






注意:在配置hadoop完全分布式之前需要先安装jdk和配置集群免密哦~
配置免密可以参考我上一篇文章: Centos7集群配置免密登录
一、安装hadoop
1.解压
tar -zxvf hadoop包名
2.配置环境变量
vi /etc/profile
在文件末尾写入
##HADOOP_HOME
export HADOOP_HOME=/opt/download/hadoop包名
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存并退出文件编辑
:wq
保存后执行配置文件生效
source profile
检测是否安装成功 出现版本号就是安装成功
hadoop version
二、修改配置文件
1.mapred-env.sh
JAVA_HOM后面写你的jdk安装路径
export JAVA_HOME=/opt/module/jdk
2.yarn.env.sh
同上一样
export JAVA_HOME=/opt/module/jdk
3.mapred-site.xml
mapred-site.xml要是不存在就复制一份,然后重命名为 mapred-site.xml 命令如下
cp mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framwork.name</name>
<value>yarn</value>
</property>
4.yarn-site.xml
这里的node001为三台机器中主节点机器的host名称
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname></name>
<value>node001</value>
</property>
5.core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://node001:9000</value>
</property>
6.hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node001:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
7.hadoop-env.sh
export JAVA_HOMT=/opt/module/jdk
设置哪个用户可以执行namenode和datanode命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
#设置哪个用户可以启动resourcemanager和nodemanager的命令
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
8.vi works 分发给其他节点
注意:hadoop2.x使用的是slaves文件
hadoop3.x使用的是works文件
Hadoop1
Hadoop2
Hadoop3
三、格式化节点
在主节点上输入
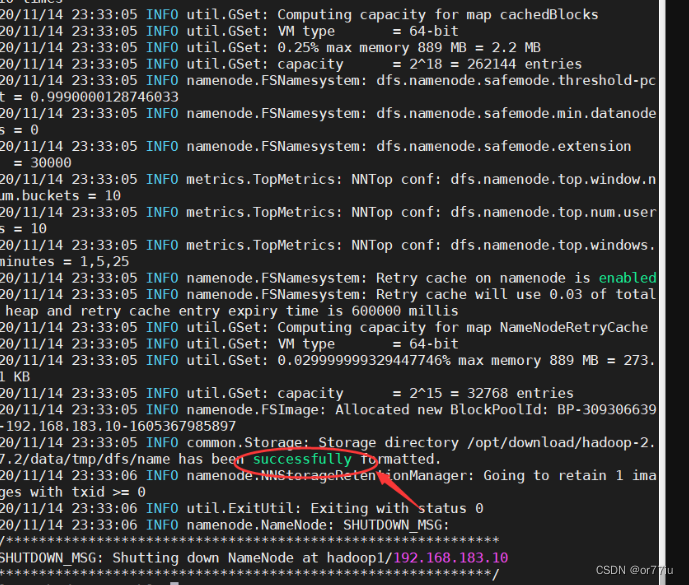
hadoop namenode -format
成功如下图出现successfully
四、启动集群
start-all.sh
五、关闭集群
stop-all.sh














 3817
3817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









