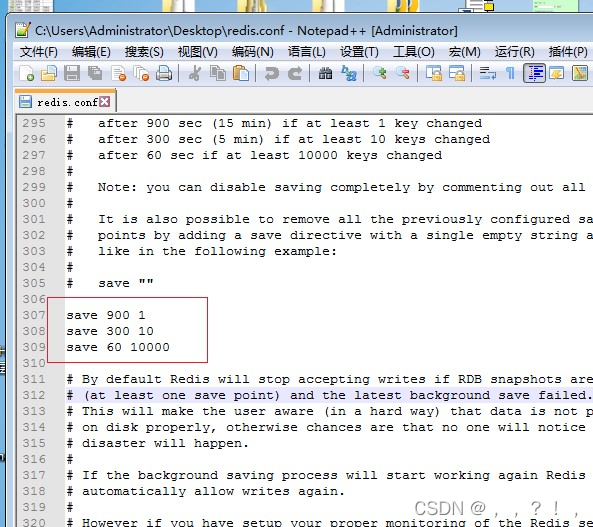
其中save 900 1的含义是:当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsave;save 300 10和save 60 10000同理。当三个save条件满足任意一个时,都会引起bgsave的调用。
优点:
恢复数据幅度快。
缺点:
每次bgsave时都会fork子进程有时间成本。
因为每次存储数据都有时间间隔,当Redis突然宕机,会导致最近的数据丢失。
AOF方式
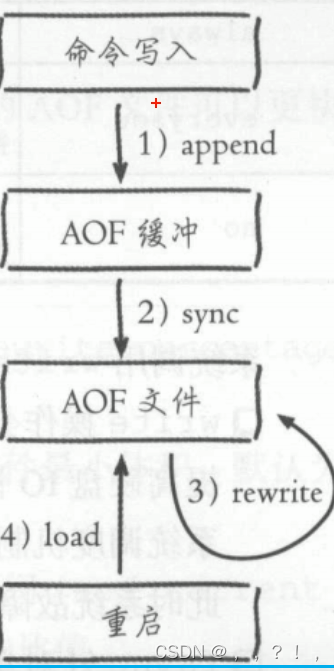
RDB持久化是将进程数据写入文件,而AOF持久化,则是将Redis执行的每次写命令记录到单独的日志文件中;当Redis重启时再次执行AOF文件中的命令来恢复数据。
开启AOF
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置:appendonly yes
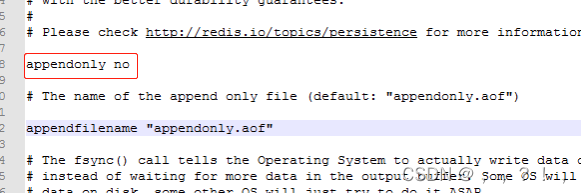
配置改为yes后,AOF回记录每一次的写操作。AOF是文件形式存储的,文件有可能会出现问题,当AOF文件出错redis将无法正常启动,对于这个问题Redis提供了一个修复工具 redis-check-aof可对ADF文件进行修复,但会丢失一些Key值,这种丢失是可以接受的。
appendfsync no :完全依赖操作系统来进行日志同步,Redis不主动进行同步。这种方式性能最高,但在系统崩溃时可能会导致数据丢失。
AOF重写机制
随着时间流逝,Redis服务器执行的写命令越来越多,AOF文件也会越来越大;过大的AOF文件不仅会影响服务器的正常运行,也会导致数据恢复需要的时间过长。文件重写是指定期重写AOF文件,减小AOF文件的体积。需要注意的是,AOF重写是把Redis进程内的数据转化为写命令,同步到新的AOF文件;不会对旧的AOF文件进行任何读取写入操作。
文件重写的触发
文件重写的触发,分为手动触发和自动触发:
手动触发:直接调用bgrewriteaof命令,该命令的执行与bgsave有些类似:都是fork子进程进行具体的工作,且都只有在fork时阻塞。
自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数,以及aof_current_size和aof_base_size状态确定触发时机。

auto-aof-rewrite-min-size 64mb:当AOF文件体积达到64mb时会触发重写。
auto-aof-rewrite-percentage 100:当AOF文件体积在上次重写之后的基础上体积增加了100%时触发重写。
优点:
安全性更高,配置得当最多丢失一秒钟的数据,
AOF太大时会自动进行重写。
缺点:
恢复数据慢。
相同数量来说,AOF文件体积大于RDB。
RDB-AOF混合模式
在执行写操作时,先持久化的数据写入AOF文件的开头,之后的写操作命令拼接到后方。可以将其理解为,在 aof 持久化的基础上,进行的一些优化,本身也依然是基于 aof 持久化
Redis事务
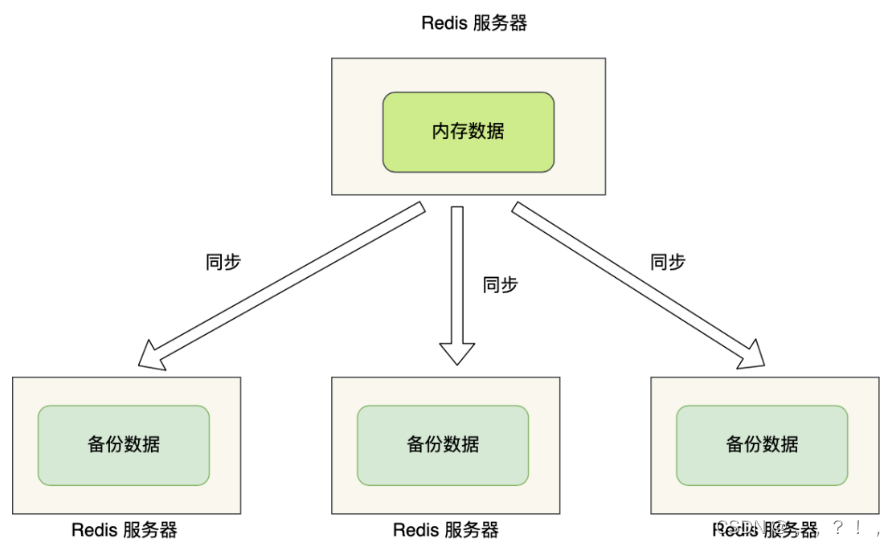
主从复制的作用主要包括:
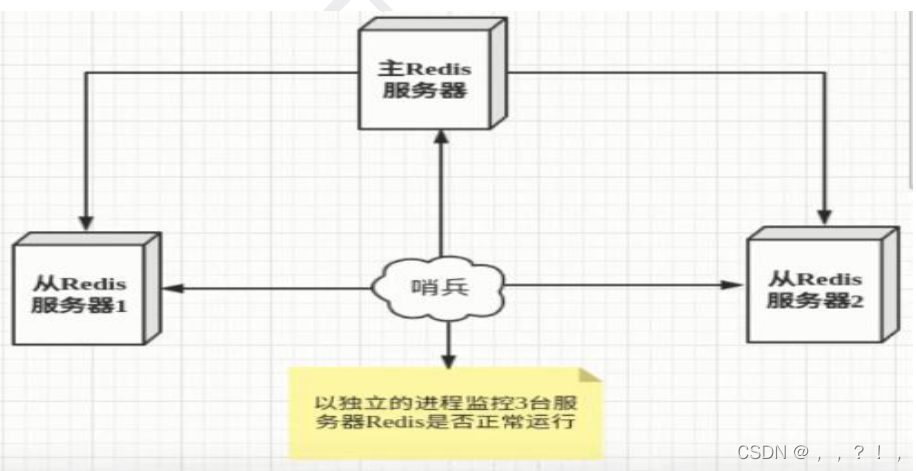
哨兵的主要工作任务:
(1)监控:哨兵会不断地检查你的Master和Slave是否运作正常。
(2)提醒:当被监控的某个Redis节点出现问题时,哨兵可以通过 API 向管理员或者其他应用程序发送通知。
(3)自动故障迁移:当一个Master不能正常工作时,哨兵会进行自动故障迁移操作,将失效Master的其中一个Slave升级为新的Master,并让失效Master的其他Slave改为复制新的Master;当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用新Master代替失效Master。
RedisKey的过期策略
1.立即删除
当Key的时间到了之后会立即删除Key,好处是不浪费内存空间,缺点是如果大量的Key同时到期会增加的CPU负荷。
2.惰性删除
Key到期后,不会立即删除,而是等待下次要使用该Key时会检测到Key已过期,此时才会删除Key,惰性删除的缺点就是浪费内存空间。
3.定时删除
每隔一段时间删除过期的健
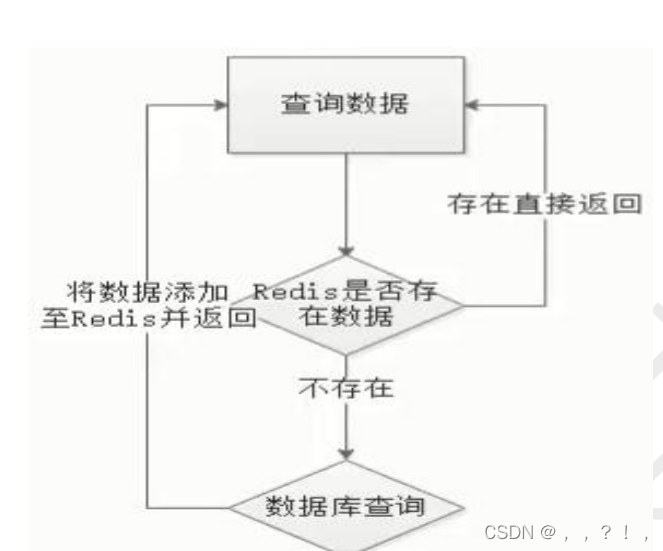
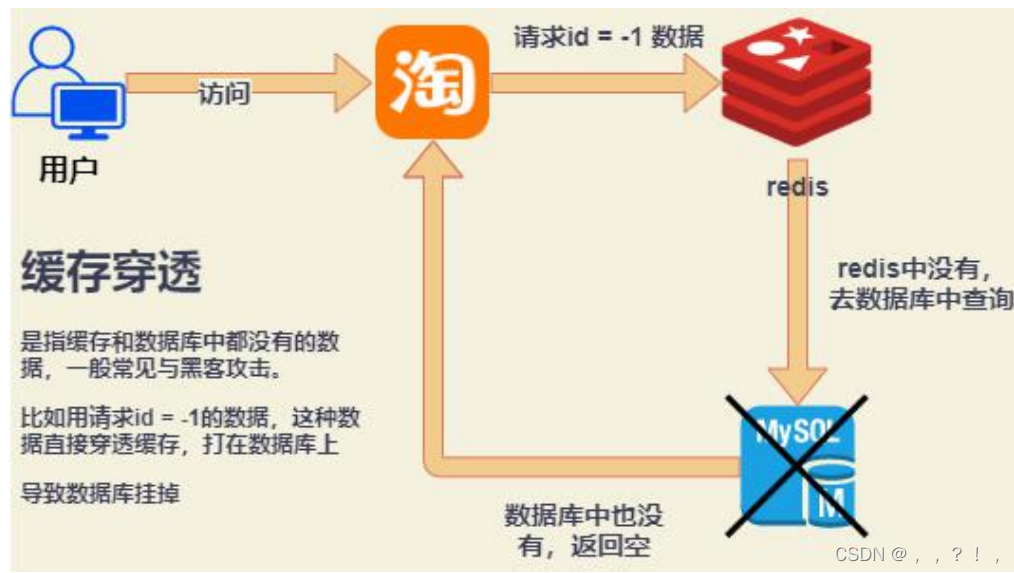
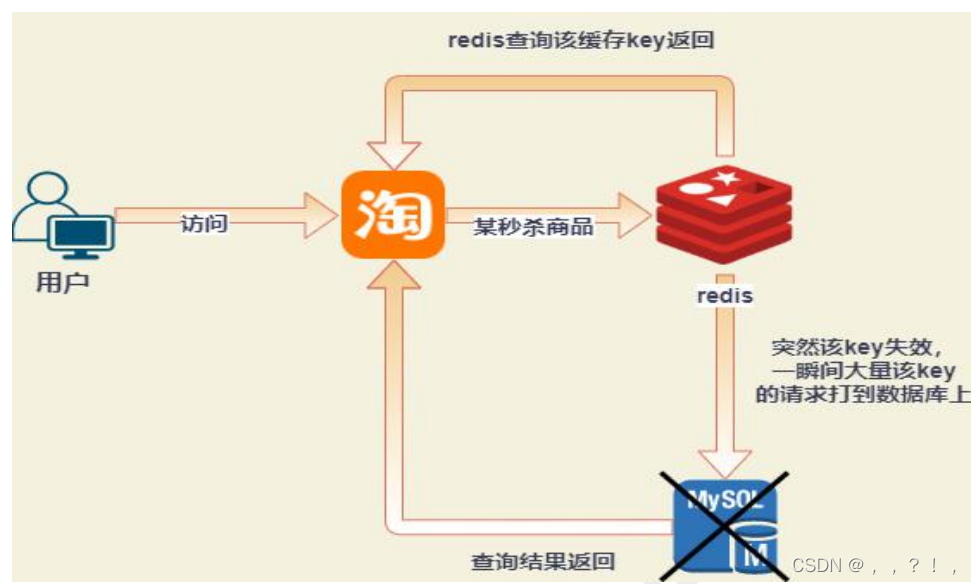
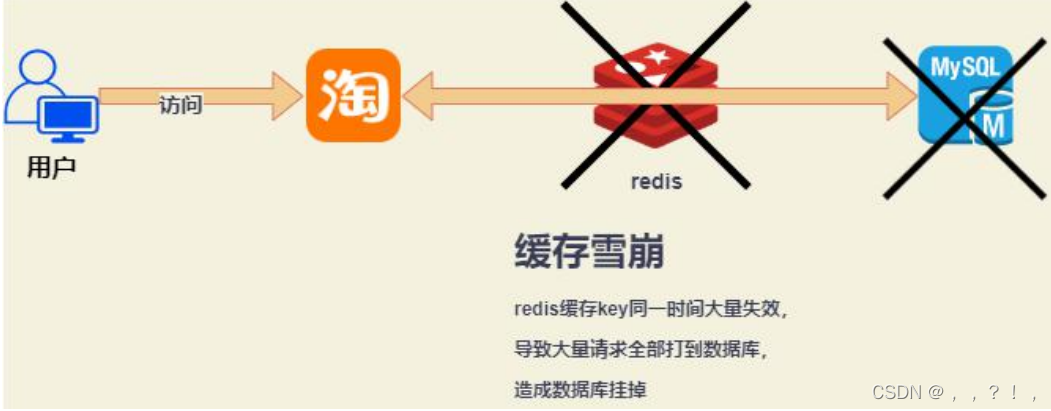
redis实现分布式锁
分布式锁,即分布式系统中的锁。在单体应用中我们通过 java 中的锁解决多线程访问共享资源的问题,而分布式锁,就是解决了分布式系统中控制共享资源访问的问题。与单体应用不同的是,分布式系统中竞争共享资源的最小粒度从线程升级成了进程.+
redis中有一个setnx方法,该方法在每次存储时,会检测key值是否已经存在,若存在则不会存储,利用这一原理可以实现分布式锁。在线程到来时调用 redisTemplate.opsForValue().setIfAbsent();
方法(该方法的底层实现为setnx 方法 )判断所要存储的key是否存在,若不存在则存储key并获取到锁,若存在则等候锁的释放。以下几个例子是分布式锁一步一步优化的过程,便于更好的理解其原理
第一个版本

但是,以上实现存在一个很大的问题,当客户端 1 拿到锁后,如果发生下面的场景就会造成死锁。
1. 程序处理业务逻辑异常,没及时释放锁
2. 进程挂了,没机会释放锁
以上情况会导致已经获得锁的客户端一直占用锁,其他客户端永远无法获取到锁。
第二版本 对以上代码进行改进,在 finally 中释放锁,以及设置键失效时间.
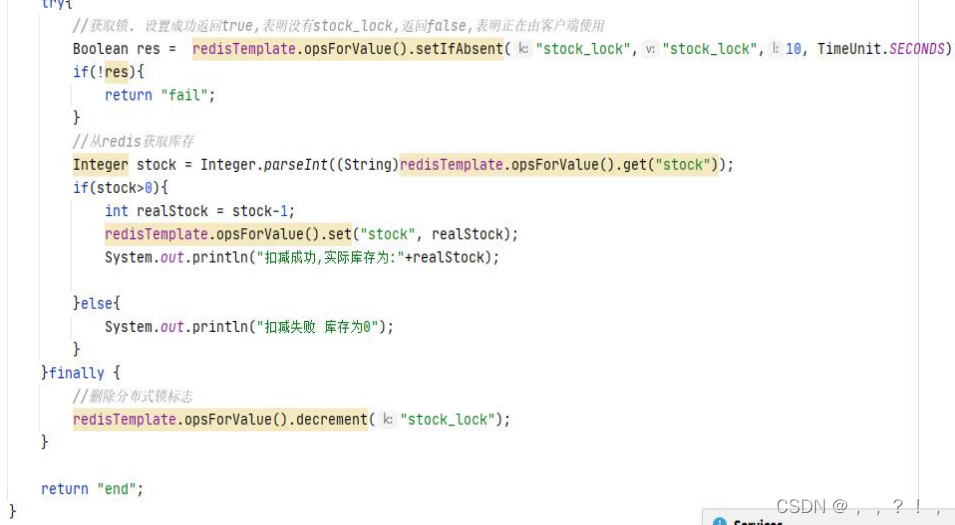
但该写法依旧会有问题,假设有两个线程,当第一个线程执行时间大于健的失效时间时,当执行到一半时锁释放,第二个线程获取到锁并执行,这时第一个线程执行完毕,并且执行了删除key这个步骤,但是他删除的是第二个线程所存储的的key值,这样会导致锁失效。
第三版本 我们可以使用 UUID.randomUUID().tostring();方法生成版本号,在存储健时加上一个版本号,在最后删除时判断该线程的版本号是否一致,这样以来执行时间超过key失效时间的线程就不会出现误删情况
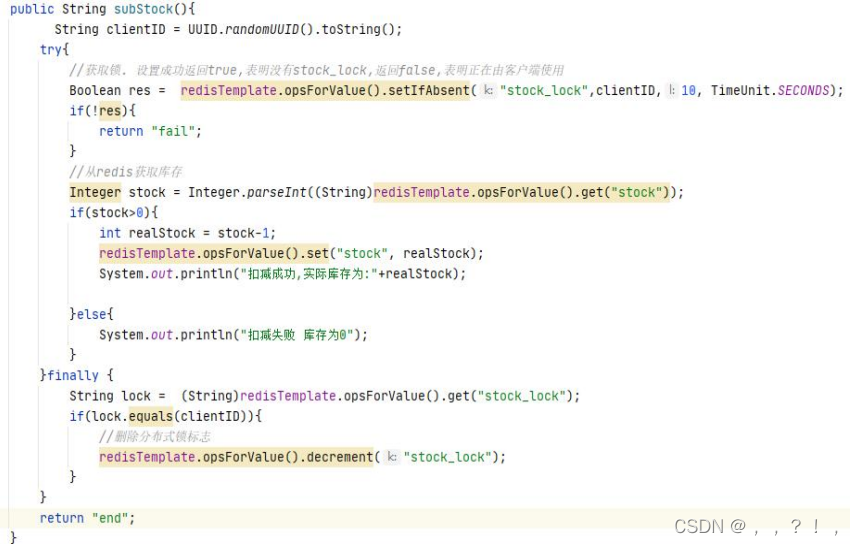
redis中提供了一个组件,名叫Redission可以简单的实现分布式锁
redission的实现
导入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>创建 Redisson 对象
@Bean
public Redisson getRedisson(){
Config config = new Config();
config.useSingleServer().setAddress("redis://120.48.37.232:6379").setDatabase(0);
return (Redisson)Redisson.create(config);
}在需要使用该对象的地方使用@Autowired标签注入即可
使用 Redisson 实现加锁,释放锁.

Redission执行过程如下图
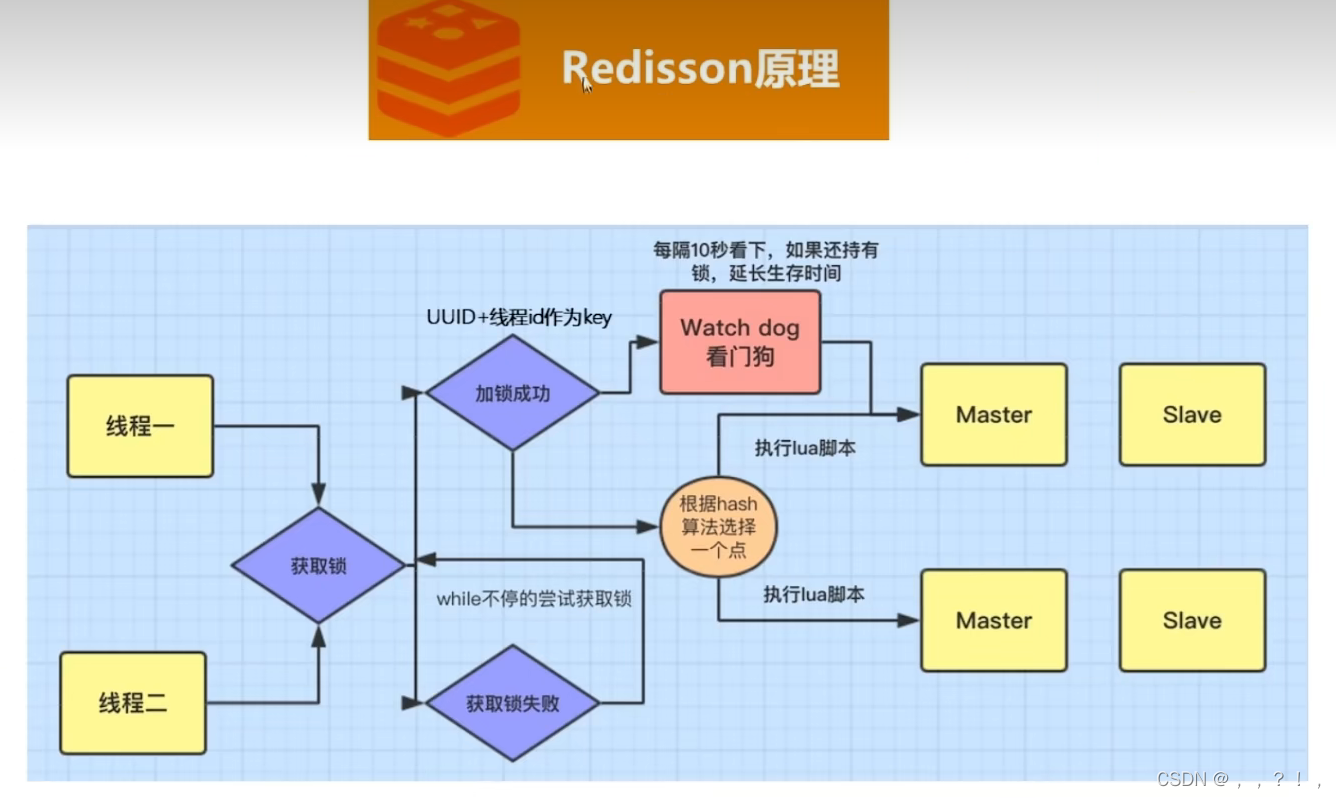
两个线程同时来到,但只有一个线程可以获取到锁,获取失败的锁会不停的尝试继续获取锁直到超时。获取成功的线程 会用UUID和线程id作为KEY存储到redis中,在此期间还会有一个watch dog机制,每过几秒 查看该线程是否还持有锁,如果有会,加长key的存活时间,直到任务执行完毕,删除KEY释放锁。















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









