







DML语句
DML语句:数据库操作语言,用来操作数据库表中的记录,如增删改查等。
在数据库的操作中对于数据的插入,删除,更新,查询自然称为了重中之重。只有掌握了相应的语句语法,才能让我们高效准确的对数据进行一个规范化的处理。本文将结合实例,对数据库中的数据的插入,删除,更新,查询等方面进行训练。
INSERT 语句
INSERT INTO table [(column [, column...])] VALUES(value [, value...]);
默认情况下,一次插入操作只插入一行
一次性插入多条记录:
INSERT INTO table [(column [, column...])]
VALUES(value [, value...]),(value [, value...])
如果为每列都指定值,则表名后不需列出插入的列名
如果不想在表名后列出列名,可以为那些无法指定的值插入null
可以使用如下方式一次插入多行
insert into 表名[(列名,…)]
select 语句——可以非常复杂。
注意点:
1.数据表存在
2.列名正确
3.对应的列名和数值一一对应
实例练习:
#创建数据表
CREATE TABLE dept(
dept_id INT(4) PRIMARY KEY NOT NULL AUTO_INCREMENT,
dept_name VARCHAR(50) NOT NULL,
dept_description VARCHAR(50),
dept_num INT(4)
)ENGINE=INNODB;
#插入数据
INSERT INTO dept VALUES('1','开发部','主要做开发','500');
INSERT INTO dept VALUES('2','运维部','主要做运维','50');
INSERT INTO dept VALUES('3','网络部','主要做网络','10');
INSERT INTO dept VALUES('4','市场部','主要做市场营销','100');
INSERT INTO dept(dept_id,dept_name) VALUES ('5','总经办');
SELECT * FROM dept;
#备份dept表
-- 创建备份一体化
CREATE TABLE dept_bak AS SELECT * FROM dept;
SELECT * FROM dept_bak;
DELETE FROM dept_bak;
SELECT * FROM dept_bak;
-- 存在了表,插入数据
INSERT INTO dept_bak SELECT * FROM dept;
注:这里新建的表是没有主键相关信息的,仅仅起到数据拷贝的作用
REPLACE语句
replace语句的语法格式有三种语法格式。
语法格式1:
replace into 表名 [(字段列表)] values (值列表)
语法格式2:
replace [into] 目标表名[(字段列表1) select (字段列表2) from 源表 where 条件表达式
语法格式3:
replace [into] 表名 set 字段1=值1, 字段2=值2
对比replace和insert语句:
replace语句的功能与insert语句的功能基本相同,不同之处在于:使用replace语句向表插入新记录时,如果新记录的主键值或者唯一性约束的字段值与已有记录相同,则已有记录先被删除(注意:已有记录删除时也不能违背外键约束条件),然后再插入新记录。
使用replace的最大好处就是可以将delete和insert合二为一(效果相当于更新),形成一个原子操作,这样就无需将delete操作与insert操作置于事务中了。
实例:
#replace插入数据
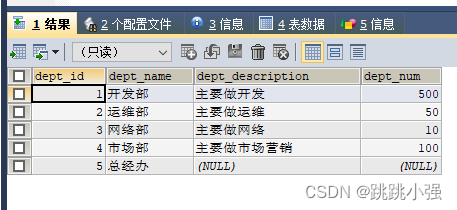
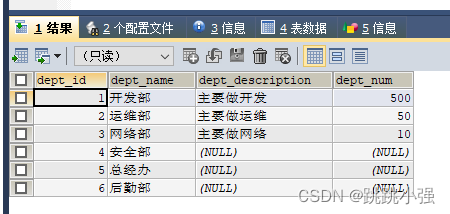
REPLACE INTO dept (dept_id,dept_name) VALUES ('4','安全部');
SELECT * FROM dept;
REPLACE INTO dept (dept_id,dept_name) VALUES ('6','后勤部');
UPDATE 语句
UPDATE table
SET column = value [, column = value]
[WHERE condition];
修改可以一次修改多行数据,修改的数据可用where子句限定,where子句里是一个条件表达式,只有符合该条件的行才会被修改。没有where子句意味着where字句的表达式值为true。也可以同时修改多列,多列的修改中间采用逗号(,)隔开
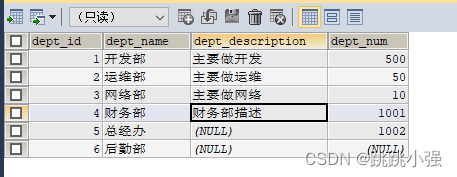
实例:
UPDATE dept SET dept_name='财务部',dept_description='财务部描述' WHERE dept_id = 4;
SELECT * FROM dept;
delete和TRUNCATE语句
DELETE FROM table_name [where 条件];
TRUNCATE TABLE table_name
DROP、TRUNCATE、DELETE的区别:
delete:删除数据,保留表结构,可以回滚,如果数据量大,很慢
truncate: 删除所有数据,保留表结构,不可以回滚,一次全部删除所有数据,速度相对很快
drop: 删除数据和表结构,删除速度最快。
实例:
#测试delete和truncate的异同,现在对于dept2这张表来说其主键id是有自增性的
CREATE TABLE dept2 LIKE dept;
INSERT INTO dept2 SELECT * FROM dept;
SELECT * FROM dept2;
DELETE FROM dept2;
TRUNCATE TABLE dept2;

我们可以看到delete并未删除我们的结构信息,自增到的数字未被归零。
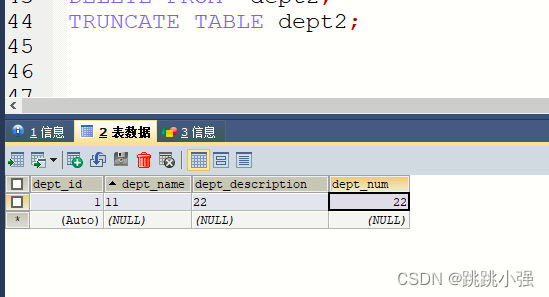
truncate对自增进行归零恢复。
SELECT语句
基础用法
SELECT {*, column [alias],...}
FROM table;
说明:
–SELECT列名列表。*表示所有列。
–FROM 提供数据源(表名/视图名)
–默认选择所有行
算数表达式
对数值型数据列、变量、常量可以使用算数操作符创建表达式(+ - * /)
对日期型数据列、变量、常量可以使用部分算数操作符创建表达式(+ -)
运算符不仅可以在列和常量之间进行运算,也可以在多列之间进行运算。
SELECT dept_id,dept_name,dept_num*10
FROM dept;
补充:
'+'说明
– MySQL的+默认只有一个功能:运算符
SELECT 100+80; # 结果为180
SELECT ‘123’+80; # 只要其中一个为数值,则试图将字符型转换成数值,转换成功做预算,结果为203
SELECT ‘abc’+80; # 转换不成功,则字符型数值为0,结果为80
SELECT ‘This’+‘is’; # 转换不成功,结果为0
SELECT NULL+80; # 只要其中一个为NULL,则结果为NULL
运算符的优先级
乘法和除法的优先级高于加法和减法
同级运算的顺序是从左到右
表达式中使用括号可强行改变优先级的运算顺序
SELECT dept_id,dept_name,dept_num*10+5 FROM dept;
SELECT dept_id,dept_name,dept_num*(10+5) FROM dept;
NULL值的使用
空值是指不可用、未分配的值
空值不等于零或空格
任意类型都可以支持空值
包括空值的任何算术表达式都等于空
字符串和null进行连接运算,得到也是null.
安全等于
安全等于<=>
1.可作为普通运算符的=
2.也可以用于判断是否是NULL 如:where salary is NULL/(is not NULL) ->where salary <=>NULL
示例1:查询emp表奖金为空的员工信息。
select * from emp where comm <=> NULL;
示例2:查询emp表奖金为50000的员工信息
select * from emp where comm <=> 50000;
字段别名
改变列的标题头,用于表示计算结果的含义,作为列的别名。如果别名中使用特殊字符,或者是强制大小写敏感,或有空格时,都可以通过为别名添加加双引号实现。
示例:
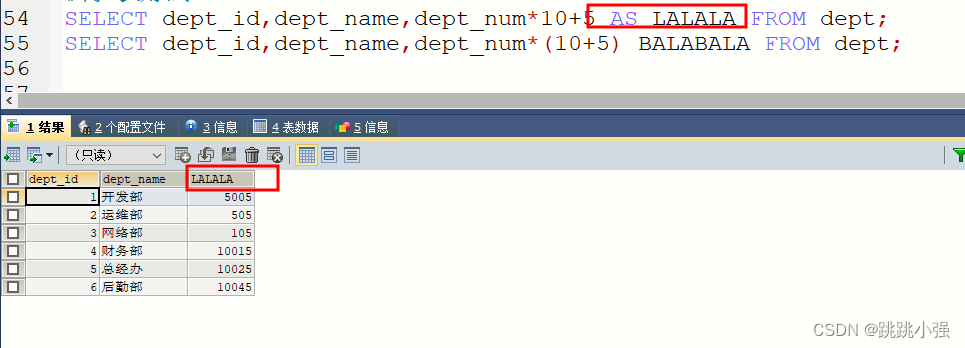
SELECT dept_id,dept_name,dept_num*10+5 AS LALALA FROM dept;
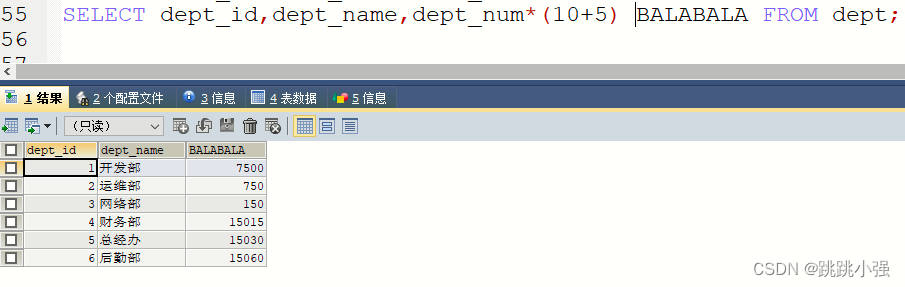
SELECT dept_id,dept_name,dept_num*(10+5) BALABALA FROM dept;
注:这里的AS可以省略,同一个显示列列表内出现两个字段的话,后面的默认为前面的别名。
示例:
#别名应用
SELECT dept_id '部门编号',dept_name AS '部门名称' FROM dept;
SELECT d.* FROM dept d;
SELECT d.dept_id '编号',d.dept_num '部门人数',d.`dept_name` '部门名称' FROM dept d;
重复记录
缺省情况下查询显示所有行,包括重复行
SELECT department_id
FROM employees;
使用DISTINCT关键字可从查询结果中清除重复行
SELECT DISTINCT department_id
FROM employees;
DISTINCT的作用范围是后面所有字段的组合
SELECT DISTINCT department_id , job_id
FROM employees;
条件查询
使用WHERE子句限定返回的记录
WHERE子句在FROM 子句后,where语句后可以插入许多运算符进行多样的数据匹配
SELECT[DISTINCT] {*, column [alias], ...}
FROM table–[WHEREcondition(s)];
WHERE中的字符串和日期值:
字符串和日期要用单引号扩起来
字符串是大小写敏感的,日期值是格式敏感的
WHERE中比较运算符:
SELECT last_name, salary, commission_pct
FROM employees
WHERE salary<=1500;
其他比较运算符:
使用BETWEEN运算符显示某一值域范围的记录
SELECTlast_name, salary
FROM employees
WHERE salary BETWEEN 1000 AND 1500;
IN运算符:
使用IN运算符获得匹配列表值的记录
SELECTemployee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (7902, 7566, 7788);
LIKE运算符:
使用LIKE运算符执行模糊查询
查询条件可包含文字字符或数字
(%) 可表示零或多个字符
( _ ) 可表示一个字符
SELECT last_name
FROM employees
WHERE last_name LIKE '_A%';
IS NULL运算符:
查询包含空值的记录
SELECT last_name, manager_id
FROM employees
WHERE manager_id IS NULL;
逻辑运算符:
使用AND运算符
AND需要所有条件都是满足T.
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary>=1100–4 AND job_id='CLERK';
使用OR运算符
OR只要两个条件满足一个就可以
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary>=1100 OR job_id='CLERK';
使用NOT运算符
NOT是取反的意思
SELECT last_name, job_id
FROM employees
WHERE job_id NOT IN ('CLERK','MANAGER','ANALYST');
使用正则表达式:REGEXP
<列名> regexp '正则表达式'
select * from product where product_name regexp '^2018';
数据分组
普通分组
GROUP BY子句的真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分组。
分组的含义是:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录。
分组函数忽略空值,。
结果集隐式按升序排列,如果需要改变排序方式可以使用Order by 子句。
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
#每个部门的平均工资
SELECT deptno,AVG(sal) FROM TB_EMP GROUP BY deptno
#每个部门每个职位的平均工资
SELECT deptno,job,AVG(sal) FROM TB_EMP GROUP BY deptno,job
#查每个部门的整体工资情况
#如果select语句中的列未使用组函数,那么它必须出现在GROUP BY子句中
#而出现在GROUP BY子句中的列,不一定要出现在select语句中
SELECT deptno,AVG(sal),MAX(sal),MIN(sal),SUM(sal),COUNT(1)
FROM TB_EMP
GROUP BY deptno #根据部门编号分组
示例:对此表进行dept_id的分组查询
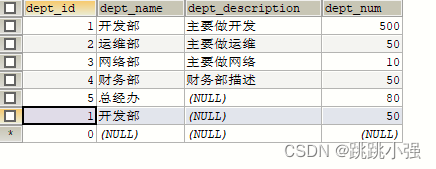
SELECT dept_id 部门编号,MAX(dept_num),MIN(dept_num),AVG(dept_num),COUNT(dept_num) ,sum(dept_num)
FROM dept3 GROUP BY dept_id;
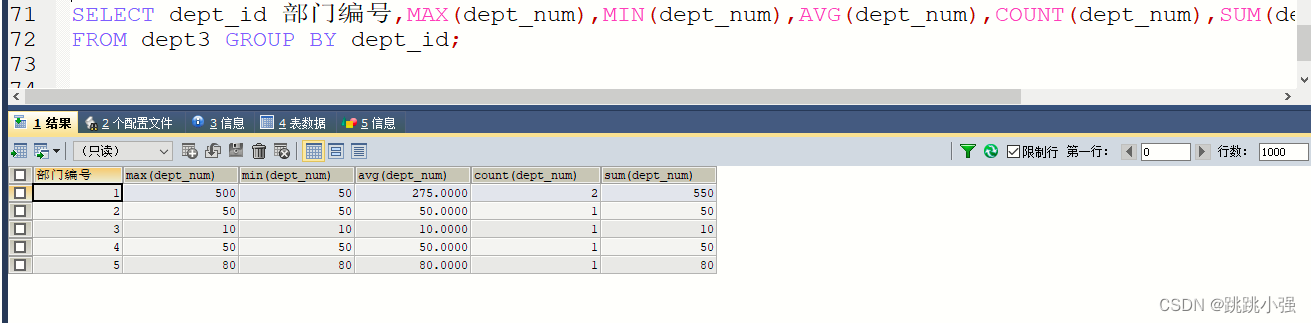
注:按什么分组就需要让这个列名出现在前面的查询列表里边,否则会报错。
分组结果过滤
限定组的结果:HAVING子句
HAVING子句用来对分组后的结果再进行条件过滤。
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BYcolumn];
HAVING子句用来对分组后的结果再进行条件过滤。
#查询部门平均工资大于2000的
#分组后加条件 使用having
#where和having都是用来做条件限定的,但是having只能用在group by之后
SELECT deptno,AVG(sal),MAX(sal),MIN(sal),SUM(sal),COUNT(1)
FROM TB_EMP
GROUP BY deptno
HAVING AVG(sal) > 2000
HAVING与WHERE的区别:
WHERE是在分组前进行条件过滤, HAVING子句是在分组后进行条件过滤,WHERE子句中不能使用聚合函数,HAVING子句可以使用聚合函数。
分组结果连接
将查询的某一类结果连接起来显示出来
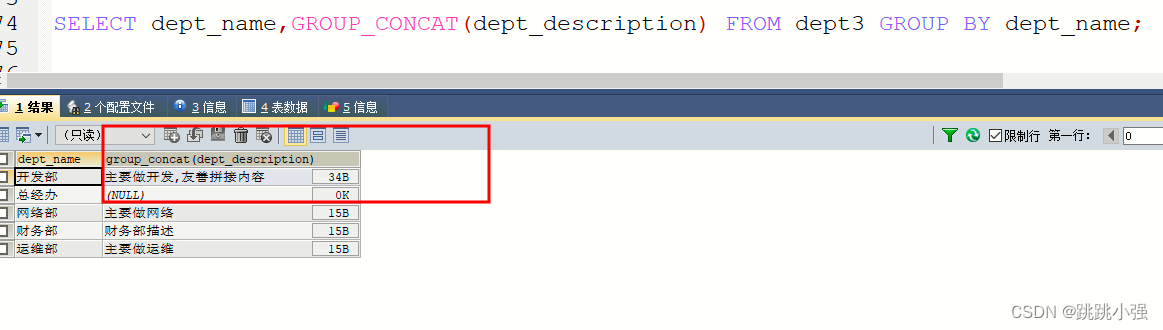
MySQL 多行数据合并 GROUP_CONCAT
Syntax: GROUP_CONCAT(expr)
示例:
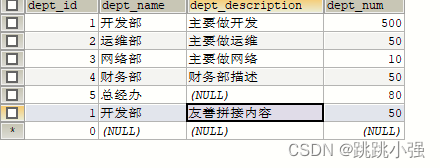
SELECT dept_name,GROUP_CONCAT(dept_description) FROM dept3 GROUP BY dept_name;
UNION联合查询
应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点:
1、要求多条查询语句的查询列数是一致的
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all 可以包含重复项
示例:
-- 联合查询中国或美国城市信息
SELECT * FROM city
WHERE countrycode IN ('CHN' ,'USA');
SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA'
结果显示限定与通配符
查询结果限定
在SELECT语句最后可以用LIMLT来限定查询结果返回的起始记录和总数量。MySQL特有。
SELECT … LIMIT offset_start,row_count;
offset_start:第一个返回记录行的偏移量。默认为0.
row_count:要返回记录行的最大数目。
例子:
SELECT * FROM TB_EMP LIMIT 5;/*检索前5个记录*/
SELECT * FROM TB_EMP LIMIT 5,10;/*检索记录行6-15*/
注:a,b从a开始往后面查询b条记录
MySQL中的通配符:
MySQL中的常用统配符有三个:
%:用来表示任意多个字符,包含0个字符
_ : 用来表示任意单个字符
escape:用来转义特定字符
示例: SELECT * FROM dept2 WHERE dep_desc LIKE '/_1111' ESCAPE '/';
含义:告诉系统/符号后的内容不需要进行通配符匹配















 3006
3006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









