






win10自带Hyper-V
Hyper-V是Win10自带的虚拟机安装管理工具,使用Hyper-V 可以比较方便地在win10上安装各种不同的虚拟机,包括各种版本的Linux,FreeBSD和Windows。
但是不少初学者在尝试使用该功能时,发现自己并不能直接在系统设置中打开Hyper-V,其中很大一部分是由于本身电脑版本问题。因此,我们需要注意的是,Hyper-V目前只可以在win10专业版、企业版和教育版上使用,无法在家庭版上使用。
win10家庭版无法使用Hyper-V的解决办法
我们可以先检查一下我们的电脑是否使用的是win10家庭版。
打开“设置->更新和安全->激活”,可以在“版本”一栏查看我们当前使用Windows版本。
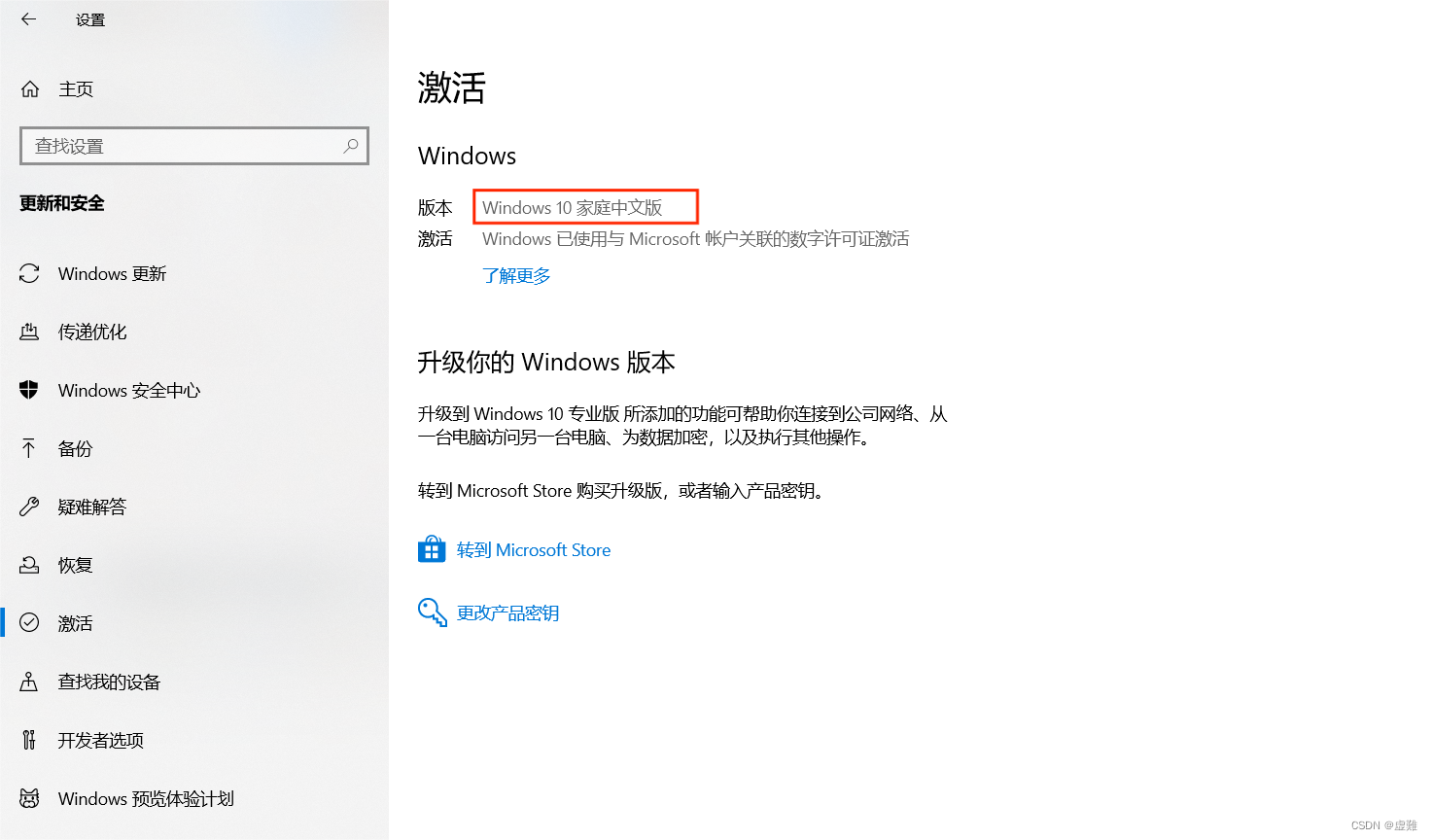
在该情况下,我们无法通过“设置->应用->程序和功能->启用或关闭Windows功能”,找到勾选Hyper-V的选项,但是我们可以通过以下方法实现:
①我们需要将下面的命令复制到新建的txt文件中,并将文档重命名为.cmd文件。
命令如下
pushd "%~dp0"
dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt
for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i"
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL
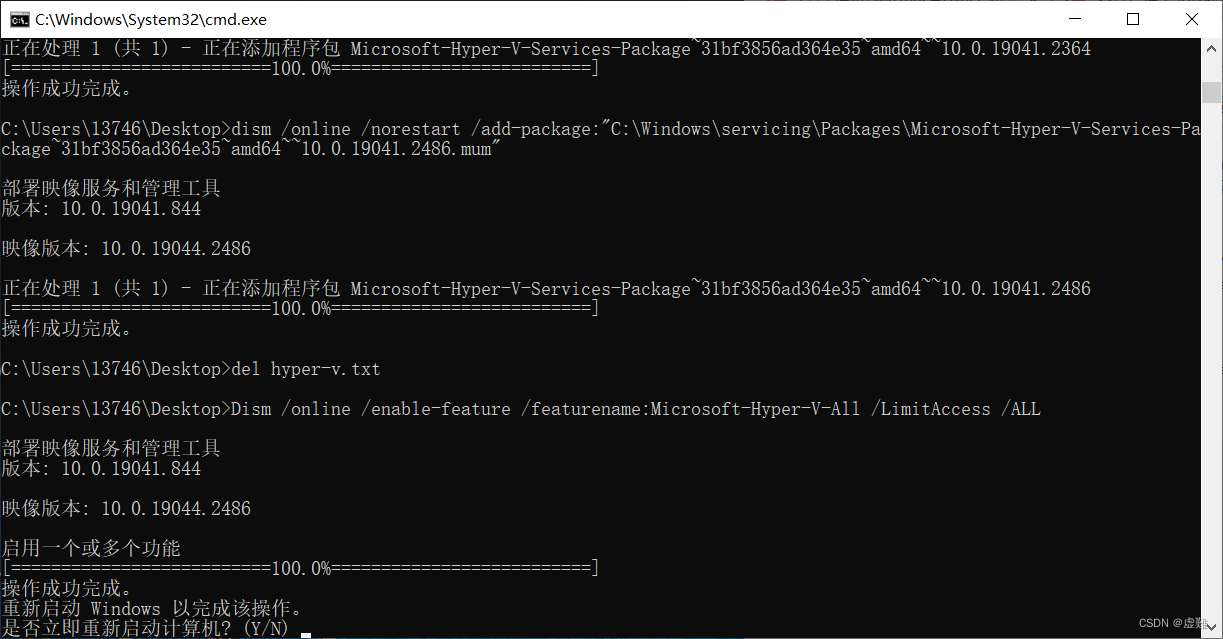
完成后文档样式如下:

②对该文件右键,以管理员身份运行该文档。脚本执行完毕后,按照提示输入Y,进行电脑重启。
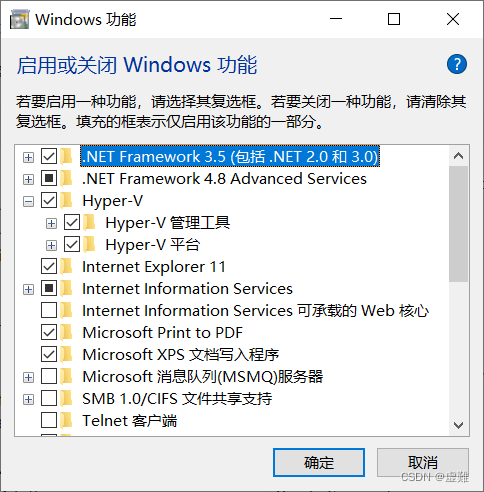
③步骤2输入Y重启电脑后,通过路径“设置->应用->程序和功能->启用或关闭Windows功能”,我们可以发现Hyper-v选项已经存在。

















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









