






http 协议基本格式
一、http 是什么?
http 协议是前后端的一个桥梁,想要完成一个网站光写完前端页面还不行,还得需要后端的加持,客户端和服务器之间,是基于网络来进行通信的,而他们两个通信就需要通过http协议来连接,HTTP协议就是常见,也常用的网络通信协议。
- HTTP 协议有个重要的特点就是:一发一收的模式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bEAMvTtI-1648635483067)(https://cdn.jsdelivr.net/gh/power152/Image/202203281750052.png)]](https://img-blog.csdnimg.cn/ea6eacbc6e21489fa0043ffa45116b9c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6bii5Lmf,size_20,color_FFFFFF,t_70,g_se,x_16)
1、客户端:主动发起网络请求的一端;
2、服务器:被动接受网络请求的一端;
3、请求:客户端给服务器发的数据;
4、响应:服务器给客户端返回的数据;
网络编程中,除了一发一收的模式之外,还有其他模式:
1、多发一收:上传大文件;
2、已发多收:看直播;
3、多发到收:串流(steam link,moonlight…)
在应用层上面的协议是有很多种的,such as:DNS,POP,SSH…,但是http协议是非常广泛的应用层协议,这个帖子主要是介绍http协议的基本格式。
二、fiddler使用
要想看到http的基本格式可以借助Chrome浏览器开发者工具自带的功能来看,浏览器和服务器的交互数据,但是这种始终是不完善的。
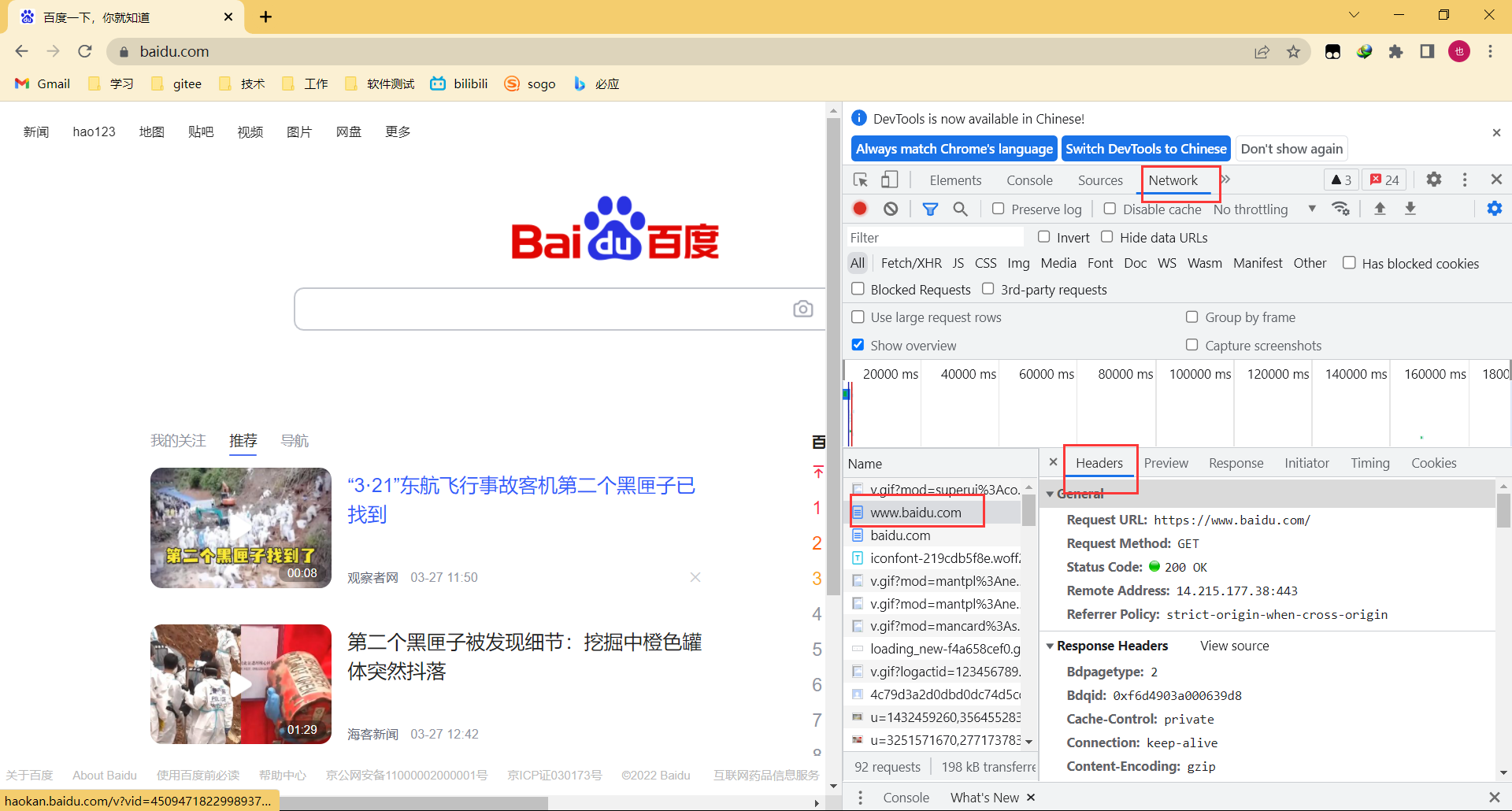
浏览器自带的功能数据并不是很完善所以我们需要用到第三方工具 fiddler 这个工具来抓包,fiddler很好安装直接在官网下载即可。
下载地址: https://www.telerik.com/fiddler/
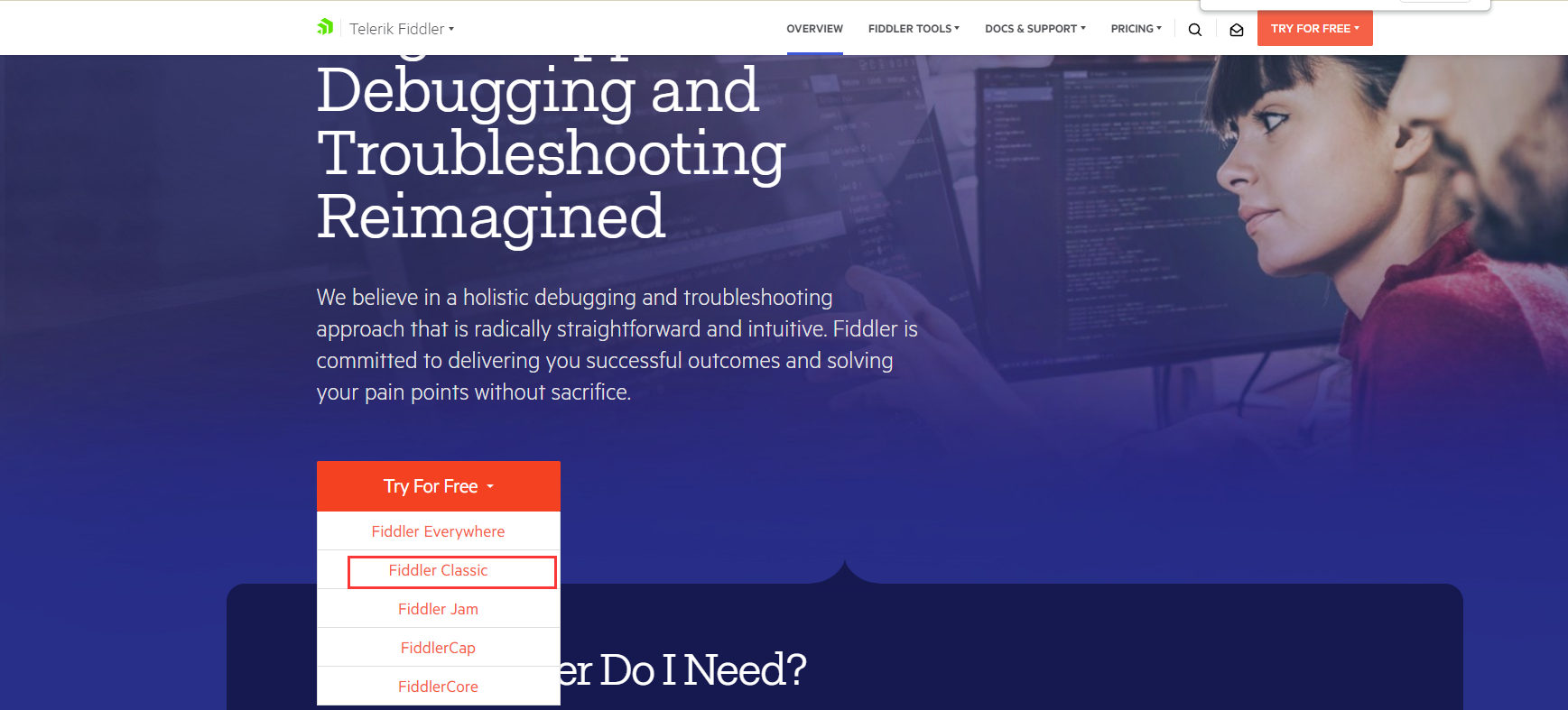
在官网选择经典模式(因为不要钱😁😁😁),安装下载即可。
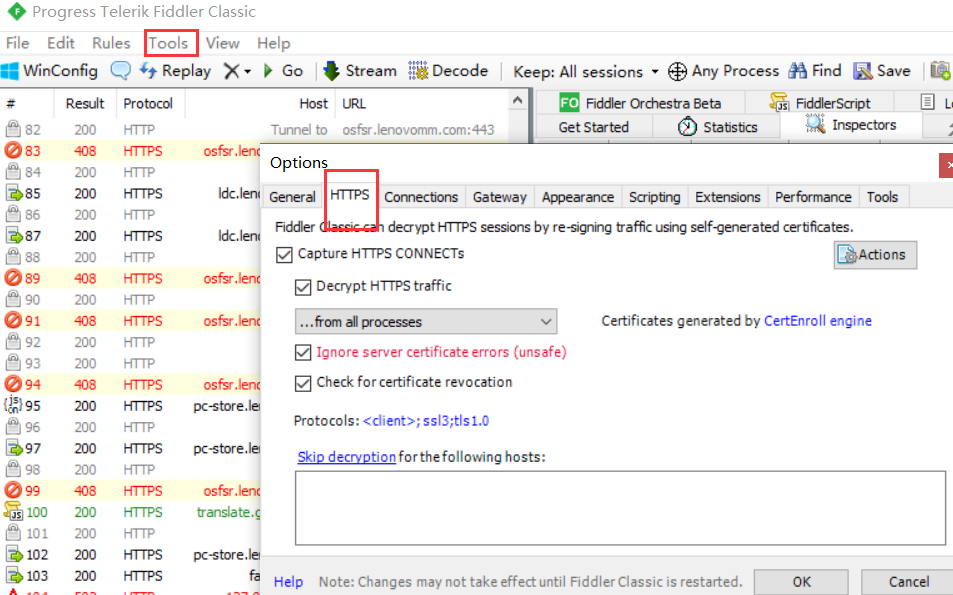
安装好之后先选择tools然后options点击https在找图中内容全选,再安装提示,安装一个证书,由于我已经安装过了就没有弹出证书,同常情况下,跟着提示走会安装一个证书就可以用了。我这里只是简略的说明下安装步骤,详细的大家可以去网上搜索,网上很多关于fiddler的详细安装教程,我这里就不赘述了,下面主要说明下fiddler的使用方法。
2.1 使用
1、首先刚进 fiddler左侧会有东西,把他全部清除掉,再从浏览器地址栏搜索你想要的地址。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d74IaJ40-1648635483069)(https://cdn.jsdelivr.net/gh/power152/Image/202203281749213.png)]](https://img-blog.csdnimg.cn/abe6d77f25944a2fa4072e2e35c67f5f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6bii5Lmf,size_20,color_FFFFFF,t_70,g_se,x_16)
2、此时左侧会有很多选项,选项中字体有一些为蓝色的可能就是我们要抓的包,抓包这种东西得多抓几次才会抓准确,下来自己练习多玩玩就会装包了
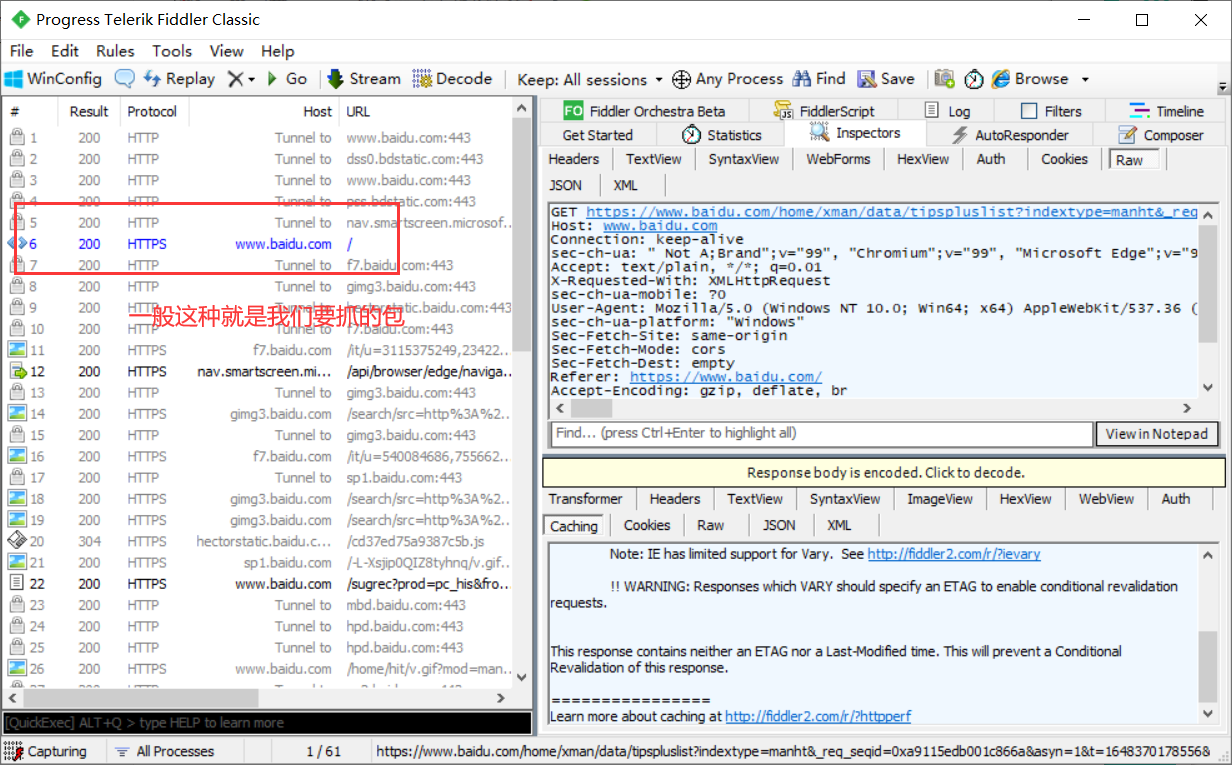
3、请求与响应
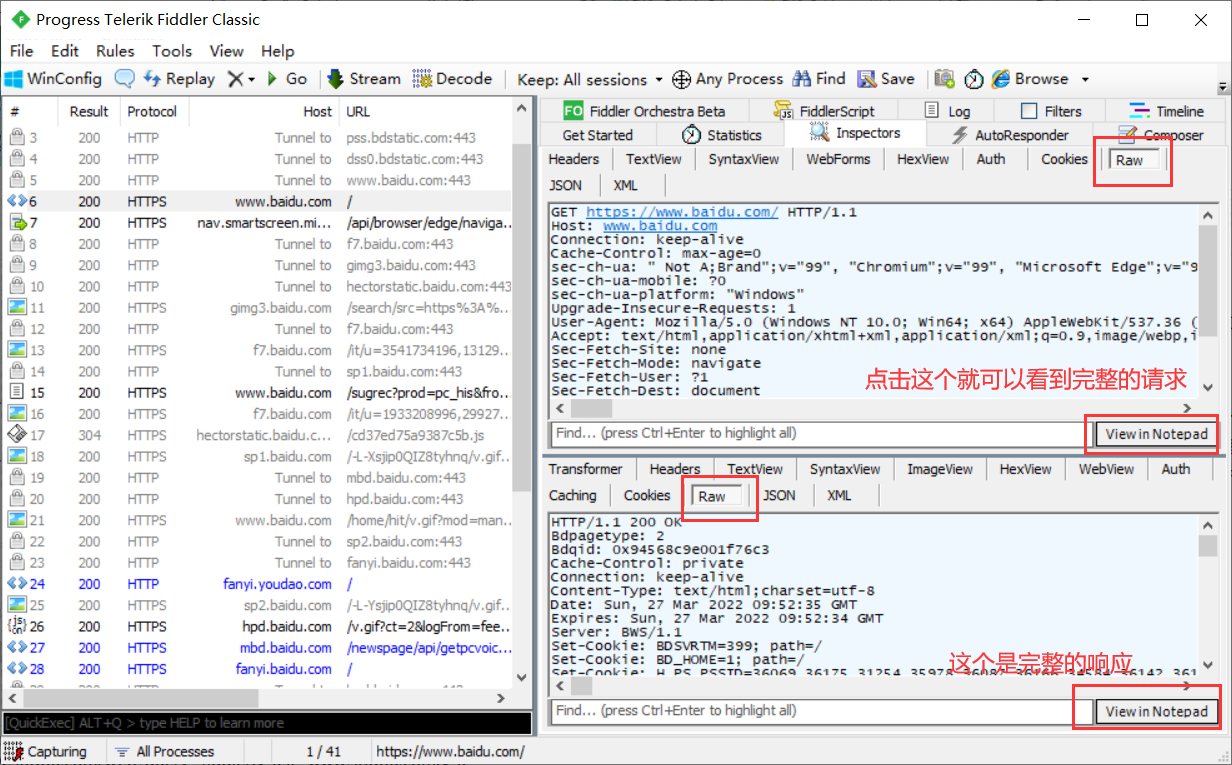
2.2 抓包原理
Fiddler之所以能够获得到这些HTTP请求的详细情况,主要是因为Fiddler相当于一个“代理‘的作用。也可以想象成一个代购,人在中国但是你想买国外的东西,这是后就需要代购了,代购直接在国外买东西,然后给你寄过来,这时候代购的这个人对于你买的东西是一清二楚。Fiddler就相当于中间的代购,浏览器给服务请求发送的数据服务器响应返回的数据,就会被Fiddler给都获取。
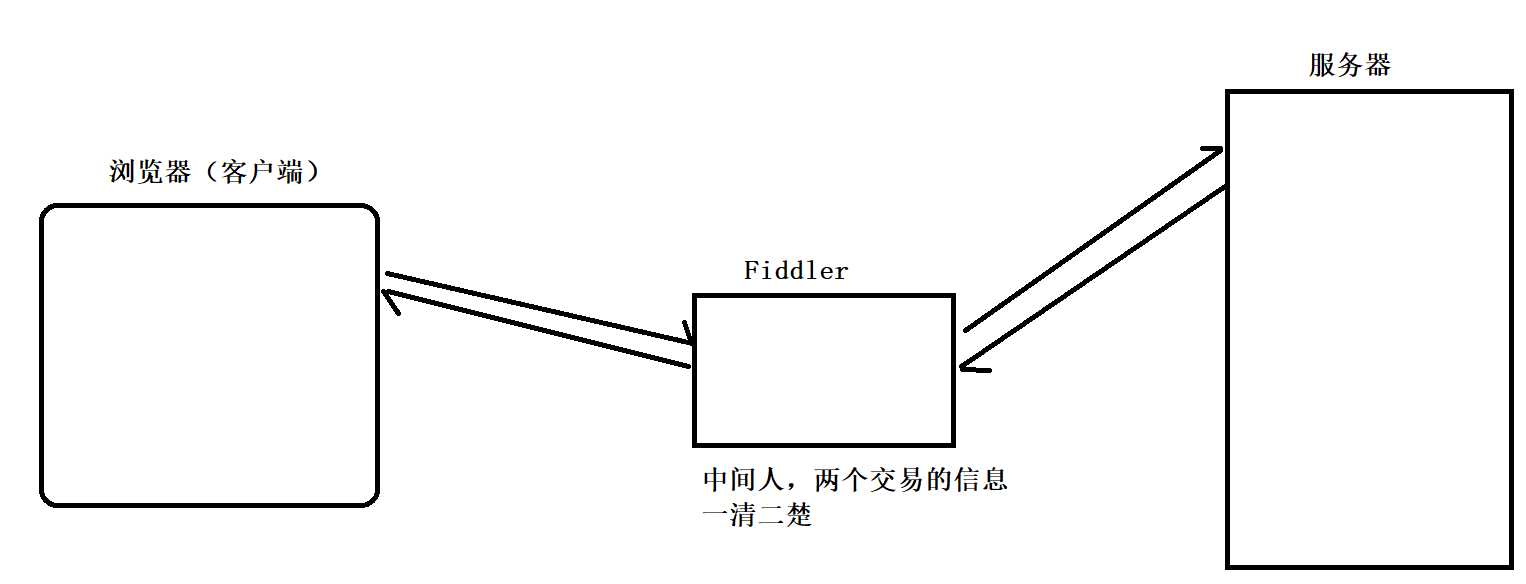
2.3 抓包结果
2.3.1 HTTP请求
POST https://edu.bitejiuyeke.com/tms/login HTTP/1.1
Host: edu.bitejiuyeke.com
Connection: keep-alive
Content-Length: 117
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="99", "Microsoft Edge";v="99"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.52
Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS
Content-Type: application/json;charset=UTF-8
Access-Control-Allow-Origin: *
Accept: application/json, text/plain, */*
Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization, Accept, X-Requested-With , yourHeaderFeild
sec-ch-ua-platform: "Windows"
Origin: https://edu.bitejiuyeke.com
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://edu.bitejiuyeke.com/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
{"username":"132424328182","password":"Zo/BAcYpgdfsgsMg9yPf/nM2g==","uuid":"e04184dbda5d45ad9991b2a8b1dbd639","status":0}
1、首行
POST https://edu.bitejiuyeke.com/tms/login HTTP/1.1
方法+URL+版本号
2、协议头(header)
从 Host 开始,遇到空行结束
协议头里面是“键值对”结构,每个键值对占一行,每个键和值之间使用 冒号空格 来分割。
3、空行
空行是协议头的结束标记。
4、协议正文(body)
空行后面的部分,有的请求是有的body的,有的没有,我这上面的百度就没有。body是允许为空字符串的,正文的话大部分是有多种格式,其中就有json格式(这上面我抓的包不是),不知道json格式,可以看看,我之前写的 json基本用法。
2.3.2 http响应
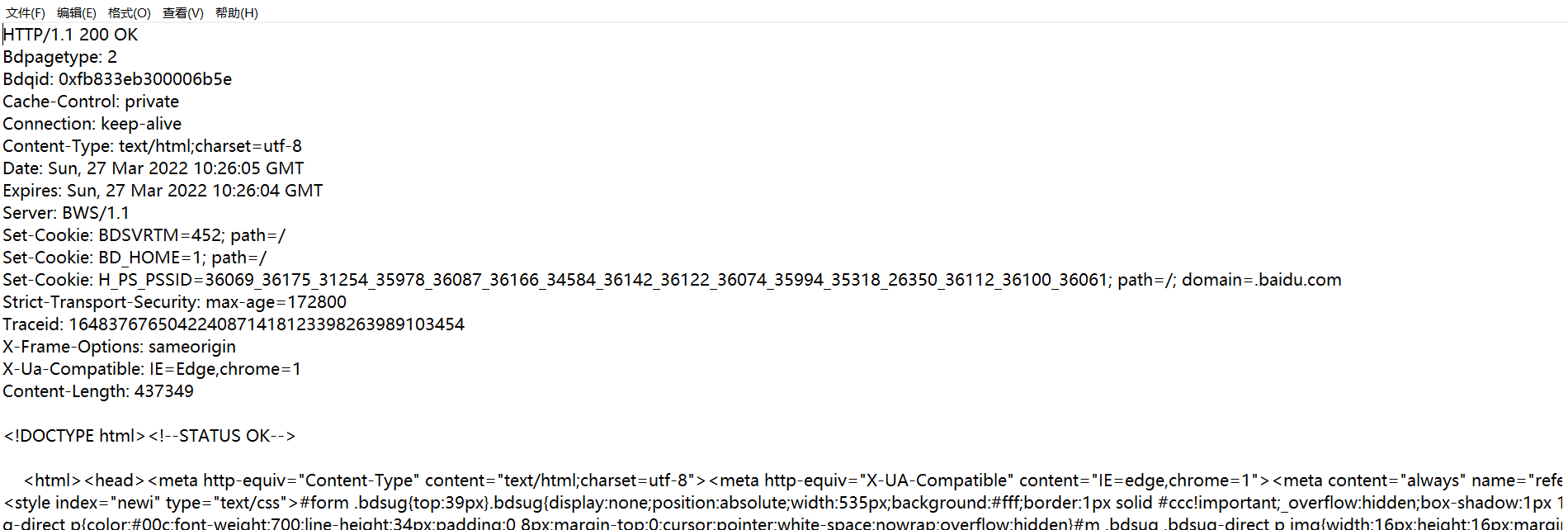
1、首行:
HTTP/1.1 200 OK
版本号+状态码+状态码解释
2、协议头(Header)
协议头里面是“键值对”结构,每个键值对占一行,每个键和值之间使用 冒号空格 来分割。
3、空行
空行是协议头的结束标记。
4、响应正文
空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有
一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页
面内容就是在body中 。
响应的正文都是显示在浏览器上面的,常见的显示正文格式就是html,因为许多网站的html都是压缩过的,所以要点检上面的解压缩,才不会乱码,因为压缩过后,网络传输的数据量就变少了,就更节省网络带宽,
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gSEFQ46L-1648635483072)(https://cdn.jsdelivr.net/gh/power152/Image/202203281749926.png)]](https://img-blog.csdnimg.cn/636a61c56801440bbc38f4baadc6082e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6bii5Lmf,size_20,color_FFFFFF,t_70,g_se,x_16)
对于服务器来说,硬件资源有四个部分
1、带宽资源 (也是成本最高的)。
2、CPU
3、内存资源
4、硬盘资源
2.3.3 协议格式总结
一张图搞定;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DZ83P6Rn-1648635483073)(../image/image-20220327185129146.png)]](https://img-blog.csdnimg.cn/ed7d4e5f564c4fa4a0ce717922987d44.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6bii5Lmf,size_20,color_FFFFFF,t_70,g_se,x_16)
- HTTP 的协议报文格式:
请求(request):
1、首行:方法 + URL + 版本号
2、请求头(header):键值对结构,每个键值对占一行,键和值之间使用 冒号空格 分割
3、空行:header 的结束标志
4、正文。(可有可无)
响应(response):
1、首行:版本号+状态码+状态码的描述
2、响应头:键值对结构,每个键值对占一行,键和值之间使用 冒号空格 分割
3、空行:header 的结束标志
4、正文。(可有可无)
三、request(请求)
3.1 URL基本格式
我们再浏览器中地址栏,就是输入的URL,就是平常说的网址。URL(Uniform Resource Locator) 统一资源定位符,互联网上面每个文件都有一个唯一的URL,URL也表示文件的位置以及浏览器改怎么处理。
- 一个完整的URL

1、协议名:这个不多说
2、登录信息:原来有,现在基本上不会显示了,都是通过抓包来看用户账户
3、域名:也称之为ip地址,ip地址是描述一个主机在网络上的具体位置,域名是可以转换为ip地址的(DNS),由于ip地址太难记了,就出现了域名
4、端口号:具体区分主机上面的某一个程序,一台主机太多的程序了,通过端口号可以找的对应的程序,平时地址栏没有端口号,可能浏览器自动加上默认的端口号(HTTPS:443;HTTP:80)存在特殊情况也可以手动加入端口号;
5、文件路径:这个很好理解,就是利用端口号找到程序再利用文件路径精确定位某个文件
6、查询字符串:一般从问号开始就是查询字符串query String,query String是客服端给服务器的参数,这个参数是一个键值对的结构
> 以 & 作为键值对分隔符;
> 以 = 作为键和值之间的分隔符;
> 这里面的键值对,都是程序员自定义的,所以只有该程序员才看得懂这个参数;
> 这里的参数很重要,是给前后端交互提供很多的“可能性”;
在实际使用中不会出现完整的URL,经常会省略一部分
1、省略域名:继续访问当前网站的其他资源
2、省略端口号:浏览器自动填充默认端口号(80,443)
3、省略带层次的路径:表示访问/目录
4、省略query string:这是可选的,客户端可以给浏览器传递参数,也可以不传递。
3.1.1 URL encode
对于:、?/.…或者中文符号这些符号在URL中都当做特殊的意义理解,不只是单纯的``?、/,#或者中文符号 ,此时我们就要进行url encode 转义,这里的转义是直接取当前字符/字符串的内存的十六进制表示形式,然后在每个字节的前面加上%`。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RsMavWR5-1648635483074)(https://cdn.jsdelivr.net/gh/power152/Image/202203291445694.png)]](https://img-blog.csdnimg.cn/327d591424f340a3a760fd2a662e9f13.png)
我们也不必背转义字符,直接使用urlencode转义工具就行了,urlencode工具
四、HTTP中的“方法”
HTTP中的方法就是请求报文首行中的一部分,
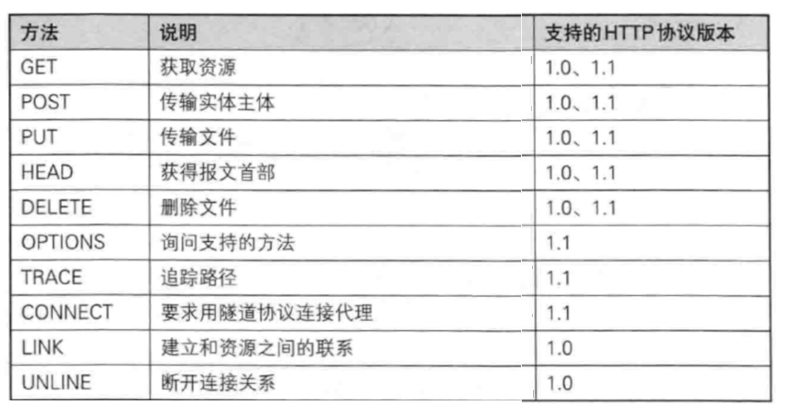
这些不同的方法代表着不同的含义,来表达不同的“语义”,但是我们最常用也必须掌握的就是 GET,POST这两个方法,也是面试官极大可能被问到的连个方法,其他的方法面试也会问但是说几个就行了,但是重点掌握GET和POST这两个方法。
4.1 GET
可以说是大部分时候都会出发 GET 方法的请求。
1、在浏览器地中中输入URL,回车就是一个 GET请求,(类似收藏夹中的链接也是一样的效果。
2、HTML 中的一些标签;
> img 中的 src属性,写一个URL,也会构造出一个 GET 请求
> link/script/ a 标签中href属性,也是构造出 GET 请求
3、使用 javascript ,在浏览器前端构造出 GET 请求(ajax)
4、各种编程语言只要能访问网络就是构造出 GET 请求。
GET 请求的特点:
1、首行的部分是 GET 方法
2、URL里面的query String可以为空,也可以不为空
3、GET 请求里面有多组 header 这样的 键值对
4、GET 请求里面body一般都是空的,(也有,但是少见)
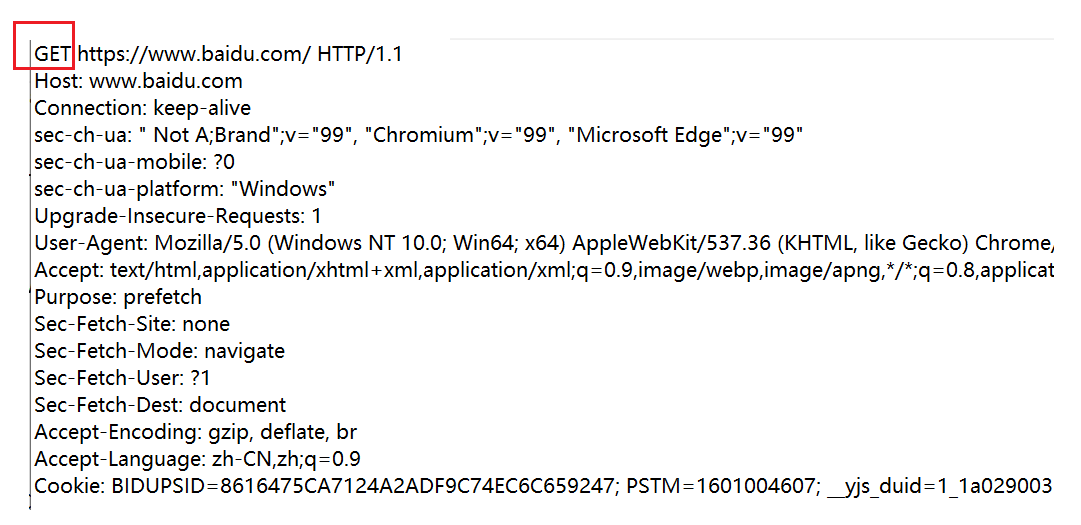
注意:关于 GET 网上的一些说法是错误的,网上很多都在说GET请求会有长度限制,这得看 RFC 2616这份文档是怎么写的了,这份文档,里面约定了很多和网络协议相关的标准。对于长度这一块原文档是怎么说的:Hypertext Transfer Protocol --HTTP/1.1," does not specify any requirement for URL length 。原文档没有对URL的长度有任何的限制。真正限制可能是浏览器的实现和HTTP服务器端的实现。不同浏览器最大长度是不同的,服务器可以对长度进行配置。
4.2 POST
POST 常见的场景就是登录,输入用户名和密码之后, 点击登录就会产生post请求。
POST请求的特点:
1、首行得一个部分就是POST;
2、URL 后面没有query string,(一般是没有,个别会有)
3、POST 里面有多组 header 这样的 键值对
4、body一般不为空
> 关于body的数据格式,是有header中的 Content-Type来描述
> body的具体长度,有请求header 中的Content-Length 来描述的
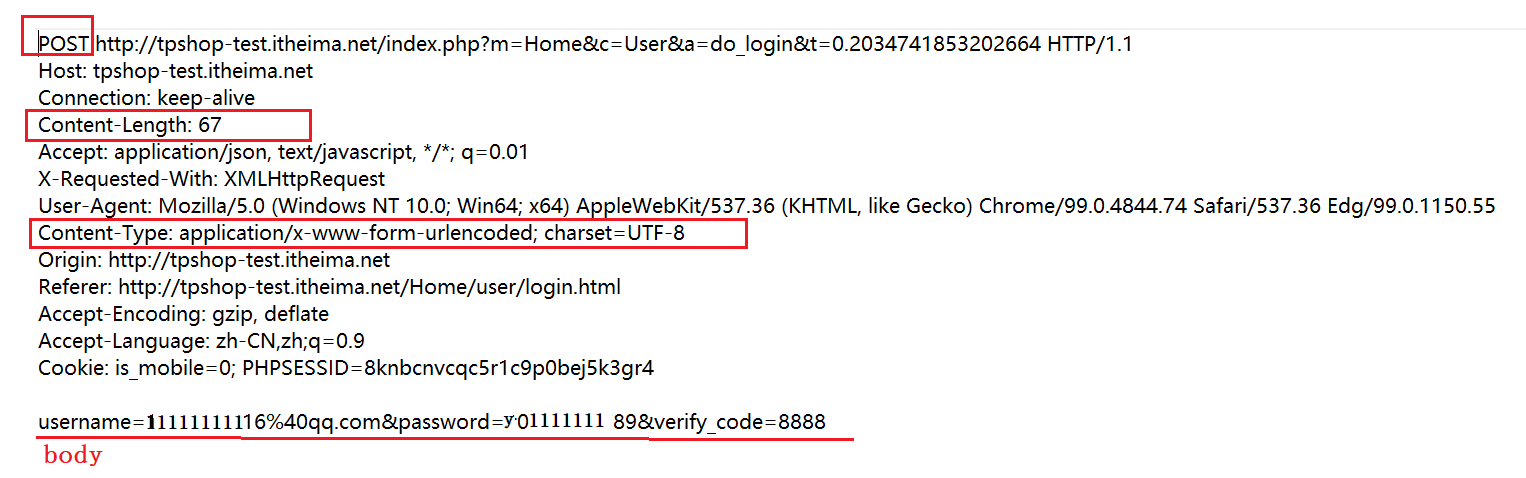
这里可以看到body部分可以显示你的登录账号和密码,所以说互联网上的信息是不安全的,随便抓个包,就能就能把密码都抓出来,但是我们也不要太惊慌,像我们支付宝密码这些都是加密过的,并且这个加密还是动态相对来说还是很安全。
4.3 经典面试题 GET 和 POST 的区别
正确答案:GET 和 POST 是没有本质区别的。(他们俩用的场景是可以互相代替的)
但是在具体使用上还是会存在细节的区别的:
1、GET 习惯上,把客户端的数据通过query String来传输(body部分是空),POST 习惯上,把客户端的数据通过body来传输(query String是空的)
注意:这里的习惯上并不是必须!!!
2、语义区别,GET 习惯上,用于从服务器获取数据;POST习惯上,是客户端给服务器提交数据。
注意:这里的习惯上并不是必须!!!
3、一般情况下,程序员会把 GET 请求的处理,实现成“幂等”的,POST 请求的处理,不要求实现“幂等”。
注意:
幂等的含义:请求被重复的发送不会产生影响。such as一个网站加载时间过长你反复刷新,给服务器反复发送请求是没有影响的,但是如果对一个东西进行下单,下多次单就会产生很多订单,买一份就够了,不需要买多份就会给顾客产生影响。
4、GET 请求可以被缓存,可以被浏览器保存到收藏夹里面,POST不行。
对于这个问题,网上也有多种说法,也是不准确的。
1、POST 比 GET 更安全 ×;
> 登录的时候如果使用 GET 进行登录,就会把username和password显示在地址栏中不安全,但是 POST就会把username和password放到body中会比 GET 更安全。
- 一般这种说法都是错误的,POST已抓包也能抓到username和password,故安不安全取决于加密算法的强度
2、传输的数据量:POST 传输的数据量比 GET 更多,原因 GET 的URL有上限 ×;
- RFC 标准明确说明,不对URL进行长度限制。
3、GET 只能传输文本数据。 ×
> POST可以传输 文本和二进制数据
- GET完全可以传输文本和二进制数据,只需要对二进制数据 urlencode 即可;GET 也可以把数据放入body中。
五、认识请求”报头“
5.1 Host
Host: www.sogou.com
Host 表示该请求对应的服务器地址,地址里面可以是ip可以是域名,也可以手动指定端口号,但是域名是可以在URL中显示的,有时候URL中显示的域名和Host的域名不太一样,这是怎么回事???
- 因为网站存在一种程序叫做“代理”,“代理”需要翻外网,翻外网的域名就和
Host里面的域名就不一样了。
5.2 Content-Length
表示的是 body 的长度,长度的单位是字节
5.3 Content-Type
表示的是 body 的格式。
注意:如果请求有body(POST),此时就会在header中带上Content-Length和Content-Type这两个参数。如果请求中没有 body (GET),此时这两个参数就不会出现在header中了。
1、Content-Type 中的常见取值
application/x-www-form-urlencoded:
此时body就会使用类似于query String的格式进行组织
multipart/form-data
使用HTML上传文件的时候的格式。
application/json
这个格式就非常的流行了,是一种json格式 ,不知道json格式的看这个链接,json基本用法。这里简单说明一下在花括号里面以多种键值对的方式组织,键值对之间采用“,”分割,键和值之间使用“:”分割,里面的字符串都是用双引号引起来;就像下面这个样子。
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
a861fa2bddfdcd15"}
5.4 User-Agent
简称 UA。
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55
这是请求中常见的header,User-Agent里面保存的是当前浏览器的类型/版本,以及操作系统的类型/版本。
在早些年UA可以识别当前浏览器类型/版本,就可以对对应的浏览器响应更丰富的页面,支持js交互的页面,在当时不是所有的浏览器都能达到网页丰富的效果,多以当版本不达标就响应一个静态页面。但是现在大多数浏览器都可以实现JS的交互。
所以UA 现在的作用就是区分pc端还是移动端。
5.5 Referer
这个是表示页面是从哪里来的,并且这个header不一定存在,如果直接在地址栏里面输入URL或者点击浏览器的收藏夹中的链接,此时Referer是空,就是没有这个header。
Referer: http://tpshop-test.itheima.net/Home/user/login.html
这个就是从tpshop中这个网站,跳转的登录页面的。
5.6 Cookie ☆
Cookie机制存在的目的,主要是为了能够在浏览器这一段,保存一些程序员的自定义数据。

Cookie也像键值对的结构,键值对之间用“;”分割,键和值之间用“=”分割。
Cookie里面保存的键值对都是程序员自定义的,想定义啥就定义啥,当然你粒粒面的含义也只有网站开发者才知道。
question:
1、能不能把要存的数据保存在客户端浏览器所在的主机硬盘上(存个文件)??
> 不能,因为浏览器为了保证安全性,禁止网页中的代码访问主机的硬盘(无法在JS上写文件),那么这就让前端失去了持久化存储能力。为了解决这个缺陷,就产生出了Cookie这个机制,Cookie机制按照键值对的方式存储,来代替直接访问文件,而Cookie是浏览器管理的(本质是保存在硬盘上)会持久化存在。
故Cookie就是浏览器提供的一个让程序员在客户端这边持久保存的数据的一种机制!!!至于存的是什么,由程序员来定义。
总结:
1、Cookie是什么?
> Cookie是浏览器提供的一种让程序员在本地存储数据的能力。
2、Cookie里面存的是啥?
> Cookie里面存的是键值对的格式数据,键值对用“;”分割,键和值之间用“,”分割。
3、Cookie从哪里来?程序员如何在Cookie里面存东西??
> 在浏览器中的URL位置左边用一个锁,点击这个锁就可以看到浏览器中的Cookie,每个Cookie还不一样,百度有一组百度的Cookie,搜狗有一组搜狗的Cookie…
> 浏览器里面存的Cookie都是从服务器的响应“报头”里面的 set-cookie 字段中来的,每个 set-cookie 字段里面都包含一个Cookie 这样的键值对,浏览器拿到响应之后就会把 set-cookie中的内容保存到本地,而 set-cookie 就是程序员自己在服务器中构造填写的。
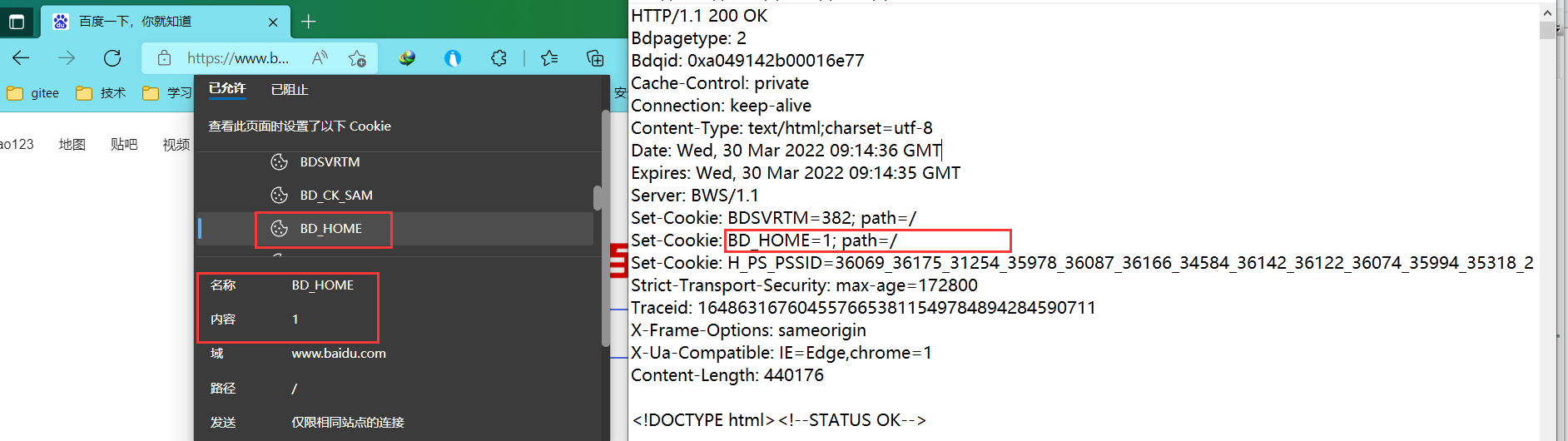
4、Cookie要到哪儿去?(谁来使用Cookie)
Cookie的一个流程:
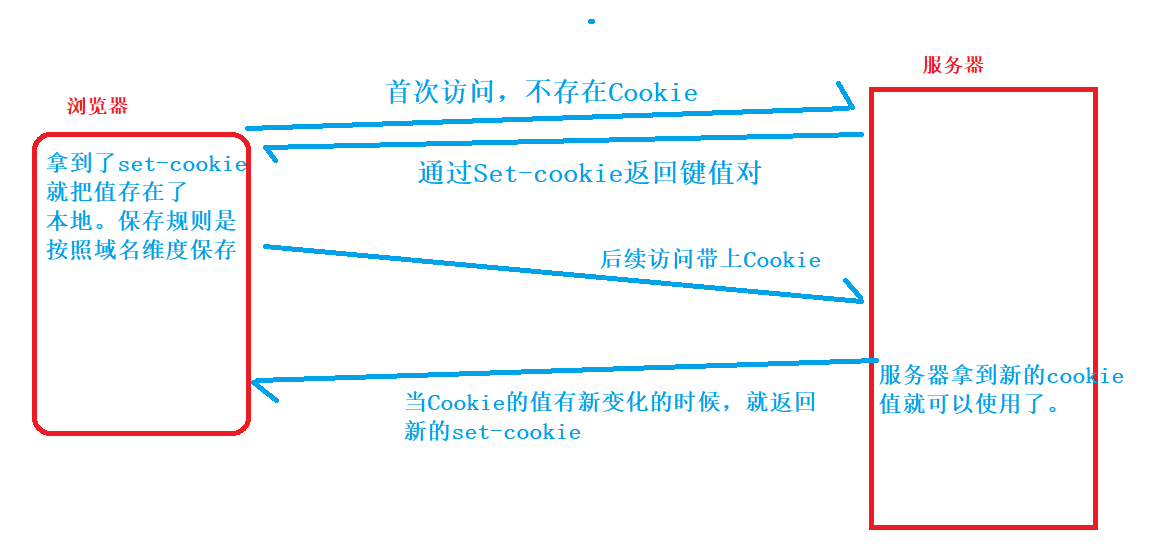
最常用的应用就是保持客服端的登录状态;
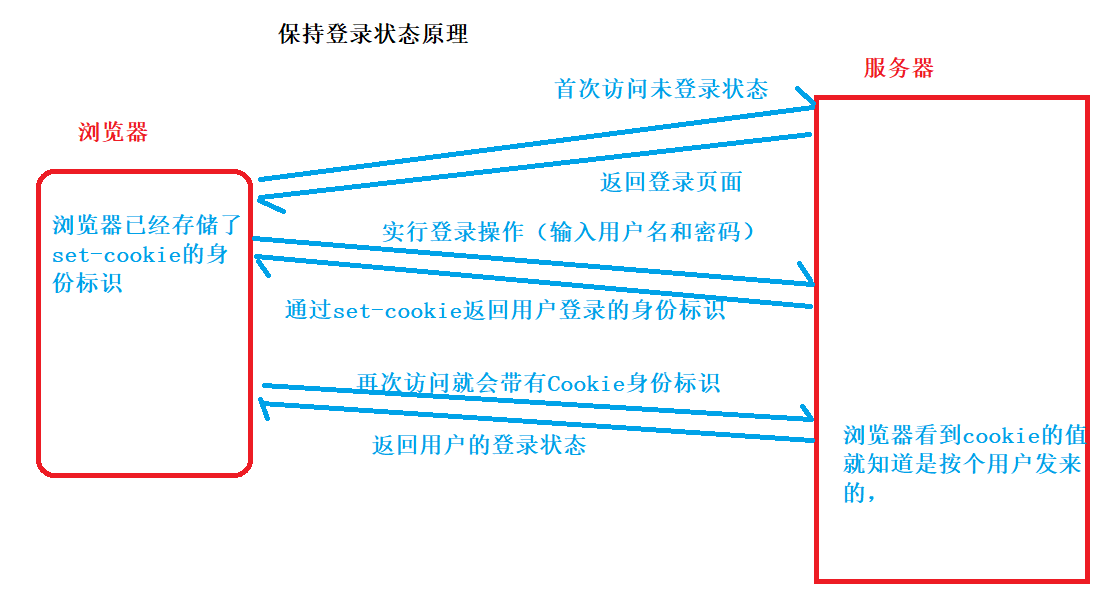
这里插一句嘴,在做自动化测试中,通常会遇到登录出现验证码的情况,这个验证码是随机改变的,为了方便自动化测试,测试功能的完整性,就可以使用Cookie来绕过验证码实现自动登录。
到了2022年,Cookie不是唯一浏览器本地存储的机制,浏览器现在还提供了其他的本地存储的机制
1、LocalStorage
2、indexDB
Cookie的缺陷:每次请求,都要把该域名下的所有的Cookie通过HTTP请求传给服务器,就注定Cookie的存储容量是有限的 ,因为在服务器中,带宽资源 成本很高。
相比之下,新的存储机制就没有这个问题。
六、状态码
属于HTTP的响应内容,表示这次的请求结果是如何的。
五大类别:
1、1XX Hold on 等会继续
2、2XX Here you are 成功访问
3、3XX Go away 重定向
4、4XX You fucked up 服务器崩了
5、5XX I fucked up 客服端的问题
6.1 200 OK
ok 是状态码的描述,就是一个或者多个简单的单词,表示状态码的意思。
HTTP/1.1 200 OK
6.2 404
404 Net Found
客服端尝试请求的资源,在服务器上不存在
6.3 403
403 Forbidden
访问被拒绝(没有权限的表现)
6.4 405
405 Method Not Allowed
当前http方法,服务器不支持
6.5 500
500 Internal Server Error
服务器代码出现了崩溃/异常
6.6 504
504 Gateway Timeout
当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的情况
6.7 302
302 Move temporarily
重定向

http协议这篇帖子就先写到这里,后面会把https的帖子写完。❤🧡💛💚💙💜🤎🖤🤍💟,收藏关注呗,你们支持就是我写博客最大的动力!!!!
















 7910
7910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











