






LLM分布式训练(一):从 DP 到 FSDP:拆解数据并行技术!
大家好!我是小雲。 随着大语言模型(LLM)的参数量和训练数据量指数级增长,单张 GPU 已经远远无法满足我们的“胃口”。这时候,分布式训练就成了必备技能。而在众多分布式策略中,“数据并行”(Data Parallelism)是最常用也是基础的一种。
很多同学可能听说过 PyTorch 里的 DataParallel (DP)、DistributedDataParallel (DDP),甚至更新的 FullyShardedDataParallel (FSDP)。它们都是数据并行的实现,但背后的原理和效率却大相径庭。面试官常常会揪住这些细节,考察你对分布式训练的理解深度。
别担心!今天这篇文章,我就带大家把这几个技术掰开了、揉碎了,讲清楚它们的来龙去脉、工作原理、优缺点以及关键区别。目标是让大家不仅能“知其然”,更能“知其所以然”,轻松应对面试挑战!
一、 什么是数据并行?—— “众人拾柴火焰高”
想象一下,你要处理一座山的“数据”(训练样本)。一个人(单 GPU)干活太慢,怎么办?
数据并行的核心思想很简单:把活儿分给大家干!
具体来说:
- 数据切分:把这座山的“数据”分成 N 份,每份分给一个工人(GPU)。
- 模型复制:每个工人(GPU)都拿到一套完整的工具(模型副本)。
- 并行计算:每个工人(GPU)用自己的工具,处理自己分到的那份数据,独立计算出模型应该如何调整(梯度)。
- 结果汇总:需要一个机制把所有工人算出的“调整意见”(梯度)汇总起来,形成一个统一的调整方案。
- 同步更新:最后,确保每个工人(GPU)都根据这个统一的方案更新自己的工具(模型参数),这样下一轮干活时,大家的工具还是一模一样的。
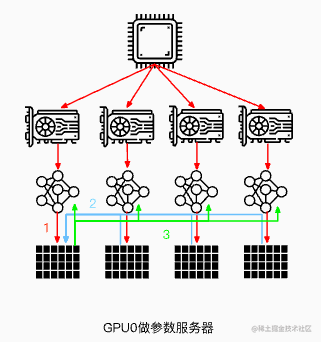
“结果汇总”的方式有几种:
-
中心化汇总 (Parameter Server 模式):
- 指定一个“工头”(比如 GPU0 或 CPU)作为参数服务器(Parameter Server)。所有工人把算好的梯度发给工头。
- 工头负责把所有梯度加起来求平均,然后更新模型参数。
- 最后,工头把更新后的模型参数再分发给所有工人。
- 注意:如果用 CPU 当工头,速度通常会慢一些,因为 GPU 和 CPU 之间的通信(通常是 PCIe)带宽通常低于 GPU 之间的通信(如 NVLink)。
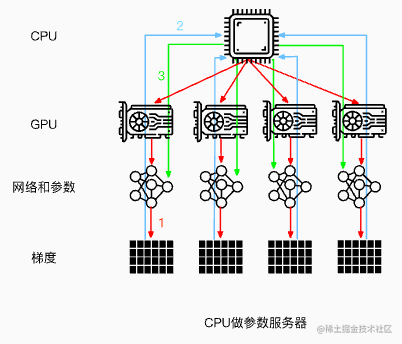
*图2:使用CPU作为参数服务器* -
去中心化汇总 (All-Reduce 模式):
- 没有指定的“工头”。所有工人通过高效的通信方式(比如 Ring All-Reduce)互相交换梯度信息。
- 最终,每个工人都能独立计算出全局平均梯度,并更新自己的模型参数。这种方式负载更均衡,通信效率通常更高。DDP 主要采用这种模式。
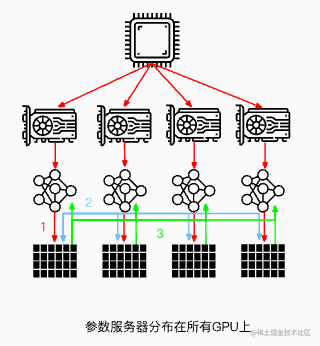
*图3:去中心化梯度聚合(类似All-Reduce)*
数据并行不只是并行处理训练数据,也涉及到模型梯度、权重参数、优化器状态等数据的并行管理和同步。
了解了基本概念,我们来看看 PyTorch 中数据并行的具体实现是如何演进的。
二、torch.nn.DataParallel (DP) - 元老级方案,但廉颇老矣
DP 是 PyTorch 最早提供的数据并行方式。它的特点是使用简单,但效率不高。
工作流程(简化版):
- 数据分发 (Scatter):在“主 GPU”(通常是
device_ids[0])上,把一个 mini-batch 的数据切分成小份,分发给所有指定的 GPU。 - 模型复制:在每次前向传播之前,把“主 GPU”上的最新模型参数复制到其他所有 GPU。
- 并行前向:每个 GPU 独立计算自己那份数据的前向传播,得到输出。
- 结果收集 (Gather):把所有 GPU 的输出收集回“主 GPU”。
- 计算损失 & 反向传播 (在主 GPU):在“主 GPU”上计算总损失,并进行反向传播,计算出梯度。注意:只有主 GPU 上的模型计算了梯度,并进行了参数更新。
- 参数广播 (Broadcast):主卡根据梯度更新自己的模型权重。然后,将更新后的模型权重广播给所有其他 GPU,以保持同步。
使用方法:
import torch
import torch.nn as nn
model = MyAwesomeModel()
# 假设你有 3 个 GPU (0, 1, 2)
dp_model = nn.DataParallel(model, device_ids=[0, 1, 2])
# 像普通模型一样使用
outputs = dp_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step() # 优化器作用在原始 model 上,但更新的是主卡上的参数
DP 的致命缺点 (面试重点!):
- 单进程多线程,GIL 瓶颈:DP 运行在单个 Python 进程中,利用多线程控制多个 GPU。但由于 Python 的全局解释器锁 (Global Interpreter Lock, GIL),同一时刻只有一个线程能真正执行 Python 字节码。这导致在涉及大量 Python 交互(如数据加载、线程协调)时,并行效率低下,速度慢。而且只能用于单机多卡,无法跨节点。
- 主 GPU 负载不均衡:所有的数据分发、结果收集、损失计算、梯度计算(最终的聚合)和参数更新都发生在主 GPU (GPU0) 上。这导致 GPU0 的显存占用和计算负载远高于其他 GPU。经常出现 GPU0 OOM (Out of Memory),而其他 GPU 显存还很空闲的情况。这严重限制了能使用的
batch_size。 - 通信开销大:每次迭代都需要将数据分发、模型复制(或者说参数广播)、输出收集回主卡。通信成了性能瓶颈,尤其是在 GPU 数量增加时。
- 不支持模型并行:DP 本身的机制限制了它无法与模型并行(将模型不同部分放在不同 GPU)很好地结合。
- 不支持 Apex 混合精度(早期):一些优化手段(如 Apex 库的混合精度训练)与 DP 的兼容性不好。
一句话总结 DP:用起来简单,但效率低、负载不均,基本已被淘汰。 官方现在强烈建议使用 DDP。
三、torch.nn.DistributedDataParallel (DDP) - 现代标准,高效稳定
为了解决 DP 的种种问题,PyTorch 推出了 DDP。它是基于多进程的,是目前进行分布式训练(包括单机多卡和多机多卡)的主流选择。
核心思想:每个 GPU 跑一个独立的进程!
工作流程:
- 初始化:启动 N 个进程,每个进程绑定一个 GPU。通过
torch.distributed.init_process_group建立进程组进行通信。 - 模型和数据:每个进程加载完整的模型副本到自己的 GPU。每个进程独立地从数据集中加载属于自己的那部分数据(通常使用
DistributedSampler来保证数据不重复且覆盖完整数据集)。 - 并行计算:所有进程同时进行模型的前向传播和反向传播,计算出各自的梯度。
- 梯度同步 (All-Reduce):这是 DDP 的关键!在反向传播过程中,当某个参数的梯度计算完成后,DDP 会立即启动对该梯度的 All-Reduce 操作。All-Reduce 是一种高效的集体通信操作,它会把所有进程上该参数的梯度加起来求平均,然后让每个进程都得到这个最终的平均梯度。
- 计算与通信重叠 (Overlap):DDP 的一个重要优化是梯度计算和 All-Reduce 通信是重叠进行的。也就是说,在计算后面层的梯度时,前面层的梯度已经在进行 All-Reduce 通信了。这极大地隐藏了通信延迟,提高了训练吞吐量。
- 独立参数更新:由于每个进程都得到了相同的平均梯度,它们可以独立地使用自己的优化器更新自己持有的那份模型参数。因为初始参数相同,梯度也相同,所以所有进程的模型参数在每一步结束后都能保持严格一致。
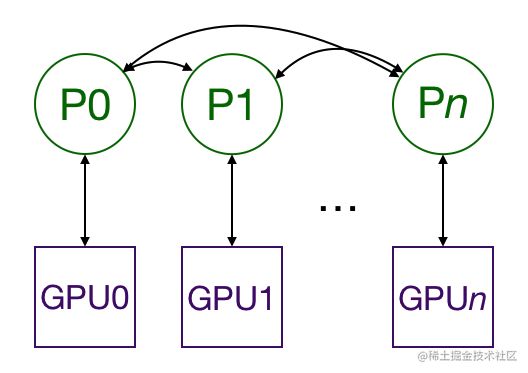
图6:DistributedDataParallel (DDP) 简化流程
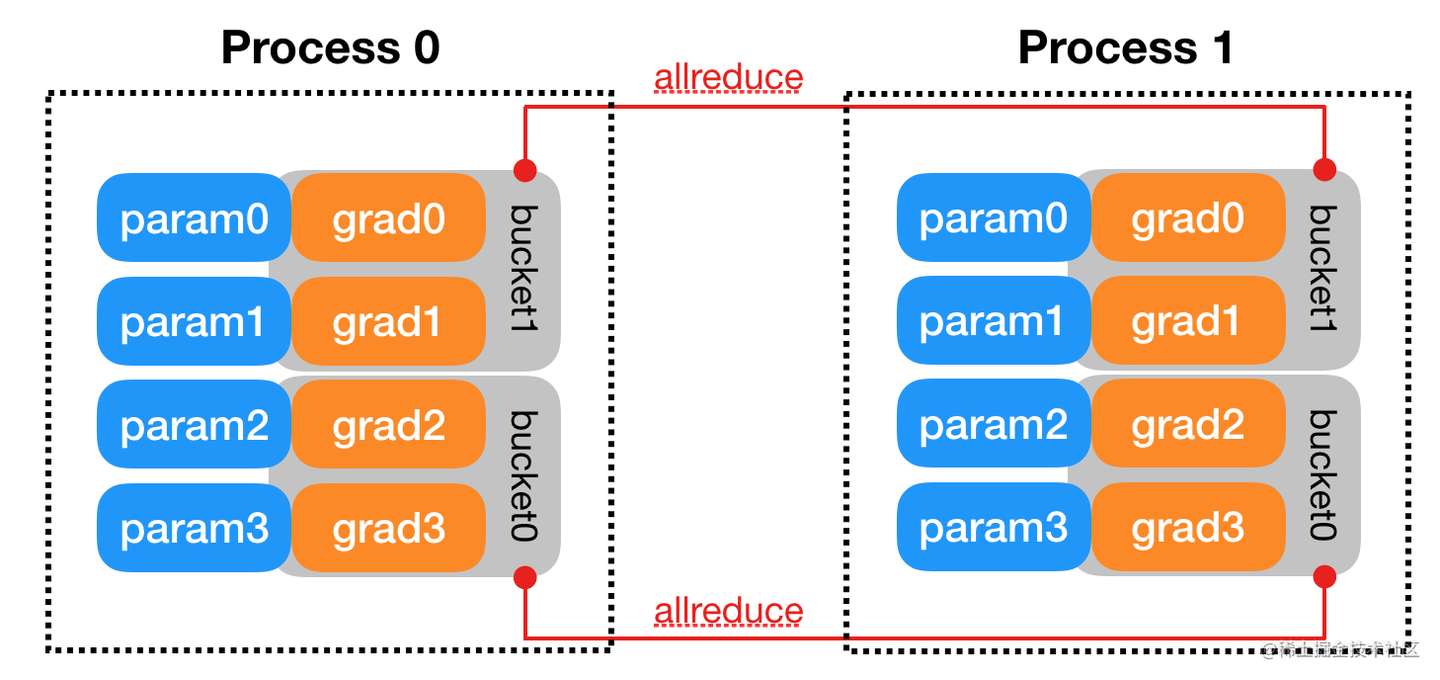
图7:DDP 中的梯度计算与 All-Reduce 通信重叠
DDP 的优势 (面试重点!):
- 多进程,无 GIL 瓶颈:每个 GPU 一个进程,彻底摆脱了 Python GIL 的限制,并行效率高。
- 负载均衡:每个 GPU 承担的计算任务和显存负载基本相同,不会出现 DP 那样的主卡瓶颈。
- 高效通信 (All-Reduce):使用高效的 All-Reduce 算法同步梯度,通信开销相对 DP 大幅减少,且通信量不随 GPU 数量线性增长(对于 Ring All-Reduce)。
- 计算与通信重叠:显著提升训练速度。
- 支持多机多卡:真正实现了跨节点的分布式训练。
- 支持模型并行:可以和模型并行等其他并行策略结合使用。
使用示例 (简化版):
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
import os
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355' # Or any free port
# Initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size) # nccl is recommended for GPUs
def cleanup():
dist.destroy_process_group()
def train_process(rank, world_size):
print(f"Running DDP example on rank {rank}.")
setup(rank, world_size)
# Create model and move it to GPU with id rank
model = nn.Linear(10, 10).to(rank)
# Wrap the model with DDP
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# Example training loop iteration
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn(outputs, labels).backward() # backward() triggers gradient synchronization
optimizer.step()
cleanup()
if __name__ == "__main__":
world_size = torch.cuda.device_count() # Use all available GPUs
mp.spawn(train_process,
args=(world_size,),
nprocs=world_size,
join=True)
DP vs DDP 核心区别总结 (面试必考!):
| 特性 | DataParallel (DP) | DistributedDataParallel (DDP) |
|---|---|---|
| 实现方式 | 单进程,多线程 | 多进程,每个 GPU 一个进程 |
| GIL 瓶颈 | 存在 | 无 |
| 适用范围 | 仅单机多卡 | 单机多卡、多机多卡 |
| 负载均衡 | 差,主 GPU 瓶颈明显 | 好,各 GPU 负载均衡 |
| 参数更新 | 主 GPU 收集损失 -> 更新 -> 广播参数 | All-Reduce 同步梯度 -> 各自独立更新参数 |
| 通信效率 | 较低,通信开销大 | 较高,All-Reduce + 计算通信重叠 |
| 模型并行 | 不支持 | 支持 |
| 推荐使用 | 不推荐 | 推荐 |
DP 与 DDP 数据传输细节对比:
-
DP:
- Scatter 输入数据到各 GPU。
- Broadcast/复制 模型参数到各 GPU (或者说每次前向隐式依赖主卡模型)。
- Gather 输出到主 GPU 计算 loss。
- (隐式) 主 GPU 计算梯度并更新模型参数。
- Broadcast 更新后的模型参数到其他 GPU。
- 瓶颈: Gather 和 Broadcast 步骤都以主 GPU 为中心,通信量大且集中。
-
DDP:
- (初始化时) Broadcast 初始模型参数。
- 各 GPU 独立计算前向和反向。
- All-Reduce 梯度。这是主要的通信开销,但效率高且负载均衡。
- 各 GPU 独立更新参数。
- 优势: 通信发生在梯度层面,且通过 All-Reduce 分散进行,可与计算重叠。
四、FullyShardedDataParallel (FSDP) - 驾驭巨型模型的利器
DDP 已经很棒了,但对于 GPT-3 这种千亿、万亿参数的巨型模型,DDP 还是会遇到瓶颈:每个 GPU 仍然需要存储完整的模型参数、梯度和优化器状态。即使有 8 张 A100,每张 80GB 显存,也可能装不下一个超大模型及其训练状态。
怎么办?分片 (Sharding)!
FSDP 的核心思想源于 Microsoft 的 ZeRO (Zero Redundancy Optimizer) 优化器。ZeRO 的目标是消除分布式训练中的内存冗余。
ZeRO 的核心洞察: 在 DDP 中,虽然计算是并行的,但每个 GPU 都存着一份完整的:
- 模型参数 (Model Parameters)
- 梯度 (Gradients)
- 优化器状态 (Optimizer States) (例如 Adam 优化器需要存储动量
m和方差v,这通常是模型参数大小的两倍!)
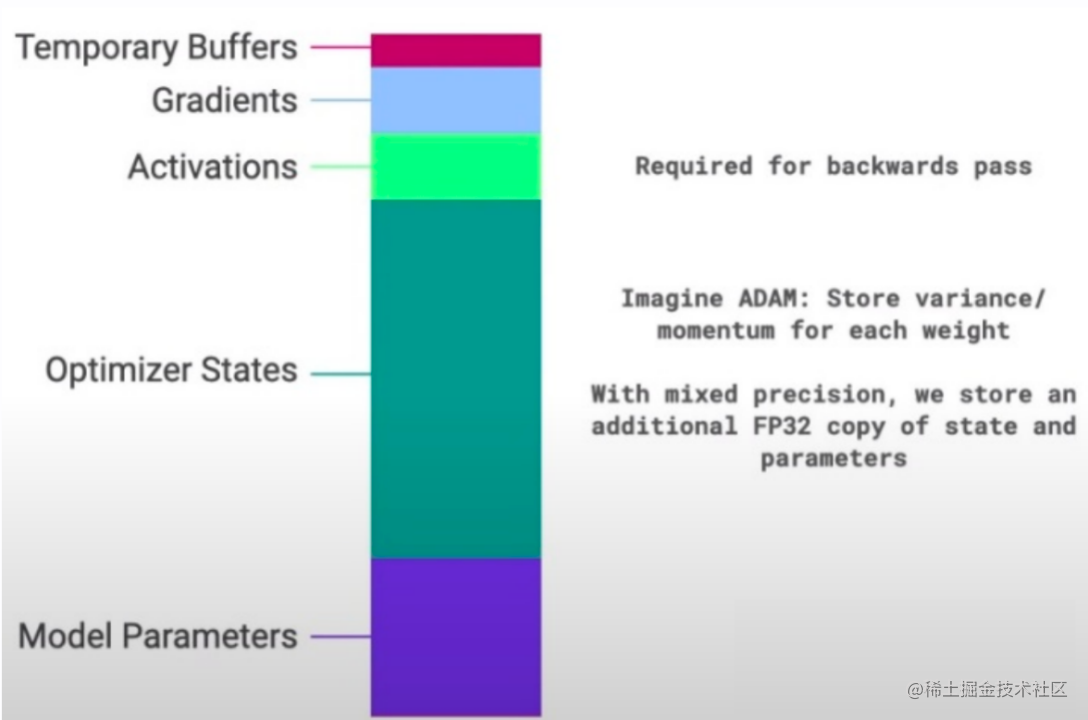
图8:混合精度训练中显存占用分布(模型状态是大头)
ZeRO 提出,这些状态信息在整个训练过程中并非所有时刻都需要完整地存在于每个 GPU 上。因此,可以将它们分片 (Shard),让每个 GPU 只负责存储和更新其中的一部分 (1/N)。
ZeRO 的三个级别:
- ZeRO-1 (Optimizer State Sharding):只对优化器状态进行分片。每个 GPU 只保存 1/N 的优化器状态。更新参数时,需要 AllGather 对应的参数,更新完后再丢弃。梯度还是需要 All-Reduce。
- ZeRO-2 (Optimizer State & Gradient Sharding):对优化器状态和梯度都进行分片。梯度计算出来后,不再进行 All-Reduce,而是通过 Reduce-Scatter 操作,让每个 GPU 只得到它负责那部分参数的最终梯度。然后用这个分片梯度更新对应的分片优化器状态和分片参数。通信量进一步减少。
- ZeRO-3 (Optimizer State & Gradient & Parameter Sharding):终极形态!把模型参数也分片了。每个 GPU 平时只持有 1/N 的模型参数。
- 在前向传播计算某一层时,通过 All-Gather 临时从其他 GPU 获取该层所需的完整参数。
- 计算完成后,立即丢弃非自己负责的那部分参数,释放显存。
- 反向传播类似。梯度通过 Reduce-Scatter 同步。
- 最后,每个 GPU 只更新自己负责的那 1/N 的参数。
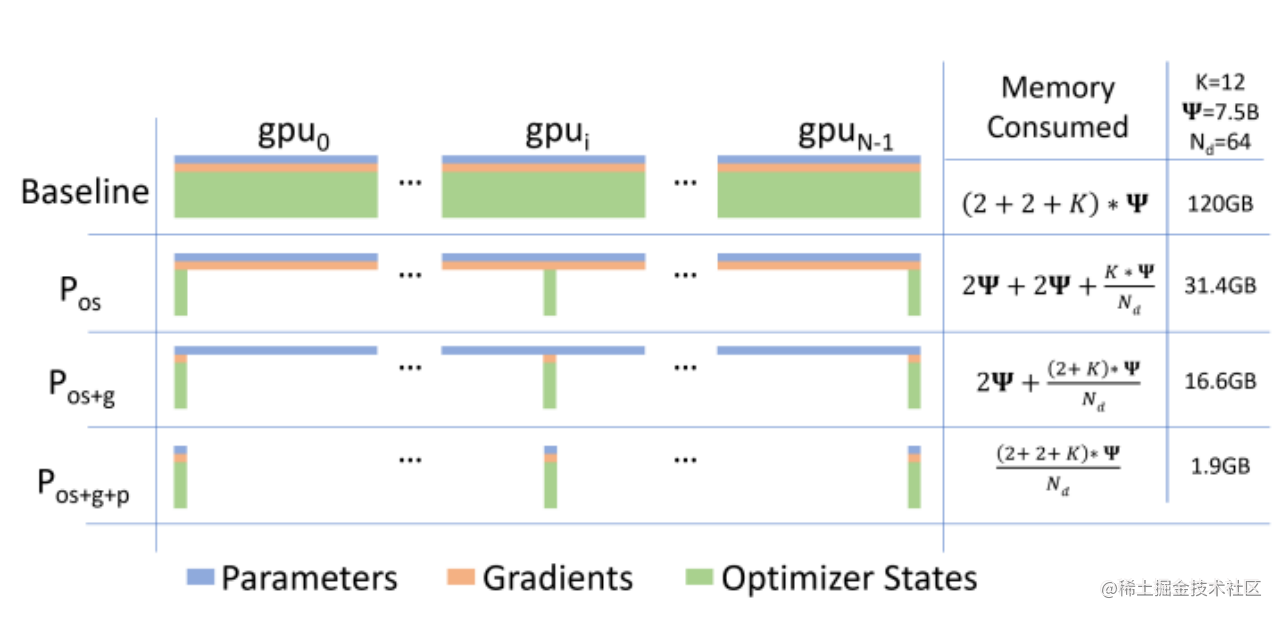
图9:ZeRO 不同级别的分片策略
PyTorch FSDP 就是 ZeRO-3 思想的原生实现。
FSDP 工作流程 (简化版,对应 ZeRO-3):
- 初始化 & 分片:模型参数、梯度、优化器状态都被均匀地分片到所有 GPU 上。每个 GPU 只持久保有 1/N 的完整状态。
- 前向传播 (逐层进行):
- 当计算第 L 层时,All-Gather 操作会收集所有 GPU 上关于第 L 层的参数分片,在每个 GPU 上临时重构出完整的第 L 层参数。
- 用完整的第 L 层参数执行前向计算。
- (可选优化
reshard_after_forward=True) 计算一结束,立即释放不属于自己分片的那些参数,回收显存给下一层使用。
- 反向传播 (逐层进行):
- 同样,计算第 L 层的梯度前,先 All-Gather 重构完整的第 L 层参数。
- 计算梯度 (此时每个 GPU 上有对应层的完整梯度)。
- Reduce-Scatter 操作会将完整梯度进行聚合和分发,使得每个 GPU 只得到它负责的那部分参数的最终平均梯度。
- (可选优化) 释放临时的完整参数和非本分片的梯度。
- 参数更新:每个 GPU 使用自己持有的分片梯度和分片优化器状态,来更新自己负责的分片模型参数。
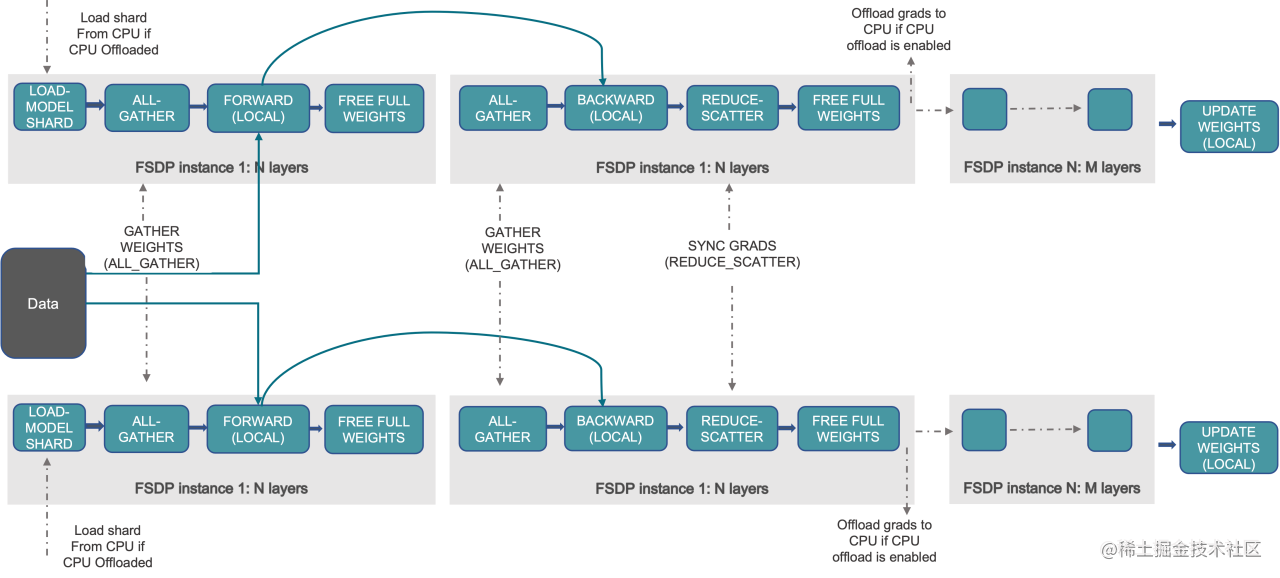
图10:FSDP 工作流程示意
FSDP 的核心优势:
- 极大地降低了单个 GPU 的峰值显存占用:因为它不需要在任何时候都持有完整的模型参数、梯度和优化器状态。这使得在同等硬件条件下可以训练更大的模型,或者使用更大的
batch_size。 - 保持了数据并行的简单性:从用户角度看,使用 FSDP 仍然主要是对模型进行包装,训练循环代码改动不大。
- 与 DDP 类似的计算效率:通过 All-Gather 和 Reduce-Scatter 操作,并结合计算通信重叠,可以达到接近 DDP 的训练速度。
- CPU Offload (可选):可以将不活跃的分片参数、梯度、优化器状态临时卸载到 CPU 内存,进一步节省 GPU 显存,但会增加 CPU-GPU 的通信开销。
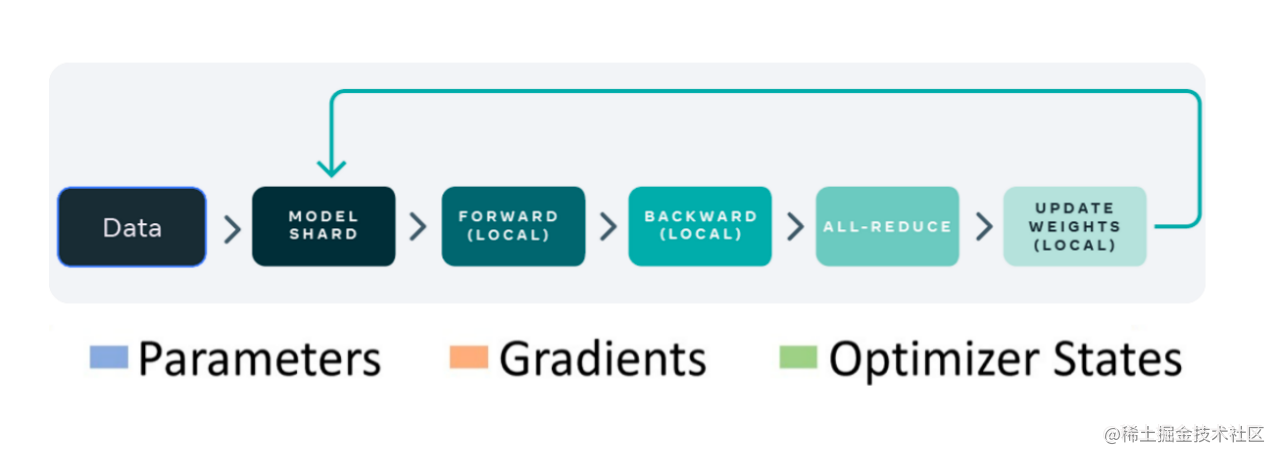
解锁ZeRO/FSDP的关键是我们可以把DDP之中的All-Reduce操作分解为独立的 Reduce-Scatter 和 All-Gather 操作。
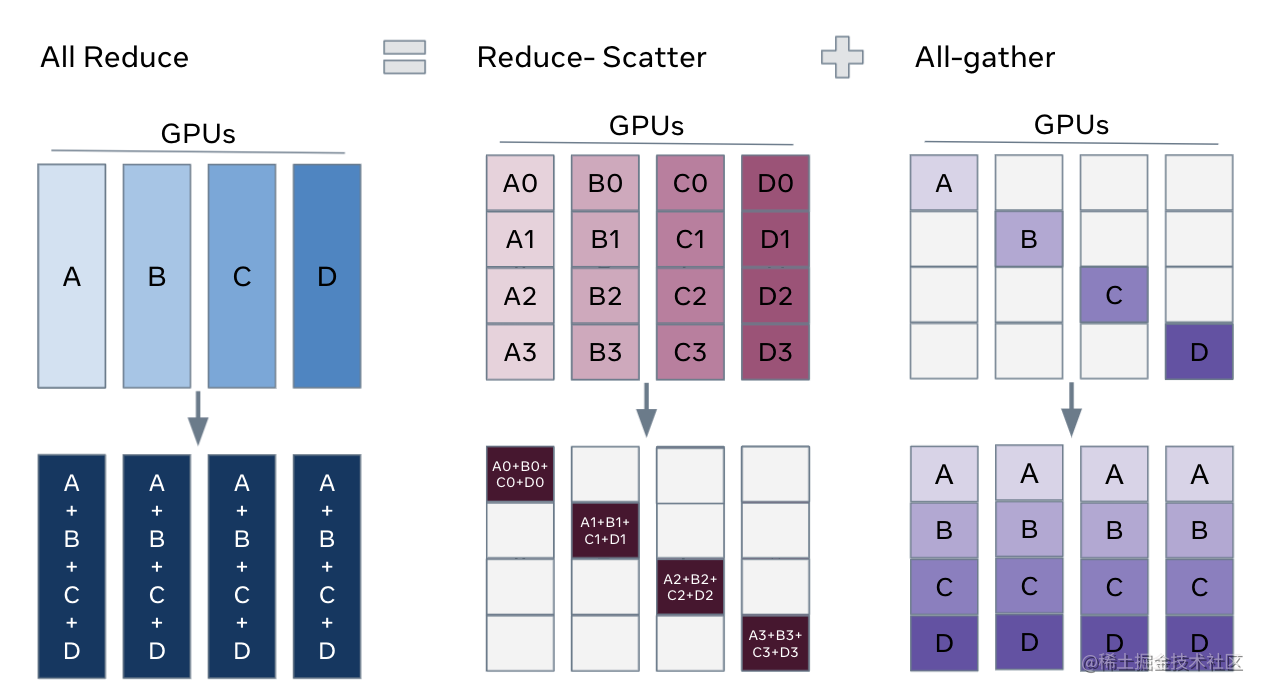
All-Reduce 是 Reduce-Scatter 和 All-Gather 的组合。聚合梯度的标准 All-Reduce 操作可以分解为两个单独的阶段。
- Reduce-Scatter 阶段,在每个GPU上,会基于 rank 索引对 rank 之间相等的块进行求和。
- All-Gather 阶段,每个GPU上的聚合梯度分片可供所有GPU使用。
通过重新整理 Reduce-Scatter 和 All-Gather,每个 DDP worker只需要存储一个参数分片和优化器状态。
FSDP 与 DDP 的关键区别:
| 特性 | DistributedDataParallel (DDP) | FullyShardedDataParallel (FSDP) (ZeRO-3) |
|---|---|---|
| 状态存储 | 每个 GPU 存储完整模型参数、梯度、优化器状态 | 每个 GPU 只持久存储分片的模型参数、梯度、优化器状态 |
| 显存占用 | 高,受限于单卡容量 | 低,显著降低峰值显存 |
| 核心通信操作 | All-Reduce (梯度) | All-Gather (参数), Reduce-Scatter (梯度) |
| 主要应用场景 | 常规大小模型,效率优先 | 超大规模模型,显存优先 |
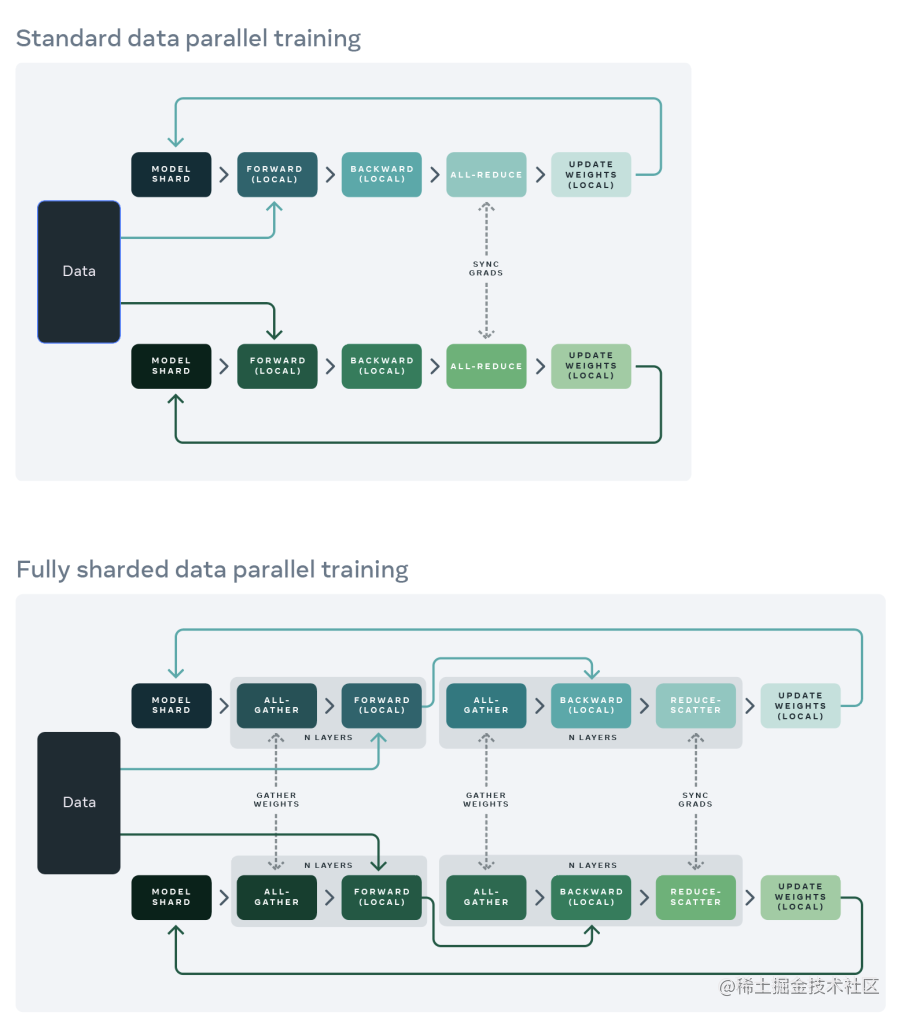
图11:DDP vs FSDP 对比
如何使用 FSDP (简化概念):
PyTorch 提供了方便的 API 来使用 FSDP,主要通过 FullyShardedDataParallel 类包装模型层。
-
自动包装 (Auto Wrapping):类似 DDP,可以设置一个策略(如按模块大小)自动递归地包装模型层。
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP from torch.distributed.fsdp.wrap import size_based_auto_wrap_policy import functools # Define your large model my_model = MyLargeModel() # Define auto wrap policy (e.g., wrap layers larger than 100M parameters) auto_wrap_policy = functools.partial( size_based_auto_wrap_policy, min_num_params=100*1000*1000 ) # Wrap the model with FSDP using the auto wrap policy fsdp_model = FSDP(my_model, auto_wrap_policy=auto_wrap_policy, device_id=torch.cuda.current_device()) # Training loop remains similar optimizer = torch.optim.Adam(fsdp_model.parameters(), lr=1e-4) # ... rest of the training loop ... -
手动包装 (Manual Wrapping):可以更精细地控制哪些模块被 FSDP 包装。
FSDP 的使用通常还需要配合 torch.distributed 的初始化等设置,与 DDP 类似。
五、总结与面试建议
好了,我们回顾一下 PyTorch 数据并行的演进之路:
DataParallel(DP):元老,易用但效率低、负载不均,有 GIL 瓶颈,基本弃用。面试时知道它的缺点即可。DistributedDataParallel(DDP):主流,多进程无 GIL 瓶颈,负载均衡,通过 All-Reduce 高效同步梯度且能与计算重叠,支持多机多卡。是目前分布式训练的标准实践。面试重点掌握其原理、优势和与 DP 的区别。FullyShardedDataParallel(FSDP):前沿,基于 ZeRO 思想,通过分片极大降低单卡显存峰值,使得训练超大模型成为可能。核心操作是 All-Gather 参数和 Reduce-Scatter 梯度。是训练巨型模型的利器。面试时理解其动机(解决显存瓶颈)、核心机制(分片)和与 DDP 的关键差异(状态存储和通信方式)。
面试小贴士 Revisit:
- DDP vs DP 优势:
- 多进程 vs 多线程: DDP 避免 GIL 瓶颈。✅
- 通信效率: DDP 使用 All-Reduce(通常是 Ring All-Reduce),比 DP 的 Gather/Scatter + Broadcast 更高效,负载更均衡。✅
- 负载均衡: DDP 各 GPU 负载一致,DP 主卡是瓶颈。✅
- FSDP:
- 动机: DDP 仍需在每卡存完整模型状态,FSDP 通过分片解决超大模型显存问题。✅
- 机制: 分片参数、梯度、优化器状态;通信变为 All-Gather (参数) + Reduce-Scatter (梯度)。✅
给面试同学的建议:
- 清晰地解释 DP 的主要缺点,说明为什么现在推荐 DDP。
- 准确描述 DDP 的工作流程,特别是 All-Reduce 同步梯度和计算通信重叠的优化。
- 说明 FSDP (或 ZeRO) 出现的背景(解决超大模型显存瓶颈),以及它的核心思想(分片)。
- 能够比较 DDP 和 FSDP 在显存占用、通信模式上的关键区别。
- 如果能提到 Ring All-Reduce、Reduce-Scatter、All-Gather 等具体通信原语,并解释它们在对应并行策略中的作用,会是加分项。
希望这篇博客能帮助大家系统地理解 PyTorch 中的数据并行技术。分布式训练是通往大模型之路的基石,掌握好它,无论是在面试还是未来的工作中,都将受益匪浅。
如果大家有任何疑问,欢迎在评论区交流讨论!祝大家学习进步,面试顺利!
参考:
https://zhuanlan.zhihu.com/p/650002268



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









