








一、哈希表的理论基础
1、哈希表
哈希表(Hash table)/散列表:是根据关键码的值而直接进行访问的数据结构。
作用:
- 一般哈希表都是用来快速判断一个元素是否出现集合里/是否出现过。
例子:
例如要查询一个名字是否在这所学校里,则枚举的话时间复杂度是O(n),使用哈希表, 只需要O(1)。而学生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函数。
2、哈希函数

如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
- 为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,就要我们就保证了学生姓名一定可以映射到哈希表上了。
如果学生的数量大于哈希表的大小怎么办?
- 哈希碰撞
3、哈希碰撞
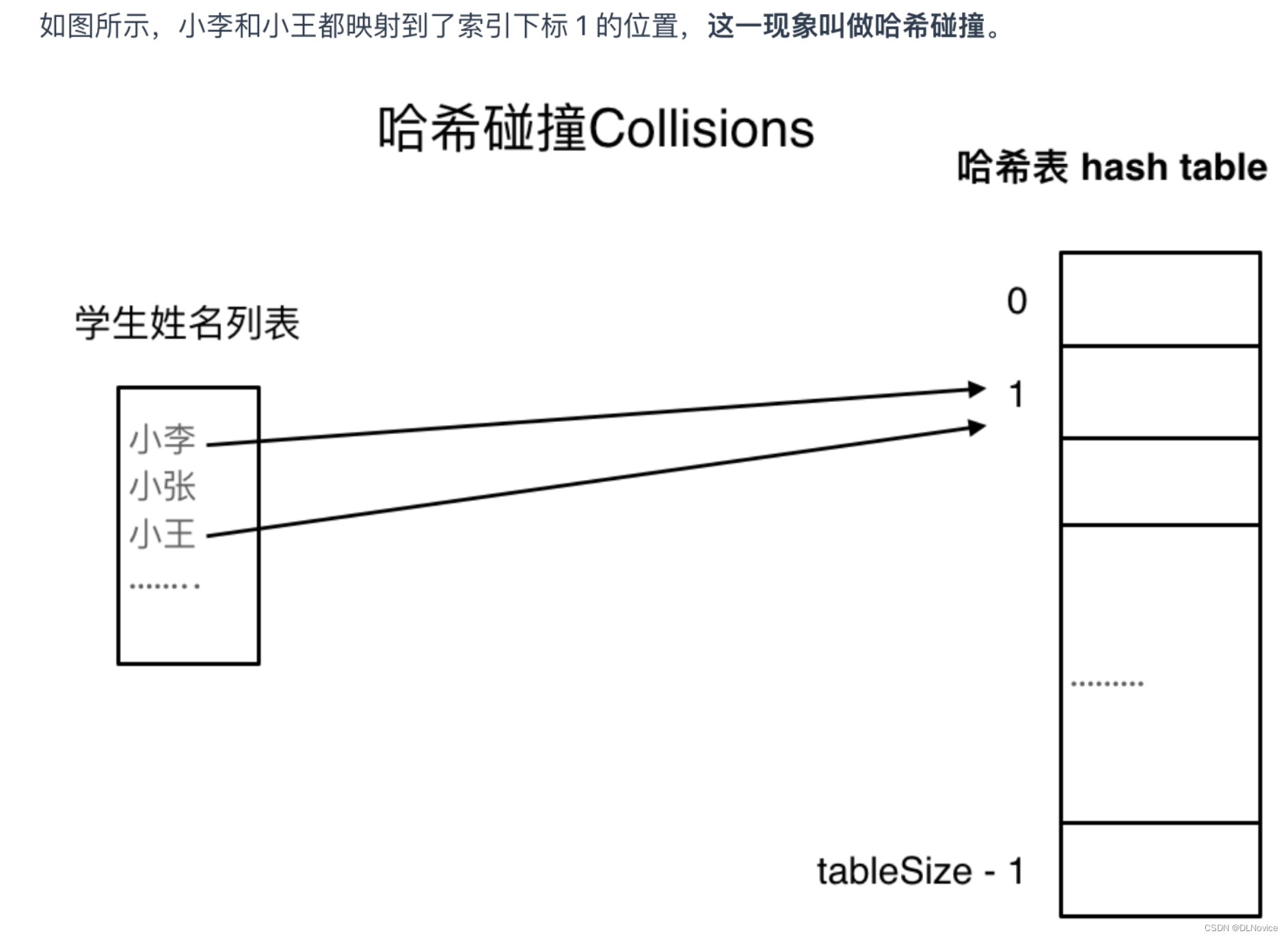
解决方式有两种:
- 拉链法
- 线性探测法
3.1 拉链法
小李和小王在索引1的位置发生了冲突,,我们可以新起一个链表,发生冲突的元素都被存储在链表中。
3.2 线性探测法
使用线性探测法,一定要保证tableSize大于dataSize。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求tableSize一定要大于dataSize
4、常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set (集合)
- map(映射)
这里数组就没啥可说的了,我们来看一下set和map。
4.1 set
在C++中,set提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
set的使用:
- 优先使用unordered_set,因为它的查询和增删效率是最优的
- 如果需要集合是有序的,那么就用set
- 如果要求不仅有序还要有重复数据的话,那么就用multiset
4.2 map
在C++中,map提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
二、有效的字母异位词
LeetCode:力扣题目链接
字母异位词:两字符串长度相同,字母相同,但顺序不同。
1、题意
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1: 输入: s = “anagram”, t = “nagaram” 输出: true
示例 2: 输入: s = “rat”, t = “car” 输出: false
说明: 你可以假设字符串只包含小写字母。
2、解题思路
-
创建一个长度为26的数组,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25,所有位置大小为 0
- 其他字母对应的下标位置可以借助ASCII码来确定 -> 基于 s[i] - ‘a’ 得到整型数字
-
遍历s时,对该字符在数组相应位置的数值做+1 操作即可,这样就记录字符串s里字符出现的次数。遍历t时,对该字符在数组相应位置的数值做- 1 操作即可;
-
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
3、示例代码
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {0};
for(int i=0; i<s.size(); i++){
record[s[i] - 'a']++;
}
for(int i=0; i<t.size(); i++){
record[t[i] - 'a']--;
}
for(int i=0; i<26; i++){
if(record[i] != 0){
return false;
}
}
return true;
}
};
三、两个数组的交集
LeetCode:力扣题目链接
1、题意
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
2、解题思路
这道题目,主要要学会使用一种哈希数据结构:unordered_set
其基本函数:
2.1 构造
- std::unordered_setstd::string c:初始化容器;
- std::unordered_setstd::string c{ “aaa”, “bbb”, “ccc” }:初始化容器,并将"aaa", “bbb”, "ccc"加入到容器中;
- std::unordered_setstd::string c{ 16 }:初始化容器,并设置16个桶;
2.2 添加元素
-
c.insert(“dddd”):向容器添加元素”dddd";
-
a.insert({ “aaa”,“bbbb”,“cccc” }):向容器添加元素"aaa",“bbbb”,“cccc”;
-
a.insert(b.begin(), b.end()):b是一个存储着和a相同类型元素的向量,可将b中所有元素添加到a中。
2.3 查找元素
-
a.find(“eeee”):查找元素"eeee",返回结果为a.end()则表明没有找到,否则返回所对应元素;
-
a.count(“eeee”):查找元素"eeee"在a中有几个(由于unordered_set中没有相同的元素,所以结果通常为0或1)。
2.4 查找桶接口
-
a.bucket_count():返回数据结构中桶的数量;
-
a.bucket_size(i):返回桶i中的大小;
-
a.bucket(“eeee"):返回元素"eeee"在哪个桶里。
2.5 观察器
-
a.hash_function()(“aaa”):返回"aaa"所对应的hash值;
-
a.key_eq()(“aaa”,“aaaa”) :当元素相同时返回true,否则返回false。
2.6 清除元素
-
a.clear():清除a中所有元素;
-
a.erase(“aaa”):清除元素"aaa"。
2.7 统计函数
-
a.size():返回a中总的元素个数;
-
a.max_size():返回a中最大容纳元素;
-
a.empty():判断a中是否为空。
3、示例代码
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
// if (nums_set.find(num) != nums_set.end()) { // 用下面这种判断形式也可
if(num1_set.count(num)){ // count函数返回num1_set中num这个数的数量
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
拓展:
问题: set和数组那么像,为啥我不直接用set?
答:直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
四、快乐数
LeetCode:力扣题目链接
1、题意
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 True ;不是,则返回 False 。
示例:
输入:19
输出:true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
2、解体思路
根据我们的探索,我们猜测会有以下三种可能。
- 最终会得到 1 ,则return true
- 最终会进入循环, 检测到循环,return false;
- 值会越来越大,最后接近无穷大。
最麻烦的就是第三种情况
但搜索发现,第三种情况不可能出现,可自行搜索检验。
3、方法一:哈希法
-
这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
-
判断sum是否重复出现就可以使用unordered_set。
示例代码:
class Solution {
public:
int getSum(int n){
// 除法运算符“/”和求余运算符“%”,例如:5/2=2, 121/10=12 ,5%2=1
int sum = 0; // 一定要对sum进行初始化为 0
while(n){
sum += (n % 10) * (n % 10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
int sum;
while(true){
sum = getSum(n);
if(sum == 1){
return true;
}
if(set.find(sum) != set.end()){
return false;
}
else{
set.insert(sum);
}
n = sum;
}
}
};
4、方法二:“快慢指针”法
我们只需要理解一种思路:使用 “快慢指针” 思想,可以找出循环
-
如果给定的数字最后会一直循环重复,那么快的指针(值)一定会追上慢的指针(值),也就是两者一定会相等。
-
如果没有循环重复,那么最后快慢指针也会相等,且都等于1。
示例代码:
class Solution {
public:
int getSum(int n){
// 除法运算符“/”和求余运算符“%”,例如:5/2=2, 121/10=12 ,5%2=1
int sum = 0; // 一定要对sum进行初始化为 0
while(n){
sum += (n % 10) * (n % 10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
int slow = n, fast = n;
do{
slow = getSum(slow);
fast = getSum(fast);
fast = getSum(fast);
}while(slow != fast);
return slow == 1;
}
};
五、两数之和
LeetCode:力扣题目链接
梦开始的地方,LeetCode第一题,这里我们用哈希法解决它。
1、题意
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
2、解题思路
本题呢,我就需要一个集合来存放我们遍历过的元素,然后在遍历数组的时候去询问这个集合,某元素是否遍历过,也就是 是否出现在这个集合。那么我们就应该想到使用哈希法了。
因为本地,我们不仅要知道元素有没有遍历过,还有知道这个元素对应的下标(题目最终需要 return 的是下标),需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
再来看一下使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value在保存数值所在的下标。
解题思路:
本题中map中的存储结构为 {key:数据元素,value:数组元素对应的下表}。
在遍历数组的时候,只需要向map去查询是否有和目前遍历元素比配的数值,如果有,就找到的匹配对,如果没有,就把目前遍历的元素放进map中,因为map存放的就是我们访问过的元素。
3、示例代码
补充知识:
find():
- 作用:find() 函数本质上是一个模板函数,用于在指定范围内查找和目标元素值相等的第一个元素。
- 用法:InputIterator find (InputIterator first, InputIterator last, const T& val); // 其中,first 和 last 为输入迭代器,[first, last) 用于指定该函数的查找范围;val 为要查找的目标元素。
- 补充:
- 该函数会返回一个输入迭代器,当 find() 函数查找成功时,其指向的是在 [first, last) 区域内查找到的第一个目标元素;如果查找失败,则该迭代器的指向和 last 相同。
- 值得一提的是,find() 函数的底层实现,其实就是用
==运算符将 val 和 [first, last) 区域内的元素逐个进行比对。这也就意味着,[first, last) 区域内的元素必须支持==运算符。
auto:
- 原理:根据后面的值,来自己推测前面的类型是什么。
- 作用:为了简化变量初始化,如果这个变量有一个很长很长的初始化类型,就可以用auto代替。
示例代码:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map<int,int> map;
for(int i=0; i<nums.size(); i++){
auto iter = map.find(target - nums[i]); // 遍历nums中的当前元素,并在map中寻找是否有匹配的key
if(iter != map.end()){ // 如果存在,则返回两个数的下标
return {iter->second, i};
}
map.insert(pair<int,int>(nums[i], i)); // 若不存在,则将num[i]的数值与下标放入map
}
return {};
}
};
六、四数相加
LeetCode:力扣题目链接
1、题意
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
- 0 <= i, j, k, l < n
- nums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
示例 1:
输入:nums1 = [1,2], nums2 = [-2,-1], nums3 = [-1,2], nums4 = [0,2]
输出:2
解释:
两个元组如下:
1. (0, 0, 0, 1) -> nums1[0] + nums2[0] + nums3[0] + nums4[1] = 1 + (-2) + (-1) + 2 = 0
2. (1, 1, 0, 0) -> nums1[1] + nums2[1] + nums3[0] + nums4[0] = 2 + (-1) + (-1) + 0 = 0
示例 2:
输入:nums1 = [0], nums2 = [0], nums3 = [0], nums4 = [0]
输出:1
2、解题思路
首先明确,我们只需要 return 符合题意的元组出现的次数,无需具体列出元组
- 首先定义 一个unordered_map,key放a和b两数之和,value 放a和b两数之和出现的次数。
- 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中。
- 定义int变量count,用来统计 a+b+c+d = 0 出现的次数。
- 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就用count把map中key对应的value也就是出现次数统计出来。
- 最后返回统计值 count 就可以了
3、示例代码
先看个长的丑的代码(C++小白):
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
unordered_map<int,int> map;
int sum = 0;
for(int i=0; i<nums1.size(); i++){
for(int j=0; j<nums2.size(); j++){
sum = (nums1[i] + nums2[j]);
if(map.find(sum) != map.end()){
map[sum]++;
}
else{
map.insert(pair<int,int>(sum,1));
}
}
}
int count = 0;
int target = 0;
for(int i=0; i<nums3.size(); i++){
for(int j=0; j<nums4.size(); j++){
target = 0 - (nums3[i] + nums4[j]);
if(map.find(target) != map.end()){
count += map[target];
}
}
}
return count;
}
};
代码随想录示例代码:
class Solution {
public:
int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {
unordered_map<int, int> umap; //key:a+b的数值,value:a+b数值出现的次数
// 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
for (int a : A) {
for (int b : B) {
umap[a + b]++;
}
}
int count = 0; // 统计a+b+c+d = 0 出现的次数
// 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
for (int c : C) {
for (int d : D) {
if (umap.find(0 - (c + d)) != umap.end()) {
count += umap[0 - (c + d)];
}
}
}
return count;
}
};
问题:“umap[a + b]++;”这一步中,umap的value不初始化,默认为0吗?
七、赎金信
LeetCode:力扣题目链接
1、题意
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
示例 1:
输入:ransomNote = "a", magazine = "b"
输出:false
示例 2:
输入:ransomNote = "aa", magazine = "ab"
输出:false
示例 3:
输入:ransomNote = "aa", magazine = "aab"
输出:true
2、解题思路
首先审清题意,我开始时觉得需要遍历magazine,如“aab”,记录成[“a”,“a”,“b”,“aa”,“ab”, ‘“aab”’],越想越麻烦。
后来发现我们只需要统计magazine中各个字符串的数量可以拼成ransomNote,不需要考虑字符的顺序,例如:
输入:ransomNote = "ac", magazine = "abc"
输出:true
这就简单了,直接用一个长26的数组记录magazine中a~z出现的次数就结束了。
3、示例代码
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
int record[26] = {0};
for(int i=0; i<magazine.size(); i++){
record[magazine[i] - 'a']++;
}
for(int i=0; i<ransomNote.size(); i++){
record[ransomNote[i] - 'a']--;
}
for(int i=0; i<26; i++){
if(record[i]<0){
return false;
}
}
return true;
}
};
八、三数之和
LeetCode:力扣题目链接
1、题意
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
注意: 答案中不可以包含重复的三元组。
示例:
给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为: [ [-1, 0, 1], [-1, -1, 2] ]
2、方法一、哈希法
本题不推荐使用哈希法。
解题思路:
- 两层for循环就可以确定 a 和b 的数值了
- 可以使用哈希法来确定 0-(a+b) 是否在 数组里出现过
难点:
- 题目中说的不可以包含重复的三元组,去重的过程不好处理,有很多小细节,如果在面试中很难想到位,而且操作非常容易超时。
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
// 找出a + b + c = 0
// a = nums[i], b = nums[j], c = -(a + b)
for (int i = 0; i < nums.size(); i++) {
// 排序之后如果第一个元素已经大于零,那么不可能凑成三元组
if (nums[i] > 0) {
break;
}
if (i > 0 && nums[i] == nums[i - 1]) { //三元组元素a去重
continue;
}
unordered_set<int> set;
for (int j = i + 1; j < nums.size(); j++) {
if (j > i + 2
&& nums[j] == nums[j-1]
&& nums[j-1] == nums[j-2]) { // 三元组元素b去重
continue;
}
int c = 0 - (nums[i] + nums[j]);
if (set.find(c) != set.end()) {
result.push_back({nums[i], nums[j], c});
set.erase(c);// 三元组元素c去重
} else {
set.insert(nums[j]);
}
}
}
return result;
}
};
3、方法二、双指针法(推荐)
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
// 找出a + b + c = 0
// a = nums[i], b = nums[left], c = nums[right]
for (int i = 0; i < nums.size(); i++) {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
if (nums[i] > 0) {
return result;
}
// 对a去重我们想到两种方法nums[i] == nums[i + 1] 和nums[i] == nums[i - 1],然而前者这次不能使用
// 错误去重a方法,将会漏掉-1,-1,2 这种情况
/*
if (nums[i] == nums[i + 1]) {
continue;
}
*/
// 正确去重a方法
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// 去重复逻辑如果放在这里,0,0,0 的情况,可能直接导致 right<=left 了,从而漏掉了 0,0,0 这种三元组
/*
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
*/
if (nums[i] + nums[left] + nums[right] > 0) right--;
else if (nums[i] + nums[left] + nums[right] < 0) left++;
else {
result.push_back(vector<int>{nums[i], nums[left], nums[right]});
// 去重逻辑应该放在找到一个三元组之后,对b 和 c去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
return result;
}
};
简洁代码(去掉上面一堆注释):
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
for(int i=0; i < nums.size(); i++){
if(nums[i] > 0){
return result;
}
if(i > 0 && nums[i] == nums[i-1]){
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while(left < right){
if(nums[i] + nums[left] + nums[right] > 0) right--;
else if(nums[i] + nums[left] + nums[right] < 0) left++;
else{
result.push_back(vector<int>{nums[i], nums[left], nums[right]});
while(left < right && nums[left] == nums[left+1]) left++;
while(left < right && nums[right] == nums[right-1]) right--;
left++;
right--;
}
}
}
return result;
}
};
4、去重逻辑的思考
本题难点就是去重。
4.1 a的去重
说道去重,其实主要考虑三个数的去重。 a, b ,c, 对应的就是 nums[i],nums[left],nums[right]
a 如果重复了怎么办,a是nums里遍历的元素,那么应该直接跳过去。
但这里有一个问题,是判断 nums[i] 与 nums[i + 1]是否相同,还是判断 nums[i] 与 nums[i-1] 是否相同。
有同学可能想,这不都一样吗。
其实不一样!
都是和 nums[i]进行比较,是比较它的前一个,还是比较他的后一个。
如果我们的写法是 这样:
if (nums[i] == nums[i + 1]) { // 去重操作
continue;
}
那就我们就把 三元组中出现重复元素的情况直接pass掉了。 例如{-1, -1 ,2} 这组数据,当遍历到第一个-1 的时候,判断 下一个也是-1,那这组数据就pass了。
我们要做的是 不能有重复的三元组,但三元组内的元素是可以重复的!
所以这里是有两个重复的维度。
那么应该这么写:
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
这么写就是当前使用 nums[i],我们判断前一位是不是一样的元素,在看 {-1, -1 ,2} 这组数据,当遍历到 第一个 -1 的时候,只要前一位没有-1,那么 {-1, -1 ,2} 这组数据一样可以收录到 结果集里。
这是一个非常细节的思考过程。
4.2 b与c的去重
很多同学写本题的时候,去重的逻辑多加了 对right 和left 的去重:(代码中注释部分)
while (right > left) {
if (nums[i] + nums[left] + nums[right] > 0) {
right--;
// 去重 right
while (left < right && nums[right] == nums[right + 1]) right--;
} else if (nums[i] + nums[left] + nums[right] < 0) {
left++;
// 去重 left
while (left < right && nums[left] == nums[left - 1]) left++;
} else {
}
}
但细想一下,这种去重其实对提升程序运行效率是没有帮助的。
拿right去重为例,即使不加这个去重逻辑,依然根据 while (right > left) 和 if (nums[i] + nums[left] + nums[right] > 0) 去完成right-- 的操作。
多加了 while (left < right && nums[right] == nums[right + 1]) right--; 这一行代码,其实就是把 需要执行的逻辑提前执行了,但并没有减少 判断的逻辑。
最直白的思考过程,就是right还是一个数一个数的减下去的,所以在哪里减的都是一样的。
所以这种去重 是可以不加的。 仅仅是 把去重的逻辑提前了而已。
九、四数之和
1、题意
题意:给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
注意:
答案中不可以包含重复的四元组。
示例: 给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。 满足要求的四元组集合为: [ [-1, 0, 0, 1], [-2, -1, 1, 2], [-2, 0, 0, 2] ]
2、解题思路
依旧是双指针法:
-
15.三数之和 (opens new window)的双指针解法是一层for循环num[i]为确定值,然后循环内有left和right下标作为双指针,找到nums[i] + nums[left] + nums[right] == 0。
-
四数之和的双指针解法是两层for循环nums[k] + nums[i]为确定值,依然是循环内有left和right下标作为双指针,找出nums[k] + nums[i] + nums[left] + nums[right] == target的情况,三数之和的时间复杂度是O(n2),四数之和的时间复杂度是O(n3) 。
3、示例代码
class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
for(int k=0; k<nums.size();k++){
if(nums[k]>target && nums[k]>=0) break; // 注意 nums[k]>=0,因为如果nums[k]>target,而nums[k]<0,代表target是一个小于nums[k]的负数,负数累加依旧可以达到target
if(k>0 && nums[k]==nums[k-1]) continue;
for(int j=k+1; j<nums.size(); j++){
// 注意二次剪枝
if(nums[k] + nums[j]>target && nums[k] + nums[j]>=0) break;
if(j>k+1 && nums[j] == nums[j-1]) continue;
int left = j+1;
int right= nums.size()-1;
while(left < right){
// 注意加入(long)不然会超限制
if((long)nums[k] + nums[j] + nums[left] + nums[right] > target) right--;
else if((long)nums[k] + nums[j] + nums[left] + nums[right] < target) left++;
else{
result.push_back(vector<int>{nums[k], nums[j], nums[left], nums[right]});
while(left<right && nums[left]==nums[left+1]) left++;
while(left<right && nums[right]==nums[right-1]) right--;
left++;
right--;
}
}
}
}
return result;
}
};
十、总结
用处:一般来说哈希表都是用来快速判断一个元素是否出现集合里。
常见的三种哈希结构:
- 数组
- set(集合)
- map(映射)
虽然map是万能的,但什么时候用数组,什么时候用se还是需要知道的。
1、数组作为哈希表
一些应用场景就是为数组量身定做的。
2、 set作为哈希表
在349. 两个数组的交集 (opens new window)中我们给出了什么时候用数组就不行了,需要用set。
这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
主要因为如下两点:
- 数组的大小是有限的,受到系统栈空间(不是数据结构的栈)的限制。
- 如果数组空间够大,但哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
所以此时一样的做映射的话,就可以使用set了。
3、map作为哈希表
在1.两数之和 (opens new window)中map正式登场。
来说一说:使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
map是一种<key, value>的结构,本题可以用key保存数值,用value在保存数值所在的下标。所以使用map最为合适。
















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











