







目录
闭包
例如要实现一个存钱的功能,可以这么做
account_amount = 0
def atm(num,deposit = True):
global account_amount
if deposit:
account_amount += num
else:
account_amount -= num
print(account_amount)
这样是运用了外部变量构建函数实现,但是这样的缺点是,外部变量容易被篡改
那么我们可以运用闭包
def card(account_num=0):
def ATM(num,deposit=True):
nonlocal account_num
if deposit:
account_num += num
else:
account_num -= num
print(account_num)
return ATM1.什么是闭包
定义双层嵌套函数,内层函数可以访问外层函数的变量
将内存函数作为外层函数的返回,此内层函数就是闭包函数
2.闭包的好处和缺点
- 优点:不定义全局变量,也可以让函数持续访问和修改一个外部变量
- 优点:闭包函数引用的外部变量,是外层函数的内部变量。作用域封闭难以被误操作修改
- 缺点:额外的内存占用
3.nonlocal关键字的作用
在闭包函数(内部函数中)想要修改外部函数的变量值,需要用nonlocal声明这个外部变量
装饰器
普通用法
可以参考这篇博客
装饰器本质上是一个Python函数(其实就是闭包),它可以让其他函数在不需要做任何代码变动的前提下增加额外功能
一般写法:
def func1():
print('我是func1')
def func2(func):
def inner():
print('我是func2开始')
func()
print('我是func2结束')
return inner
a = func2(func1)
a()语法糖写法
def func2(func):
def inner():
print('我是func2开始')
func()
print('我是func2结束')
return inner
@func2
def func1():
print('我是func1')
func1()多层装饰器
def func2(func):
def inner():
print('我是func2开始')
func()
print('我是func2结束')
return inner
def func3(func):
def inner():
print('func3开始')
func()
print('func3结束')
return inner
@func3
@func2
def func1():
print('我是func1')
func1()
# func3开始
# 我是func2开始
# 我是func1
# 我是func2结束
# func3结
相当于
func3(func2(func1))设计模式
单例模式
对于一个这样的类
class tools:
pass如果我在很多地方需要使用它,一般会这么做
a = tools()
b = tools()
print(a)
print(b)
# <__main__.tools object at 0x00000210AA9D7710>
# <__main__.tools object at 0x00000210AA9DD208>可以看到不同的实例,内存是不一样的,也就是说这两个实例是独立的。
但是如果这是一个工具类,我们在不同的地方使用同一个实例就可以了
tool = tools()
a=tool
b=tool
print(a)
print(b)
# <__main__.tools object at 0x00000210AA9DD278>
# <__main__.tools object at 0x00000210AA9DD278>一般开发中,会把下面的代码放在一个单独的文件,然后别的地方要用的时候直接import调用tool就可以了
class tools:
pass
tool = tools()工厂模式
Python并发编程
CPU密集型任务和IO密集型任务
CPU密集型(CPU-bound ) :
CPU密集型也叫计算密集型,是指V/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高
例如:压缩解压缩、加密解密、正则表达式搜索
IO密集型(l/O bound) :
IO密集型指的是系统运作大部分的状况是CPU在等I/O(硬盘/内存)的读/写操作,CPU占用率仍然较低。
例如:文件处理程序、网络爬虫程序读写数据库程序
多线程、多进程、多协程的对比
多进程Process ( multiprocessing)·
优点:可以利用多核CPu并行运算
缺点:占用资源最多、可启动数自比线程少,适用于:CPU密集型计算
一个进程中可以启动N个线程
多线程Thread ( threading)
·优点:相比进程,更轻量级、占用资源少·缺点:
·相比讲程:多线程只能并发执行,不能利用多CPU ( GIL)·相比协程:启动数目有限制,占用内存资源,有线程切换开销
·适用于:IO密集型计算、同时运行的任务数目要求不多
一个线程中可以启动N个协程
多协程Coroutine ( asyncio )
·优点:内存开销最少、启动协程数量最多
·缺点:支持的库有限制(aiohttp vs requests)、代码实现复杂。适用于:IO密集型计算、需要超多任务运行、但有现成库支持的场景
方法选择
任务是CPU密集型,选择多进程Process ( multiprocessing)·
任务是IO密集型:
是否需要超多任务量?
是否有现成的协程库支持?
协程的复杂度是否可以接受?
如果都是,那么用多协程Coroutine ( asyncio ),否则多线程Thread ( threading)
多线程
基础使用
python多线程的基础使用:
import threading
thread_obj = threading.Thread([group [, target [, name [, args [,kwarngs[,daemon=None]]]]])
#
# group:暂时无用,未来功能的预留参数
# target:执行的目标任务名
# args:以元组或者列表的方式给执行任务传参
# kwargs:以字典方式给执行任务传参
# name:线程名,一般不用设置
# daemon 参数将显式地设置该线程是否为守护模式
#启动线程,让线程开始工作
thread_obj.start()通过小案例来体会多线程
import threading
import time
def func1():
while 1:
print(111)
time.sleep(1)
def func2():
while 1:
print(222)
time.sleep(1.5)
thread_1 = threading.Thread(target=func1)
thread_2 = threading.Thread(target=func2)
thread_1.start()
thread_2.start()当函数需要传递参数时,就可以用到args,kwargs了,需要注意的是args必须是元组或者列表(默认元组),kwargs必须是字典
import threading
import time
def func1(msg):
while 1:
print(msg)
time.sleep(1)
def func2(msg1,msg2):
while 1:
print(msg1)
print(msg2)
time.sleep(1.5)
thread_1 = threading.Thread(target=func1,args=(111,))
thread_2 = threading.Thread(target=func2,kwargs={'msg1':222,'msg2':333})
thread_1.start()
thread_2.start()
#得到当前的线程
import threading
import threading
import time
def func1(msg):
while 1:
time.sleep(1)
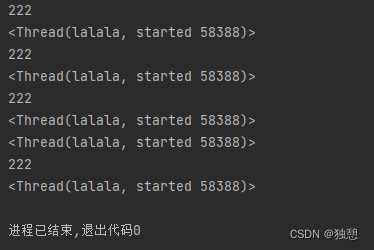
print(threading.currentThread())
thread_1 = threading.Thread(target=func1,args=[111],name='lalala')
thread_1.start()
可以使用threading.currentThread()得到当前的进程,如果指定了线程名字,会显示进程名字
守护线程
启动python时,会生成一个主线程,我们可以通过之前的方法生成子线程,当所有子线程都结束了,主线程才会结束
threading提供了一个daemon参数,默认是False,如果是True,则表示主线程不会等待这个线程,等别的子线程结束就直接结束主线程
例如
import threading
import time
def func1():
for i in range(5):
time.sleep(1)
print(threading.currentThread())
def func2():
while 1:
print(222)
time.sleep(1.5)
thread_1 = threading.Thread(target=func1,name='lalala')
thread_2 = threading.Thread(target=func2,daemon=True)
thread_1.start()
thread_2.start()func1内的代码执行五次后就会结束运行
线程阻塞join方法
join(timeout=None)
- 等待,直到线程终结。这会阻塞调用这个方法的线程,直到被调用 join() 的线程终结 -- 不管是正常终结还是抛出未处理异常 -- 或者直到发生超时,超时选项是可选的。
- 当 timeout 参数存在而且不是
None时,它应该是一个用于指定操作超时的以秒为单位的浮点数或者分数。因为 join() 总是返回None,所以你一定要在 join() 后调用 is_alive() 才能判断是否发生超时 -- 如果线程仍然存活,则 join() 超时。- 当 timeout 参数不存在或者是
None,这个操作会阻塞直到线程终结。- A thread can be joined many times.
- 如果尝试加入当前线程会导致死锁, join() 会引起 RuntimeError 异常。如果尝试 join() 一个尚未开始的线程,也会抛出相同的异常
相当于给进程增加阻塞,需要等待timeout时间
我们分成三种情况分析这个功能
1、等待时间小于执行时间
def target():
time.sleep(7)
print("线程{}已退出".format(current_thread().name))
thread01 = Thread(target=target,name="1")
thread01.start()
thread01.join(timeout=5)
print(11111)
在这里,五秒之后输出11111,再经过2秒后输出 线程1已退出
相当于这里join阻碍了主线程,设置主线程需要等待我的thread01 5秒才能运行
2、等待时间大于执行时间
def target():
time.sleep(5)
print("线程{}已退出".format(current_thread().name))
thread01 = Thread(target=target,name="1")
thread01.start()
thread01.join(timeout=7)
print(11111)
再这里,五秒之后同时输出两个
也就是说join函数在timeout时间结束或者执行时间结束都会返回
3、设置dasman
def target():
time.sleep(5)
print("线程{}已退出".format(current_thread().name))
thread01 = Thread(target=target,daemon=True,name="1")
thread01.start()
thread01.join(timeout=3)
print(11111)
3秒后输入11111,不输出 其他
说明join可以无视守护线程的限制进行阻碍
线程锁 Lock
实现原始锁对象的类。一旦一个线程获得一个锁,会阻塞随后尝试获得锁的线程,直到它被释放;任何线程都可以释放它。
原始锁处于 "锁定" 或者 "非锁定" 两种状态之一。它被创建时为非锁定状态。它有两个基本方法, acquire() 和 release() 。当状态为非锁定时, acquire() 将状态改为 锁定 并立即返回。当状态是锁定时, acquire() 将阻塞至其他线程调用 release() 将其改为非锁定状态,然后 acquire() 调用重置其为锁定状态并返回。 release() 只在锁定状态下调用; 它将状态改为非锁定并立即返回。如果尝试释放一个非锁定的锁,则会引发 RuntimeError 异常。
当多个线程同时处理数据时,可能会发生错误,其实就是通过锁的方式 对数据进行保护
我们通过一个例子查看这个的作用
import time
import threading
lock = threading.Lock()
cash = 1000
def func1(money):
global cash
if cash>money:
time.sleep(1)
cash -= money
print('ok')
print(cash)
else:
print('no')
th1 = threading.Thread(target=func1,args=[600])
th2 = threading.Thread(target=func1,args=[600])
# ok
# ok
# -200
# -200由于两个线程同时开始,都会通过 cash>money的判断,从而使得同时减去600,输出负数
def func1(money):
global cash
lock.acquire()
if cash>money:
time.sleep(1)
cash -= money
print('ok')
print(cash)
else:
print('no')
lock.release()
th1 = threading.Thread(target=func1,args=[600])
th2 = threading.Thread(target=func1,args=[600])
#
th1.start()
th2.start()
# ok
# 400
# no增加线程锁之后,在th1调用时,不允许th2调用,起到了保护数据的作用
下面这篇文章说到,锁保证了python语句的 原子性 ,我觉得很有道理,可以参考一下
递归锁对象RLock
重入锁是一个可以被同一个线程多次获取的同步基元组件。在内部,它在基元锁的锁定/非锁定状态上附加了 "所属线程" 和 "递归等级" 的概念。在锁定状态下,某些线程拥有锁 ; 在非锁定状态下, 没有线程拥有它。
若要锁定锁,线程调用其 acquire() 方法;一旦线程拥有了锁,方法将返回。若要解锁,线程调用 release() 方法。 acquire()/release() 对可以嵌套;只有最终 release() (最外面一对的 release() ) 将锁解开,才能让其他线程继续处理 acquire() 阻塞
上面的Lock是不能被重复访问的,否则会陷入死锁状态
例如
import threading
lock = threading.Lock()
print(22222)
lock.acquire()
lock.acquire()
print(1111)
lock.release()
lock.release()输出22222只会就陷入了死锁状态,但是换成RLock就可以
我们可以看一下Rlock的源码
[threading]
class _RLock:
def __init__(self):
self._block = _allocate_lock() # _thread模块中定义一个锁对象的方法
self._owner = None # 用来标记哪个线程获取了锁
self._count = 0 # 计数器
def acquire(self, blocking=True, timeout=-1):
me = get_ident()
if self._owner == me:
self._count += 1
return 1
rc = self._block.acquire(blocking, timeout)
if rc:
self._owner = me
self._count = 1
return rc
def release(self):
if self._owner != get_ident():
raise RuntimeError("cannot release un-acquired lock")
self._count = count = self._count - 1
if not count:
self._owner = None
self._block.release()这里的 me代表方法的调用者,如果调用者就是锁的拥有者,则计数器加1,否则进行阻塞自己(也可能是获得锁)
可以看到,在重复得到锁的过程中,实际上只有第一次调用了acquire()方法,后面只进行了加1操作,解开锁的过程类似
但是需要注意的是,acquire()后必须搭配release(),若两者数量不相同,则仍然会陷入锁死
GIL锁
全局解释器锁(英语:Global Interpreter Lock,缩写GIL)
是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。
即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。
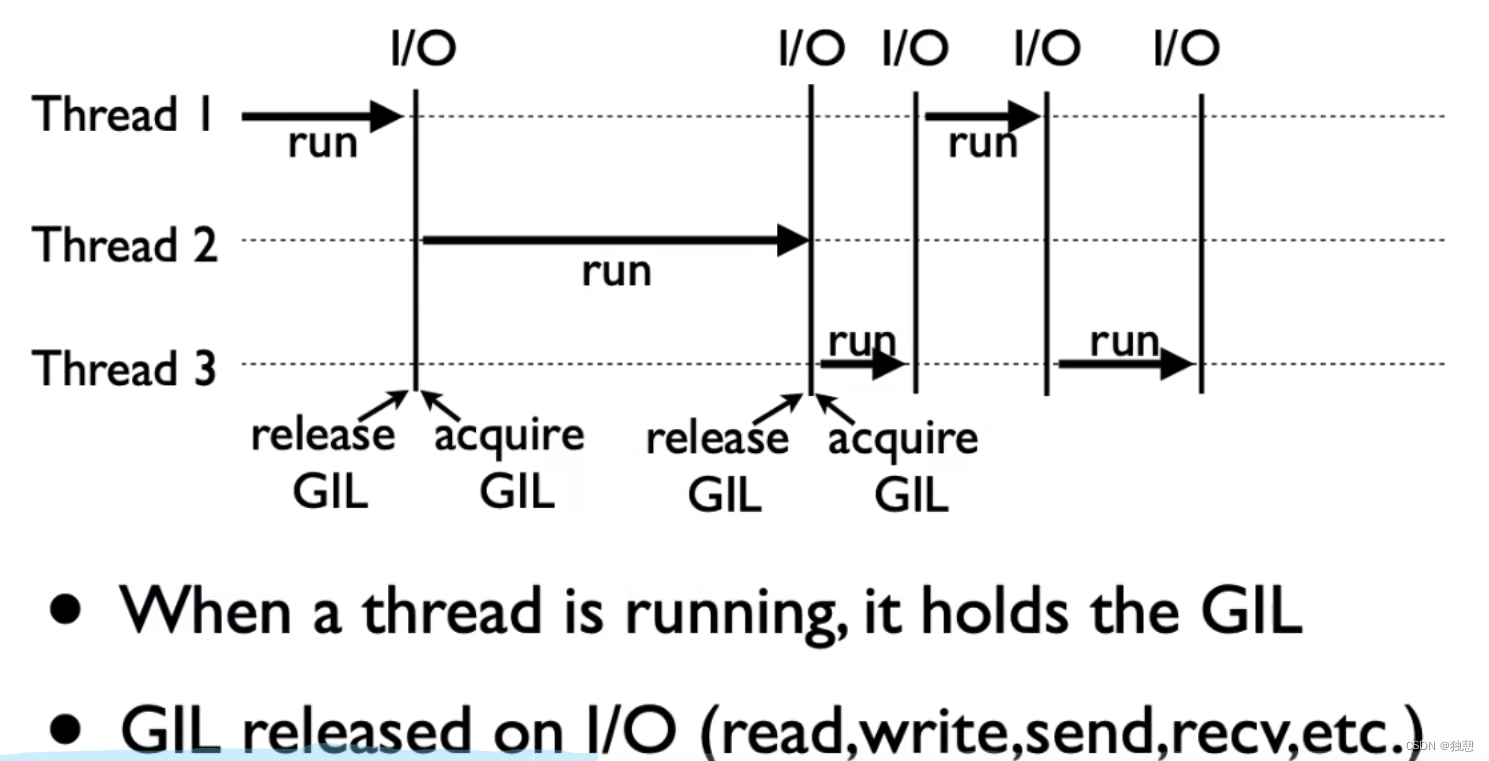
也就是线程在运行的时候获得GIL,当它到达IO时释放GIL
那为什么有GIL锁这个东西呢,下面这个视频讲的很好,可参考
Python速度慢的罪魁祸首,全局解释器锁GIL_哔哩哔哩_bilibili
ThreadPoolExecutor线程池
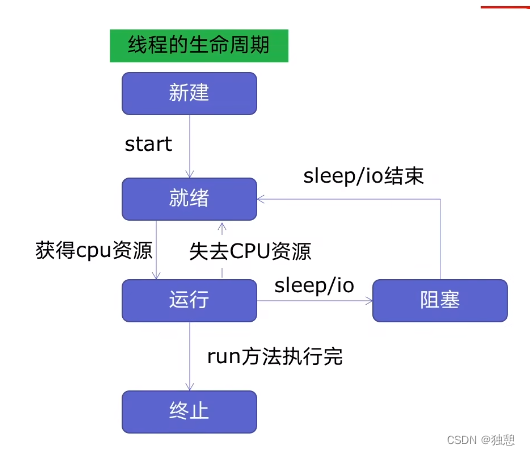
线程的生命周期如下图,面对需要生成很多线程的任务时,如果能将线程复用,就可以省去新建和终止线程的资源,线程池可以做到这一点
线程池的优点:
- 1、提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源;
- 2、适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短
- 3、防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题
- 4、代码优势:使用线程池的语法比自己新建线程执行线程更加简洁
用法:这里介绍两种用法:
1:使用map的方式,将url参数全部导入
import threading
import concurrent.futures
import requests
import time
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1,71)
]
def craw(url):
r = requests.get(url)
print(len(r.text))
return 1
with concurrent.futures.ThreadPoolExecutor() as pool:
results = pool.map(craw,urls)
for result in results:
print(result)
2、使用submit方式,将url一个一个输入,打印结果时也有两种方法,第一种是按照url顺序打印,第二种是按照完成的顺序打印
with concurrent.futures.ThreadPoolExecutor() as pool:
timenow = time.time()
futures = [pool.submit(craw,url)for url in urls]
for future in futures:
print(future.result())
for future in concurrent.futures.as_completed(futures):
print(future.result())这里推荐第二种,实测比第一种快很多
线程队列queue
1、导入类库import queue
2、创建Queue
q = queue.Queue()
3、添加元素
q.put (item)
4、获取元素
item = q.get()
5、查询状态
#查看元素的多少
q.qsize()
#判断是否为空
q.empty()
#判断是否已满
q.full()
多进程
基础实现
其实跟多线程是一样的
from multiprocessing import Process
def func():
print(11111)
if __name__ == '__main__':
p=Process(target=func)
p.start()
p.join()
Process类的其他方法
Process([group [, target [, name [, args [, kwargs]]]]])
group: 线程组
target: 要执行的方法
name: 进程名
args/kwargs: 要传入方法的参数
实例方法:
is_alive():返回进程是否在运行,bool类型。
join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)。
start():进程准备就绪,等待CPU调度
run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。
terminate():不管任务是否完成,立即停止工作进程
属性:
daemon:和线程的setDeamon功能一样
name:进程名字
pid:进程号进程对列Queue
进程是系统独立调度核分配系统资源(CPU、内存)的基本单位,进程之间是相互独立的,每启动一个新的进程相当于把数据进行了一次克隆,子进程里的数据修改无法影响到主进程中的数据,不同子进程之间的数据也不能共享,这是多进程在使用中与多线程最明显的区别。
进程对列Queue就可以实现进程通讯














 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









