






管道的概述
在Linux的日常使用中,我们常常会用到管道。竖线“ | ”就是一个管道,它会将前一个命令的输出,作为后一个命令的输入。从管道的这个名称可以看出来,管道是一种单向传输数据的机制,它其实是一段缓存,里面的数据只能从一端写入,从另一端读出。
管道的实现原理
相关函数
-
fork()
pid_t fork(void);fork()可以用来新建进程,实际上是创建一个原进程的拷贝,包括文件描述符、寄存器值、缓冲区等,子进程和父进程互不相关,如果一个进程的变量发生变化,并不会影响另一个进程。
-
pipe()
int pipe(int fd[2]);pipe函数定义中的fd参数是一个大小为2的数组类型指针。通过pipe函数创建的这两个文件描述符fd[0]和fd[1]分别构成管道的两端,并且fd[1]一端只能进行写操作,fd[0]一端只能进行读操作。
实现步骤
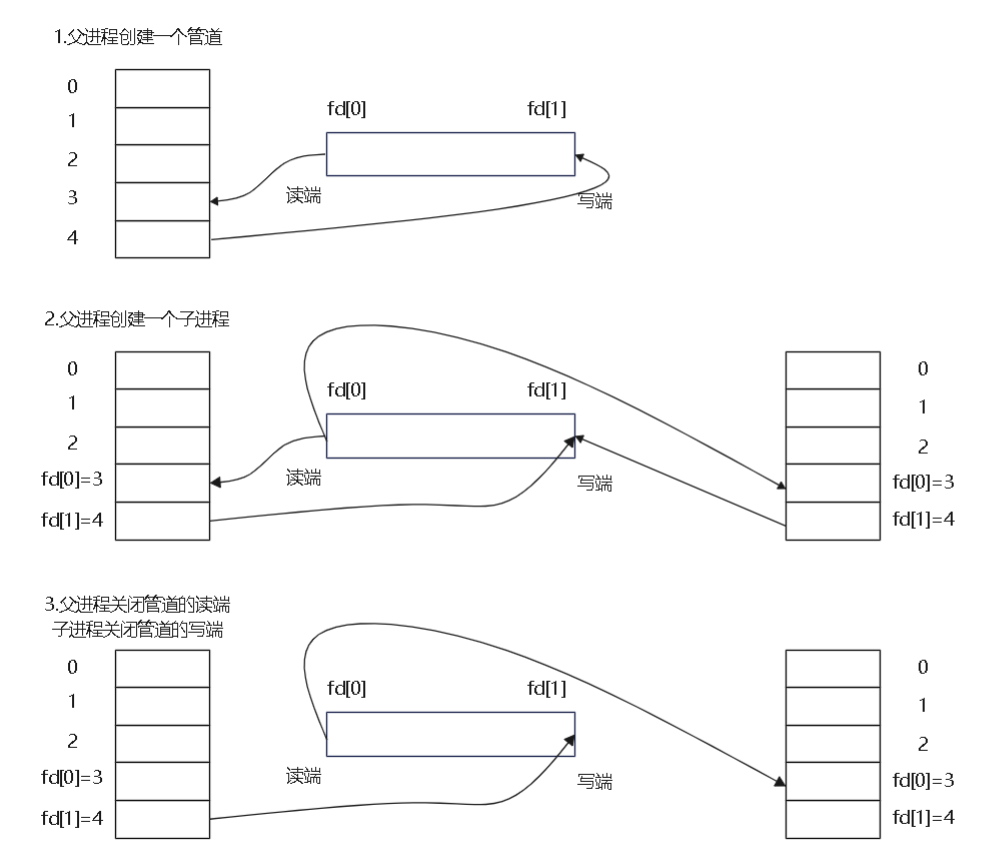
- 父进程调用pipe创建管道,得到两个文件描述符指向管道的两端。
- 父进程调用fork创建子进程,那么子进程也有两个文件描述符指向同一管道。
- 父进程关闭管道读端,子进程关闭管道写端。父进程可以往管道里写,子进程可以从管道里读,管道是用环形队列实现的,数据从写端流入从读端流出,这样就实现了进程间通信。
代码实现
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(int argc, char **argv)
{
int pipefd[2];
char buf[50], msg[50]; // 定义一个缓冲区
pid_t pid = 0;
pipe(pipefd); // 创建一个管道
if (fork() == 0) // 子进程
{
close(pipefd[1]); // 子进程关闭写端
read(pipefd[0], buf, 50); // 将读取到的数据写入缓冲区
printf("子进程读取到的数据:%s\n", buf);
}
else // 父进程
{
close(pipefd[0]); // 父进程关闭读端
pid = getpid(); // 得到父进程的pid
char *str = "This hello form father process: ";
sprintf(msg, "%s%d", str, pid);
write(pipefd[1], msg, strlen(msg)); // 向管道的读端写入数据
}
wait(NULL);
return 0;
}
运行结果如下:

尽管和真正的Unix操作系统的管道源代码有很大差距,但是以上代码也算是实现了管道的基本原理。
总结
- 当你在Linux的终端上输入一串包含管道符“ | ”的命令的时候,在按下回车键以后,shell回去解析这段命令,当识别到“ | ”的时候,就会创建一个管道和一个子进程,通过对管道描述符的打开和关闭,实现了将父进程的命令执行结果作为标准输出,通过管道,将结果作为标准输入,传递给子进程。
- 所以Linux当中的管道符就是一种进程间通信(IPC)的实例。其他的进程间通信方法有内存共享和消息队列。
- 特点:虽然管道是单向通信的,而且还会存在缓冲区大小的限制,但是管道实现起来是最简单的。
- 如果只考虑两个进程之间的通信,管道的通信效率无疑是最高的。像基于内存共享的进程间通信由于要考虑到信号量这些同步机制,这会让两个进程之间通信的效率下降。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









