






一、题目描述
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是"wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke"是一个子序列,不是子串。
提示:
0 <= s.length <= 5 * 104s由英文字母、数字、符号和空格组成
二、解题思路+代码
思路:这道题操作的对象是字符串,并且还要找到最长的无重复字符的子串,所以可以肯定的是我们必须要从头到尾遍历所有的字符。
首先,我们必须了解什么是无重复字符子串,顾名思义就是从原字符串中截取的连续字符片段,并且该字符子串中的没有重复的字符。
然后,在我的理解中,我们就需要有一个数据结构来从原字符串中截取字符子串。
最后,我们还需要一个额外的变量记录无重复字符子串的长度。
2.1 方法一:字符拼接法
因为我们的目的是从原字符串中截取无重复的字符子串,所以我们可以构建一个空字符串,通过顺序遍历原字符串和字符串相加的形式生成字符子串。当字符子串中包含重复字符的时候,就从截断在第一个重复字符处,于是截断后的字符子串便又恢复了无重复的状态。在遍历的过程中,我们还设立了一个额外的变量用于记录最大的无重复字符子串的长度。
以下是遍历的示例(原字符串):
a b c a d a 以下便是遍历得到字符子串的过程:
(1)最大的无重复字符子串的长度为1:
a(2)最大的无重复字符子串的长度为2:
a b(3)最大的无重复字符子串的长度为3:
a b c(4)最大的无重复字符子串的长度为3(因为第4步遍历得到的字符a被包含在字符子串中,所以从第一个a处之前的字符都被截断,才能保证字符子串始终保持无重复的状态):
b c a(5)最大的无重复字符子串的长度为4:
b c a d(6)最大的无重复字符子串的长度为4(与第4步相同,因为第6步遍历得到的字符a被包含在字符子串中,所以从第一个a处之前的字符都被截断,才能保证字符子串始终保持无重复的状态):
d a至此便得到了无重复字符的最长子串长度为4。
代码:
class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
:type s: str
:rtype: int
"""
tmp_str = "" # 创建空字符串
result = 0 # 用于记录无重复字符子串的最大长度
for s1 in s: # 遍历原字符串
if s1 not in tmp_str: # 如果字符子串中不包含该字符,便添加到字符串的最后面
tmp_str += s1
else: # 如果字符子串包含该重复字符,便使用切片法从重复字符处截断
tmp_str = tmp_str[tmp_str.find(s1) + 1:] # find方法能够返回指定字符的索引
tmp_str += s1 # 依然要将遍历得到的字符拼接到最后面
if len(tmp_str) > result:
result = len(tmp_str)
return result
2.2 方法二:指针法
指针法在思想上其实和字符拼接法差不多,只是使用了字典结构用于存储字符和其在原字符串中的索引。
指针法的示意图如下图所示:
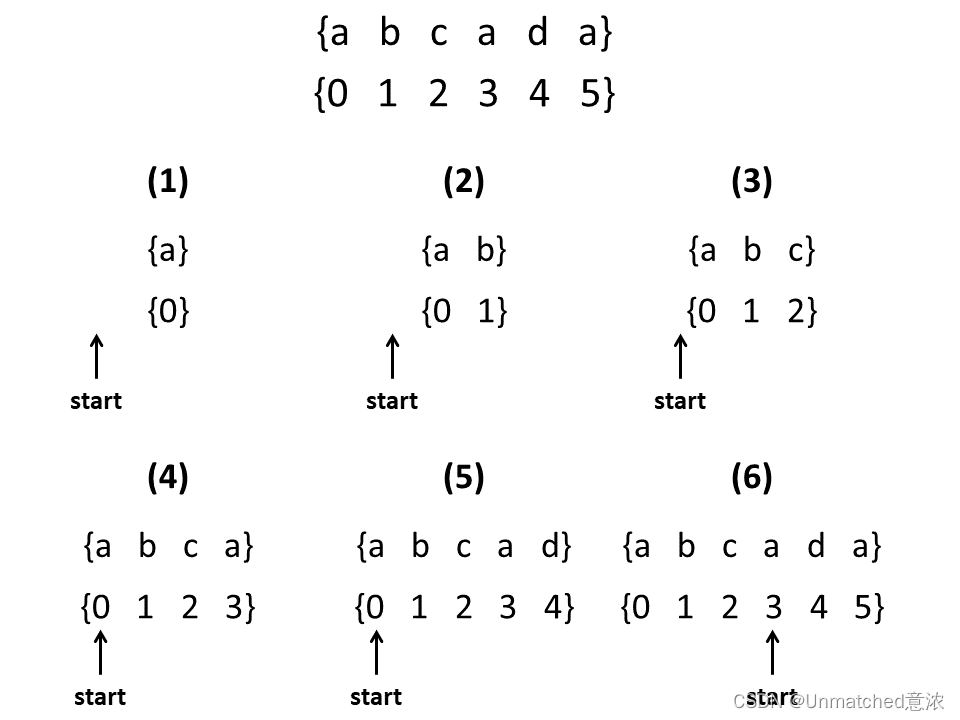
如图所示,使用字典存储字符,没有截取的操作,但是会构建一个start指针,用来记录第一个无重复字符的位置,于是用当前字符的索引减去起始指针的位置就得到了无重复字符子串的最大长度。
代码:
class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
:type s: str
:rtype: int
"""
dict = {}
start = -1 # 起始指针
result = 0
for i in range(len(s)):
if s[i] in dict and dict[s[i]] > start:
start = dict[s[i]]
dict[s[i]] = i
else:
dict[s[i]] = i
if i - start > result:
result = i - start
return result 














 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









