






1.什么是性能调优
性能调优就是调节计算机硬件、操作系统和应用三者之间的关系,实现整个系统(包括硬件、操作系统、应用)的性能最大化,并能不断的满足现有的业务需求。
1.1为什么需要性能调优
一是为了获得更好的系统性能(就是你现有的系统运行的还不错,但优化一下可以运行的更好)。
二是通过性能调优来满足不断增加的业务需求。
1.2定位问题
在性能调优或者改bug的时候定位问题是最困难的,反而解决问题是比较简单的,有些问题比如OOM,线程死锁,执行速度慢,并不是很简单就能找到的问题的,可能改完代码后性能并没有提高多少,有时候性能反而不升反降,这些都是没有找准问题而导致的,我们需要通过各种性能分析工具来找到问题的根源。
2.如何调优
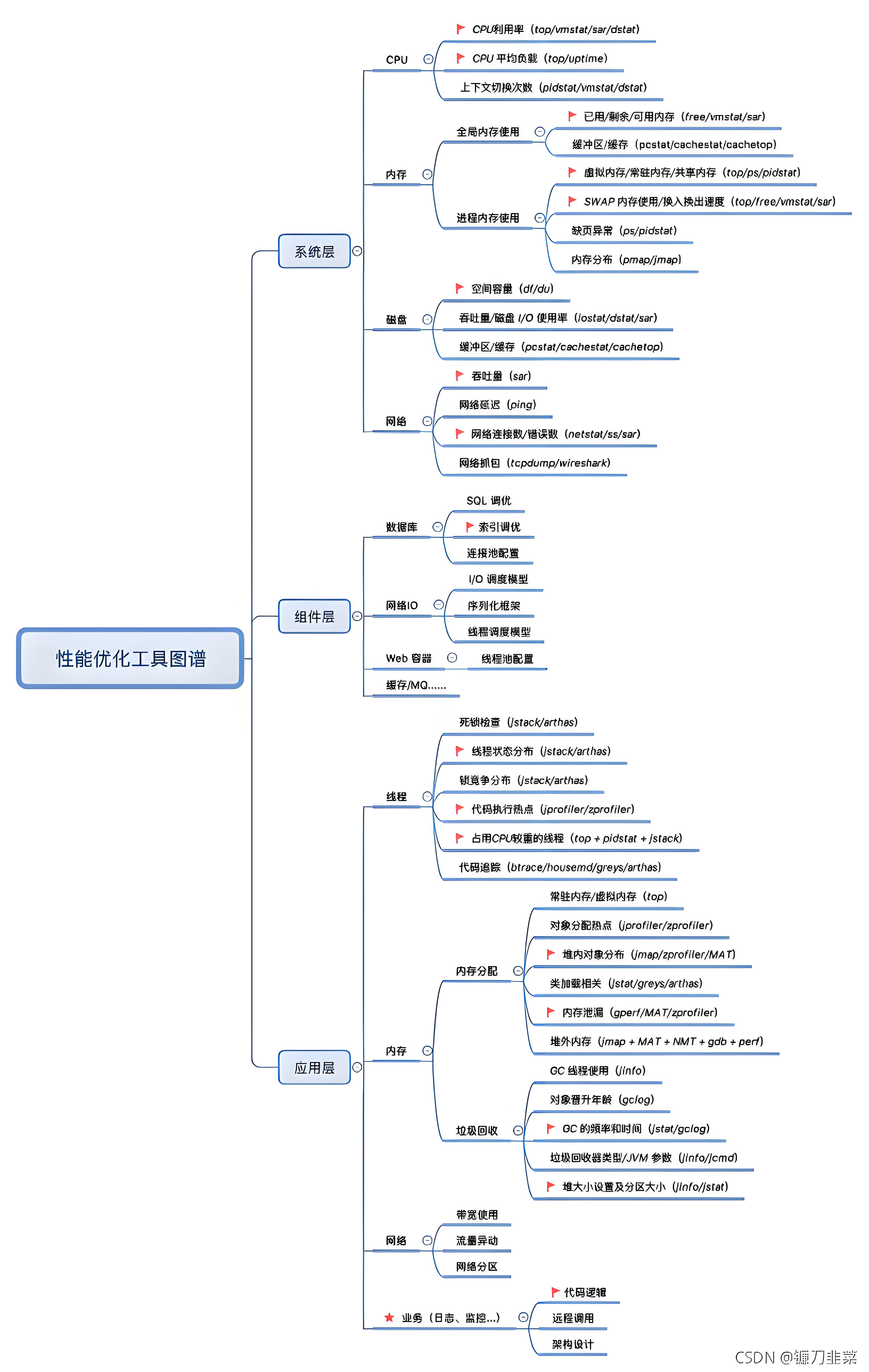
2.1看懂监控指标
和 CPU 相关的指标主要有以下几个,常用的工具有 top、 ps、uptime、 vmstat、 pidstat等
2.1.1CPU指标的含义
第一行:当前时间、系统启动时间、当前系统登录用户数目、平均负载(1分钟,10分钟,15分
钟),平均负载(load average),一般对于单个cpu来说,负载在0~1.00之间是正常的,超过
1.00须引起注意,在cpu中,系统平均负载不应该高于cpu核心的总数
第二行: 进程总数、运行进程数、休眠进程数、终止进程数、僵死进程数
第三行: CPU指标
%us:用户空间占用cpu百分比;
%sy:内核空间占用cpu百分比;
%ni:用户进程空间内改变过优先级的进程占用cpu百分比;
%id:空闲cpu百分比,反映一个系统cpu的闲忙程度。越大越空闲;
%wa:等待输入输出(I/O)的cpu百分比;
%hi:指的是cpu处理硬件中断的时间;
%si:值的是cpu处理软件中断的时间;
%st:用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间。
第四行:total总的物理内存;used使用物理内存大小;free空闲物理内存;buffers用于内核缓存
的内存大小
第五行:total总的交换空间大小;used已经使用交换空间大小;free空间交换空间大小;cached
缓冲的交换空间大小
第六行:进程显示区
PID 进程号
USER 运行用户
PR:优先级,PR(Priority)所代表的值有什么含义?它其实就是进程调度器分配给进程的时间
片长度,单位是时钟个数,那么一个时钟需要多长时间呢?这跟CPU的主频以及操作系统平台
有关,比如linux上一般为10ms,那么PR值为15则表示这个进程的时间片为150ms。
NI:任务nice值
VIRT: 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES: 物理内存用量
SHR: 共享内存用量
S :该进程的状态,其中S代表休眠状态;D代表不可中断的休眠状态;R代表运行状态;Z代
表僵死状态;T代表停止或跟踪状态
%CPU:该进程自最近一次刷新以来所占用的CPU时间和总时间的百分比
%MEM:该进程占用的物理内存占总内存的百分比
TIME+ :累计cpu占用时间
COMMAND:该进程的命令名称,如果一行显示不下,则会进行截取,内存中的进程会有一
个完整的命令行。
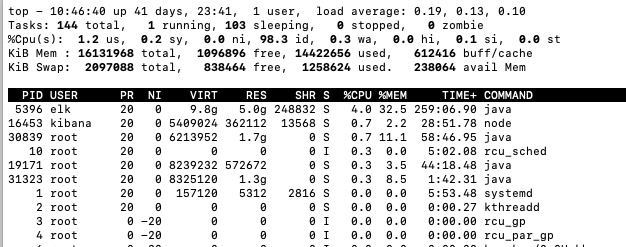
2.1.2查看线程
top -H -p 12312(PID号)
2.1.3虚拟内存
vmstat 5 6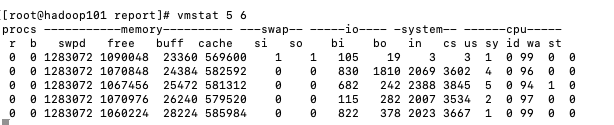
字段说明
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
System(系统):
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间3.调优工具
运用jvm自带的命令可以方便的在生产监控和打印堆栈的日志信息帮忙我们来定位问题
3.1jps
JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
3.1.1参数
-l : 输出主类全名或jar路径
-q : 只输出LVMID
-m : 输出JVM启动时传递给main()的参数
-v : 输出JVM启动时显示指定的JVM参数
3.2.jstat
jstat(JVM statistics Monitoring)是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机
进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
3.2.1参数
[option] : 操作参数
LVMID : 本地虚拟机进程ID
[interval] : 连续输出的时间间隔
[count] : 连续输出的次数
3.2.2垃圾回收统计
jstat -gc pid [interval] [count]可以显示gc的信息,查看gc的次数,及时间,下面是显示列的具体描述
列名 描述
S0C 第一个幸存区的大小
S1C 第二个幸存区的大小
S0U 第一个幸存区的使用大小
S1U 第二个幸存区的使用大小
EC 伊甸园区的大小
EU 伊甸园区的使用大小
OC 老年代大小
OU 老年代使用大小
MC 方法区大小
MU 方法区使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC 年轻代垃圾回收次数
YGCT 年轻代垃圾回收消耗时间
FGC 老年代垃圾回收次数
FGCT 老年代垃圾回收消耗时间
GCT 垃圾回收消耗总时间3.2.2.1老年代垃圾回收统计
jstat -gcold pid [interval] [count]列名 描述
MC 方法区大小
MU 方法区使用大小
CCSC 压缩类空间大小
CCSU 压缩类空间使用大小
OC 老年代大小
OU 老年代使用大小
YGC 年轻代垃圾回收次数
FGC 老年代垃圾回收次数
FGCT 老年代垃圾回收消耗时间
GCT 垃圾回收消耗总时间3.2.2.2整体垃圾回收情况
jstat -gcutil pid [interval] [count]列名 描述
S0 第一个幸存区的使用大小
S1 第二个幸存区的使用大小
EU 伊甸园区的使用大小
OU 老年代使用大小
MU 方法区使用大小
CCSU 压缩类空间使用大小
YGC 年轻代垃圾回收次数
YGCT 年轻代垃圾回收消耗时间
FGC 老年代垃圾回收次数
FGCT 老年代垃圾回收消耗时间
GCT 垃圾回收消耗总时间3.3jmap
jmap(JVM Memory Map)命令用于生成heap dump文件,如果不使用这个命令,还可以使用 -
XX:+HeapDumpOnOutOfMemoryError 参数来让虚拟机出现OOM的时候·自动生成dump文件。
jmap不仅能生成dump文件,还可以查询finalize执行队列、Java堆和永久代的详细信息,如当前
使用率、当前使用的是哪种收集器等。
3.3.1参数
dump : 生成堆转储快照
finalizerinfo : 显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象
heap : 显示Java堆详细信息
histo : 显示堆中对象的统计信息
permstat : to print permanent generation statistics
F : 当-dump没有响应时,强制生成dump快照
3.3.2查看进程的内存映像信息
使用不带选项参数的jmap打印共享对象映射,将会打印目标虚拟机中加载的每个共享对象的起始
地址、映射大小以及共享对象文件的路径全称
jmap pid3.3.3查看堆信息
打印一个堆的摘要信息,包括使用的GC算法、堆配置信息和各内存区域内存使用信息
jmap -heap pid3.3.4显示堆中对象的统计信息
其中包括每个Java类、对象数量、内存大小(单位:字节)、完全限定的类名。打印的虚拟机内部的
类名称将会带有一个’*’前缀。如果指定了live子选项,则只计算活动的对象。
jmap -histo[:live] pid3.3.5显示类加载器
打印Java堆内存的永久保存区域的类加载器的智能统计信息
jmap -clstats pid3.3.6生成堆转储快照
以hprof二进制格式转储Java堆到指定filename的文件中
jmap -dump:format=b,file=heapdump.phrof pid3.4jstack
jstack用于生成java虚拟机当前时刻的线程快照
3.4.1参数
-F : 当正常输出请求不被响应时,强制输出线程堆栈
-l : 除堆栈外,显示关于锁的附加信息
-m : 如果调用到本地方法的话,可以显示C/C++的堆栈
3.4.2使用实例
jstack pid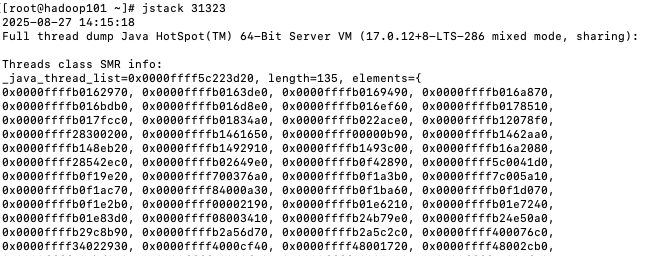
3.4.3还有下工具JConsole、VisualVM、jprofiler、Arthas
4.调优案例
4.1排查消耗CPU的方法
4.1.1Jprofiler
这个也是经常面试的一个面试题,如何排查CPU超高的JAVA线程,这里我们分为开发环境以及生
产环境来说
在开发环境可以通过Jprofiler进行快速排查CPU过高的代码
使用简单具体操作可以其他相关文档查看。
4.1.2命令排查
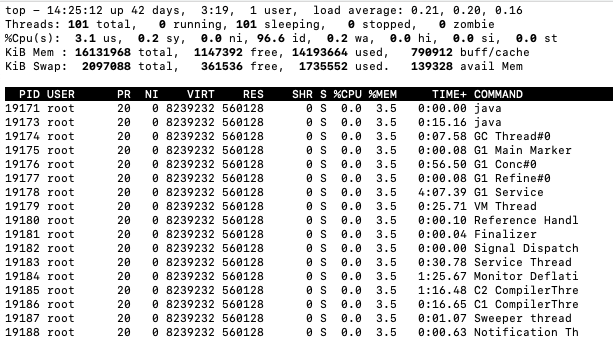
有的时候在生产环境是无法使用Jprofiler等工具的,我们只能借助jdk提供的相关命令进行排查使用top命令排查CPU消耗很高的进程,查到进程消耗的CPU很高的情况下我们可以通过以下命令来定位到那个线程消耗的CPU高
top -H -p pid通过这个命令可以定位到当前的这个线程消耗CPU很高
4.1.2.1转换16进制
因为java中查看线程号使用的是16进制我们需要将linux中的线程号转换为java中能够使用的16进
制
printf "%x" 19171![]()
4.1.2.2查看进行运行状态
使用 jstack 进程id|grep tid 转换成16进制后的数字,查看该线程是否运行

4.1.2.3排查代码
使用 jstack pid ,查看该进程中线程的详细信息,因为默认 jstack 会显示当前进程下的所有线程堆栈信息,所有我们只需要显示我们运行的消费CPU最高的代码即可,使用如下命令就可以显示当前线程后面CPU消耗很高的线程的堆栈信息,找到代码就可以解决问题了
jstack 19171|grep 4ae5 -A20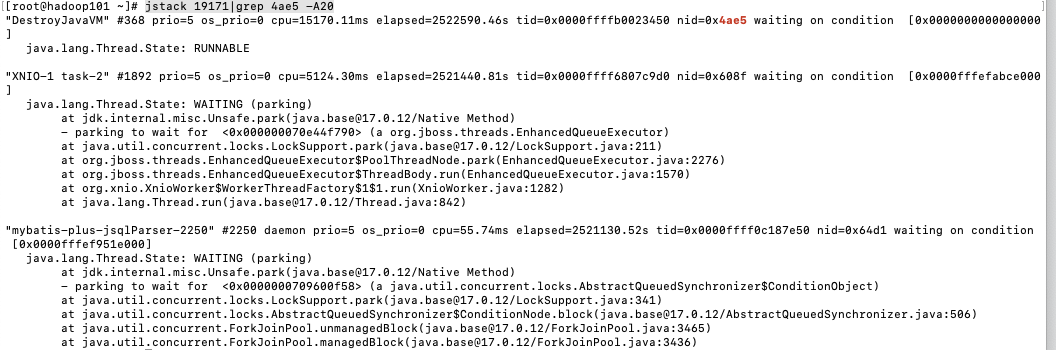
查看线程的运行状态锁定代码行数。
4.1.3Arthas排查
生产环境下通过上面命令排查毕竟是比较繁琐的,如果有条件用Arthas可以让我们排查起来更加方便
java -jar arthas-boot.jar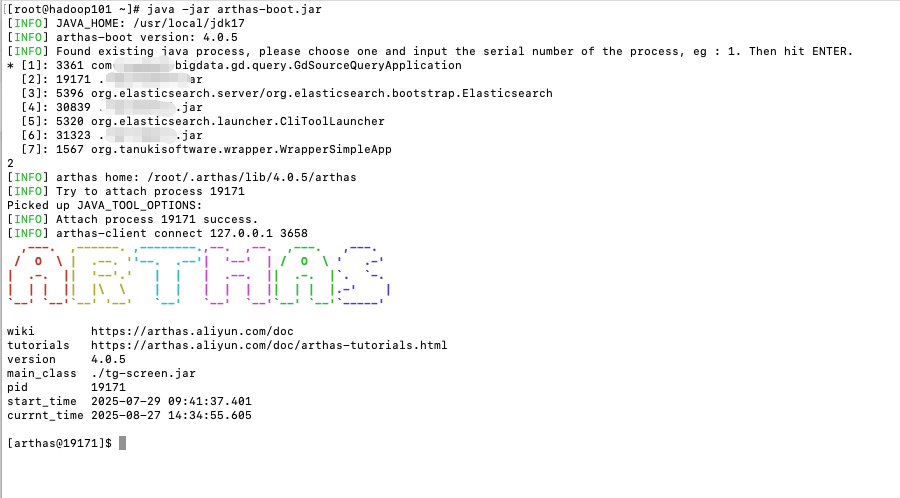
4.1.3.1dashboard
使用 dashboard 来查看全局的性能监控
dashboard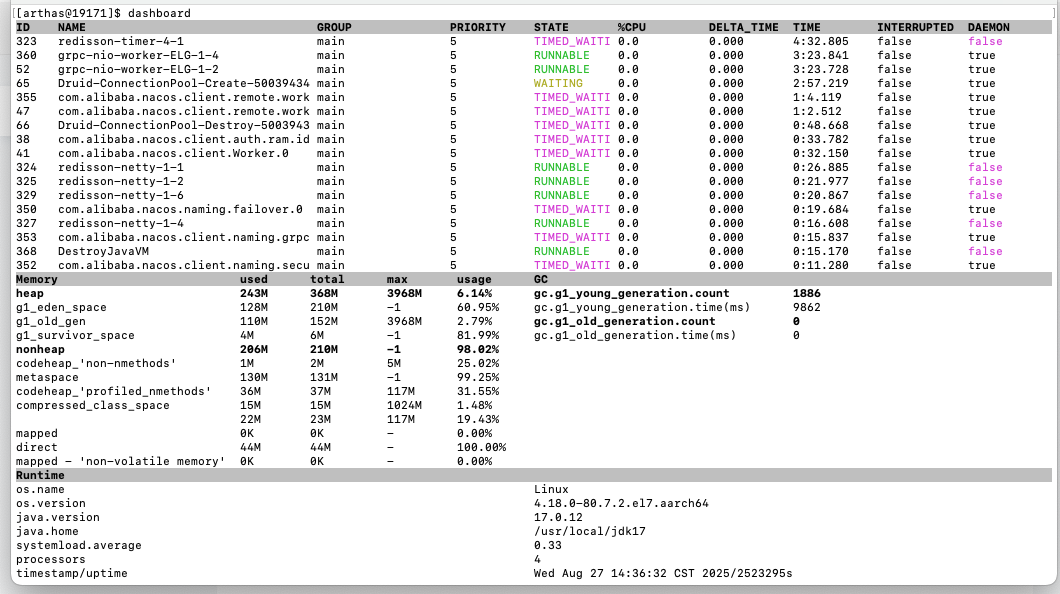
4.1.3.2发现负载高的CPU线程
thread 325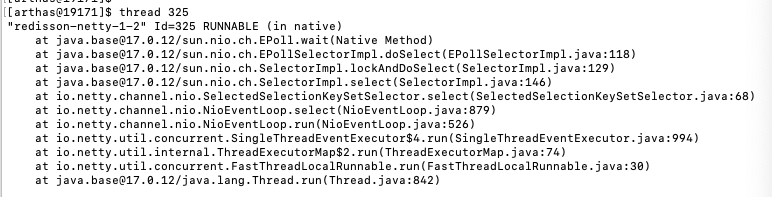
4.1.3.3反编译代码
可以使用jad工具进行反编译,查看具体哪里有问题
jad io.netty.channel.nio.SelectedSelectionKeySetSelector导出当前的内内存中的类的原代码,为后边使用
jad io.netty.channel.nio.SelectedSelectionKeySetSelector >
/tmp/CpuTooHigh.java4.1.3.4跟踪方法调用
怀疑这个方法有问题,可以尝试用 trace 方法来进行调用一次
trace io.netty.channel.nio.SelectedSelectionKeySetSelector handler4.1.3.5修改原代码
有问题的话修改代码
vi /tmp/CpuTooHigh.java4.1.3.6查找类加载器
有的时候服务不能轻易的上线,我们可以只编译当前的类,然后替换内存中,实现快速上线
sc -d io.netty.channel.nio.SelectedSelectionKeySetSelector | grep classLoaderHash4.1.3.7热编译
通过类加载器将我们的类进行编译
mc -c 31efe0(上边编译的结果) /tmp/CpuTooHigh.java -d /tmp4.1.3.8加载新类
redefine /tmp/com/handler/CpuTooHigh.class(上边代码输出的结果)4.2排查内存泄漏
4.2.1命令排查
首先需要排查下FGC的情况,看看是否在频繁的进行FGC,可以使用 jstat -gc pid 间隔时间 显
示次数 来查看GC情况
jcmd 查看运行
jstat -gc 31323 3000 30
查看FGC并且FullGC平均时间是否越来越长
通过以下方式查找问题所在
top
top -H -p 31323
printf "%x" 97600
jstack 31323 |grep 17d40 -A204.3死锁排查
4.3.1jconsole排查死锁
4.3.2命令检查死锁
jcmd
# 检查是否存在死锁
jstack -l 31323|grep "deadlock"![]()
4.3.3排查死锁
如果排查出现死锁问题后,接着就可以使用 jstack 导出堆栈信息,死锁信息就在最后
jstack -l 313234.3.4Arthas排查
thread -b这里面已经打印出来发现一个死锁,以及死锁阻塞的线程id
4.3.5查看堆栈信息
thread 324.4内存溢出排查
内存溢出是指程序员在申请内存时,没有足够的内存空间供其实用
4.4.1内存溢出分类
4.4.1.1堆内存溢出
堆内存是存放由 new 创建的对象和数组,在堆中分配的内存,由 Java 虚拟机的自动垃圾回收器来
管理
异常类型:java.lang.OutOfMemoryError: Java heap space
优化:通过-Xmn(最小值)–Xms(初始值) -Xmx(最大值)参数手动设置 Heap(堆)的大小
4.4.1.2元空间溢出
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区
别在于:元空间并不在虚拟机中,而是使用本地内存
异常类型:Java.Lang.OutOfMemoryError:Metaspace
优化:通过调整 -XX:MaxMetaspaceSize 设置元空间大小
4.4.1.3栈溢出
栈内存在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配(更准确
地说是保存了引用的堆内存空间的地址,java中的“指针”)
异常类型: java.lang.StackOverflowError
优化:通过Xss参数调整
4.4.2调整JVM参数
#出现OOM则导出heapdump日志
-XX:+HeapDumpOnOutOfMemoryError
# 导出heapdump日志的路径
-XX:HeapDumpPath=d:/tmp/heapdump-%t.hprof
# 打印GC的详细信息
-XX:+PrintGCDetails
# 打印GC的时间戳
-XX:+PrintGCDateStamps
# 打印出幸存区中对象的年龄分布
-XX:+PrintTenuringDistribution
# 打印GC前后堆的概况
-XX:+PrintHeapAtGC
# 打印各种引用的处理时间
-XX:+PrintReferenceGC
#打印 stw 暂停时间,GC 最重要的指标
-XX:+PrintGCApplicationStoppedTime
# GC日志输出位置
-Xloggc:d:/tmp/jvm-%t.log
# 开启日志文件分割
-XX:+UseGCLogFileRotation
# 最多分割几个文件,超过之后从头开始写
-XX:NumberOfGCLogFiles=14
# 每个文件上限大小,超过就触发分割
-XX:GCLogFileSize=100M4.5堆内存
4.5.1heap space
对象过多,并且是GC Root 所以不会被回收
4.5.2GC overhead limit exceeded
当JVM资源利用出现问题时抛出,更具体地说,这个错误是由于JVM花费太长时间执行GC且只能回收很少的堆内存时抛出的。根据Oracle官方文档,默认情况下,如果Java进程花费98%以上的时间执行GC,并且每次只有不到2%的堆被恢复,则JVM抛出此错误。换句话说,这意味着我们的应用程序几乎耗尽了所有可用内存,垃圾收集器花了太长时间试图清理它,并多次失败。在这种情况下,用户会体验到应用程序响应非常缓慢,通常只需要几毫秒就能完成的某些操作,此时则需要更长的时间来完成,这是因为所有的 CPU 正在进行垃圾收集,因此无法执行其他任务。
4.6栈内存
4.6.1StackOverFlowError
栈主要是被线程所使用的,存放着线程上下文的一些数据,这块空间相对堆来说是比较小的,对于栈是有可能出现溢出的,也就是我们熟知的 StackOverFlowError ,接下来用程序来模拟一下此异常,典型发生的场景就是使用不正确的递归
4.6.2OutOfMemoryError
很多人在做多线程开发时,当创建很多线程时,容易出现OOM(OutOfMemoryError),这时可以通过
具体情况,减少最大堆容量,或者栈容量来解决问题,这是为什么呢
下面是整个机器内存的分配情况
线程数*(最大栈容量)+最大堆值+其他内存(忽略不计或者一般不改动)<=机器最大内存
4.6.3unable to create new native thread
这也是常见的OOM类型,当应用程序无法创建新线程时会生成这种类型的异常
JVM 向操作系统申请创建新的 native thread(原生线程)时,就有可能会碰到java.lang.OutOfMemoryError: Unable to create new native thread 错误,如果底层操作系统创建新的 native thread 失败,JVM 就会抛出相应的 OutOfMemoryError。
4.7元空间
4.7.1OutOfMemoryError
这个 java.lang.OutOfMemoryError:Metaspace 表示为Java类元数据分配的本机内存量已被耗尽
-XX:MetaspaceSize=1024m
-XX:MaxMetaspaceSize=1024mnohup java -jar -XX:MetaspaceSize=100m -XX:MaxMetaspaceSize=100m spring-boottest-1.0-SNAPSHOT.jar &

















 152
152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









