






1、数据集管理
1.1创建知识库(数据集)
功能
创建一个知识库(数据集)
请求方法
方法: POST
URL: /api/v1/datasets
请求头部
Headers:
'content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
application/json,表示请求体的媒体类型是JSON格式。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"name": string,
"avatar": string,
"description": string,
"language": string,
"embedding_model": string,
"permission": string,
"chunk_method": string,
"parser_config": object
}
请求体是一个JSON对象,包含以下字段:
- name(字符串,必填):
- 数据集的唯一名称。
- 允许字符:英文字母(大小写)、数字、下划线。
- 必须以英文字母或下划线开头。
- 最大长度65,535个字符。
- 不区分大小写。
- avatar(字符串):
- 数据集的头像,以Base64编码。
- description(字符串):
- 数据集的简短描述。
- language(字符串):
- 数据集的语言设置。
- 可选值:“English”(默认)、“Chinese”。
- embedding_model(字符串):
- 要使用的嵌入模型名称。
- permission(字符串):
- 指定谁可以访问该数据集。
- 可选值:“me”(默认,仅你可管理)、“team”(团队所有成员可管理)。
- chunk_method(枚举字符串):
- 数据集的分块方法。
- 可选值:“naive”(默认,通用)、“manual”(手动)、“qa”(Q&A)、“table”(表格)、“paper”(论文)、“book”(书籍)、“laws”(法律)、“presentation”(演示文稿)、“picture”(图片)、“one”(单一)、“knowledge_graph”(知识图谱)、“email”(电子邮件)。
- 注意:选择"knowledge_graph"前需确保LLM(可能是指大型语言模型)已在设置页面正确配置,且知识图谱会消耗大量Tokens。
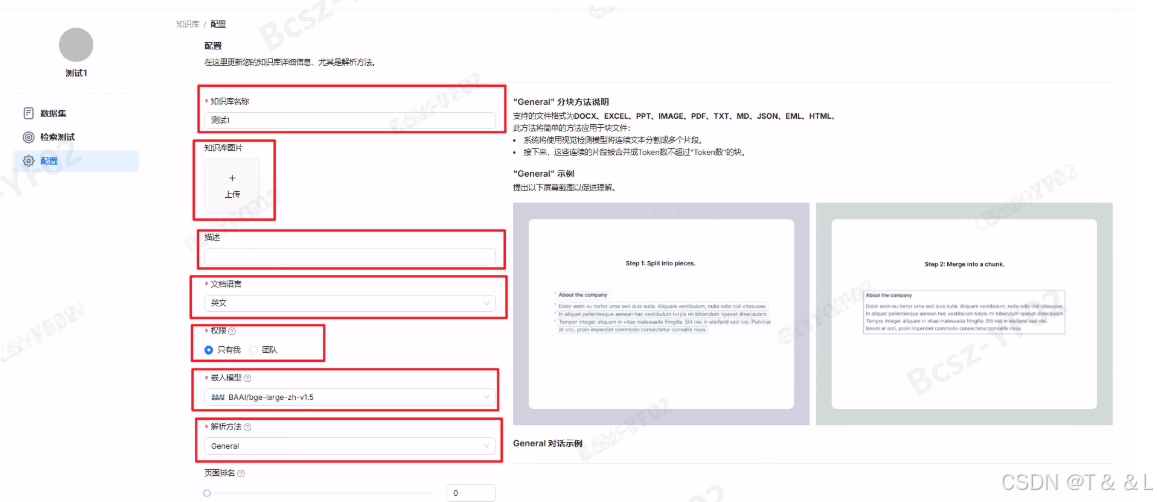
- parser_config(对象):
- 数据集解析器的配置设置。
- 属性根据
chunk_method的不同而变化。
成功
{
"code": 0,
"data": {
"avatar": null,
"chunk_count": 0,
"chunk_method": "naive",
"create_date": "Thu, 24 Oct 2024 09:14:07 GMT",
"create_time": 1729761247434,
"created_by": "69736c5e723611efb51b0242ac120007",
"description": null,
"document_count": 0,
"embedding_model": "BAAI/bge-large-zh-v1.5",
"id": "527fa74891e811ef9c650242ac120006",
"language": "English",
"name": "test_1",
"parser_config": {
"chunk_token_num": 128,
"delimiter": "\\n!?;。;!?",
"html4excel": false,
"layout_recognize": true,
"raptor": {
"user_raptor": false
}
},
"permission": "me",
"similarity_threshold": 0.2,
"status": "1",
"tenant_id": "69736c5e723611efb51b0242ac120007",
"token_num": 0,
"update_date": "Thu, 24 Oct 2024 09:14:07 GMT",
"update_time": 1729761247434,
"vector_similarity_weight": 0.3
}
}
失败
{
"code": 102,
"message": "Duplicated knowledgebase name in creating dataset."
}
1.2删除知识库(数据集)
功能
通过ID删除数据集。
请求方法
方法: DELETE
URL: /api/v1/datasets
请求头部
Headers:
'content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
application/json,表示请求体的媒体类型是JSON格式。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"ids": list[string]
}
请求体:JSON格式,包含一个名为ids的字段,该字段是一个字符串列表,表示要删除的数据集的ID。如果未指定,将删除所有数据集。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "You don't own the dataset."
}
1.3修改知识库(数据集)
功能
通过PUT请求更新指定数据集的配置。
请求方法
方法: PUT
URL: /api/v1/datasets/{dataset_id}
# dataset_id 为知识库(数据集)的id
请求头部
Headers:
'content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
application/json,表示请求体的媒体类型是JSON格式。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"name": string,
"embedding_model": string,
"chunk_method": enum<string>
}
请求体是一个JSON对象,包含以下字段:
- name(字符串,必填):
- 数据集的新名称
- embedding_model(字符串):
- 更新后的嵌入模型名称。在更新嵌入模型之前,请确保数据集的
chunk_count(分块计数)为0。
- 更新后的嵌入模型名称。在更新嵌入模型之前,请确保数据集的
- chunk_method(枚举字符串):
- 数据集的分块方法。
- 可选值:“naive”(默认,通用)、“manual”(手动)、“qa”(Q&A)、“table”(表格)、“paper”(论文)、“book”(书籍)、“laws”(法律)、“presentation”(演示文稿)、“picture”(图片)、“one”(单一)、“knowledge_graph”(知识图谱)、“email”(电子邮件)。
- 注意:选择"knowledge_graph"前需确保LLM(可能是指大型语言模型)已在设置页面正确配置,且知识图谱会消耗大量Tokens。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "You don't own the dataset."
}
1.4查询知识库(数据集)
功能
查询所有知识库(数据集)。
请求方法
方法: GET
URL: /api/v1/datasets?page={page}&page_size={page_size}&orderby={orderby}&desc={desc}&name={dataset_name}&id={dataset_id}
# page (可选)指定要显示数据集的页码,默认为1。
# page_size (可选)每页显示的数据集数量,默认为30。
# orderby (可选)指定排序的字段。可选值包括create_time(默认,创建时间)和update_time(更新时间)。
# desc(可选)指示是否按降序排序,默认为true。
# name(可选)指定要检索的数据集的名称。
# dataset_id (可选)指定要检索的数据集的ID。
请求头部
Headers:
'Authorization: Bearer <YOUR_API_KEY>'
- Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
成功
{
"code": 0,
"data": [
{
"avatar": "",
"chunk_count": 59,
"create_date": "Sat, 14 Sep 2024 01:12:37 GMT",
"create_time": 1726276357324,
"created_by": "69736c5e723611efb51b0242ac120007",
"description": null,
"document_count": 1,
"embedding_model": "BAAI/bge-large-zh-v1.5",
"id": "6e211ee0723611efa10a0242ac120007",
"language": "English",
"name": "mysql",
"chunk_method": "knowledge_graph",
"parser_config": {
"chunk_token_num": 8192,
"delimiter": "\\n!?;。;!?",
"entity_types": [
"organization",
"person",
"location",
"event",
"time"
]
},
"permission": "me",
"similarity_threshold": 0.2,
"status": "1",
"tenant_id": "69736c5e723611efb51b0242ac120007",
"token_num": 12744,
"update_date": "Thu, 10 Oct 2024 04:07:23 GMT",
"update_time": 1728533243536,
"vector_similarity_weight": 0.3
}
]
}
失败
{
"code": 102,
"message": "The dataset doesn't exist"
}
2、知识库(数据集)中的文件管理
2.1上传文件
功能
用于向指定的知识库(数据集)上传文档
请求方法
方法: POST
URL: /api/v1/datasets/{dataset_id}/documents
# dataset_id 为知识库(数据集)的id
请求头部
Headers:
'Content-Type: multipart/form-data'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为多部分表单数据,这是上传文件时常用的格式。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
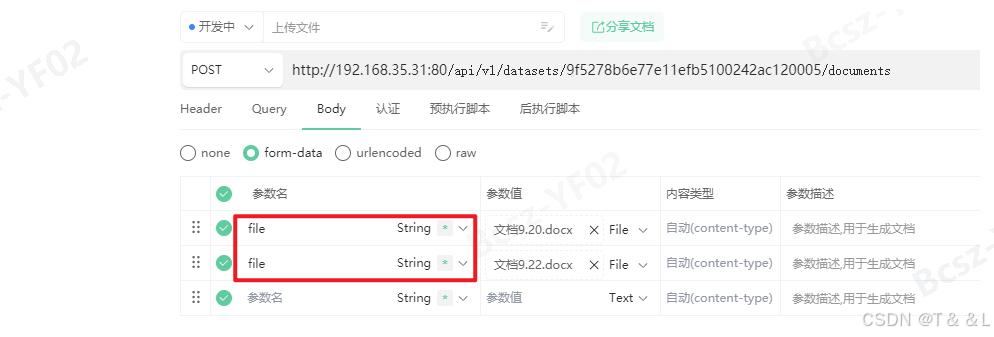
请求表单(Form)
file=@{FILE_PATH}
这里file是表单字段名,@{FILE_PATH}是你要上传的文件的路径。你可以上传多个文件,每个文件都需要一个file字段。
成功
{
"code": 0,
"data": [
{
"chunk_method": "naive",
"created_by": "69736c5e723611efb51b0242ac120007",
"dataset_id": "527fa74891e811ef9c650242ac120006",
"id": "b330ec2e91ec11efbc510242ac120004",
"location": "1.txt",
"name": "1.txt",
"parser_config": {
"chunk_token_num": 128,
"delimiter": "\\n!?;。;!?",
"html4excel": false,
"layout_recognize": true,
"raptor": {
"user_raptor": false
}
},
"run": "UNSTART",
"size": 17966,
"thumbnail": "",
"type": "doc"
}
]
}
失败
{
"code": 101,
"message": "No file part!"
}
2.2更新文档
功能
更新指定文档的配置。
请求方法
方法: PUT
URL: /api/v1/datasets/{dataset_id}/documents/{document_id}
# dataset_id 为知识库(数据集)的id
# document_id 为你要更新的文档的ID。
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"name": string,
"chunk_method": string,
"parser_config": enum<string>
}
请求体是一个JSON对象,包含以下字段:
-
"name":文档的名称(字符串类型)。 -
"chunk_method":文档的解析方法(字符串类型),决定了如何解析文档内容。可选值包括"naive"General(通用)、"manual"Manual(手动)、"qa"Q&A(问答)、"table"Table(表格)、"paper"Paper(论文)、"book"Book(书籍)、"laws"Laws(法律)、"presentation"Presentation(演示文稿)、"picture"Picture(图片)、"one"One(单一)、"knowledge_graph"Knowledge Graph(知识图谱)等。 -
"parser_config":解析器配置(对象类型),根据所选的"chunk_method",这个对象中的属性会有所不同。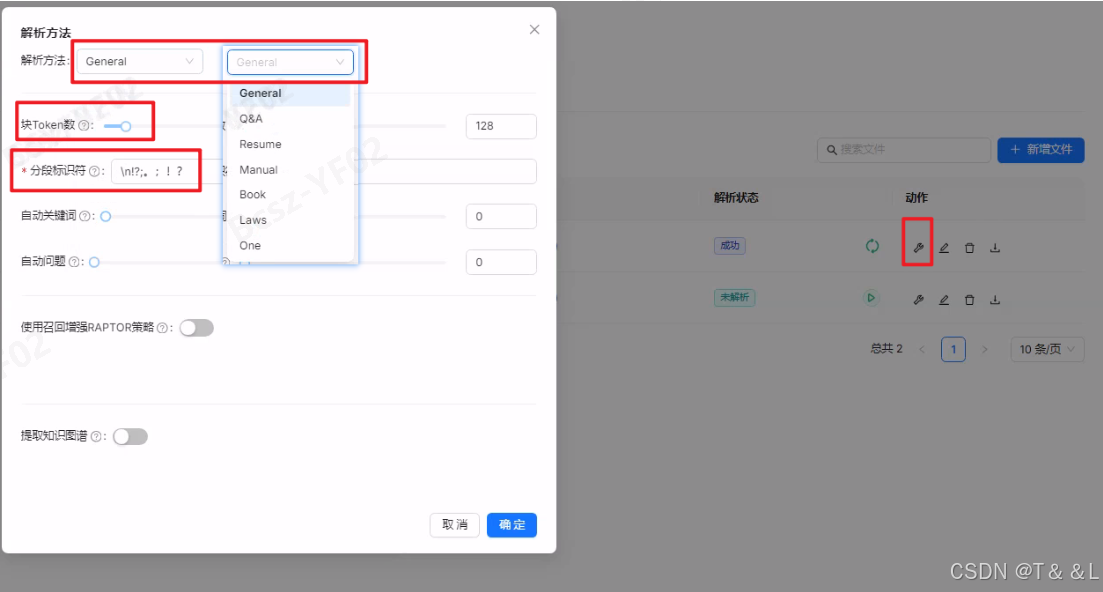
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "The dataset does not have the document."
}
2.3下载文档
功能
从指定的数据集下载文档。
请求方法
方法: GET
URL: /api/v1/datasets/{dataset_id}/documents/{document_id}
# dataset_id 为知识库(数据集)的id
# document_id 为你要更新的文档的ID。
请求头部
Headers:
'Authorization: Bearer <YOUR_API_KEY>'
- Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
成功
这是一个验证文件下载特性的测试。
失败
{
"code": 102,
"message": "You do not own the dataset 7898da028a0511efbf750242ac1220005."
}
2.4查询文档
功能
查询指定数据集中的所有文档。
请求方法
方法: GET
URL: /api/v1/datasets/{dataset_id}/documents?page={page}&page_size={page_size}&orderby={orderby}&desc={desc}&keywords={keywords}&id={document_id}&name={document_name}
# page (可选)指定显示文档的页码,默认为1。
# page_size (可选)每页显示的最大文档数,默认为30。
# orderby (可选)指定排序的字段。可选值包括create_time(默认,创建时间)和update_time(更新时间)。
# desc(可选)指示是否按降序排序,默认为true。
# keywords(可选)用于匹配文档标题的关键词。
# id (可选)指定要检索的文档的ID。注意,当使用此参数时,接口可能只会返回与该ID匹配的单个文档(具体行为取决于API的实现)。
# name (可选)指定要检索的文档的名称。与id参数类似,其行为可能取决于API的具体实现。
请求头部
Headers:
'content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
成功
{
"code": 0,
"data": {
"docs": [
{
"chunk_count": 0,
"create_date": "Mon, 14 Oct 2024 09:11:01 GMT",
"create_time": 1728897061948,
"created_by": "69736c5e723611efb51b0242ac120007",
"id": "3bcfbf8a8a0c11ef8aba0242ac120006",
"knowledgebase_id": "7898da028a0511efbf750242ac120005",
"location": "Test_2.txt",
"name": "Test_2.txt",
"parser_config": {
"chunk_token_count": 128,
"delimiter": "\n!?。;!?",
"layout_recognize": true,
"task_page_size": 12
},
"chunk_method": "naive",
"process_begin_at": null,
"process_duation": 0.0,
"progress": 0.0,
"progress_msg": "",
"run": "0",
"size": 7,
"source_type": "local",
"status": "1",
"thumbnail": null,
"token_count": 0,
"type": "doc",
"update_date": "Mon, 14 Oct 2024 09:11:01 GMT",
"update_time": 1728897061948
}
],
"total": 1
}
}
失败
{
"code": 102,
"message": "You don't own the dataset 7898da028a0511efbf750242ac1220005. "
}
2.5删除文档
功能
按ID删除文档。
请求方法
方法: DELETE
URL: /api/v1/datasets/{dataset_id}/documents
# dataset_id 为知识库(数据集)的id
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"ids": list[string]
}
- ids(请求体参数):要删除的文档的ID列表。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "You do not own the dataset 7898da028a0511efbf750242ac1220005."
}
2.6解析文档
功能
解析指定数据集中的文档。
请求方法
方法: POST
URL: /api/v1/datasets/{dataset_id}/chunks
# dataset_id 为知识库(数据集)的id
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"document_ids": list[string]
}
- document_ids(请求体参数):要解析的文档的ID列表。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "`document_ids` is required"
}
2.7停止解析文档
功能
停止解析指定数据集中的文档。
请求方法
方法: DELETE
URL: /api/v1/datasets/{dataset_id}/chunks
# dataset_id 为知识库(数据集)的id
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"document_ids": list[string]
}
- document_ids(请求体参数):要停止解析的文档的ID列表。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "`document_ids` is required"
}
3、数据集中的解析块管理
3.1增加解析块
功能
将解析块添加到指定数据集中的指定文档中。
请求方法
方法: POST
URL: /api/v1/datasets/{dataset_id}/documents/{document_id}/chunks
# dataset_id 为知识库(数据集)的id
# document_id 为你要更新的文档的ID。
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"content": string,
"important_keywords": list[string]
}
请求体是一个JSON对象,可以包含以下字段:
-
content(请求体参数,字符串,必需):要添加的文本解析块的内容。
-
important_keywords(请求体参数,字符串列表,可选):与文本块相关联的关键术语或短语。
-
questions(请求体参数,字符串列表,可选):如果提供了问题,则嵌入的文本块将基于这些问题。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "`document_ids` is required"
}
3.2查询解析块
功能
列出指定文档中的解析块。
请求方法
方法: GET
URL: /api/v1/datasets/{dataset_id}/documents/{document_id}/chunks?keywords={keywords}&page={page}&page_size={page_size}&id={chunk_id}
# dataset_id 为知识库(数据集)的id。
# document_id 为你要更新的文档的ID。
# keywords(可选)用于匹配文本块内容的关键词。
# page (可选)指定显示文本块的页码,默认为1。
# page_size (可选)每页显示的文本块最大数量,默认为1024。
# id (可选)要检索的文本块的ID。如果提供此参数,则只返回该ID对应的文本块信息。
请求头部
Headers:
'Authorization: Bearer <YOUR_API_KEY>'
- Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
成功
{
"code": 0,
"data": {
"chunks": [
{
"available_int": 1,
"content": "This is a test content.",
"docnm_kwd": "1.txt",
"document_id": "b330ec2e91ec11efbc510242ac120004",
"id": "b48c170e90f70af998485c1065490726",
"image_id": "",
"important_keywords": "",
"positions": [
""
]
}
],
"doc": {
"chunk_count": 1,
"chunk_method": "naive",
"create_date": "Thu, 24 Oct 2024 09:45:27 GMT",
"create_time": 1729763127646,
"created_by": "69736c5e723611efb51b0242ac120007",
"dataset_id": "527fa74891e811ef9c650242ac120006",
"id": "b330ec2e91ec11efbc510242ac120004",
"location": "1.txt",
"name": "1.txt",
"parser_config": {
"chunk_token_num": 128,
"delimiter": "\\n!?;。;!?",
"html4excel": false,
"layout_recognize": true,
"raptor": {
"user_raptor": false
}
},
"process_begin_at": "Thu, 24 Oct 2024 09:56:44 GMT",
"process_duation": 0.54213,
"progress": 0.0,
"progress_msg": "Task dispatched...",
"run": "2",
"size": 17966,
"source_type": "local",
"status": "1",
"thumbnail": "",
"token_count": 8,
"type": "doc",
"update_date": "Thu, 24 Oct 2024 11:03:15 GMT",
"update_time": 1729767795721
},
"total": 1
}
}
失败
{
"code": 102,
"message": "You don't own the document 5c5999ec7be811ef9cab0242ac12000e5."
}
3.3删除解析块
功能
将解析块添加到指定数据集中的指定文档中。
请求方法
方法: DELETE
URL: /api/v1/datasets/{dataset_id}/documents/{document_id}/chunks
# dataset_id 为知识库(数据集)的id
# document_id 为你要更新的文档的ID。
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"chunk_ids": list[string]
}
chunk_ids 一个字符串列表,指定要删除的文本块ID。如果不指定,则删除指定文档的所有文本块。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "`chunk_ids` is required"
}
3.4修改解析块
功能
更新指定块的内容或配置。
请求方法
方法: PUT
URL: /api/v1/datasets/{dataset_id}/documents/{document_id}/chunks/{chunk_id}
# dataset_id 为知识库(数据集)的ID。
# document_id 为你要更新的文档的ID。
# chunk_id 为要更改解析块的ID。
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"content": string,
"important_keywords": list[string],
"available": boolean
}
content:字符串,文本块的内容。important_keywords:字符串列表,与文本块关联的关键术语或短语列表。available:布尔值,文本块的可用性状态。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "Can't find this chunk 29a2d9987e16ba331fb4d7d30d99b71d2"
}
3.5删除解析块
功能
将解析块添加到指定数据集中的指定文档中。
请求方法
方法: DELETE
URL: /api/v1/datasets/{dataset_id}/documents/{document_id}/chunks
# dataset_id 为知识库(数据集)的id
# document_id 为你要更新的文档的ID。
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"chunk_ids": list[string]
}
chunk_ids 一个字符串列表,指定要删除的文本块ID。如果不指定,则删除指定文档的所有文本块。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "`chunk_ids` is required"
}
3.6检索的解析块
功能
从指定的数据集中检索块。
请求方法
方法: POST
URL: /api/v1/retrieval
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"question": string,
"dataset_ids": list[string],
"document_ids": list[string],
"page": integer,
"page_size": integer,
"similarity_threshold": float,
"vector_similarity_weight": float,
"top_k": integer,
"rerank_id": string,
"keyword": boolean,
"highlight": boolean
}
-
question(必需):字符串,用户查询或查询关键词。
-
dataset_ids:字符串列表,要搜索的数据集ID列表。如果不设置此参数,则必须设置
document_ids。 -
document_ids:字符串列表,要搜索的文档ID列表。确保所选文档使用相同的嵌入模型,否则会发生错误。如果不设置此参数,则必须设置
dataset_ids。 -
page:整数,指定显示文本块的页码。默认为1。
-
page_size:整数,每页的最大文本块数。默认为30。
-
similarity_threshold:浮点数,最小相似度分数。默认为0.2。
-
vector_similarity_weight:浮点数,向量余弦相似度的权重。默认为0.3。如果x表示向量余弦相似度的权重,则(1 - x)是术语相似度的权重。
-
top_k:整数,参与向量余弦计算的文本块数。默认为1024。
-
rerank_id:整数,重排模型的ID。
-
keyword
:布尔值,指示是否启用基于关键词的匹配:
true:启用基于关键词的匹配。false:禁用基于关键词的匹配(默认)。
-
highlight
:布尔值,指定是否在结果中高亮显示匹配的术语:
true:启用高亮显示匹配的术语。false:禁用高亮显示匹配的术语(默认)。
成功
{
"code": 0,
"data": {
"chunks": [
{
"content": "ragflow content",
"content_ltks": "ragflow content",
"document_id": "5c5999ec7be811ef9cab0242ac120005",
"document_keyword": "1.txt",
"highlight": "<em>ragflow</em> content",
"id": "d78435d142bd5cf6704da62c778795c5",
"image_id": "",
"important_keywords": [
""
],
"kb_id": "c7ee74067a2c11efb21c0242ac120006",
"positions": [
""
],
"similarity": 0.9669436601210759,
"term_similarity": 1.0,
"vector_similarity": 0.8898122004035864
}
],
"doc_aggs": [
{
"count": 1,
"doc_id": "5c5999ec7be811ef9cab0242ac120005",
"doc_name": "1.txt"
}
],
"total": 1
}
}
失败
{
"code": 102,
"message": "`datasets` is required."
}
4、聊天助手管理
4.1创建聊天助手
功能
创建一个聊天助手。
请求方法
方法: POST
URL: /api/v1/chats
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"name": "string",
"avatar": "string",
"dataset_ids": list[string],
"llm": "object",
"prompt": "object"
}
- name(字符串,必需):聊天助手的名称。
- avatar(字符串):聊天助手的头像,应为Base64编码的字符串。
- dataset_ids(字符串列表):与聊天助手关联的数据集ID列表。
- llm(对象):聊天助手的LLM(大型语言模型)设置。如果不明确设置,将使用默认值。LLM对象包含以下属性:
- model_name(字符串):聊天模型名称。如果不设置,将使用用户的默认聊天模型。
- temperature(浮点数):控制模型预测的随机性。较低的温度导致更保守的响应,而较高的温度产生更具创意和多样性的响应。默认为0.1。
- top_p(浮点数):也称为“核采样”,此参数设置用于采样较小词汇集的阈值。它专注于最可能的单词,并排除不太可能的单词。默认为0.3。
- presence_penalty(浮点数):通过惩罚已经在对话中出现过的单词来阻止模型重复相同的信息。默认为0.2。
- frequency_penalty(浮点数):类似于存在惩罚,这减少了模型频繁重复相同单词的倾向。默认为0.7。
- max_token(整数):模型输出的最大长度,以令牌(单词或单词片段)数量衡量。默认为512。如果禁用,则取消最大令牌限制,允许模型确定其响应中的令牌数量。
- prompt(对象):LLM应遵循的指令。如果不明确设置,将使用默认值。提示对象包含以下属性:
- similarity_threshold(浮点数):设置用户查询和块之间相似性的阈值。如果相似性分数低于此阈值,则相应的块将从结果中排除。默认为0.2。
- keywords_similarity_weight(浮点数):设置关键字相似性在混合相似性分数(与向量余弦相似性或重新排序模型相似性结合)中的权重。通过调整此权重,可以控制关键字相似性相对于其他相似性度量的影响。默认为0.7。
- top_n(整数):指定相似性分数高于similarity_threshold的顶级块的数量,这些块将被提供给LLM。LLM将仅访问这些“顶级N”块。默认为8。
- variables(对象数组):此参数列出了在“系统”字段中用于聊天配置的变量。注意:
- “knowledge”是一个保留变量,表示检索到的块。
- “系统”中的所有变量都应用大括号括起来。
- 默认值为[{“key”: “knowledge”, “optional”: true}]。
- rerank_model(字符串):如果不指定,则使用向量余弦相似性;否则,将使用重新排序分数。
- top_k(整数):指根据特定排名标准对列表或集合中的前k项进行重新排序或选择的过程。默认为1024。
- empty_response(字符串):如果数据集中没有检索到用户的问题,则将此用作响应。如果要允许LLM在找不到内容时即兴创作,请留空。
- opener(字符串):用户的开场问候语。默认为“Hi! I am your assistant, can I help you?”。
- show_quote(布尔值):指示是否应显示文本的来源。默认为true。
- prompt(字符串):提示内容(注意:这里与外层prompt对象名重复,可能是文档错误或特定字段,需根据实际API文档确认)。
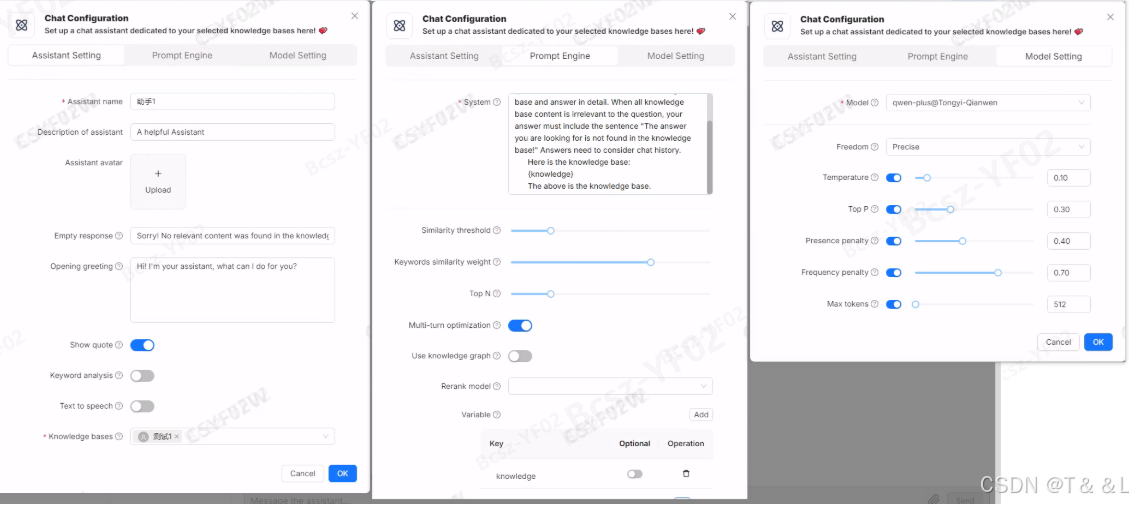
成功
{
"code": 0,
"data": {
"avatar": "",
"create_date": "Thu, 24 Oct 2024 11:18:29 GMT",
"create_time": 1729768709023,
"dataset_ids": [
"527fa74891e811ef9c650242ac120006"
],
"description": "A helpful Assistant",
"do_refer": "1",
"id": "b1f2f15691f911ef81180242ac120003",
"language": "English",
"llm": {
"frequency_penalty": 0.7,
"max_tokens": 512,
"model_name": "qwen-plus@Tongyi-Qianwen",
"presence_penalty": 0.4,
"temperature": 0.1,
"top_p": 0.3
},
"name": "12234",
"prompt": {
"empty_response": "Sorry! No relevant content was found in the knowledge base!",
"keywords_similarity_weight": 0.3,
"opener": "Hi! I'm your assistant, what can I do for you?",
"prompt": "You are an intelligent assistant. Please summarize the content of the knowledge base to answer the question. Please list the data in the knowledge base and answer in detail. When all knowledge base content is irrelevant to the question, your answer must include the sentence \"The answer you are looking for is not found in the knowledge base!\" Answers need to consider chat history.\n ",
"rerank_model": "",
"similarity_threshold": 0.2,
"top_n": 6,
"variables": [
{
"key": "knowledge",
"optional": false
}
]
},
"prompt_type": "simple",
"status": "1",
"tenant_id": "69736c5e723611efb51b0242ac120007",
"top_k": 1024,
"update_date": "Thu, 24 Oct 2024 11:18:29 GMT",
"update_time": 1729768709023
}
}
失败
{
"code": 102,
"message": "Duplicated chat name in creating dataset."
}
4.2更新聊天助手
功能
更新指定聊天助手的配置。
请求方法
方法: PUT
URL: /api/v1/chats/{chat_id}
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"name": "string",
"avatar": "string",
"dataset_ids": list[string],
"llm": "object",
"prompt": "object"
}
- name(字符串,必需):聊天助手的名称。
- avatar(字符串):聊天助手的头像,应为Base64编码的字符串。
- dataset_ids(字符串列表):与聊天助手关联的数据集ID列表。
- llm(对象):聊天助手的LLM(大型语言模型)设置。如果不明确设置,将使用默认值。LLM对象包含以下属性:
- model_name(字符串):聊天模型名称。如果不设置,将使用用户的默认聊天模型。
- temperature(浮点数):控制模型预测的随机性。较低的温度导致更保守的响应,而较高的温度产生更具创意和多样性的响应。默认为0.1。
- top_p(浮点数):也称为“核采样”,此参数设置用于采样较小词汇集的阈值。它专注于最可能的单词,并排除不太可能的单词。默认为0.3。
- presence_penalty(浮点数):通过惩罚已经在对话中出现过的单词来阻止模型重复相同的信息。默认为0.2。
- frequency_penalty(浮点数):类似于存在惩罚,这减少了模型频繁重复相同单词的倾向。默认为0.7。
- max_token(整数):模型输出的最大长度,以令牌(单词或单词片段)数量衡量。默认为512。如果禁用,则取消最大令牌限制,允许模型确定其响应中的令牌数量。
- prompt(对象):LLM应遵循的指令。如果不明确设置,将使用默认值。提示对象包含以下属性:
- similarity_threshold(浮点数):设置用户查询和块之间相似性的阈值。如果相似性分数低于此阈值,则相应的块将从结果中排除。默认为0.2。
- keywords_similarity_weight(浮点数):设置关键字相似性在混合相似性分数(与向量余弦相似性或重新排序模型相似性结合)中的权重。通过调整此权重,可以控制关键字相似性相对于其他相似性度量的影响。默认为0.7。
- top_n(整数):指定相似性分数高于similarity_threshold的顶级块的数量,这些块将被提供给LLM。LLM将仅访问这些“顶级N”块。默认为8。
- variables(对象数组):此参数列出了在“系统”字段中用于聊天配置的变量。注意:
- “knowledge”是一个保留变量,表示检索到的块。
- “系统”中的所有变量都应用大括号括起来。
- 默认值为[{“key”: “knowledge”, “optional”: true}]。
- rerank_model(字符串):如果不指定,则使用向量余弦相似性;否则,将使用重新排序分数。
- top_k(整数):指根据特定排名标准对列表或集合中的前k项进行重新排序或选择的过程。默认为1024。
- empty_response(字符串):如果数据集中没有检索到用户的问题,则将此用作响应。如果要允许LLM在找不到内容时即兴创作,请留空。
- opener(字符串):用户的开场问候语。默认为“Hi! I am your assistant, can I help you?”。
- show_quote(布尔值):指示是否应显示文本的来源。默认为true。
- prompt(字符串):提示内容(注意:这里与外层prompt对象名重复,可能是文档错误或特定字段,需根据实际API文档确认)。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "Duplicated chat name in updating dataset."
}
4.3删除聊天助手
功能
删除指定聊天助手的配置。
请求方法
方法: DELETE
URL: /api/v1/chats
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"ids": list[string]
}
ids,其值是一个字符串列表,列表中每个字符串代表一个要删除的聊天助手的ID。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "Duplicated chat name in updating dataset."
}
4.4查询聊天助手
功能
该接口用于获取聊天助手的列表。
请求方法
方法: GET
URL: /api/v1/chats?page={page}&page_size={page_size}&orderby={orderby}&desc={desc}&name={chat_name}&id={chat_id}
# page (可选)指定要显示的聊天助手所在的页码。默认为1。
# page_size (可选)每页显示的聊天助手数量。默认为30。
# orderby (可选)指定排序的字段。可选值包括create_time(默认,创建时间)和update_time(更新时间)。
# desc(可选)指示检索到的聊天助手是否应按降序排序,默认为true。
# name (可选)指定要检索的聊天助手的名称。如果提供此参数,将返回名称匹配或包含指定字符串的聊天助手。
# id (可选)指定要检索的聊天助手的ID。如果提供此参数,将只返回具有该ID的聊天助手。
请求头部
Headers:
'Authorization: Bearer <YOUR_API_KEY>'
- Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
成功
{
"code": 0,
"data": [
{
"avatar": "",
"create_date": "Fri, 18 Oct 2024 06:20:06 GMT",
"create_time": 1729232406637,
"description": "A helpful Assistant",
"do_refer": "1",
"id": "04d0d8e28d1911efa3630242ac120006",
"dataset_ids": ["527fa74891e811ef9c650242ac120006"],
"language": "English",
"llm": {
"frequency_penalty": 0.7,
"max_tokens": 512,
"model_name": "qwen-plus@Tongyi-Qianwen",
"presence_penalty": 0.4,
"temperature": 0.1,
"top_p": 0.3
},
"name": "13243",
"prompt": {
"empty_response": "Sorry! No relevant content was found in the knowledge base!",
"keywords_similarity_weight": 0.3,
"opener": "Hi! I'm your assistant, what can I do for you?",
"prompt": "You are an intelligent assistant. Please summarize the content of the knowledge base to answer the question. Please list the data in the knowledge base and answer in detail. When all knowledge base content is irrelevant to the question, your answer must include the sentence \"The answer you are looking for is not found in the knowledge base!\" Answers need to consider chat history.\n",
"rerank_model": "",
"similarity_threshold": 0.2,
"top_n": 6,
"variables": [
{
"key": "knowledge",
"optional": false
}
]
},
"prompt_type": "simple",
"status": "1",
"tenant_id": "69736c5e723611efb51b0242ac120007",
"top_k": 1024,
"update_date": "Fri, 18 Oct 2024 06:20:06 GMT",
"update_time": 1729232406638
}
]
}
失败
{
"code": 102,
"message": "The chat doesn't exist"
}
5、会话管理
5.1用聊天助手创建会话
功能
与聊天助手创建会话。
请求方法
方法: POST
URL: /api/v1/chats/{chat_id}/sessions
# chat_id 为聊天助手的ID
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"name": string,
"user_id": string (optional)
}
- “name”: string:会话的名称,这是一个必需的参数。例如,你可以命名为
"new session"。 - “user_id”: string:用户定义的ID,这是一个可选参数。如果你提供这个参数,它可以帮助你标识或关联特定的用户到这个会话。
成功
{
"code": 0,
"data": {
"chat_id": "2ca4b22e878011ef88fe0242ac120005",
"create_date": "Fri, 11 Oct 2024 08:46:14 GMT",
"create_time": 1728636374571,
"id": "4606b4ec87ad11efbc4f0242ac120006",
"messages": [
{
"content": "Hi! I am your assistant,can I help you?",
"role": "assistant"
}
],
"name": "new session",
"update_date": "Fri, 11 Oct 2024 08:46:14 GMT",
"update_time": 1728636374571
}
}
失败
{
"code": 102,
"message": "Name cannot be empty."
}
5.2更新聊天助手的会话
功能
更新指定聊天助手的会话。
请求方法
方法: PUT
URL: /api/v1/chats/{chat_id}/sessions/{session_id}
# chat_id 为聊天助手的ID。
# session_id 为聊天助手的会话ID。
请求头部
Headers:
'Content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"name": string,
"user_id": string (optional)
}
- “name”: string:会话的名称,这是一个必需的参数。例如,你可以命名为
"new session"。 - “user_id”: string:用户定义的ID,这是一个可选参数。如果你提供这个参数,它可以帮助你标识或关联特定的用户到这个会话。
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "Name cannot be empty."
}
5.3列出聊天助手的会话
功能
列出与指定聊天助手关联的会话。
请求方法
方法: GET
URL: /api/v1/chats/{chat_id}/sessions?page={page}&page_size={page_size}&orderby={orderby}&desc={desc}&name={session_name}&id={session_id}
# chat_id 为聊天助手的ID。
# session_id 为聊天助手的会话ID。
# page (可选)指定要显示的会话所在的页码。默认为1。
# page_size (可选)指定每页显示的会话数量。默认为30。
# orderby (可选)指定用于排序会话的字段。可选值包括create_time(默认,创建时间)和update_time(更新时间)。
# desc(可选)指示检索到的会话是否应按降序排序。默认为true。
# name (可选)指定要检索的会话名称。如果提供此参数,将只返回名称匹配的会话。
# id (可选)指定要检索的会话ID。如果提供此参数,将只返回ID匹配的会话。
请求头部
Headers:
'Authorization: Bearer <YOUR_API_KEY>'
- Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
成功
{
"code": 0,
"data": [
{
"chat": "2ca4b22e878011ef88fe0242ac120005",
"create_date": "Fri, 11 Oct 2024 08:46:43 GMT",
"create_time": 1728636403974,
"id": "578d541e87ad11ef96b90242ac120006",
"messages": [
{
"content": "Hi! I am your assistant,can I help you?",
"role": "assistant"
}
],
"name": "new session",
"update_date": "Fri, 11 Oct 2024 08:46:43 GMT",
"update_time": 1728636403974
}
]
}
失败
{
"code": 102,
"message": "The session doesn't exist"
}
5.4删除聊天助手的会话
功能
通过ID删除聊天助手的会话。
请求方法
方法: DELETE
URL: /api/v1/chats/{chat_id}/sessions
# chat_id 为聊天助手的ID。
请求头部
Headers:
'content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"ids": list[string]
}
成功
{
"code": 0
}
失败
{
"code": 102,
"message": "The chat doesn't own the session"
}
5.5与聊天助手交谈
功能
向指定的聊天助手提问,以启动人工智能对话。
请求方法
方法: POST
URL: /api/v1/chats/{chat_id}/completions
# chat_id 为聊天助手的ID。
请求头部
Headers:
'content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"question": string,
"stream": boolean,
"session_id": string (optional),
"user_id: string (optional)
}
-
请求体是一个JSON对象,可以包含以下字段:
-
“question”:字符串类型,必填。这是你想要问聊天助手的问题。
-
“stream”
:布尔类型。指示是否以流式方式输出响应:
true:启用流式传输(默认)。false:禁用流式传输。
-
“session_id”:字符串类型,可选。会话的ID。如果不提供,将生成一个新的会话。
-
“user_id”:字符串类型,可选。用户定义的ID,仅在未提供
session_id时有效。
-
成功,不带session_id
data:{
"code": 0,
"message": "",
"data": {
"answer": "Hi! I'm your assistant, what can I do for you?",
"reference": {},
"audio_binary": null,
"id": null,
"session_id": "b01eed84b85611efa0e90242ac120005"
}
}
data:{
"code": 0,
"message": "",
"data": true
}
成功,带session_id
data:{
"code": 0,
"data": {
"answer": "I am an intelligent assistant designed to help answer questions by summarizing content from a",
"reference": {},
"audio_binary": null,
"id": "a84c5dd4-97b4-4624-8c3b-974012c8000d",
"session_id": "82b0ab2a9c1911ef9d870242ac120006"
}
}
data:{
"code": 0,
"data": {
"answer": "I am an intelligent assistant designed to help answer questions by summarizing content from a knowledge base. My responses are based on the information available in the knowledge base and",
"reference": {},
"audio_binary": null,
"id": "a84c5dd4-97b4-4624-8c3b-974012c8000d",
"session_id": "82b0ab2a9c1911ef9d870242ac120006"
}
}
data:{
"code": 0,
"data": {
"answer": "I am an intelligent assistant designed to help answer questions by summarizing content from a knowledge base. My responses are based on the information available in the knowledge base and any relevant chat history.",
"reference": {},
"audio_binary": null,
"id": "a84c5dd4-97b4-4624-8c3b-974012c8000d",
"session_id": "82b0ab2a9c1911ef9d870242ac120006"
}
}
data:{
"code": 0,
"data": {
"answer": "I am an intelligent assistant designed to help answer questions by summarizing content from a knowledge base ##0$$. My responses are based on the information available in the knowledge base and any relevant chat history.",
"reference": {
"total": 1,
"chunks": [
{
"id": "faf26c791128f2d5e821f822671063bd",
"content": "xxxxxxxx",
"document_id": "dd58f58e888511ef89c90242ac120006",
"document_name": "1.txt",
"dataset_id": "8e83e57a884611ef9d760242ac120006",
"image_id": "",
"similarity": 0.7,
"vector_similarity": 0.0,
"term_similarity": 1.0,
"positions": [
""
]
}
],
"doc_aggs": [
{
"doc_name": "1.txt",
"doc_id": "dd58f58e888511ef89c90242ac120006",
"count": 1
}
]
},
"prompt": "xxxxxxxxxxx",
"id": "a84c5dd4-97b4-4624-8c3b-974012c8000d",
"session_id": "82b0ab2a9c1911ef9d870242ac120006"
}
}
data:{
"code": 0,
"data": true
}
失败
{
"code": 102,
"message": "Please input your question."
}
5.6使用代理创建会话(代理id未知)
功能
使用代理创建会话。
请求方法
方法: POST
URL: /api/v1/agents/{agent_id}/sessions
# agent_id 指定要与之创建会话的代理的ID。。
请求头部
Headers:
'content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
成功
{
"code": 0,
"data": {
"agent_id": "b4a39922b76611efaa1a0242ac120006",
"dsl": {
"answer": [],
"components": {
"Answer:GreenReadersDrum": {
"downstream": [],
"obj": {
"component_name": "Answer",
"inputs": [],
"output": null,
"params": {}
},
"upstream": []
},
"begin": {
"downstream": [],
"obj": {
"component_name": "Begin",
"inputs": [],
"output": {},
"params": {}
},
"upstream": []
}
},
"embed_id": "",
"graph": {
"edges": [],
"nodes": [
{
"data": {
"label": "Begin",
"name": "begin"
},
"dragging": false,
"height": 44,
"id": "begin",
"position": {
"x": 53.25688640427177,
"y": 198.37155679786412
},
"positionAbsolute": {
"x": 53.25688640427177,
"y": 198.37155679786412
},
"selected": false,
"sourcePosition": "left",
"targetPosition": "right",
"type": "beginNode",
"width": 200
},
{
"data": {
"form": {},
"label": "Answer",
"name": "dialog_0"
},
"dragging": false,
"height": 44,
"id": "Answer:GreenReadersDrum",
"position": {
"x": 360.43473114516974,
"y": 207.29298425089348
},
"positionAbsolute": {
"x": 360.43473114516974,
"y": 207.29298425089348
},
"selected": false,
"sourcePosition": "right",
"targetPosition": "left",
"type": "logicNode",
"width": 200
}
]
},
"history": [],
"messages": [],
"path": [
[
"begin"
],
[]
],
"reference": []
},
"id": "2581031eb7a311efb5200242ac120005",
"message": [
{
"content": "Hi! I'm your smart assistant. What can I do for you?",
"role": "assistant"
}
],
"source": "agent",
"user_id": "69736c5e723611efb51b0242ac120007"
}
}
失败
{
"code": 102,
"message": "Agent not found."
}
5.7与代理人交谈(代理id未知)
功能
向指定的代理询问问题以启动ai驱动的对话。
请求方法
方法: POST
URL: /api/v1/agents/{agent_id}/completions
# agent_id 指定要与之创建会话的代理的ID。。
请求头部
Headers:
'content-Type: application/json'
'Authorization: Bearer <YOUR_API_KEY>'
- Content-Type:
multipart/form-data,指定请求的内容类型为JSON。 - Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
请求体(Body)
{
"question": string,
"stream": boolean,
"session_id": string,
"user_id": string(optional),
other parameters: string
}
- “question”:请求体参数,必需。要提出的问题。
- “stream”:请求体参数,指示是否以流式方式接收响应。
- “session_id”:请求体参数,可选。会话的ID。如果不提供,将生成一个新的会话。
- “user_id”:请求体参数,可选。用户定义的ID,仅当不提供
session_id时有效。 - 其他参数:取决于代理的开始组件的配置。
成功
失败
5.8列出代理会话(代理id未知)
功能
列出与指定代理关联的会话。
请求方法
方法: GET
URL: /api/v1/agents/{agent_id}/sessions?page={page}&page_size={page_size}&orderby={orderby}&desc={desc}&id={session_id}&user_id={user_id}
# agent_id 指定要列出会话的代理的ID。
# page (可选)指定要显示的会话所在的页码。默认为1。
# page_size (可选)指定每页显示的会话数量。默认为30。
# orderby (可选)指定会话应该按哪个字段排序。可选值包括create_time(默认,创建时间)和update_time(更新时间)。
# desc(可选)指示检索到的会话是否应该按降序排序。默认为true。
# id (可选)指定要检索的代理会话的ID。如果提供此参数,将只返回具有该ID的会话。
# user_id (可选)创建会话时传递的可选用户定义的ID。如果提供此参数,将返回具有该用户ID的会话(如果API支持此过滤方式)。
请求头部
Headers:
'Authorization: Bearer <YOUR_API_KEY>'
- Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
成功
失败
6、代理管理
6.1查询代理列表
功能
查询代理列表
请求方法
方法: GET
URL: /api/v1/agents?page={page}&page_size={page_size}&orderby={orderby}&desc={desc}&name={agent_name}&id={agent_id}
# page (可选)指定显示代理的页码,默认为1。
# page_size (可选)每页显示的代理数量。默认为30。
# orderby (可选)指定会话应该按哪个字段排序。可选值包括create_time(默认,创建时间)和update_time(更新时间)。
# desc(可选)指示检索到的会话是否应该按降序排序。默认为true。
# name (可选)指定要检索的代理ID。
# name (可选)指定要检索的代理名称。
# id (可选)指定要检索的代理会话的ID。如果提供此参数,将只返回具有该ID的会话。
请求头部
Headers:
'Authorization: Bearer <YOUR_API_KEY>'
- Authorization:
Bearer <YOUR_API_KEY>,用于身份验证,<YOUR_API_KEY>需要替换为实际的API密钥。
成功
{
"code": 0,
"data": [
{
"avatar": null,
"canvas_type": null,
"create_date": "Thu, 05 Dec 2024 19:10:36 GMT",
"create_time": 1733397036424,
"description": null,
"dsl": {
"answer": [],
"components": {
"begin": {
"downstream": [],
"obj": {
"component_name": "Begin",
"params": {}
},
"upstream": []
}
},
"graph": {
"edges": [],
"nodes": [
{
"data": {
"label": "Begin",
"name": "begin"
},
"height": 44,
"id": "begin",
"position": {
"x": 50,
"y": 200
},
"sourcePosition": "left",
"targetPosition": "right",
"type": "beginNode",
"width": 200
}
]
},
"history": [],
"messages": [],
"path": [],
"reference": []
},
"id": "8d9ca0e2b2f911ef9ca20242ac120006",
"title": "123465",
"update_date": "Thu, 05 Dec 2024 19:10:56 GMT",
"update_time": 1733397056801,
"user_id": "69736c5e723611efb51b0242ac120007"
}
]
}
失败
{
"code": 102,
"message": "The agent doesn't exist."
}


















 5249
5249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











