







目录
一、概述
又是一年毕业季,简历对于求职来说是一个必不可少的东西,加之本人学校最近要求提交一份简历给指导老师,于是突发奇想运用爬虫技术来爬取一些免费的模板。本博客将带领大家编写一个简单的爬虫程序,目的是爬取网页中免费的简历模板。先提前附上免费的简历模板网站:免费简历模板 个人简历模板 简历模板免费下载-站长素材。 (chinaz.com)
二、了解网页解析技术
通过python的request库我们能够请求到网站的HTML内容,但是很多时候我们需要数据并不是整个网页而是网页中局部的数据,比如我们想爬取一些小姐姐的图片,请求到网页之后我们需要拿出来的只是网页中小姐姐的图片,而并非里面的小狗,小猫或者其他图片(手动狗头);我们只需要页面中部分数据,称之为页面的局部解析。那么针对页面局部解析我们可以运用下面三种技术:
2.1、正则表达式
这个有编程语言基础的人应该都了解,我们可以编写对应的正则表达式将网页中有用的数据匹配出来,例如:
ex = '<div class="con">.*?<img data-src="(.*?)" alt.*?</div>'(正则表达式这里不过多讲解 )正则表达式非常灵活,并且大部分编程语言都支持,这就代表如果下次使用其他语言来做爬虫,这段正则同样可以运用。但是正则表达式的学习相对来说还是具有一定的成本,所以本次项目不采用这种方式。
2.2、bs4
bs4是python的一个用于解析网页的库,相对于正则表达式,bs4使用起来非常简单,比如下面这段代码:
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 将本地的HTML文档中的数据加载到该对象中
fp = open('test.html', 'r', encoding='utf-8')
soup = BeautifulSoup(fp, 'lxml')
print(soup.select('.tang > ul a')[0]['href'])这个案例中我们读取了本地的一个html文件来进行解析, BeautifulSoup() 接收两个参数,第一个是需要的解析html内容,第二个是解析器。传入这两个参数后我们能够得到一个soup对象,通过soup对象上的属性或者方法我们就能够选取到对应网页元素。这里select()函数中,我们编写了一个类似于CSS选择器的东西,语法是和CSS一模一样;这里代表选择class为tang的元素中的直接子元素ul下的所有a标签,并且在后面我们通过[0]选中第一个a标签,通过['href']拿到a标签中href属性的值。
怎么样?是不是非常的方便,bs4虽好但是不要太贪杯哦(滑稽)。在上面的时候我们就说了bs4只是python的一个库,那么在Java或者其他语言中是没有办法使用的。那么有没有一种兼容性好,并且写起来简单的方式呢?接着往下看嘛!
2.3、xpath
终于到主角登场了,xpath应该算是当前比较流行的网页解析的方式了,它写起来相对简单,并且通用性强,很多语言都支持,所以我们的项目就采用这种方式解析网页了。对于xpath这里同样不会过多讲解,小伙伴可以自行去了解,这里同样附上示例代码以及我学习时候记录的笔记:
from lxml import html
etree = html.etree
if __name__ == '__main__':
# 实例化一个etree对象
tree = etree.parse('test.html', etree.HTMLParser())
r = tree.xpath('//div[@class="song"]/img/@src')
print(r)
1. 初始化
from lxml import html
etree = html.etree
if __name__ == '__main__':
# 实例化一个etree对象
tree = etree.parse('test.html', etree.HTMLParser())
2. 编写xpath表达式,拿到对应的元素
* /: r = tree.xpath('/html/body/div') #最左侧斜杠代表从根节点定位,一个斜杠代表一个层级
* //: 代表多个层级 例如: //div 代表可以从任意位置开始定位,寻找div的位置
* [@class=""]: 属性定位,代表找到class为song的这个属性 例如: //div[@class="song"] 从所有div中找到class属性为song的那个div
* p[3]: 属性定song位,代表拿到第三个p元素 例如: //div[@class="song"]/p[3] 从所有div中找到class属性为song的那个div,从这个div下,找到第三个p元素,索引从1开始
* 注意: 不管元素是一个还是多个返回的类型永远都是列表类型
3. 获取标签中的文本内容
* //a/text(): 通过在xpath路径后面添加一个text()函数,就能够拿到对应标签中的文本内容,此时就是拿到页面中所有a标签中的内容
* //text(): 上面获取文本内容必须是直系,才能够获得,但是//text()能够获取标签中非直系的文本内容
4. 获取标签中的属性:
* /img/@src: 通过@属性名就能够取得某个元素的属性值, 例如: //div[@class="song"]/img/@src 取得class为song的div下的img标签中的src属性
在高版本的lxml库中,etree被集中到了html中,这点小伙伴们需要注意,在使用的时候为了方便调用建议将html.etree赋予给etree变量。那么以上三种解析网页的方法我就全部讲解完毕了,马上开始我们的项目吧!!!
三、项目编写
3.1、引入库,初始化etree
import requests
from lxml import html
import os
etree = html.etree
这一步相信对于大部分人来说没有难度。
3.2、创建存储数据的目录,确定爬取的URL,进行UA伪装
if __name__ == '__main__':
# 爬取到页面源码数据
if not os.path.exists('./resume'):
os.mkdir('./resume')
url = 'https://sc.chinaz.com/jianli/free.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML,like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.33'
}前两步就不废话解释了,重点说一下UA伪装,在HTTP中有一个特殊的头部:User-Agent,这个头部记录着请求载体的信息,简单的来说如果你是用浏览器请求的,那么里面记录就是你的浏览器信息了,如果你是使用爬虫请求的,里面自然记录的就是爬虫程序的信息了。UA伪装就是将我们爬虫伪装成为一个浏览器的请求。
那么为什么这么做呢?服务器就好比小红帽,她只会给信任的人开门,这个人当然就是她的外婆(浏览器),那么假设你是大灰狼(爬虫程序)你怎么样才能够让小红帽给你开门呢?当然是伪装成她的外婆(UA伪装)获取她小红帽的信任,她自然就不会拒绝开门了。
3.3、初始化数据容器,请求网页
# 用于存放下载页面的字符串
resume_download_pages = []
# 用于存放下载url
download_url_list = []
page_text = requests.get(url=url, headers=headers).text3.4、初始化etree对象,调用xpath解析
tree = etree.HTML(page_text)
a_list = tree.xpath('//div[@id="container"]/div/a/@href')
for a in a_list:
resume_download_pages.append('https:' + a)首先将我们请求过来的网页传入到HTML函数中,这样我们就得到了一个tree对象。对于xpath的编写我们最好是打开网页来逐步分析:

这里很明显是个列表页,如果下载的话需要进入到详情页,那么本页详情页链接就成为了我们想要的数据。
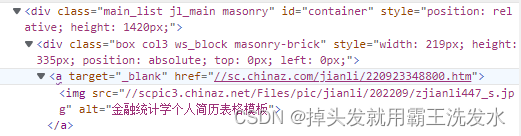
通过逐层查找能够发现我们需要详情页链接数据存在a标签的href中,那么有了目标就可以开始编写xpath路径了:
最外层是一个id为container的div标签,那么首先我们定位到这个标签。因为Id属性不能够重复所以我们可以直接全局查找 //div[@id="container"] 这一句代表找到页面中所有id为container 的div盒子;定位到这个盒子之后后面自然就简单了,我们找到这个盒子中的所有div下的a标签即可,那么 //div[@id="container"]/div/a 最后通过@href取值 于是xpath就成为了上面那样:
//div[@id="container"]/div/a/@href
3.5、请求下载网页,拿到下载链接
for download_pages_url in resume_download_pages:
download_pages = requests.get(url=download_pages_url, headers=headers).text
resume_tree = etree.HTML(download_pages)
download_url_list.append(resume_tree.xpath('//ul[@class="clearfix"]/li/a[1]/@href')[0])3.4步的时候我们拿到了所有详情页面链接,也就是如下页面:

继续分析,对于这一页什么数据是我们需要的呢?当然是下面的下载按钮:
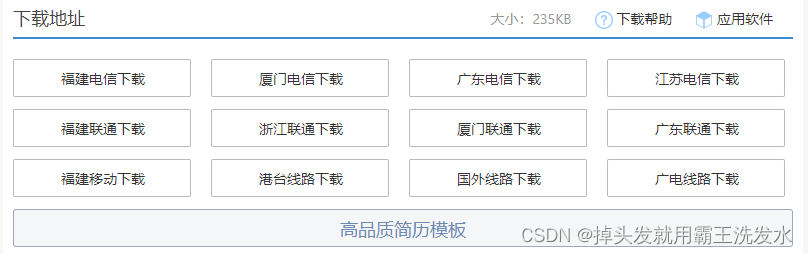 我们只需要得到下载的链接,然后请求是不是就可以将数据下载到本地了。
我们只需要得到下载的链接,然后请求是不是就可以将数据下载到本地了。

那么这里我们自然是需要拿到a标签中href属性的值了。 那么很简单就能够写入下面的xpath了,这里我就不过多分析了,大家要学会举一反三:
//ul[@class="clearfix"]/li/a[1]/@href
这里我们通过循环请求到每个详情页面,并且通过xpath拿到每一个详情页的第一个下载链接,并存放到了download_url_list列表中。
3.5、通过下载链接下载模板,将数据存入到本地
for download_url in download_url_list:
# print(download_url.split('/')[-1])
resume_rar = requests.get(url=download_url, headers=headers).content
with open('resume/' + download_url.split('/')[-1], 'wb') as fp:
fp.write(resume_rar)
print(download_url.split('/')[-1] + '下载成功')最后一步非常简单了,通过请求下载链接我们能够拿到对应的数据,最后通过open()函数,将存入到本地。值得注意的是文件名我是通过 / 拆分url ,拿到最后的文件名的;例如:https://downsc.chinaz.net/Files/DownLoad/jianli/202209/zjianli447.rar 这个下载链接,对应的文件名就是zjianli447.rar。最后我们打印 "下载成功" 的字样代表程序正在执行。
3.6、拿到数据

解压之后我们就能够看到对应的简历模板了。
四、总结
以上就是爬虫程序的编写了,在程序中我们主要学习了xpath的使用,以及相关细节的实现。到这里有人会问免费模板我直接下载就好了,为什么大费周折编写程序下载呢?对于此案例确实有此鸡肋之处,本教程主要亦在帮助大家学会简单的爬虫,以及自我学习。如果错误和不足欢迎大佬指正,也希望大佬能够带带我这个新手。当然如果这篇文章对你有帮助的话也可以点一个免费的赞。
侵删















 2806
2806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









