






你是否曾经在浏览一篇篇论文时,常常被那些密密麻麻的术语和长长的摘要弄的眼花缭乱?别担心,今天我们将利用NLTK和Gensim这两个强大的Python库来帮助我们从论文的摘要中提取出最有价值的关键词,让我们一眼就能抓住文章的核心内容。
在之前的教学中,我们已经学会了用Gensim库中的LDA进行主题建模,今天我们将学习Gensim库的另一项重要的文本分析方法——关键词提取分析。关键词提取能够帮助我们从大量的文本中提取出代表性关键词,这能让我们在阅读文献时快速筛选出相关研究,并精确地定位文献的相关领域。接下来,我们将具体学习关键词提取的相关步骤。
一、准备工作
1. 第一步:安装所需库,并加载需要的函数
- 首先,我们需要在Python运行的环境中安装以下库:Pandas、Numpy、NLTK和Gensim:

- 接下来,我们可以提前加载后面会用到的函数:
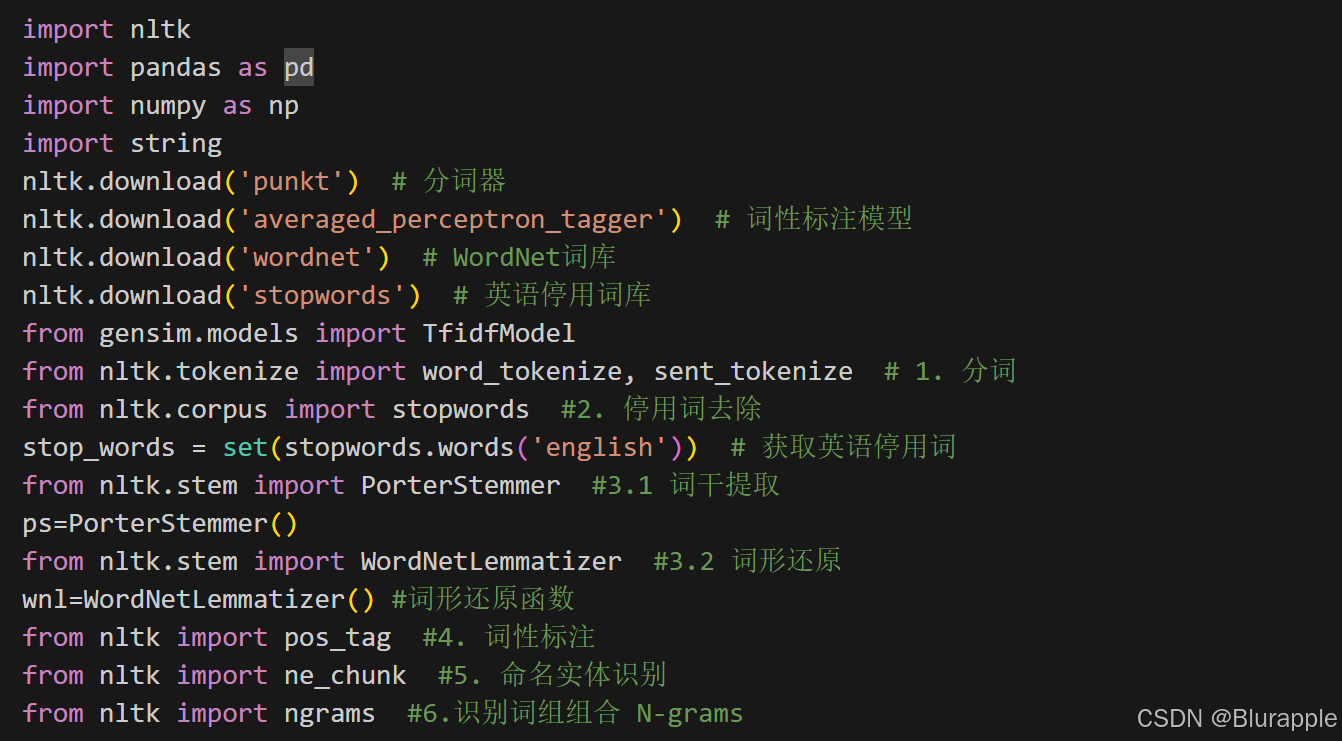
2. 第二步:准备数据集
我们从kaggle上下载了一个包含两万多篇论文摘要的文本数据集,为了简化代码的运算量,我们随机选取了其中150个样本作为研究,代码及数据格式如下所示:


二、关键词提取流程
在熟悉了需要用到的函数和数据集后,我们就可以开始着手操作关键词提取的具体步骤了。
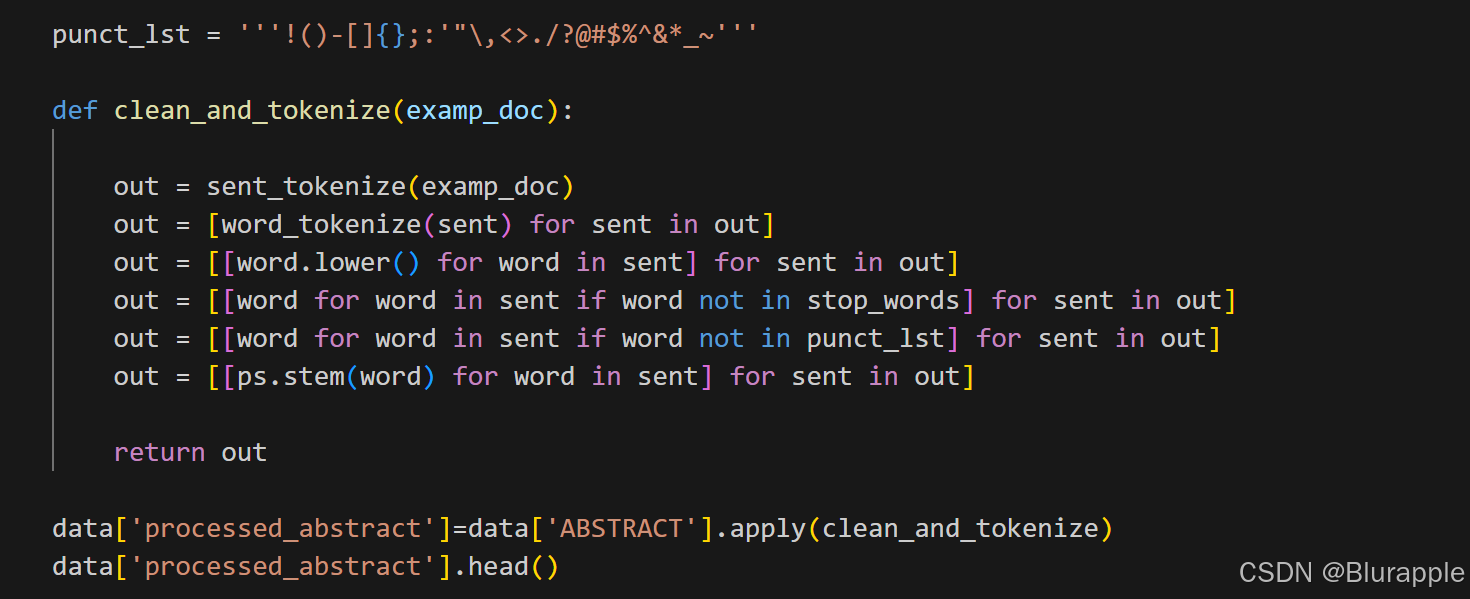
第一步:文本预处理
在开始提取每一篇摘要的关键词之前,我们需要对这150篇摘要进行一些基本的清晰和预处理。常见的步骤包括:
- 分词:将每篇摘要拆分为一个个单词
- 去除停用词:如“the”、“is”、“in”这类的不影响文本中心意思的词叫停用词,我们可以去除以简化运算量
- 转换大小写:将词全部转换为小写,避免同一词的不同形式被当作不同的词
- 词干提取:将词语还原为词根(例如,“running”转换为“run”)
具体代码及结果如下:
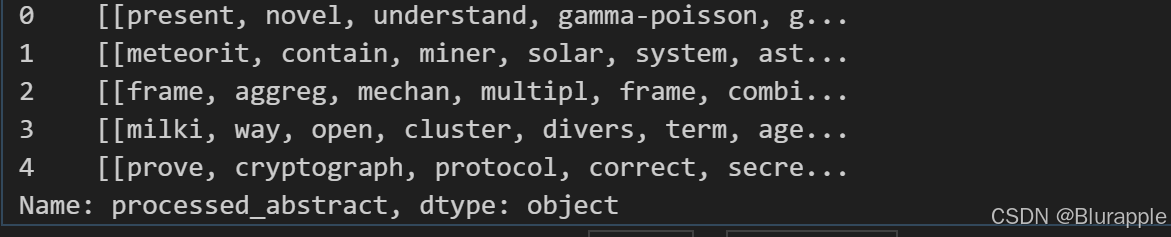
第二步:构建词袋模型
词袋模型 (Bag-of-Words, BoW) 是文本分析中常用的一种表示方式,它将文本转换为一个单词的出现频率矩阵。
具体代码如下:

第三步:使用TF-IDF提取关键词:
TF-IDF(Term Frequency-Inverse Document Frequency)是一种计算单词在文档中重要性的统计方法,单词对应的TF-IDF值越高,代表它在文档中越重要。Gensim提供了TfidfModel,它可以帮助我们从词袋模型中提取出最重要的关键词。
具体代码如下:

这展示了第一篇摘要部分单词的TF-IDF值: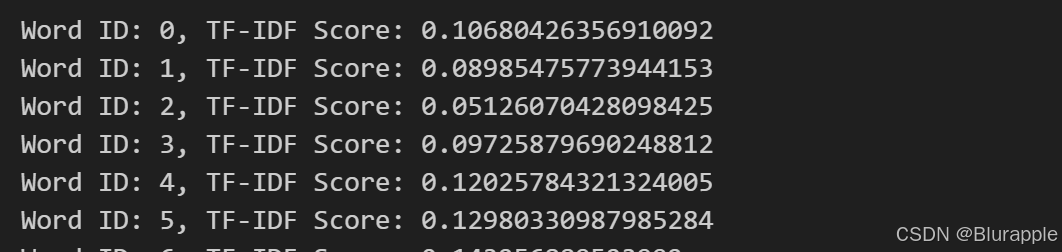
第四步:提取关键词
最后,我们根据TF-IDF值可以提取出每个摘要的关键词。我们提取出每篇摘要的5个关键词,即在每篇摘要中选出TF-IDF值最高的五个单词。这些关键词可以帮助我们快速理解文章的主题。
具体代码如下:

第一篇摘要的关键词提取结果如下:

- matrix:可能与论文中的数学建模、数据结构或某种矩阵运算(如特征提取、主成分分析)有关。
- gap:可能是研究中的理论空白、实验结果之间的差距,也可能是模型性能的改进空间。
- margin:可能是机器学习领域的研究,也可能与论文的结果范围或偏差有关。
- factor:可能代表某种因子或变量,涉及影响实验结果或模型性能的关键要素。
- estim:可能是estimate的简写,表明论文的重点可能在估计方法或估计某些参数。
这些关键词结合在一起,可能指向出这是一篇讨论数学方法、机器学习模型优化或数据分析的论文。
三、小结
就这样,我们完成了关键词提取的整个流程。通过NLTK和Gensim这两个工具,我们不仅能清理文本,还能提取出最重要的关键词,帮助我们更好地理解文本内容。
如果你有任何疑问或对其他NLP技术感兴趣,欢迎在评论区留言交流!

















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









