







数组_内存解析
- 一维数组内存解析
Java虚拟机的内存划分,如下图:
(为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。)
为了方便理解数组在Java虚拟机(JVM)中的存在,先了解以下Java虚拟机:
了解 JVM (Java Virtual Machine) 是掌握 Java 编程的关键,因为它是 Java 代码执行的基础。以下是一些关于 JVM 的重要概念:
1.1 JVM 的基本结构

-
类加载器 (Class Loader): JVM 使用类加载器将字节码(.class 文件)加载到内存中。类加载器分为三种类型:引导类加载器、扩展类加载器和应用程序类加载器。它们按顺序工作,引导类加载器首先加载核心 Java 库,然后是扩展类加载器,最后是应用程序类加载器。
-
运行时数据区 (Runtime Data Areas): 这是 JVM 在运行时使用的内存区域,包括以下几个关键部分:
- 方法区 (Method Area): 存储已加载类的结构信息、常量池、静态变量和方法代码。
- 堆内存 (Heap): 所有对象和数组的内存分配都在堆内存中进行。堆内存是 JVM 中最大的内存区域,所有线程共享。
- 栈内存 (Stack): 每个线程都有自己的栈内存,用于存储局部变量、操作数栈和方法调用的返回值等。栈内存是线程私有的。
- 程序计数器 (Program Counter, PC): 记录每个线程当前执行的字节码指令的地址。
- 本地方法栈 (Native Method Stack): 为本地方法服务,存储调用本地方法时使用的数据。
-
字节码执行引擎 (Execution Engine)
-
解释器 (Interpreter): JVM 的解释器逐行读取字节码并执行。但是,由于逐行解释,解释器的性能较低。
-
即时编译器 (Just-In-Time Compiler, JIT): 为了提高执行速度,JIT 编译器将热点代码(经常执行的代码)编译成本地机器码。这样,JVM 在执行热点代码时可以跳过解释步骤,直接执行本地机器码,从而提高了性能。
-
1.2 JVM结合数组
将 JVM 的内存结构与 Java 数组的内存解析结合起来,可以更全面地理解数组在 JVM 中是如何存储和管理的。
-
数组在 JVM 中的内存分布
在 JVM 中,数组对象被分配在 堆内存 中,因为数组是对象的一种。具体来说,数组的内存分布如下:
- 对象头 (Object Header): 数组对象的头部包含了一些元数据信息,比如数组的长度和类型信息。这些信息保存在 方法区 中。
- 数组元素: 数组元素本身存储在 堆内存 中。对于基本数据类型的数组,元素直接存储在堆中,并且是连续分布的。对于引用类型的数组(如
String[]),存储的是对象的引用(即指向实际对象的指针),这些引用也存储在堆内存中。
-
数组的内存分配过程
当你在 Java 中创建一个数组时,例如
int[] arr = new int[10];,JVM 会执行以下步骤:- 类加载器加载数组类: 如果数组类还没有加载,JVM 的类加载器会首先加载该数组类型的类(如
int[]或String[])。 - 堆内存分配: JVM 在堆内存中为数组对象分配内存。对于
int[] arr = new int[10];,JVM 将分配足够大的内存来存储 10 个int类型的元素(每个int占用 4 字节,共 40 字节),加上对象头部的内存(通常为 12 或 16 字节,具体取决于 JVM 实现和架构)。 - 初始化: JVM 会自动将数组的所有元素初始化为默认值(基本数据类型为
0,引用类型为null)。
- 类加载器加载数组类: 如果数组类还没有加载,JVM 的类加载器会首先加载该数组类型的类(如
-
数组访问与 JVM 栈内存的关联
- 局部变量表: 在方法执行时,数组的引用会被存储在当前线程的 栈内存 中的局部变量表中。比如
arr引用会存储在局部变量表的一个槽位中。 - 操作数栈: 在方法执行过程中,数组访问(如
arr[5])会将数组引用和索引值压入操作数栈中,JVM 根据这两个值计算出对应元素的内存地址,并访问该内存位置。
- 局部变量表: 在方法执行时,数组的引用会被存储在当前线程的 栈内存 中的局部变量表中。比如
1.3举例
- 创建数组的流程:

- 二维数组内存解析
2.1 二维数组的结构
在 Java 中,二维数组可以看作是一个包含了多个一维数组的数组。比如,int[][] matrix = new int[3][4]; 是一个 3 行 4 列的二维数组,本质上是一个长度为 3 的一维数组,其中每个元素又是一个长度为 4 的一维 int 数组。
2.2 内存分布
- 顶层数组(行数组): 首先,JVM 在堆内存中分配一块内存用于存储长度为 3 的一维数组(称为行数组),每个元素都是一个对一维
int数组的引用。这个数组中的每个元素实际上是一个指针,指向具体的行。 - 每行的数组: 然后,JVM 为
matrix中的每一行(即每个int[]数组)分别分配内存。每个一维int数组都是一个独立的对象,存储在堆内存中,并且这些数组的内存是连续的。
2.3 内存布局示例
假设我们定义了一个二维数组 int[][] matrix = new int[3][4];,其内存布局如下:
matrix引用指向堆内存中的一个数组对象,这个数组对象长度为 3。- 数组对象的第一个元素指向一个
int[4]数组,第一个元素的引用指针存储在matrix[0]中。 - 类似地,
matrix[1]和matrix[2]分别指向另外两个int[4]数组。
例如:
matrix (3 elements)
+------+ +------------+
| * | --> | int[4] (0) |
+------+ +------------+
| * | --> | int[4] (1) |
+------+ +------------+
| * | --> | int[4] (2) |
+------+ +------------+
2.4 内存访问
当你访问二维数组的元素时,例如 matrix[1][2],JVM 进行以下操作:
- 首先,找到
matrix[1],即第一行数组的引用。 - 然后,在这个行数组中查找索引
2处的元素值。
这意味着访问二维数组的元素需要两个内存访问步骤:首先访问行数组,然后访问具体的元素。
2.5 内存分配与垃圾回收
- 分配: JVM 分配二维数组内存时,首先为顶层数组分配内存,然后为每个一维数组分配内存。每个分配都是独立的,因此可以灵活处理不规则的二维数组(即每一行的长度可以不同)。
- 垃圾回收: 当二维数组不再被引用时,JVM 的垃圾回收器会依次回收顶层数组和所有行数组的内存。由于每个行数组都是独立的对象,GC 需要单独处理它们。
2.6 性能考虑
- 缓存局部性: 由于二维数组中的数据存储在不同的内存块中,可能会导致较差的缓存局部性。这意味着当你访问二维数组中的元素时,可能会多次触发 CPU 缓存未命中,从而影响性能。与 C 语言中的多维数组相比,Java 的这种“数组的数组”结构可能会在处理大规模数据时产生额外的开销。
- JIT 优化: JVM 的即时编译器可以在一定程度上优化对二维数组的访问,但由于其结构,无法避免一些性能损失。
2.7 不规则数组
Java 允许创建不规则的二维数组,比如 int[][] matrix = new int[3][];,然后你可以为每一行分配不同长度的数组。这种灵活性使得 Java 的二维数组在某些场景下非常实用,但也意味着内存分布更加复杂。
2.8 内存解析图示
如果以图示表示二维数组的内存解析,可以将其看作由多个数组对象连接而成的结构,每个数组对象在堆内存中都有独立的地址和存储空间,之间通过引用(指针)连接。
通过以上内容,可以看到二维数组在 JVM 中的内存解析不仅仅是简单的连续存储,而是涉及到多个数组对象的引用与存储。理解这一点对优化和调试 Java 程序非常重要。
2.9 举例
二维数组本质上是元素类型是一维数组的一维数组:
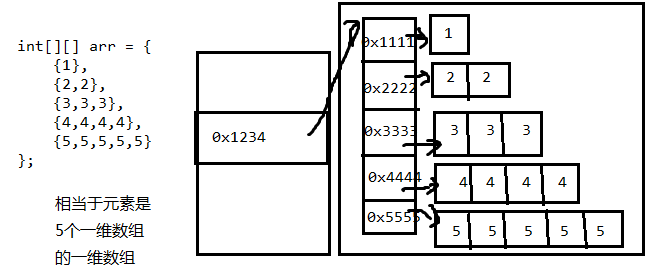
二维数组在 Java 中的内存解析稍微复杂一些,因为 Java 不支持真正的多维数组,而是将二维数组实现为“数组的数组”。















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









