







写在前面:
对于中文的检错,列数Col的值可能存在问题,原因好像是最后一个字符会读很多次?
对于中文的检错:一个中文字符的编码是两个字节,每个字节都是以1开头(ancil码都是以0开头的)
文件结构:
源码: (LA.h)
/**
* @filename: LA.cpp
* @author 张大仙 1607212422@qq.com
* @brief 词法分析函数
* @version
* @date 2022-09-19
*
*
*/
/**
* COP compare operator 比较符
* AOP assignment operator 赋值符
* OOP operation operator 操作符
* EOP end operator 结束符
* SOP separate operator 分隔符
*/
#include <iostream>
#include <fstream>
#include <string>
#include <cstring>
using namespace std;
int Row, Col; // 行列标记
FILE *in_file = fopen("D:\\vscodeworkspacde\\test\\infile1_for_LA.txt", "r"); //尽量学着用绝对路径
fstream out_file("D:\\vscodeworkspacde\\test\\outfile1_for_LA.txt", ios::out);
const string Key[] = {
"", "program", "const", "var", "procedure", "begin", "if",
"else", "end", "while", "call", "read", "write", "then", "odd", "do"}; // 定义关键字,第一个是占位符,无实际意义
/**
* @brief 判断是不是空格 \t \r \n 如果是相应的 Row和Col会做出相应的变化
* @param ch
* @return true
* @return false
*/
bool isBC(char ch)
{
if (ch == ' ')
{ // 空格
Col++;
return true;
}
else if (ch == '\t')
{ // tab
Col += 4;
return true;
}
else if (ch == '\r' || ch == '\n') // 回车
{
Row++;
Col = 1;
return true;
}
else
{
return false;
}
}
/**
* @brief 把ch连接到strToken
*
* @param strToken
* @param ch
*/
void Concat(string &strToken, char ch)
{
strToken.push_back(ch);
}
/**
* @brief 如果ch是一个A-Za-z的就返回ture
*
* @param ch
* @return true
* @return false
*/
bool IsLetter(char ch)
{
if (ch >= 'a' && ch <= 'z')
{
return true;
}
else if (ch >= 'A' && ch <= 'Z')
{
return true;
}
else
return false;
}
/**
* @brief 如果是一个0-9的数字返回ture
*
* @param ch
* @return true
* @return false
*/
bool IsDigit(char ch)
{
if (ch >= '0' && ch <= '9')
{
return true;
}
else
return false;
}
/**
* @brief 如果是Key中的系统保留字 返回其下标
*
* @param strToken
* @return int
*/
int Reserve(string strToken)
{
for (int i = 1; i <= 15; i++)
{
if (strToken == Key[i])
{
return i;
}
}
return 0;
}
/**
* @brief 如果不是EOF 将ch退回到读入流中去
*
* @param ch
*/
void Retract(char ch)
{
if (ch != EOF)
{
ungetc(ch, in_file);
}
}
/**
* @brief 词法分析实现函数
*
* @return int
*/
int LA()
{
if (!in_file)
{
cout << "输入文件打开失败" << endl;
exit(1);
}
if (!out_file.is_open())
{
cout << "输出文件打开失败" << endl;
exit(2);
}
Row = Col = 1;
string strToken = "";
char ch; //从缓冲区读进来的字符
while (1)
{
ch = fgetc(in_file);
if (ch == EOF || feof(in_file))
break;
// 1.判断是否为空白
if (isBC(ch))
{
strToken = "";
}
// 2.判断是否为字母
else if (IsLetter(ch))
{
//将所有字符连接起来
while (IsDigit(ch) || IsLetter(ch))
{
Concat(strToken, ch);
Col++;
ch = fgetc(in_file);
}
//判断是关键字还是ID
if (Reserve(strToken))
{
out_file << strToken << " RESERVED " << Row << ' ' << Col << endl;
}
else
{
out_file << strToken << " id " << Row << ' ' << Col << endl;
}
strToken = "";
Retract(ch); //别忘了把刚才不满足while的那个字退回到读入流中
}
// 3.判断是否为数字
else if (IsDigit(ch))
{
//将所有数字连接起来
while (IsDigit(ch))
{
Concat(strToken, ch);
Col++;
ch = fgetc(in_file);
}
//以数字开头的ID,报错!
if (IsLetter(ch))
{
//继续读完字符串
while (IsLetter(ch) || IsDigit(ch))
{
Concat(strToken, ch);
Col++;
ch = fgetc(in_file);
}
cout << "[Lexical ERROR]"
<< " [" << Row << "," << Col << "] "
<< "Invalid ID: " << strToken << endl;
out_file << strToken << " id " << Row << ' ' << Col << endl;
}
else
{
out_file << strToken << " INT " << Row << ' ' << Col << endl;
}
Retract(ch);
strToken = "";
}
// 4.判断是否为中文字符
else if (ch & 0x80)
{
ch = fgetc(in_file);
if (ch & 0x80 && ch != -1)
{
cout << "在" << Row << "行" << Col << "列"
<< "出现一个中文字符,出错了" << endl;
Col += 1;
}
else
{
Retract(ch);
}
}
// 5.判断是否为其他字符
else
{
if (ch == '=')
{
Col++;
out_file << ch << " COP " << Row << ' ' << Col << endl;
}
else if (ch == '<')
{
Col++;
ch = fgetc(in_file);
if (ch == '>')
{
Col++;
out_file << "<> COP " << Row << ' ' << Col << endl;
}
else if (ch == '=')
{
Col++;
out_file << "<= COP " << Row << ' ' << Col << endl;
}
else
{
out_file << "< COP " << Row << ' ' << Col << endl;
Retract(ch);
}
}
else if (ch == '>')
{
Col++;
ch = fgetc(in_file);
if (ch == '=')
{
Col++;
out_file << ">= COP " << Row << ' ' << Col << endl;
}
else
{
out_file << "> COP " << Row << ' ' << Col << endl;
Retract(ch);
}
}
else if (ch == ':')
{
Col++;
ch = fgetc(in_file);
if (ch == '=')
{
Col++;
out_file << ":= AOP " << Row << ' ' << Col << endl;
}
else
{
cout << "[LEXICAL ERROR]"
<< " [" << Row << "," << Col << "] "
<< "Missing \"=\" near the \":\" " << endl;
out_file << ":= AOP " << Row << ' ' << Col << endl;
Retract(ch);
}
}
else if (ch == '+' || ch == '-' || ch == '*' || ch == '/')
{
Col++;
out_file << ch << " OOP " << Row << ' ' << Col << endl;
}
else if (ch == ';')
{
Col++;
out_file << ch << " EOP " << Row << ' ' << Col << endl;
}
else if (ch == '(' || ch == ')' || ch == ',' || ch == '.')
{
Col++;
out_file << ch << " SOP " << Row << ' ' << Col << endl;
}
else
{
Col++;
out_file << ch << " UNKNOWN " << Row << ' ' << Col << endl;
}
}
}
fclose(in_file);
out_file.close();
printf("-----词法分析已完成,结果存至out_file.txt文件中-----\n");
return 0;
}
最后:
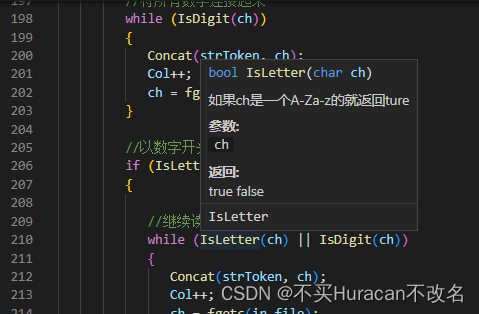
鼠标悬浮在函数上会自动出现注释,原因是使用了插件
使用方法见另一篇文章头部注释插件使用![]() https://mp.csdn.net/mp_blog/creation/editor/126925377
https://mp.csdn.net/mp_blog/creation/editor/126925377














 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









