










一、爬虫常用的库
import requests
from bs4 import BeautifulSoup
import re
import time
import json
二、使用session
在Python的requests库中,Session是一个对象,它提供了一种将HTTP请求连接到HTTP服务器并保持会话状态的方式。它实现了一个类似于Web浏览器的会话,可以在多个请求之间自动保持cookie。
使用Session对象的优点是可以跨多个请求重用同一个底层TCP连接,从而节省了连接和关闭连接的开销,并且可以共享会话级别的状态和参数,如cookie、HTTP头和SSL证书。这使得处理复杂的Web应用程序和需要进行多个请求的任务变得更加容易和高效。
具体而言,Session对象可以用来完成以下任务:
-
持久化会话: 通过使用Session对象,可以在多个请求之间共享cookies和其他参数,以模拟浏览器在同一会话期间的行为。
-
管理cookies: 通过使用Session对象,可以自动管理cookies。当发送请求时,会自动将服务器返回的cookie保存到Session对象中,然后在后续的请求中发送这些cookie,以维持会话状态。
-
连接池: 通过使用Session对象,可以复用同一个底层的TCP连接,在多个请求之间共享连接,从而减少连接和关闭连接的开销。
-
SSL证书验证: 可以使用Session对象来指定和管理SSL证书,以便在与安全的HTTPS网站通信时进行验证。
总之,Session对象可以帮助简化Web应用程序的测试、自动化、数据抓取和其他类似的任务。
s = requests.session()
commonlogin_url = '真实登录地址'
login_data = {
'uname':'uname',
'password':'passeord',
'refer':'',
't':'true',
'fid':'-1',
'forbidotherlogin': '0'
# validate:
# doubleFactorLogin: 0
# independentId: 0
}
rep_commonlogin=s.post(commonlogin_url,data=login_data,allow_redirects = True)
print(rep_commonlogin.text)
解析:
1、调用session,并实例化s
2、url输入真实的登录地址,登录地址可以通过f12,打开开发者工具,在network的监视下,刷新登录页面,抓包类似login的文件发送的真实登录请求,获取他的url。

3、输入你的data,如果你所登陆的页面密码是加密保存的,可以通过先输入正确账号错误密码,正确密码错误账号的方式,进行二次登录,找到类似fanyaloin的文件,找到对应信息。
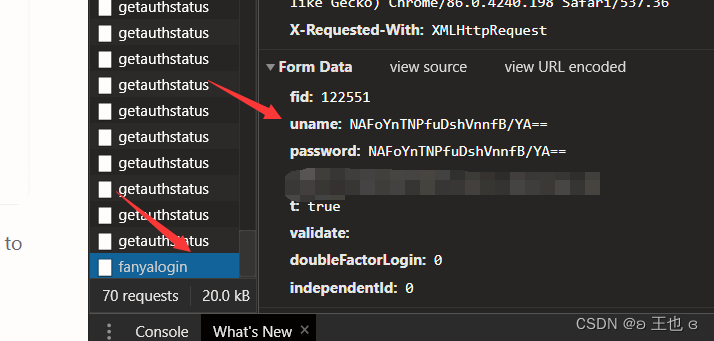
注意,这里的请求是字典形式,他是什么开头,你就要写成什么开头,比如他的键是uname,你的就是uname:你的加密密码;如果键是yourname,同理。
如果你的请求失败,可以尝试把他的get里面所有键都先复制下来,保证你可以访问,然后再删除不需要的请求。
4、.post方法接收加密通信后的发送的请求,并打印他的`.text``文本。如果不再是登录界面,证明你已经登陆成功。在接下来的一段时间内,你可以免登陆去访问网页了。
三、接下来就是(老三件)
1、先建立你的headers
2、利用.get获取url的信息
3、利用BeautifulSoup库解析你的html
4、.find_all方法获取你想要的某个类的某个标签的所有信息
5、建立空列表,利用for循环的方式和+ str()依次拼接你想要访问的页面链接,把拼接好的url存储到建立的空列表中。
从html里面获取你想要的信息,可以使用正则表达式,如果是一个键后面完整的数据,就不需要那么麻烦,直接读取就行。
6、经过页面的跳转,继续.get你想要访问页面,重复2-6的过程,直到找到最终页面
注意,你要访问的页面一定不是一蹴而就的,需要多次get请求,然后进入到最终页面才能找到你想啊哟的信息。
提示:每个人想要爬取的页面不同,这里只能提供思路,有不会的地方可以私信我。
7、爬取的时候,注意sleep不然可能会被检测出来
time.sleep(5)
8、如果你找到了你想要数据所在的页面,爬取到了js里面的代码,注意使用以下函数解析字符串:
status_json=json.loads(status_json)
一定要注意,此时你找到的是字符串,需要使用loads改变成数据框的形式。
9、获得你想要的的链接后,根据抓包,找到要拼接的真实地址,利用上述提到的方法拼接,得到完整的url(此时你可以手点,在浏览器下载),也可以使用for循环,批量下载方法:
with open(path+'/'+filename, 'wb') as f:
# 给一个后缀
f.write(rep_download.content)














 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









