







本篇博客首先讲述Opencv库中MOG和MOG2的来源,然后对MOG2的一篇论文进行翻译。
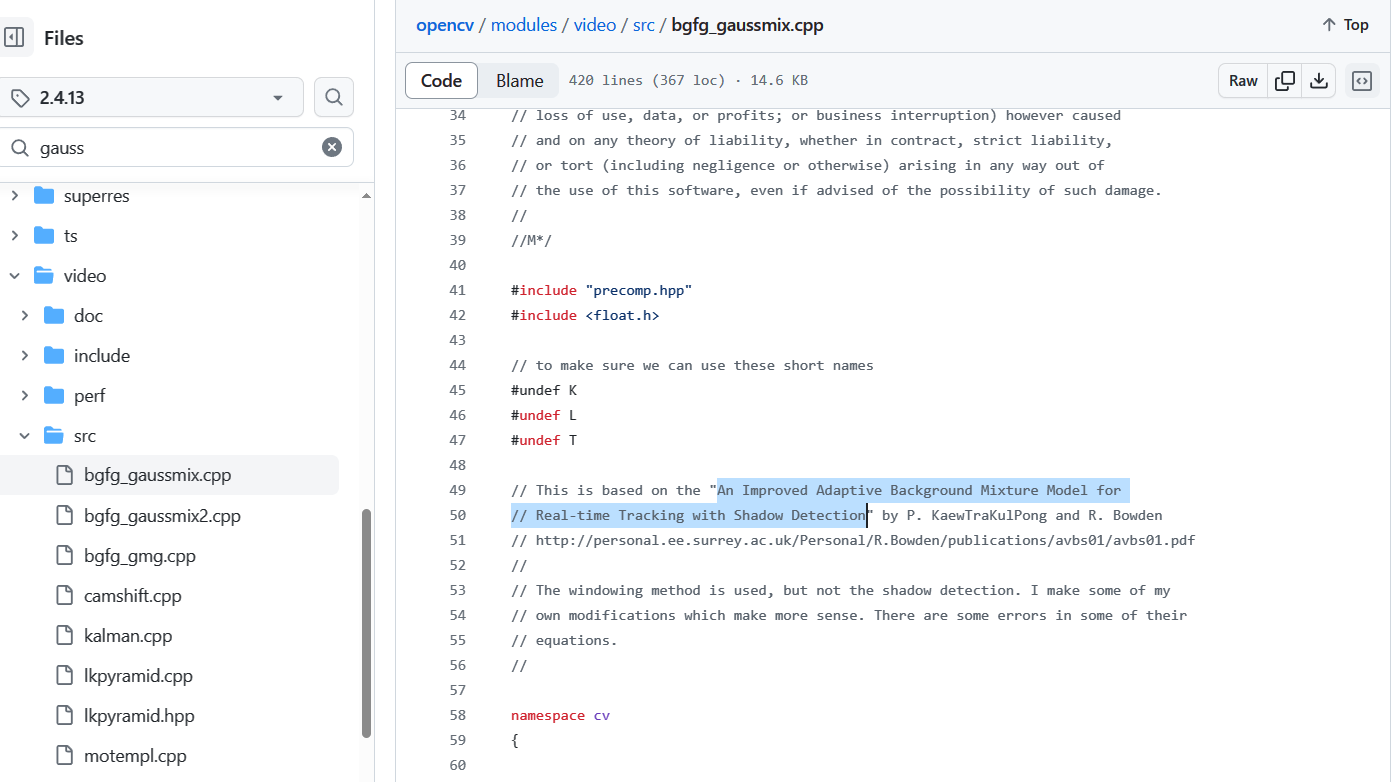
图1. OpenCV官网 MOG 算法来自一篇论文:
An Improved Adaptive Background Mixture Model for Real-time Tracking with Shadow Detection.
一种用于阴影检测实时跟踪的改进自适应背景混合模型
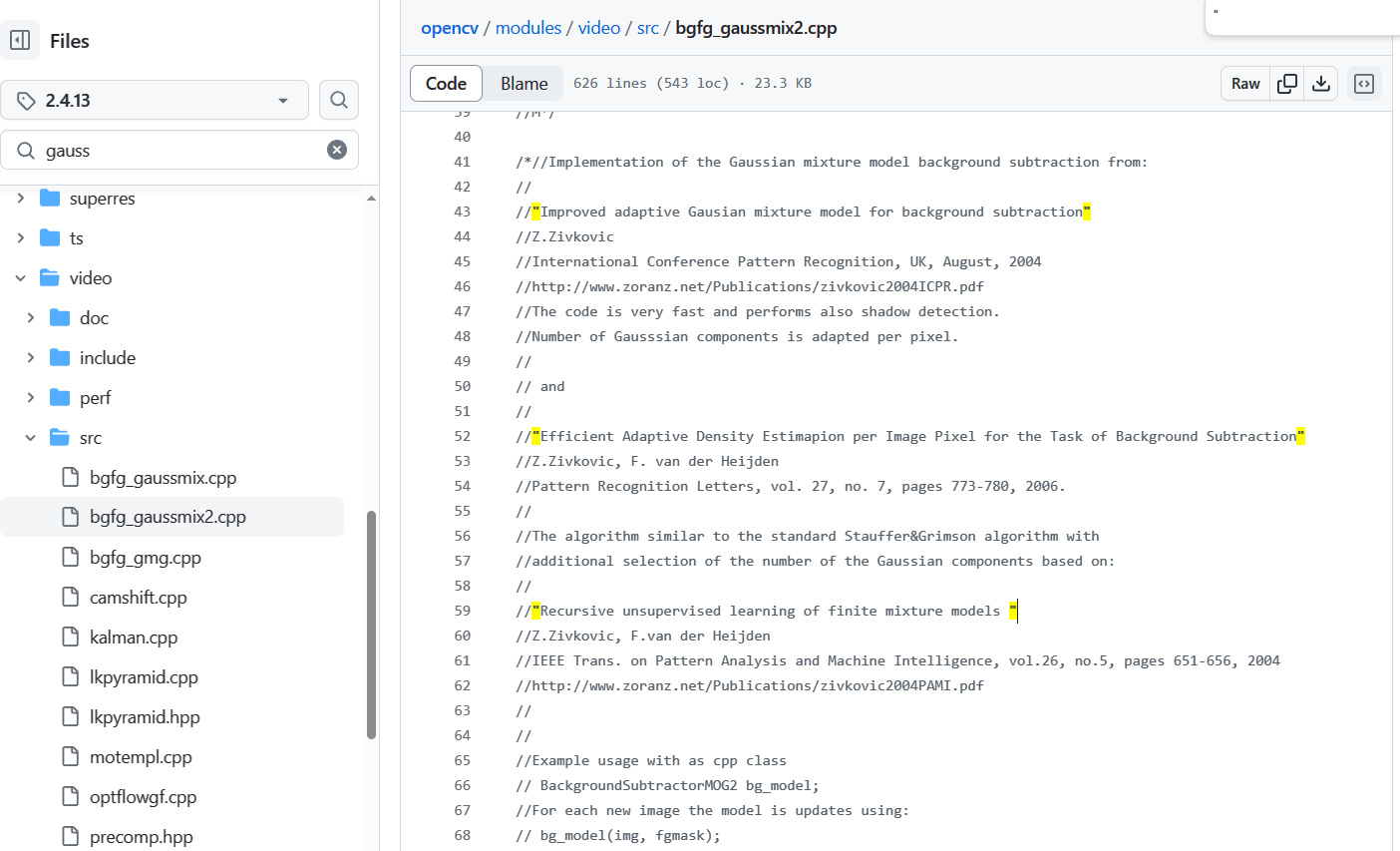
图2. OpenCV官网 MOG2 算法来自三篇论文:
Improved Adaptive Gaussian Mixture Model for Background Subtraction.
一种改进的自适应高斯混合背景相减模型
Efficient Adaptive Density Estimapion per Image Pixel for the Task of Background Subtraction.
用于背景减法任务的每个图像像素的高效自适应密度估计
Recursive unsupervised learning of finite mixture models.
有限混合模型的递归无监督学习
- MOG 算法:使用窗口化方法,但不使用阴影检测。
- MOG2 算法:该代码非常快速,还可以执行阴影检测。
Improved Adaptive Gaussian Mixture Model for Background Subtraction
一种改进的自适应高斯混合背景相减模型
摘要
背景减法是一项常见的计算机视觉任务。我们分析通常的像素级方法。我们使用高斯混合概率密度开发了一种有效的自适应算法。递归方程用于不断更新参数,而且还用于同时为每个像素选择适当数量的分量。
结论
我们提出了一种改进的GMM背景相减方案。新算法可以自动选择每个像素所需的分量数量,并以这种方式完全适应观察到的场景。处理时间减少,但分割也略有改进。
1. 介绍
静态摄像机观察场景是监控系统的常见情况。检测入侵物体是分析场景的重要步骤。一个通常适用的假设是,没有跋涉物体的场景图像表现出一些可以用统计模型描述的规则行为。如果我们有一个场景的统计模型,可以通过发现图像中不符合模型的部分来检测入侵物体。这个过程通常被称为“背景减法”。应用了一种常见的自下而上的方法,并且场景模型分别具有每个像素的概率密度函数。如果新图像中的像素的新值由其密度函数很好地描述,则将其视为背景像素。对于静态场景,最简单的模型可能只是没有入侵对象的场景图像。下一步将是例如估计来自图像的像素强度水平的方差的适当值,因为方差可以随像素而变化。[1]中使用了这种单一的高斯模型。然而,10的像素值具有复杂的分布,需要更精细的模型。[2]中提出了高斯混合模型(GMM)用于背景相减。[3]中介绍了更新GMM的最常用方法之一,[10]中对此进行了进一步阐述。这些GMM使用一定数量的组件。我们在[12]的最新结果的基础上提出了一种改进的算法。不仅参数,而且混合的分量数量都会不断地适应每个像素。通过在线过程中选择每个像素的分量数量,该算法可以自动完全适应场景。
本文组织如下。在下一节中,我们将列出一些相关的工作。在第3节中,回顾了[3]中的GMM方法。在第4节中,我们介绍了如何在线选择组件的数量以及如何改进算法。在第5节中,我们介绍了一些实验。
- [1] C.R.Wren,A.Azarbayejani,T.Darrell,and A.Pentland,“Pfinder:Real-time tracking of the human body,”IEEE Trans.on PAMI,vol.19,no.7,pp.780–785,1997.
- [2] N.Friedman and S.Russell,“Image segmentation in video sequences: A probabilistic approach,”In Proceedings ThirteenthConf.on Uncertainty in Artificial Intelligence,1997.
- [3] C.Stauffer and W.Grimson,“Adaptive background mixture models for real-time tracking,”In Proceedings CVPR,pp.246–252,1999.(GMM)
- [10] E.Hayman and J.Eklundh,“Statistical Background Subtraction for a Mobile Observer”,In Proceedings ICCV,2003.
- [12] Z.Zivkovic and F.van der Heijden,“Recursive UnsupervisedLearning of Finite Mixture Models”,IEEE Trans.on PAMI,vol.26.,no.5,2004.
2. 相关工作
RGB或某些其他颜色空间中的像素在时间t的值由![]() 表示。基于像素的背景相减涉及决定像素是属于背景(background, BG)还是某个前景对象(foreground, FG)。贝叶斯决策 R 是通过以下方式作出的:
表示。基于像素的背景相减涉及决定像素是属于背景(background, BG)还是某个前景对象(foreground, FG)。贝叶斯决策 R 是通过以下方式作出的:
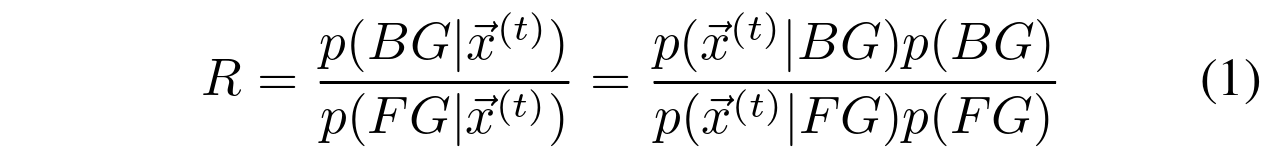
背景减法的结果通常被传播到一些更高级别的模块,例如,检测到的对象经常被跟踪。在跟踪对象时,我们可以获得一些关于被跟踪对象外观的知识,这些知识可以用于改进背景减法。例如在[7]和[8]中对此进行了讨论。在一般情况下,我们对可以看到的前景对象一无所知,也不知道它们何时以及多久出现一次。因此,我们设置![]() ,并假设前景对象外观的均匀分布
,并假设前景对象外观的均匀分布![]() 。然后我们决定像素属于背景,如果:
。然后我们决定像素属于背景,如果:
![]()
其中 是阈值。我们将把
![]() 称为背景模型。背景模型是从表示为 X 的训练集来估计的。估计的模型由
称为背景模型。背景模型是从表示为 X 的训练集来估计的。估计的模型由![]() 表示,并且取决于明确表示的训练集。我们假设样本是独立的,主要问题是如何有效地估计密度函数并使其适应可能的变化。[4]中使用了基于Ker-nel的密度估计,我们在这里对[3]中的GMM进行了改进。文献中有一些模型考虑了图像序列的时间方面,并且决策也取决于序列中先前的像素值。例如,在[5,11]中,像素值随时间的分布被建模为自回归过程。在[6]中使用了隐马尔可夫模型。然而,这些方法通常要慢得多,而且很难适应场景的变化。
表示,并且取决于明确表示的训练集。我们假设样本是独立的,主要问题是如何有效地估计密度函数并使其适应可能的变化。[4]中使用了基于Ker-nel的密度估计,我们在这里对[3]中的GMM进行了改进。文献中有一些模型考虑了图像序列的时间方面,并且决策也取决于序列中先前的像素值。例如,在[5,11]中,像素值随时间的分布被建模为自回归过程。在[6]中使用了隐马尔可夫模型。然而,这些方法通常要慢得多,而且很难适应场景的变化。
另一个相关主题是阴影检测。侵入的物体会在背景上投射阴影。通常,我们只对物体感兴趣,并且应该检测与阴影相对应的像素[9]。在本文中,我们分析了唯一基于基本像素的背景相减。对于各种应用程序,上述的一些附加方面和一些后处理步骤可能很重要,并可能导致改进,但这超出了本文的范围。
3. 高斯混合模型
在实践中,场景中的照明可以逐渐变化(室外场景中的白天或天气条件)或突然变化(室内场景中的切换光照)。可以将新对象带入场景,也可以将当前对象从中移除。为了适应变化,我们可以通过添加新样本和丢弃旧样本来更新训练集。我们选择一个合理的时间段T,在时间T,我们有![]() 。对于每个新样本,我们更新训练数据集
。对于每个新样本,我们更新训练数据集![]() 并重新估计
并重新估计![]() 。然而,在来自历史的样本中,可能有一些值属于前景对象,我们应该将该估计表示为
。然而,在来自历史的样本中,可能有一些值属于前景对象,我们应该将该估计表示为![]() 。我们使用带有M个组件的GMM:
。我们使用带有M个组件的GMM:
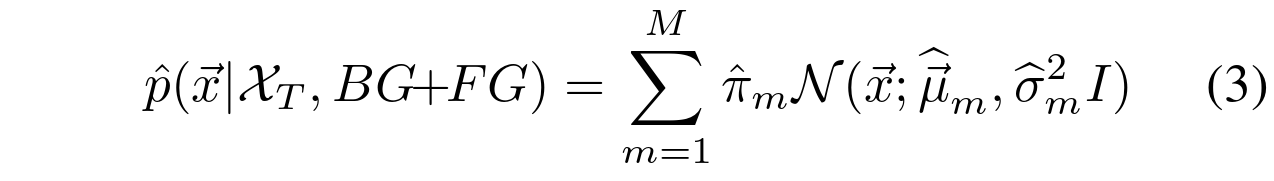
其中![]() 是高斯分布均值的估计值;
是高斯分布均值的估计值;![]() 是描述高斯分分布方差的估计值。假设协方差矩阵是对角的,并且单位矩阵 I 具有适当的维数。由
是描述高斯分分布方差的估计值。假设协方差矩阵是对角的,并且单位矩阵 I 具有适当的维数。由![]() 表示的混合权重是非负的,并且加起来为1。给定在时间t的新数据样本
表示的混合权重是非负的,并且加起来为1。给定在时间t的新数据样本![]() , 递归更新方程如下:
, 递归更新方程如下:
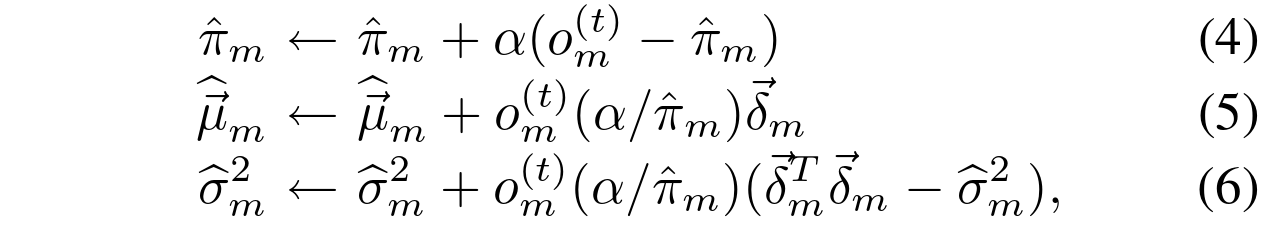
其中,![]() 。这里的常数 α 描述了一个指数衰减包络,用于限制旧数据的影响,而不是上面提到的时间间隔 T。我们记住了相同的符号,大约 α = 1/T。对于一个新的样本,对于具有最大
。这里的常数 α 描述了一个指数衰减包络,用于限制旧数据的影响,而不是上面提到的时间间隔 T。我们记住了相同的符号,大约 α = 1/T。对于一个新的样本,对于具有最大![]() 的“闭合”分量,所有权
的“闭合”分量,所有权![]() 被设置为1,而其他分量被设置为0。例如,如果样品与组件的马氏距离小于三个标准偏差,则我们确定样品与组件“接近”。距离第m个分量的平方距离计算为:
被设置为1,而其他分量被设置为0。例如,如果样品与组件的马氏距离小于三个标准偏差,则我们确定样品与组件“接近”。距离第m个分量的平方距离计算为:![]() 。如果不存在“闭合”分量,则生成一个新的分量,其中
。如果不存在“闭合”分量,则生成一个新的分量,其中![]() and
and![]() ,其中
,其中![]() 是一些适当的初始方差。如果达到分量的最大数量,我们丢弃具有最小
是一些适当的初始方差。如果达到分量的最大数量,我们丢弃具有最小![]() 的分量。
的分量。
补充知识点: 包络是由许多椭圆形曲线交织而成的一种图形,外观看起来是包起来的一样。
该算法提出了一种在线聚类算法。通常,入侵的前景对象将由一些具有小权重的附加簇![]() 表示。因此,我们可以通过前 B 个最大的聚类来近似背景模型:
表示。因此,我们可以通过前 B 个最大的聚类来近似背景模型:
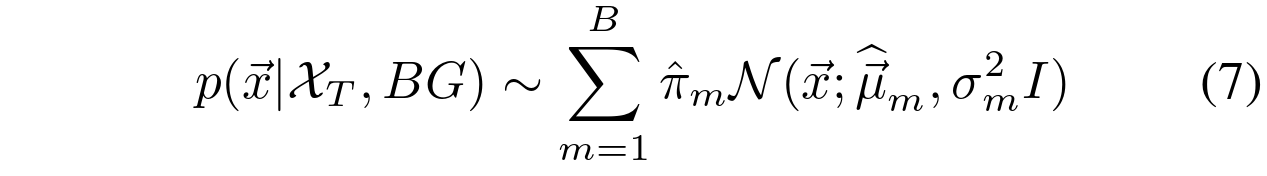
如果分量被排序为具有递减权重![]() ,则我们有:
,则我们有:
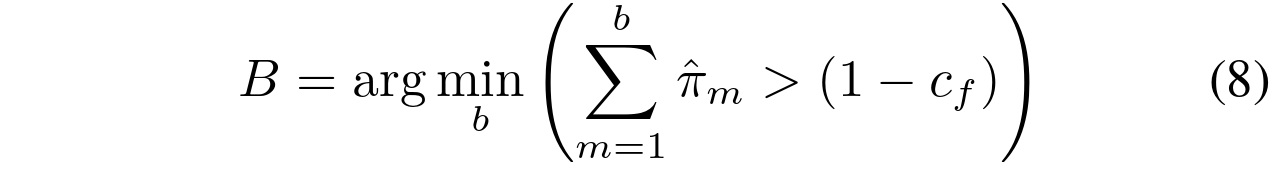
其中 是在不影响背景模型的情况下可以属于前景对象的数据的最大部分的度量。例如,如果一个新对象进入场景并在一段时间内保持静止,它可能会生成一个额外的稳定簇。由于旧的背景被遮挡,新簇的权重
将不断增加。如果对象保持静止足够长的时间,其重量将大于
,并且可以认为它是背景的一部分。如果我们看(4),我们可以得出结论,对于大约
![]() 帧,对象应该是静态的。例如,对于
帧,对象应该是静态的。例如,对于 和
,我们得到105帧。
4. 选择组件数量
权重![]() 描述了有多少数据属于GMM的第m个分量。它可以被视为样本来自第m个分量的概率,通过这种方式,
描述了有多少数据属于GMM的第m个分量。它可以被视为样本来自第m个分量的概率,通过这种方式,![]() 定义了一个潜在的多项式分布。让我们假设我们有t个数据样本,每个样本都属于GMM的一个组件。我们还假设属于第m个分量的样本数量为
定义了一个潜在的多项式分布。让我们假设我们有t个数据样本,每个样本都属于GMM的一个组件。我们还假设属于第m个分量的样本数量为![]() ,其中
,其中![]() 在前一节中定义。假设的
在前一节中定义。假设的![]() 的多项式分布给出了似然函数
的多项式分布给出了似然函数![]() 。混合权重被约束为总和为一。我们通过引入拉格朗日乘数 λ 来考虑这一点。最大似然(ML)估计值如下所示:
。混合权重被约束为总和为一。我们通过引入拉格朗日乘数 λ 来考虑这一点。最大似然(ML)估计值如下所示:![]() 。去掉 λ 后,我们得到:
。去掉 λ 后,我们得到:
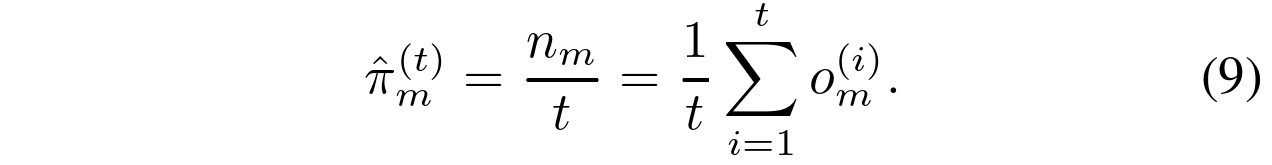
我们表示为 t 样本的估计值为 ![]() ,它可以以递归形式重写为 t−1 样本的估计值
,它可以以递归形式重写为 t−1 样本的估计值![]() 和最后一个样本的所有权
和最后一个样本的所有权 ![]() :
:
![]()
如果我们现在通过将 1/T 固定为 α = 1/T 来计算新样本的影响,我们得到更新方程(4)。新样本的这种固定影响意味着我们更多地依赖新样本,并且旧样本的贡献以指数衰减的方式向下加权,如前所述。
多项式分布的先验知识可以通过使用其共轭先验引入,即狄利克雷先验![]() 。系数
。系数 有一个有意义的解释。对于多项式分布,
表示类别的先验证据(在最大后验(MAP)意义上)m-先验属于该类别的样本数量。我们使用负系数
。负先验证据意味着,只有当数据中有足够的证据证明m类存在时,我们才会接受m类存在。这种类型的先验也与最小消息长度标准有关,该标准用于为给定数据选择适当的模型[12]。包括上述内容的MAP解决方案来自
![]()
![]() ,其中
,其中![]() 。我们得到:
。我们得到:
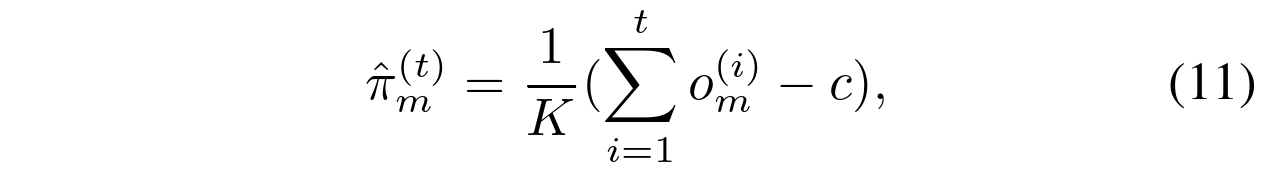
其中![]() 。我们将(11)改写为:
。我们将(11)改写为:
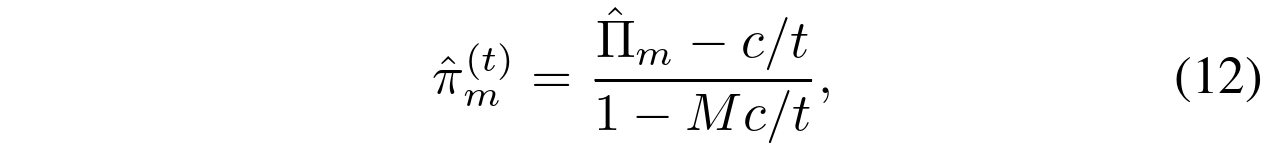
其中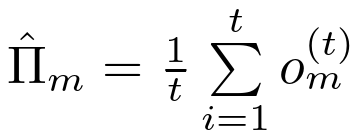 是来自(9)的ML估计,并且通过 c/t 引入来自先验的偏差。数据集越大(t越大),偏差越小。然而,如果一个小的偏差是可以接受的,我们可以通过将
是来自(9)的ML估计,并且通过 c/t 引入来自先验的偏差。数据集越大(t越大),偏差越小。然而,如果一个小的偏差是可以接受的,我们可以通过将 to
与一些大的t相乘来保持它的恒定。这意味着偏差将始终与具有t个样本的数据集相同。很容易证明,具有固定
的(11)的递归版本由下式给出:
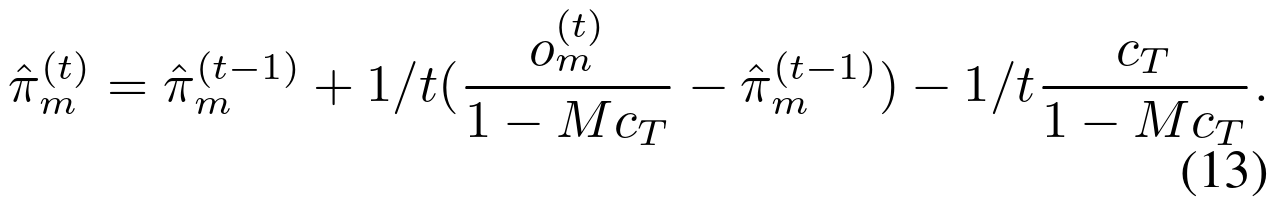
由于我们通常只期望几个分量 M 和 很小,我们假设
![]() 。如前所述,我们将1/t设置为 α,并得到最终修改的自适应更新方程:
。如前所述,我们将1/t设置为 α,并得到最终修改的自适应更新方程:
![]()
使用该方程式代替(4)。每次更新后,我们需要对 ![]() 进行归一化,使它们加起来为一。我们从 GMM 开始,其中一个成分以第一个样本为中心,并添加了新的成分,如前一节所述。具有负权重的狄利克雷先验将抑制数据不支持的分量,并且当分量 m 的权重
进行归一化,使它们加起来为一。我们从 GMM 开始,其中一个成分以第一个样本为中心,并添加了新的成分,如前一节所述。具有负权重的狄利克雷先验将抑制数据不支持的分量,并且当分量 m 的权重![]() 变为负时,我们丢弃它。这也确保了混合权重保持为非负值。对于选定的 α=1/T,我们可以要求至少 c=0.01*T 个样本支持一个组件,我们得到
变为负时,我们丢弃它。这也确保了混合权重保持为非负值。对于选定的 α=1/T,我们可以要求至少 c=0.01*T 个样本支持一个组件,我们得到 。
请注意,由以下公式给出的(11)的直接递归版本不是很有用:![]() 。我们可以从更大的t值开始,以避免对小t进行负更新,但随后我们抵消了先前的影响。这促使我们做出了重要的选择,以弥补先前的影响。
。我们可以从更大的t值开始,以避免对小t进行负更新,但随后我们抵消了先前的影响。这促使我们做出了重要的选择,以弥补先前的影响。
5. 实验
为了分析算法的性能,我们使用了三个动态场景。序列被手动分割以生成地面实况。我们将改进的算法与原始算法进行了比较,其中固定数量的分量 M = 4。对于两种算法和不同的阈值(来自(2)的 ),我们测量了属于正确分配给前景的入侵对象的像素的真阳性百分比和错误分类为前景的背景像素的假阳性百分比。在减少处理时间方面可以观察到很大的改进,如图2所示。报告的处理时间是在2GHz PC上测量的320×240幅图像。在图2中,我们还说明了新算法如何适应场景。右侧图像中的灰度值表示每个像素的组件数量。黑色表示每个像素一个高斯,如果最多使用4个分量,则像素为白色。例如,sequence“lab”是场景中具有滚动干涉条的监视器。现场的植物因风而摇曳。我们看到,动态区域是使用更多组件建模的。因此,处理时间也取决于场景的复杂性。对于高度动态的“三”序列,处理时间几乎与原始算法相同。侵入物体会产生新的组件,这些组件会在一段时间后被移除(见“raf fic”序列),这也影响了处理速度。

每帧平均处理时间:旧: 19.1ms 新: 13.0ms

每帧平均处理时间:旧: 19.3ms 新: 15.9ms

每帧平均处理时间:旧: 19.7ms 新: 19.3ms
图2. 完全适应和处理时间
致谢
本文所述的工作是在欧盟综合项目COGNIRON(“认知伴侣”)中进行的,并由欧盟委员会FP6-IST未来和新兴技术部门根据合同FP6-002020资助。
>>> 如有疑问,欢迎评论区一起探讨。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











