







知识
SQL
内连接
select 字段 from 表1,表2 where 连接条件
外连接
左外连接:LEFT OUTER JOIN(LEFT JOIN);左外连接显示“左边全部的”和“右边与左边相同的”;
右外连接:RIGHT OUTER JOIN(RIHT JOIN);右外连接显示“右边全部的”和“左边与右边相同的”;
全外连接:FULL OUTER JOIN(FULL JOIN);全外连接显示左、右两边全部的。
java
单例
确保一个类只有一个实例(要求构造方法绝对不能是public公开的,不能够被外界进行公开的实例化,只能是private。另外,仅有的一个实例属于当前类,及这个实例时当前类的类静态成员变量),而且自行实例化并向整个系统提供这个实例(在类中提供一个静态的方法,向外界提供当前类的实例)。
单例模式作用是确保一个类只有一个实例存在。可用于序列号生成器、web页面计数器;也适用于当创建一个实例需要消耗相当多的资源时,单例模式可以减少资源消耗。
单例模式的饿汉式实现:在类加载的时候就进行实例化,就是说在静态类实例创建的时候就new;
懒汉式实现:在单例第一次被调用的时候进行实例化。(此时需要加锁synchronized防止被多次实例化)。
工厂
实现对象的创建和对象的使用分离
简单工厂
public class SimpleFactory{
public static Product createProduct(string type){
if(type.equals("A"))
return new ProductA();
else
return new ProductB();
}
public static void main(string[]args){
Product product SimpleFactory.createProduct("A");
product.print();
}
}
abstract class Product{
public abstract void print();
}
class ProductA extends Product{
public void print(){System.out.println("产品A");}
}
class ProductB extends Product{
public void print(){System.out.println("产品B");}
}
抽象工厂
排序
int[] numbers=new int[]{1,5,8,2,3,9,4};
for(int i=0;i<numbers.length-1;i++){
for(int j=0;j<numbers.length-1-i;j++){
if(numbers[j]>numbers[j+1]){
int temp=numbers[j];
numbers[j]=numbers[j+1];
numbers[j+1]=temp;
}
}
}
void quickSort(int[] arr,int low,int high){
int i,j,temp,t;
if(low>high){
return;
}
i=low;
j=high;
temp = arr[low];//temp就是基准位
while (i<j) {
while (temp<=arr[j]&&i<j) {//先看右边,依次往左递减
j--;
}
while (temp>=arr[i]&&i<j) {//再看左边,依次往右递增
i++;
}
if (i<j) {//如果满足条件则交换
t = arr[j];
arr[j] = arr[i];
arr[i] = t;
}
}
arr[low] = arr[i];//最后将基准为与i和j相等位置的数字交换
arr[i] = temp;
quickSort(arr, low, j-1);//递归调用左半数组
quickSort(arr, j+1, high);//递归调用右半数组
}
查找
/**
* 使用递归的二分查找
*@param arr 有序数组
*@param key 待查找关键字
*@return 找到的位置
*/
public static int recursionBinarySearch(int[] arr,int key,int low,int high){
if(key < arr[low] || key > arr[high] || low > high){
return -1;
}
int middle = (low + high) / 2; //初始中间位置
if(arr[middle] > key){
//比关键字大则关键字在左区域
return recursionBinarySearch(arr, key, low, middle - 1);
}else if(arr[middle] < key){
//比关键字小则关键字在右区域
return recursionBinarySearch(arr, key, middle + 1, high);
}else {
return middle;
}
}
线程
消费者生产者
面试
自我介绍
面试官你好,我叫李永琪,现在在山东建筑大学软件工程专业大三就读,正在寻找自己人生中第一份实习工作。我怀着试一试的心态投了贵公司,能够被您面试也让我很惊喜。
我精通Java基础,能够熟练的运用Java SE的多种常用工具,在蓝桥杯中获得过省赛二等奖。我能够熟练运行Spring boot框架进行前后端分离的后端开发,能够熟练运用Vue框架进行前后端分离的前端开发。我在大三这一学年里多次使用Spring boot+Vue框架主导或独立开发了一些小应用,也参与过老师主导的实战项目的开发,其中有一些也上线了。
我参加过一些专业竞赛,2021年在山东省软件设计大赛同时获得一项一等奖和一项二等奖,今年又获得了服务外包创新创业大赛的二等奖,另外还有未结束或者未出成绩的比赛分别是泰迪杯全国大学生数据挖掘竞赛、中国高校计算机设计大赛、微信小程序开发赛。同时,我拥有3项软件著作权,名次均仅次于学校和指导老师。
另外,我还掌握python语言、掌握Tensor flow深度学习框架、熟悉微信小程序开发、掌握安卓原生开发。
这也是我人生中的第一次面试。非常感谢贵公司能够给予我这一次学习的机会。
Java基础知识
集合
HashMap、LinkedHashMap、ConcurrentHashMap、ArrayList、LinkedList、Vector的底层实现。
HashMap:
HashMap是基于哈希表的Map接口的非同步实现,允许null键和null值,存储效率特别高且灵活。
HashMap是基于hash算法实现的,通过put(key,value)存储对象到HashMap中,也可以通过get(key)从HashMap中获取对象。
当我们使用put的时候,首先HashMap会对key的hashCode值进行hash计算,根据hash值得到这个元素在数组中的位置,将元素存储在该位置的链表上。
当我们使用get的时候,首先HashMap会对key的hashCode值进行hash计算,根据hash值得到这个元素在数组中的。
如果两个键的hashcode相同,说明两个对象HashMap数组的同一位置上,接着HashMap会遍历链表中的每个元素,通过key的equals方法来判断是否为同一个key。
遍历HashMap链表中的每个元素,并对每个key进行hash计算,最后通过get方法获取其对应的值对象。
LinkedHashMap:
LinkedHashMap是HashMap的子类,LinkedHashMap自然会拥有HashMap的所有特性,HashMap和双向链表合二为一即是LinkedHashMap。
LinkedHashMap维护着一个运行于所有条目的双向链表,此链表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
1.按插入顺序的链表:在LinkedHashMap调用get方法后,输出的顺序和输入时的相同,这就是按插入顺序的链表,默认是按插入顺序排序
2.按访问顺序的链表:在LinkedHashMap调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。简单的说,按最近最少访问的元素进行排序(类似LRU算法)
ArrayList:
ArrayList可以理解为动态数组,它的容量能动态增长,该容量是指用来存储列表元素的数组的大小,随着向ArrayList中不断添加元素,其容量也自动增长 。ArrayList允许包括null在内的所有元素 ;ArrayList是List接口的非同步实现 ;ArrayList是有序的。
ArrayList实现了List接口、底层使用数组保存所有元素,其操作基本上是对数组的操作;
ArrayList继承了AbstractList抽象类,它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能;
ArrayList实现了RandmoAccess接口,即提供了随机访问功能,RandmoAccess是java中用来被List实现,为List提供快速访问功能的,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问;
ArrayList实现了Cloneable接口,即覆盖了函数clone(),能被克隆 ;
ArrayList实现了java.io.Serializable接口,意味着ArrayList支持序列化。
LinkedList:
LinkedList基于链表的List接口的非同步实现 ;LinkedList允许包括null在内的所有元素 ;LinkedList是有序的 ;LinkedList是fail-fast的。
ConcurrentHashMap:
ConcurrentHashMap基于双数组和链表的Map接口的同步实现;
ConcurrentHashMap中元素的key是唯一的、value值可重复;
ConcurrentHashMap不允许使用null值和null键;
ConcurrentHashMap是无序的。
数据结构:
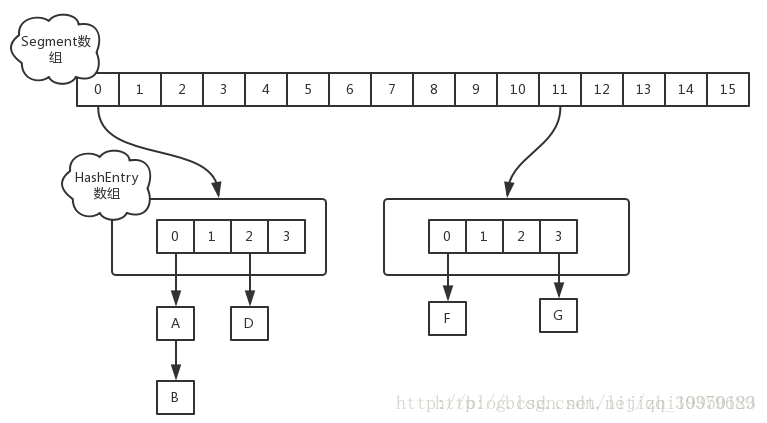
ConcurrentHashMap的数据结构为一个Segment数组,Segment的数据结构为HashEntry的数组,而HashEntry存的是我们的键值对,可以构成链表。可以简单的理解为数组里装的是HashMap。
Vector:
Vector实现了List接口、底层使用数组保存所有元素,其操作基本上是对数组的操作 ;
Vector继承了AbstractList抽象类,它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能 ;
Vector实现了RandmoAccess接口,即提供了随机访问功能,RandmoAccess是java中用来被List实现,为List提供快速访问功能的,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问;
Vector实现了Cloneable接口,即覆盖了函数clone(),能被克隆 ;
Vector实现了java.io.Serializable接口,意味着ArrayList支持序列化。
HashMap和Hashtable的区别。
Hashtable:
与HashMap很相似,是基于哈希表实现的,每个元素是一个key-value对,其内部是通过单链表解决冲突问题,容量不足(超过了阀值)时,会自动增长。
Hashtable是线程安全的,能用于多线程环境中。
实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
不同:
1,HashMap继承自AbstractMap类,Hashtable继承自Dictionary类,但二者都实现了Map接口。
2,HashMap线程不安全,HashTable线程安全。
3,HashMap是没有contains方法的,而包括containsValue和containsKey方法;hashtable则保留了contains方法,效果同containsValue,还包括containsValue和containsKey方法。
4,Hashmap是允许key和value为null值的,用containsValue和containsKey方法判断是否包含对应键值对;HashTable键值对都不能为空,否则包空指针异常。
5,计算Hash值的方式不同。为了得到元素的位置,首先需要根据元素的 KEY计算出一个hash值,然后再用这个hash值来计算得到最终的位置。
①:HashMap有个hash方法重新计算了key的hash值,因为hash冲突变高,所以通过一种方法重算hash值的方法:先调用hashCode方法计算出来一个hash值,再将hash与右移16位后相异或,从而得到新的hash值。
②:Hashtable通过计算key的hashCode()来得到hash值就为最终hash值。
6,扩容方式不同:HashMap 哈希扩容必须要求为原容量的2倍,而且一定是2的幂次倍扩容结果,而且每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入;而Hashtable扩容为原容量2倍加1;
7,解决Hash冲突的方式不同:
HashMap:1.如果冲突数量小于8,则是以链表方式解决冲突。
2.而当冲突大于等于8时,就会将冲突的Entry转换为红黑树进行存储。
3.而又当数量小于6时,则又转化为链表存储。
HashTable: 都是以链表方式存储。
ArrayList、LinkedList、Vector的区别。
LinkedList底层是双向链表,
Vector底层是可变数组,
ArrayList底层是可变数组;
LinkedList不允许随机访问,即查询效率低,异步、线程不安全,
Vector底层允许随机访问,同步、线程安全的,
ArrayList允许随机访问,即查询效率高;
LinkedList插入和删除效率快,
ArrayList插入和删除效率低,
Vector 需要额外开销来维持synchronized同步锁,性能慢;
对于随机访问的两个方法,get和set,ArrayList优于LinkedList,因为LinkedList要移动指针,
对于新增和删除两个方法,add和remove,LinedList比较占优势,因为ArrayList要移动数据;
Vector 可以使用Iterator、foreach、Enumeration输出,
ArrayList 只能使用Iterator、foreach输出。
HashMap和ConcurrentHashMap的区别。
底层数据结构不同,底层数据结构的不同又决定了HashMap和ConcurrentHashMap一个线程安全,一个线程不安全。
HashMap和LinkedHashMap的区别。
HashMap是无序的,LinkedHashMap通过维护一个额外的双向链表保证了迭代顺序。
HashMap是线程安全的吗。
我们都知道HashMap是非线程安全的,当我们只有一个线程在使用HashMap的时,自然不会有问题,但如果涉及到多个线程,并且有读有写的过程中,HashMap就会fail-fast。
ConcurrentHashMap是怎么实现线程安全的。
从CurrentHashMap的数据结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment。正是因为其内部的结构以及机制,ConcurrentHashMap在并发访问的性能上要比Hashtable和同步包装之后的HashMap的性能提高很多。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作。
多线程并发相关问题
创建线程的3种方式。
- 继承Thread类
自定义线程类继承Thread类
重写run()方法,编写线程执行体
创建线程对象,调用start()方法启动线程 - 实现Runnable接口
推荐使用Runnable对象,因为Java单继承的局限性
自定义线程类实现Runnable接口
实现run()方法,编写线程执行体
创建线程对象,调用start()方法启动对象 - 实现Callable接口
实现Callable接口,需要返回值类型
重写call方法,需要抛出异常
创建目标对象
创建执行服务:ExecutorService ser = Executors.newFixedThreadPool(1);
提交执行:Future result1 = ser.submit(11);
获取结果:boolean r1 = result1.get()
关闭服务:ser.shutdownNow();
什么是线程安全。
Runnable接口和Callable接口的区别。
wait方法和sleep方法的区别。
synchronized、Lock、ReentrantLock、ReadWriteLock。
介绍下CAS(无锁技术)。
volatile关键字的作用和原理。
什么是ThreadLocal。
创建线程池的4种方式。
ThreadPoolExecutor的内部工作原理。
分布式环境下,怎么保证线程安全。
JVM相关问题
介绍下垃圾收集机制(在什么时候,对什么,做了什么)。
垃圾收集有哪些算法,各自的特点。
类加载的过程。
双亲委派模型。
有哪些类加载器。
能不能自己写一个类叫java.lang.String。
设计模式相关问题
先问你熟悉哪些设计模式
然后再具体问你某个设计模式具体实现和相关扩展问题
数据库相关问题,针对Mysql
给题目让你手写SQL。
有没有SQL优化经验。
Mysql索引的数据结构。
SQL怎么进行优化。
SQL关键字的执行顺序。
有哪几种索引。
什么时候该(不该)建索引。
Explain包含哪些列。
框架相关问题
Hibernate和Mybatis的区别。
Spring MVC和Struts2的区别。
Spring用了哪些设计模式。
Spring中AOP主要用来做什么。
AOP,面向切面编程,对方法的一个增强。利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
@Before:在切点方法之前执行
@After:在切点方法之后执行
@AfterReturning:切点方法返回后执行
@AfterThrowing:切点方法抛异常执行
@Around:属于环绕增强,能控制切点执行前,执行后,用这个注解后,程序抛异常,会影响
Spring注入bean的方式。
什么是IOC,什么是依赖注入。
控制反转:将一组流程(控制权)从对象反转到框架中,而不是在对象中直接控制。
传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对象的创建以及外部资源获取。
有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象:由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转,依赖对象的获取被反转了。
IoC不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。
传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;
有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
IoC对编程实现由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
Spring是单例还是多例,怎么修改。
Spring事务隔离级别和传播性。
介绍下Mybatis/Hibernate的缓存机制。
Mybatis的mapper文件中#和$的区别。
Mybatis的mapper文件中resultType和resultMap的区别。
项目
有什么想问面试官的
这是我人生中第一次被面试,昨天在BOSS直聘上投简历也是抱着试试看的心态,能够被贵公司面试也是很荣幸。在这个面试之后我想您也对我有了一些了解,我是否适合贵公司的这个岗位想必您心里也已经有了答案。
我想问一下,如果我通过了您的面试,您能否说一下您对我的期望?如果我没有通过您的面试,那我想知道大概是什么时候,哪个问题开始,你觉得我不能胜任这份工作?最后,您能否对我在面试上、简历上以及学习上提出一些指导?















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









