







假如你功能都测的差不多了(自动化的前提)
假如公司现在说要做自动化,怎么办?
第一步,分析整个项目是否符合做ui自动化,
是不是长期项目,是不是甲方的, 是不是需求变化不是很频繁的(可以适当变化)
搞清楚这个也就是说开始决定做ui自动化了,
第二步 需求分析
假如公司现在要做回归测试,或者兼容性测试,并且已经考虑清楚做ui自动化了
那么我们这个时候,第一步就是分析需求,比如分析什么模块适合做自动化,从中去分析去挑选适合做自动化的测试范围,
把要测的范围整理成文档或者流程图
第三步 测试计划
分析好了后,就是做计划
比如测试计划里写拿些人搞自动化,多久搞完,用什么技术?交付条件是什么?
例子: 现在就你一个人搞自动化测试,搞两个月,用python + selenium + pytest + pom分层的设计模式 交付条件就是所有涉及核心用例通过100%,涉及普通业务的通过98%,其他不重要的用例通过95%
第四步 测试用例
这个时候就是把前面的功能测试用例再筛选一遍,看哪些是适合做自动化的,如果你不怕累,也可以全部做但有些是没必要做的,比如一个很长的业务流程,涉及的代码比较复杂,你写代码要一天,我测试20秒,性价比就不高了,这个看个人,不过总体用例肯定是要多包涵核心功能,核心业务的,或者那种不适人工的,比如重复太多的(反复点击一个按钮一千次),
第五步就是执行测试
前面讲的技术采用python + selenium + pytest + pom
执行测试也就是自动化测试的核心步骤
首先你得把框架搭建起来,对吧,也就是
这个程序是由哪些包组成的,本来我们写一个线性模块就可以的,但是我们还是需要封装,减轻代码量
(是的就是代码量,就是让代码简洁一点,仅此而已)
废话不多说开始封装
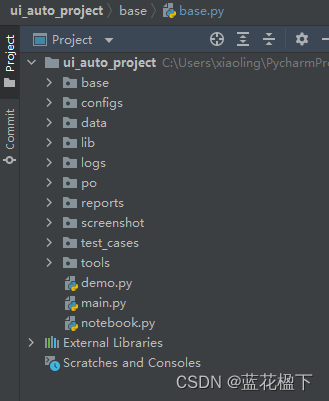
首先是base base就是个文件夹,然后里面存储了selenium的原生方法,方便后面的页面对象调用,其他暂时不用管,你只要知道里面存的是selenium原生方法就行了,至于什么是原生方法,什么是页面对象,后面慢慢讲
然后是config 如你所见,里面是存的配置文件,比如一些文件的目录,后续脚本会用到的一些常量
为啥会有这个配置文件(配置就是里面有一些变量,然后在其他地方会使用这些变量,使用不同的变量,这个地方就会有不一样的结果,我们就可以通过改变配置,达到不同的效果)
接着data data里面就是存储的一些数据,我们自动化需要用到的一些数据,比如数据驱动会用到的数据文件(存自动化数据的,就这么简单)
还有lib 这个就是第三方插件,或者说模块,比如我打印报告好看一点需要用到HTMLTestRunner_PY3这个模块,就可以放在里面
logs 放用例执行日志的文件夹
po 就是页面对象 (这个是啥呢?可以理解成把你的项目的一个个页面的测试操作封装成一个个的对象,这东西见仁见智,有的觉得好,有的觉得麻烦)
report 存测试报告的的文件夹
screenshot 截图 里面存储的是一张张的报错截图,就是用例不通过的时候,会截图,然后放在这里
test_cases 这个存储的就是我们的测试用例了
还有tools 里面存储的就是一些自定义的一些方法,比如数据库操作,日志器封装,等等,等等
整体的自动化架构就是这些
框架搭建好了之后,然后就是开始编写代码了
现在我们把前面的一个个用例实现就可以了
完了
开个玩笑,还没完呢
怎么实现呢,假如现在是测试登录模块.此时已经有用例了,拿一条用例过来
测试编号:001
测试标题:所有输入框输入正确(数据:用户名:蓝花楹下,密码:199828),点击登录,成功登录
测试模块:登录
测试优先级:高
前提条件:有账号蓝花楹下
操作步骤
1.打开火狐浏览器
2.输入网址,打开系统登录界面
3.检查登录各输入框是否有内容,并清空内容,保证输入框为空
4.在输入框输入账号密码
5.点击验证码,获取验证码,并把验证码输入验证码输入框
6.点击登录
7.检查是否成功登录,到了主页.
预期结果
成功到达主页
实际结果:
也就是我们在test_cases测试用例那个包里面,把这个测试步骤用脚本实现就行了.
"""
作者:樱下
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from tools.verify_code_tool import VerifyCodeTool
driver = webdriver.Firefox() # 创建一个浏览器驱动
driver.get("你的登录网址") # 打开登录的网址
driver.find_element(By.XPATH, "账户元素的xpath路径").clear() #清空用户名输入框
driver.find_element(By.XPATH, "账户元素的xpath路径").send_keys("蓝花楹下") # 输入用户名
driver.find_element(By.XPATH, "密码元素的xpath路径").clear() # 清空密码输入框
driver.find_element(By.XPATH, "密码元素的xpath路径").send_keys("199828") # 输入密码
driver.find_element(By.XPATH, "验证码图片元素的xpath路径").click() # 点击验证码
code = VerifyCodeTool.get_verify_code("验证码图片元素的xpath") # 通过自定义方法获取验证码
driver.find_element(By.XPATH, "验证码输入框元素的xpath路径").clear() # 清空验证码输入框
driver.find_element(By.XPATH, "验证码输入框元素的xpath路径").send_keys(code) # 输入验证码
driver.find_element(By.XPATH, "登录按钮元素的xpath路径").click() # 点击登录
value = driver.find_element(By.XPATH, "首页随便一个元素的xpath").text # 获取首页随便一个元素的值
assert "这个元素的应该显示的值" == value 通过这个元素的值做对比,判断预期的和实际的是否相等,通过则测试用例通过,反之则fail首先
driver = webdriver.Firefox() 的意思是创建一个火狐浏览器
在讲这行代码之前呢?我先讲一个概念,
就是老板,员工,电脑三者直接的关系。请问老板需要操作电脑吗?
不需要对吧,是不是老板指挥你,没错就是你~打工人,然后让你去操作电脑。对吧
然后操作浏览器也是同样的道理。
请问脚本需要直接去操作浏览器吗?不需要对吧。他只需要一个打工人就可以了。那就是浏览器驱动
也就是我们实现自动化的原理就是脚本控制浏览器驱动去操作浏览器就可以了。
讲完了这个概念,那么要实现自动化,是不是得要有浏览器对应的驱动呢?
所以讲这行代码之前,我们要先把浏览器对应的驱动下载好,并且添加驱动的环境变量(就是把驱动的路径告诉系统。这样的话咱的脚本才能通过系统知道这个打工人在哪个地方,才能更好的让驱动996工作啊)
那么我们驱动下载好并添加了环境变量之后
还要安装一个库selenium
pip install selenium
这个库里面呢就是封装的各种操作驱动的方法。
回来看看这行代码了
from selenium import webdriver
webdriver 是selenium 库里面的模块,
driver = webdriver.Friefox() 这行代码就是实例化一个驱动对象,然后这个driver里面有各种针对浏览器的方法和属性
~同时执行这行代码会打开浏览器
话不多说,现在就可以使用driver里面的方法和属性去调用驱动,然后让驱动干活了
driver.get("网站网址") 调用driver对象的get方法,里面传一个网址参数,就可以让驱动去输入网址并访问了。
也就是前面两行代码就会让驱动打开浏览器,并输入想要访问的网址并访问
再看第三行代码
driver.find_element(By.XPATH, "用户名元素的xpath路径").clear()
这一行代码的意思就是找到用户名输入框,然后清空里面的内容
在讲这行代码之前,我们要先学习一下元素的定位方式
请跳转至本专栏的另一篇博客,<<元素定位方式>>
待更新....















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









