







一、Prometheus概述
1、Prometheus介绍
- Prometheus 是一个开源的服务监控系统和时序数据库,其提供了通用的数据模型和快捷数据采集、存储和查询接口。它的核心组件Prometheus server会定期从静态配置的监控目标或者基于服务发现自动配置的自标中进行拉取数据,当新拉取到的数据大于配置的内存缓存区时,数据就会持久化到存储设备当中。
- 每个被监控的主机都可以通过专用的exporter 程序提供输出监控数据的接口,它会在目标处收集监控数据,并暴露出一个HTTP接口供Prometheus server查询,Prometheus通过基于HTTP的pull的方式来周期性的采集数据。
- 任何被监控的目标都需要事先纳入到监控系统中才能进行时序数据采集、存储、告警和展示,监控目标可以通过配置信息以静态形式指定,也可以让Prometheus通过服务发现的机制进行动态管理。
2、Prometheus特点
- 多维数据模型:由指标名称和键值对标识的时间序列数据
时序数据,是在一段时间内通过重复测量(measurement)而获得的观测值的集合;将这些观测值绘制于图形之上,它会有一个数据轴和一个时间轴;
服务器指标数据、应用程序性能监控数据、网络数据等也都是时序数据;
- PromQL一种灵活的查询语言,可以利用多维数据完成复杂查询
- 内置时间序列数据库Prometheus;外置的远端存储通常会用:InfluxDB、openTsDB等
- 基于HTTP的pull(拉取)方式采集时间序列数据
- 同时支持PushGateway组件push(推送)方式收集数据
- 通过静态配置或服务发现发现目标
- 支持作为数据源接入Grafana,多种模式的绘图和仪表板支持
3、Prometheus架构
这张图说明了prometheus的架构和一些其生态系统组成:
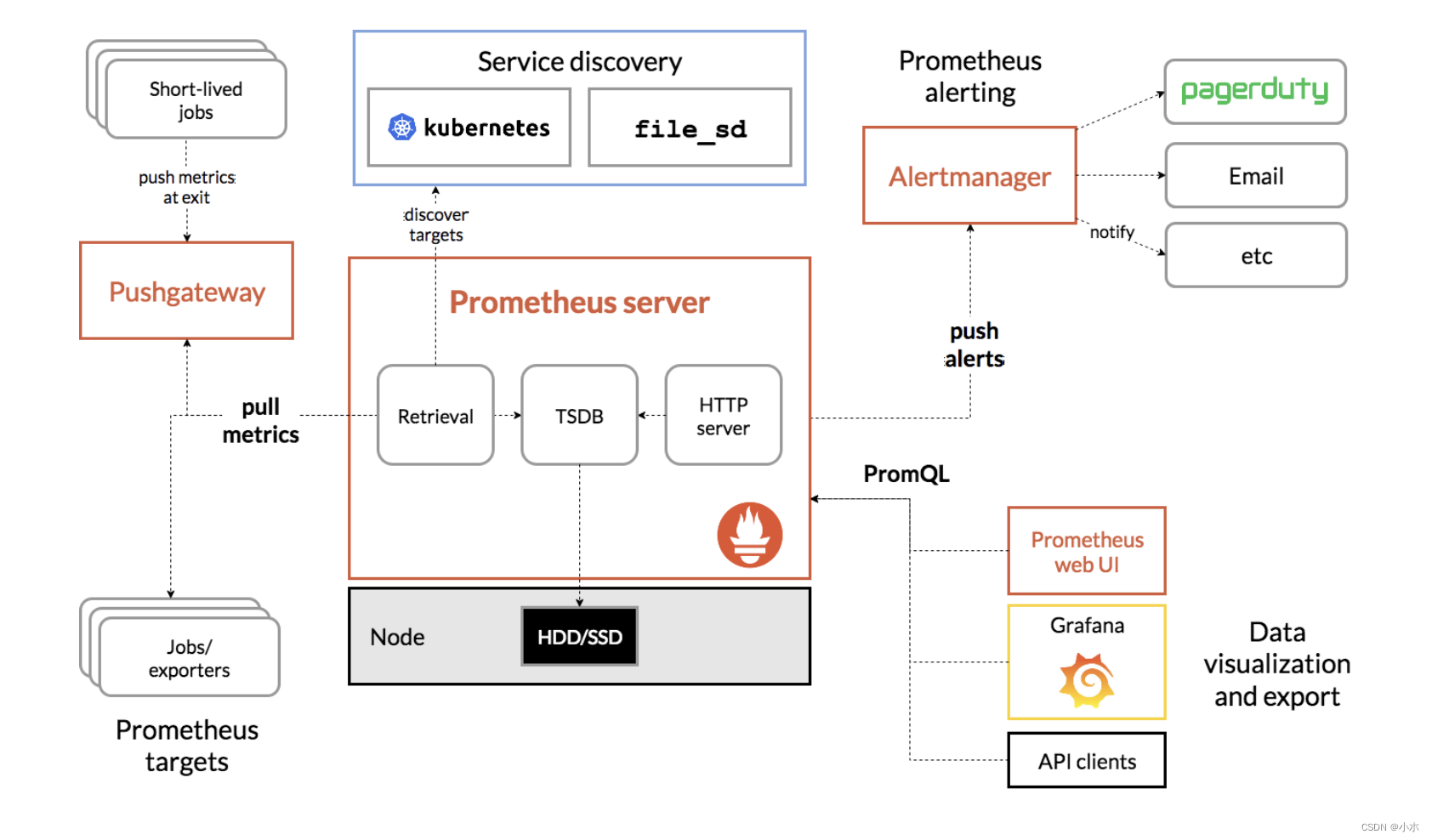
4、Prometheus生态组件组成
- Prometheus server Prometheus服务器,用于抓取和存储时间序列数据。Prometheus server 由三个部分组成:Retrival,Storage,PromQL
Retrieval:负责在活跃的target 主机上抓取监控指标数据。
Storage:存储,主要是把采集到的数据存储到磁盘中。默认为15天(可修改)。 PromQL:是Prometheus提供的查询语言模块。
- client libraries 客户端库,用于检测应用程序代码的客户端库。Prometheus本身提供了支持多种语言的SDK,用于对接 Prometheus Server, 可以查询和上报数据。目的在于为那些期望原生提供Instrumentation功能的应用程序提供便捷的开发途径。
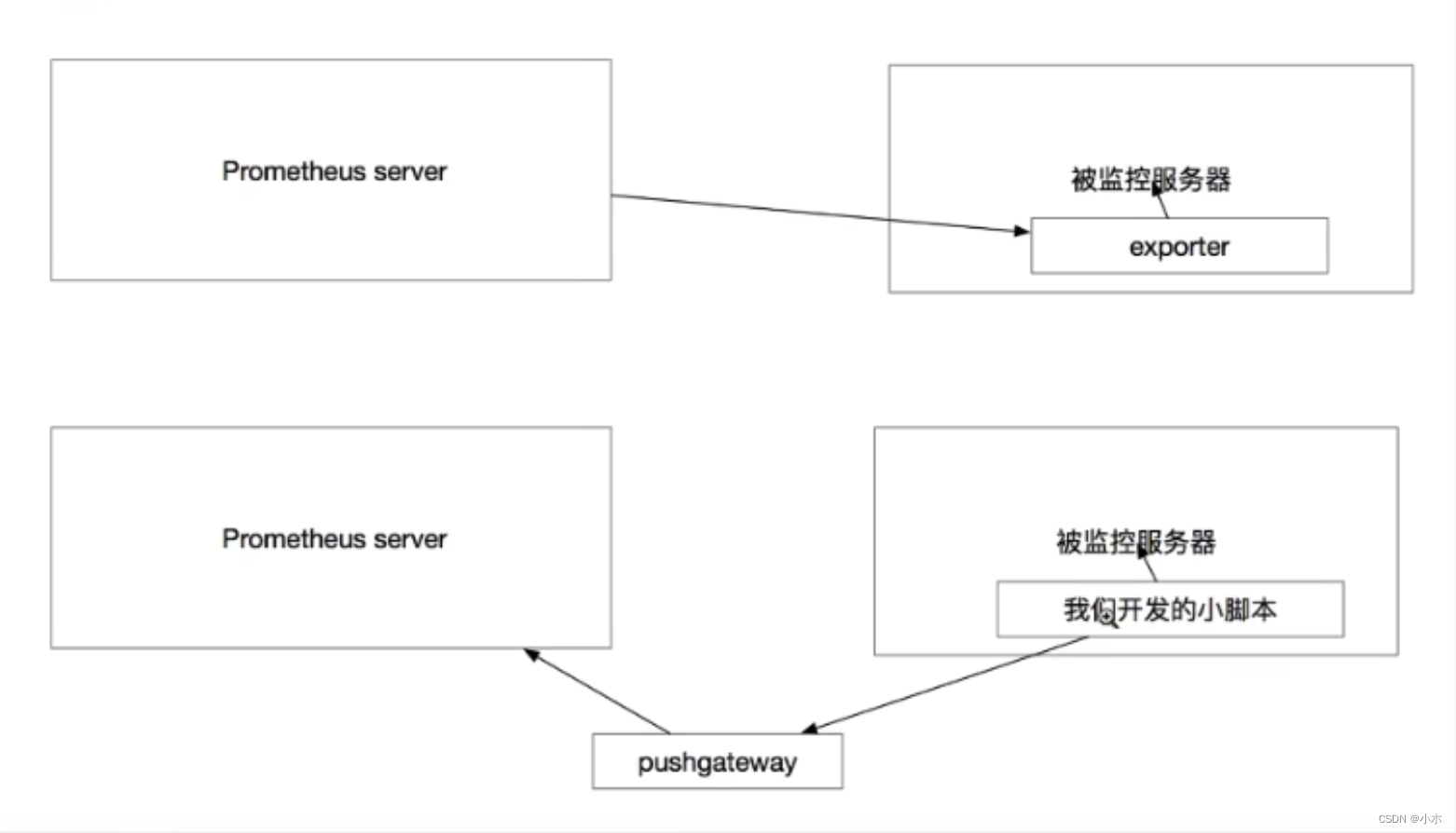
- push gateway 支持短期工作的推送网关。类似一个中转站,可以理解成目标主机可以上报短期任务的数据到Pushgateway,然后Prometheus server 统一从Pushgateway拉取数据。
- exporters 指标暴露器,负责收集不支持内建Instrumentation的应用程序或服务的性能指标数据,并通过HTTP接口供Prometheus Server获取。用于暴露已有的第三方服务的 metrics 给 Prometheus。
- alertmanager 是一个独立的告警模块,从Prometheus server端接收到“告警通知”后,会进行去重、分组,并路由到相应的接收方,发出报警。
- Service Discovery:服务发现,用于动态发现待监控的Target,Prometheus支持多种服务发现机制,例如文件、DNS、Consul、Kubernetes等等。
- Grafana:是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。其官方库中具有丰富的仪表盘插件。
- various support tools 各种支持工具
注:大多数普罗米修斯组件都是用Go语言编写的,它们很容易作为静态二进制文件构建和部署。
exporter与pushgateway两种监控方式对比:
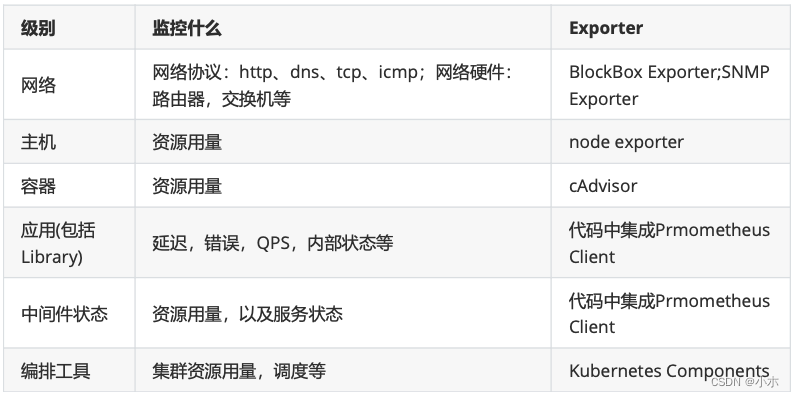
5、Prometheus各类设备常用的监控方法
6、Prometheus的数据模型
Prometheus 存储的是时序数据, 即按照相同时序(相同的名字和标签),以时间维度存储连续的数据的集合。
(1)介绍
Prometheus 中,每个时间序列都由指标名称(Metric Name)和标签(Label)来唯一标识格式为:{=,…}
指标名称:通常用于描述系统上要测定的某个特征
例如,prometheus_http_requests_total表示接收到的HTTP请求总数
标签:键值型数据,附加在指标名称之上,从而让指标能够支持多纬度特征;可选项
例如,如下代表着两个不同的时间序列
prometheus_http_requests_total{code=“200”}
prometheus_http_requests_total{code=“302”}
双下划线的标签是Prometheus系统默认标签,是不会显示在/metrics页面里面的;
系统默认标签在target页面中也是不显示的,需要鼠标放到Labels字段上才会显示。
常见的系统默认标签:
__address:当前target 实例的套接字地址:
__scheme:采集当前target 上指标数据时使用的协议(http或https)
__metrics_path:采集当前target 上的指标数据时使用URI路径,默认为/metrics
___param:传递的URL参数中第一个名称为的参数的值
__name:此标签是标识指标名称的预留标签,能够使用标签选择器对指标名称进行过滤
(2)时序样本
-
按照某个时序以时间维度采集的数据,称之为样本,其值包含:
-
一个 float64 值
-
一个毫秒级的 unix 时间戳

指标名称 标签 时间戳 值
(3)格式及命名要求
Prometheus 时序格式与 OpenTSDB 相似,其中包含时序指标名字以及时序的标签:
<metric name>{<label name>=<label value>, ...}例如,指标名称为 api_http_requests_total 和的时间序列标签为method="POST" 和 handler="/messages"
api_http_requests_total{method="POST", handler="/messages"}注:Prometheus监控指标名称和标签名称可以包含ASCII字母、数字、下划线和冒号。它必须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*
7、Metrics指标类型
(1)Counter
计数器,单调地表示单个的累积度量递增计数器,值只能在重启时增加或重置为零。从0开始不断累加计算,正常情况下是只能一直增长,不会降低。(例如累积访问量)
通常,Counter 的总数并没有直接作用,而是需要借助于 rate、topk、increase 和 irate 等函数来生成样本数据的变化状况(增长率)
rate(prometheus_http_requests_total[1h])
获取 1 小内,该指标下各时间序列上的 http 总请求数的增长速率
irate(prometheus_http_requests_total[1h])
irate 为高灵敏度函数,用于计算指标的瞬时速率,基于样本范围内的最后两个样本进行计算,相较于 rate 函数来说,irate 更适用于短期时间范围内的变化速率分析。
(2)Gauge
仪表盘,1个简单的返回值,可以上下浮动的“计数”,没有规律变化的值。(例如CPU使用率、队列数)
Gauge 用于存储其值可增可减的指标的样本数据,常用于进行求和、取平均值、最小值、最大值等聚合计算;也会经常结合 PromQL 的 delta 和 predict_linear 函数使用
delta(cpu_temp_celsius{host="node01"}[2h])
返回该服务器上的CPU温度与2小时之前的差异
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600)
基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况
(3)Histogram
直方图,将时间范围内的数据划分成不同的时间段,并各自评估其样本个数及样本值之和,因而可计算出分位数。( 可用于分析因异常值而引起的平均值过大的问题;分位数计算要使用专用的 histogram_quantile 函数;)
对于 Prometheus 来说,Histogram 会在一段时间范围内对数据进行采样(通常是请求持续时长或响应大小等),并将其计入可配置的 bucket(存储桶)中 ,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
Prometheus 取值间隔的划分采用的是累积区间间隔机制,即每个 bucket 中的样本均包含了其前面所有 bucket 中的样本,因而也称为累积直方图。
Histogram 类型的每个指标有一个基础指标名称 ,它会提供多个时间序列:
_sum :所有样本值的总和
_count :总的采样次数,它自身本质上是一个 Counter 类型的指标
_bucket{le=“<上边界>”} :观测桶的上边界,即样本统计区间,表示样本值小于等于上边界的所有样本数量
_bucket{le=“+Inf”} :最大区间(包含所有样本)的样本数量
1、例如,统计延迟在 0~10 ms 之间的请求数有多少,而 10~20 ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
http 请求响应时间 <= 0.005 秒 的请求次数为 10
prometheus_http_request_duration_seconds_bucket{handler="/metrics",le="0.005"} 10
http 请求响应时间 <= 0.01 秒 的请求次数为 15
prometheus_http_request_duration_seconds_bucket{handler="/metrics",le="0.01"} 15
http 请求响应时间 <= 0.025 秒 的请求次数为 18
prometheus_http_request_duration_seconds_bucket{handler="/metrics",le="0.025"} 18
prometheus_http_request_duration_seconds_bucket{handler="/metrics",le="0.05"} 18所有样本值的大小总和,命名为 _sum
prometheus_http_request_duration_seconds_sum{handler="/metrics"} 10.107670803000001
样本总数,命名为 _count ,效果与 _bucket{le=“+Inf”} 相同
prometheus_http_request_duration_seconds_count{handler="/metrics"} 20
2、注意:
bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布。注意后面的样本是包含前面的样本,假设
prometheus_http_request_duration_seconds_bucket{…,le=“0.01”} 的值为 10prometheus_http_request_duration_seconds_bucket{…,le=“0.05”} 的值为 30那么意味着这 30 个样本中,有 10 个是小于 0.01s 的,其余 20 个采样点的响应时间是介于 0.01s 和 0.05s 之间的。
3、累积间隔机制生成的样本数据需要额外使用内置的 histogram_quantile 函数即可根据 Histogram 指标来计算相应的分位数(quantile),即某个 bucket 的样本数在所有样本数中占据的比例。
●histogram_quantile 函数在计算分位数时会假定每个区间内的样本满足线性分布状态,因而它的结果仅是一个预估值,并不完全准确
●预估的准确度取决于bucket区间划分的粒度;粒度越大,准确度越低
例如,假设 http 请求响应时间的样本的 9 分位数(quantile=0.9)的上边界为 0.01,即表示小于等于 0.01 的样本值的数量占总体样本值的 90%
histogram_quantile(prometheus_http_request_duration_seconds_bucket{handler="/metrics",le="0.01"}) 0.9
(4)Summary
概略图,类似于 Histogram,但会在客户端直接计算并上报分位数;
Histogram 在客户端仅是简单的桶划分和分桶计数,分位数计算由 Prometheus Server 基于样本数据进行估算,因而其结果未必准确,甚至不合理的 bucket 划分会导致较大的误差。
Summary 是一种类似于 Histogram 的指标类型,但它在客户端于一段时间内(默认为 10 分钟)的每个采样点进行统计,计算并存储了分位数数值,Server 端直接抓取相应值即可。
对于每个指标,Summary 以指标名称 为前缀,生成如下几个指标序列:
- _sum :统计所有样本值之和
- _count :统计所有样本总数
- {quantile=“x”} :统计样本值的分位数分布情况,分位数范围:0 ≤ x ≤ 1
示例:
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Promtheus Server进行 wal_fsync 操作的总次数为 216 次,耗时 2.888716127000002s。 其中中位数(quantile=0.5)的耗时为 0.012352463s,9分位数(quantile=0.9)的耗时为0.014458005s。
Histogram 与 Summary 的异同:
它们都包含了 _sum 和 _count 指标,Histogram 需要通过 _bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
二、Prometheus配置
1、Prometheus安装
#解压上传后的软件包
[root@localhost opt]# tar xf prometheus-2.35.0.linux-amd64.tar.gz
#移动并命名
[root@localhost opt]# mv prometheus-2.35.0.linux-amd64 /usr/local/prometheus
[root@localhost opt]# cd /usr/local/prometheus
[root@localhost prometheus]# ls
console_libraries consoles LICENSE NOTICE prometheus prometheus.yml promtool
2、编写服务启动文件
vi /usr/lib/systemd/system/prometheus.service[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/prometheus/prometheus \
--web.listen-address=localhost:9090 \
--storage.tsdb.path="/mnt/data/prometheus" \
--storage.tsdb.retention.time=15d \
--config.file=/usr/local/prometheus/rometheus.yml \
--web.enable-lifecycle
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
3、服务启动参数介绍
--config.file=/usr/local/prometheus/prometheus.yml #指定配置文件
--storage.tsdb.path=/usr/local/prometheus/data/ #数据存储目录
--storage.tsdb.retention.time=15d #数据保存时间,支持:y, w, d, h, m, s, ms
--web.enable-lifecycle #开启配置文件热加载
--log.level=info #日志级别,支持debug, info, warn, error
4、Pormetheus配置文件介绍
(1)global 全局配置
#全局配置 (如果有内部单独设定,会覆盖这个参数)
//scrape_interval
//全局默认的数据拉取间隔
[ scrape_interval: <duration> | default = 1m ]
//scrape_timeout
//全局默认的单次数据拉取超时,当报context deadline exceeded错误时需要在特定的job下配置该字段。
[ scrape_timeout: <duration> | default = 10s ]
//evaluation_interval
//全局默认的规则(主要是报警规则)拉取间隔
[ evaluation_interval: <duration> | default = 1m ]
//external_labels
//该服务端在与其他系统对接所携带的标签
[ <labelname>: <labelvalue> ... ]
(2)alerting 告警插件定义
#告警插件定义。与Alertmanager进行对接的配置。
alerting:
alert_relabel_configs: # 动态修改 alert 属性的规则配置。
- source_labels: [dc]
regex: (.+)\d+
target_label: dc1
alertmanagers:
- static_configs:
- targets: ['127.0.0.1:9093'] # 单实例配置
#- targets: ['172.31.10.167:19093','172.31.10.167:29093','172.31.10.167:39093'] # 集群配置
- job_name: 'Alertmanager'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
- static_configs:
- targets: ['localhost:19093']
(3)rule_files 规则文件(告警规则)
#这个主要是用来设置告警规则,基于设定什么指标进行报警(类似触发器trigger)。这里设定好规则以后,prometheus会根据全局global设定的evaluation_interval参数进行扫描加载,规则改动后会自动加载。其报警媒介和route路由由alertmanager插件实现。
- 通过 rule_files指定一组告警规则文件的访问路径
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "first_rules.yml"
- "/opt/second_rules.yml"- first_rules.yml示例:
groups: # 告警组 对一组相关的告警进行统一定义,下面可定义多个告警规则
- name: test-rules
rules:
- alert: InstanceDown # 告警规则的名称
expr: up{job="myjob"} == 0 # 告警的判定条件,参考PromQL高级查询来设定
for: 10s # 满足告警条件持续时间多久后,才会发送告警
labels: #标签项
severity: error
annotations: # 解析项,详细解释告警信息;在告警产生时会一同作为参数发送到alertmanager
summary: "{{$labels.instance}}: has been down,is {{$value}}" #摘要
description: "{{$labels.instance}}: job {{$labels.job}} has been down " #描述(4)scrape_configs 监控采集配置
#采集配置。配置数据源,包含分组job_name以及具体target。又分为静态配置和服务发现。
- job_name: "192.168.111.1"
static_configs:
- targets: ["192.168.111.1:8082"]
labels:
group: '监控测试'文件服务发现:
- job_name: "IPPing"
scrape_interval: 60s
scrape_timeout: 20s
metrics_path: /probe
params:
module: [icmp]
file_sd_configs:
- files:
- /usr/local/prometheus/prometheus/ip.yamlvi ip.yaml
- targets:
- 10.0.x.x
- 10.0.x.x
labels:
group: 'ping监控'注:job_name 定义job名称,是一个拉取单元。每个job_name都会自动引入默认配置如:
scrape_interval 依赖全局配置
scrape_timeout 依赖全局配置
metrics_path 默认为’/metrics’
scheme 默认为’http’,切换抓取数据所用的协议
# 这些也可以在单独的job中自定义
(5)remote_write
#用于Prometheus远程存储写配置
url: <string>
[ remote_timeout: <duration> | default = 30s ]
#写入数据时候进行标签过滤
write_relabel_configs:
[ - <relabel_config> ... ]
basic_auth:
[ username: <string> ]
[ password: <string> ]
[ password_file: <string> ]
[ bearer_token: <string> ]
[ bearer_token_file: /path/to/bearer/token/file ]
tls_config:
[ <tls_config> ]
[ proxy_url: <string> ]
#远端写细粒度配置,这里暂时仅仅列出官方注释
queue_config:
# Number of samples to buffer per shard before we start dropping them.
[ capacity: <int> | default = 10000 ]
# Maximum number of shards, i.e. amount of concurrency.
[ max_shards: <int> | default = 1000 ]
# Maximum number of samples per send.
[ max_samples_per_send: <int> | default = 100]
# Maximum time a sample will wait in buffer.
[ batch_send_deadline: <duration> | default = 5s ]
# Maximum number of times to retry a batch on recoverable errors.
[ max_retries: <int> | default = 3 ]
# Initial retry delay. Gets doubled for every retry.
[ min_backoff: <duration> | default = 30ms ]
# Maximum retry delay.
[ max_backoff: <duration> | default = 100ms ]
(6)remote_read:
#用于Prometheus远程读配置
#远程读取的url
url: <string>
#通过标签来过滤读取的数据
required_matchers:
[ <labelname>: <labelvalue> ... ]
[ remote_timeout: <duration> | default = 1m ]
#当远端不是存储的时候激活该项
[ read_recent: <boolean> | default = false ]
basic_auth:
[ username: <string> ]
[ password: <string> ]
[ password_file: <string> ]
[ bearer_token: <string> ]
[ bearer_token_file: /path/to/bearer/token/file ]
tls_config:
[ <tls_config> ]
[ proxy_url: <string> ]
三、Prometheus的服务发现配置
参考官网:Configuration | Prometheus
1、基于文件的服务发现
基于文件的服务发现是仅仅略优于静态配置的服务发现方式,它不依赖于任何平台或第三方服务,因而也是最为简单和通用的实现方式。Prometheus Server 会定期从文件中加载 Target 信息,文件可使用 YAML 和 JSON 格式,它含有定义的 Target 列表,以及可选的标签信息。
创建用于服务发现的文件,在文件中配置所需的 target:
1、
cd /usr/local/prometheus
mkdir targets
vim targets/node-exporter.yaml
- targets:
- 192.168.109.131:9100
- 192.168.109.132:9100
- 192.168.109.133:9100
labels:
app: node-exporter
job: node
2、#修改 prometheus 配置文件,发现 target 的配置,定义在配置文件的 job 之中
vim /usr/local/prometheus/prometheus.yml
......
scrape_configs:
- job_name: nodes
file_sd_configs: #指定使用文件服务发现
- files: #指定要加载的文件列表
- targets/node*.yaml #文件加载支持通配符
refresh_interval: 2m #每隔 2 分钟重新加载一次文件中定义的 Targets,默认为 5m
systemctl reload prometheus
3、浏览器查看 Prometheus 页面的 Status -> Targets
2、基于Consul的服务发现
Consul 是一款基于 golang 开发的开源工具,主要面向分布式,服务化的系统提供服务注册、服务发现和配置管理的功能。提供服务注册/发现、健康检查、Key/Value存储、多数据中心和分布式一致性保证等功能。
(1)部署consul服务
cd /opt/
unzip consul_1.9.2_linux_amd64.zip
mv consul /usr/local/bin/
#创建 Consul 服务的数据目录和配置目录
mkdir /var/lib/consul-data
mkdir /etc/consul/
#使用 server 模式启动 Consul 服务
consul agent \
-server \
-bootstrap \
-ui \
-data-dir=/var/lib/consul-data \
-config-dir=/etc/consul/ \
-bind=192.168.109.138 \
-client=0.0.0.0 \
-node=consul-server01 &> /var/log/consul.log &
#查看 consul 集群成员
consul members
(2)在consul上注册services
#在配置目录中添加文件
vim /etc/consul/nodes.json
{
"services": [
{
"id": "node_exporter-node01",
"name": "node01",
"address": "192.168.109.138",
"port": 9100,
"tags": ["nodes"],
"checks": [{
"http": "http://192.168.109.138:9100/metrics",
"interval": "5s"
}]
},
{
"id": "node_exporter-node02",
"name": "node02",
"address": "192.168.109.134",
"port": 9100,
"tags": ["nodes"],
"checks": [{
"http": "http://192.168.109.134:9100/metrics",
"interval": "5s"
}]
}
]
}
#让 consul 重新加载配置信息
consul reload
浏览器访问:http://192.168.109.138:8500(3)修改prometheus配置文件
vim /usr/local/prometheus/prometheus.yml
......
- job_name: nodes
consul_sd_configs: #指定使用 consul 服务发现
- server: 192.168.109.138:8500 #指定 consul 服务的端点列表
tags: #指定 consul 服务发现的 services 中哪些 service 能够加入到 prometheus 监控的标签
- nodes
refresh_interval: 2m
systemctl reload prometheus
浏览器查看 Prometheus 页面的 Status -> Targets
#让 consul 注销 Service
consul services deregister -id="node_exporter-node02"
#重新注册
consul services register /etc/consul/nodes.json
四、部署exporter监控
1、下载安装包解压安装
cd /opt/
tar xf node_exporter-1.3.1.linux-amd64.tar.gz
mv node_exporter-1.3.1.linux-amd64/node_exporter /usr/local/bin2、配置启动文件并启动exporter服务
cat > /usr/lib/systemd/system/node_exporter.service <<'EOF'
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/node_exporter \
--collector.ntp \
--collector.mountstats \
--collector.systemd \
--collector.tcpstat
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
3、修改Prometheus配置文件
vim /usr/local/prometheus/prometheus.yml
#在尾部增加如下内容
- job_name: nodes
metrics_path: "/metrics"
static_configs:
- targets:
- 192.168.109.138:9100
- 192.168.109.137:9100
- 192.168.109.136:9100
labels:
service: kubernetes
4、重新加载Prometheus服务
curl -X POST http://192.168.109.138:9090/-/reload #热加载
或systemctl reload prometheus
浏览器查看 Prometheus 页面的 Status -> Targets
五、部署pushgateway监控
1、下载安装包解压安装
pushgateway可以在任何服务器上部署
cd /usr/local
wget https://github.com/prometheus/pushgateway/releases/download/v1.4.3/pushgateway-1.4.3.linux-amd64.tar.gz
tar -xf pushgateway-1.4.3.linux-amd64.tar.gz
2、编写启动文件
[Unit]
Description=Prometheus pushgateway
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/pushgateway/pushgateway --persistence.file="/usr/local/pushgateway/data/" --persistence.interval=5m #保存时间5分钟
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
RestartSec=5s
[Install]
WantedBy=multi-user.target
3、启动服务
默认端口为9091,可通过–web.listen-address更改监听端口
4、prometheus添加配置
vim /usr/local/prometheus/prometheus.yml
- job_name: 'pushgateway'
scrape_interval: 30s
honor_labels: true #加上此配置,exporter节点上传数据中的一些标签将不会被pushgateway节点的相同标签覆盖
static_configs:
- targets: ['192.168.1.1:9091']
labels:
instance: pushgateway
5、pushgateway数据推送
(1)pushgateway自定义监控项脚本
pushgateway本身没有任何抓取监控数据的功能,它只能被动地等待数据被推送过来,故需要用户自行编写数据采集脚本。
例:采集TCP waiting_connection瞬时数量
1、编写脚本
vi tcp_waiting_connection.sh
#!/bin/bash
# 获取机器名称变量,用于后面的标签
instance_name=`hostname -f | cut -d '.' -f 1`
# 机器名称不为localhost,否则标签无法区分
if [ $instance_name = "localhost" ];then
echo "Must FQDN hostname"
exit 1
fi
# For waiting connections
label="count_netstat_wait_connetions" # 定义一个key
count_netstat_wait_connetions=`netstat -an | grep -i wait | wc -l` # 取得数值
echo "$label:$count_netstat_wait_connetions"
echo "$label $count_netstat_wait_connetions" | curl --data-binary @- http://192.168.1.1:9091/metrics/job/pushgateway/instance/$instance_name注:
1)netstat -an | grep -i wait | wc -l该自定义监控的取值方法
2)实际上就是将“K V”键值对通过POST方式推送给pushgateway,格式如下:
- http://192.168.1.1:9091/metrics # pushgateway url地址
- job/pushgateway # 数据推送过去的label,即 job=“pushgateway”,也可用其他job名称
- instance/$instance_name #数据推送过去的label,即 instance=“hsotname”,显示的机器名
3)删除pushgateway组下的某个实例的所有数据
curl -X DELETE http://192.168.1.1:9091/metrics/job/pushgateway/instance/$instance_name4)删除pushgateway组下的所有数据
curl -X DELETE http://192.168.1.1:9091/metrics/job/pushgateway2、定时执行脚本
crontab -e
* * * * * /app/scripts/pushgateway/tcp_waiting_connection.sh >/dev/null 2>&13、Prometheus查看监控数据
promethues可查询监控值count_netstat_wait_connetions
注:prometheus默认每15秒从pushgateway获取一次数据,而cron定时任务最小精度是每分钟执行一次。此时可通过以下方法解决。
方法1:sleep:定义多条定时任务
* * * * * /app/scripts/pushgateway/tcp_waiting_connection.sh >/dev/null 2>&1
* * * * * sleep 15; /app/scripts/pushgateway/tcp_waiting_connection.sh >/dev/null 2>&1
* * * * * sleep 30; /app/scripts/pushgateway/tcp_waiting_connection.sh >/dev/null 2>&1
* * * * * sleep 45; /app/scripts/pushgateway/tcp_waiting_connection.sh >/dev/null 2>&1
方法2:for循环
#!/bin/bash
time=15
for (( i=0; i<60; i=i+time )); do
instance_name=`hostname -f | cut -d '.' -f 1`
if [ $instance_name = "localhost" ];then
echo "Must FQDN hostname"
exit 1
fi
label="count_netstat_wait_connetions"
count_netstat_wait_connetions=`netstat -an | grep -i wait | wc -l`
echo "$label:$count_netstat_wait_connetions"
echo "$label $count_netstat_wait_connetions" | curl --data-binary @- http://localhost:9091/metrics/job/pushgateway/instance/$instance_name
sleep $time
done
exit 0此时cron定时任务只需要定义一条:
crontab -e
* * * * * /app/scripts/pushgateway/tcp_waiting_connection.sh >/dev/null 2>&1(2)Client SDK推送
Prometheus本身提供了支持多种语言的SDK,可通过SDK的方式,生成相关的数据,并推送到pushgateway,这也是官方推荐的方案,详情可参见此链接:https://prometheus.io/docs/instrumenting/clientlibs/。
本示例以python为例,讲解SDK的使用:
pip install prometheus_clientfrom prometheus_client import Counter,Gauge,push_to_gateway
from prometheus_client.core import CollectorRegistry
registry = CollectorRegistry()
data1 = Gauge('gauge_test_metric','This is a gauge-test-metric',['method','path','instance'],registry=registry)
data1.labels(method='get',path='/aaa',instance='instance1').inc(3)
push_to_gateway('10.12.61.3:9091', job='alex-job',registry=registry)
#注解:
#第1、2行代码:引入相关的Prometheus SDK;
#第5行代码:创建相关的指标,类型为Gauge。其中“gauge_test_metric”为指标名称,'This is a gauge-test-metric’为指标注释,[‘method’,‘path’,‘instance’] 为指标相关的label。
#第6行代码:添加相关的label信息和指标value 值。
#第8行代码:push数据到pushgateway,'10.12.61.3:9091’为发送地址,job指定该任务名称。六、PromQL介绍
- PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,内置函数很多,在日常数据可视化以及rule 告警中都会使用到它。
- 在查询语句中,字符串往往作为查询条件labels(标签)的值,和Golang 字符串语法一致,可以使用 “”, ‘’, 或者 `` 也可以使用正数或浮点数。
1、PromQL的数据类型(查询结果类型)
PromQL 查询结果主要有 3 种类型:
- 瞬时数据 (Instant vector): 包含一组时序,每个时序只有一个点,例如:
http_requests_total
http_requests_total{job="prometheus"}- 区间数据 (Range vector): 包含一组时序,每个时序有多个点,例如:
http_requests_total[5m]- 纯量数据 (Scalar): 纯量只有一个数字,没有时序,例如:
count(http_requests_total)- 注:向量表达式使用要点
表达式的返回值类型亦是即时向量、范围向量、标题或字符串4种数据类型其中之一,但是,有些使用场景要求表达式返回值必须满足特定的条件,例如:
1、需要将返回值绘制成图形时,仅支持瞬时向量类型的数据;
2、对于诸如 rate、irate 之类的速率函数来说,其要求使用的却又必须是区间向量型的数据
3、由于区间向量选择器的返回的是区间向量型数据,它不能用于表达式浏览器中图形绘制功能
4、区间向量选择器通常会结合速率类的函数 rate、irate 一同使用
2、PromQL查询语句操作符
Prometheus 查询语句中,支持常见的各种表达式操作符。例如:
(1)算术运算符:
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / | 除法 |
| % | 取余 |
| ^ | 取幂 |
(2)比较运算符:
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
(3)逻辑运算符:
and,or,unless(排除)
(4)聚合运算符:
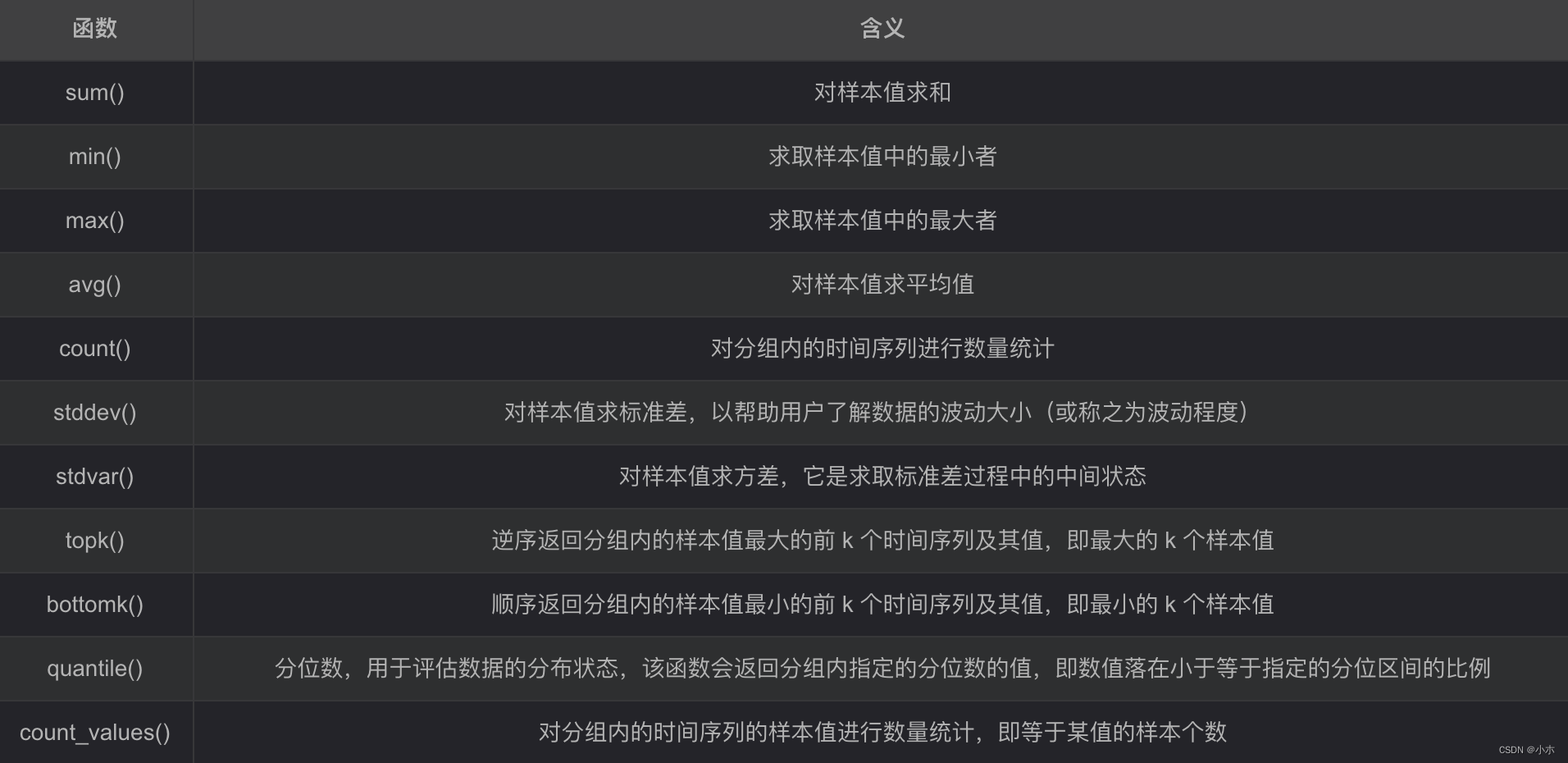
注意,和四则运算类型,Prometheus 的运算符也有优先级,它们遵从(^)> (*, /, %) > (+, -) > (==, !=, <=, <, >=, >) > (and, unless) > (or) 的原则。
(5)Label标签匹配操作符

3、PromQL的聚合表达式案例
PromQL 中的聚合操作语法格式可采用如下面两种格式之一:
- <聚合函数>([参数,] 向量表达式) by|without (标签名称列表)
- <聚合函数> by|without (标签名称列表) ([参数,] 向量表达式)
注:其中只有 count_values. , quantile , topk , bottomk 支持参数
分组聚合:先分组、后聚合
without用于从计算结果中移除列举的标签,而保留其它标签。by则正好相反,结果向量中只保留列出的标签,其余标签则移除。通过without和by可以按照样本的问题对数据进行聚合.
1、例如:
sum(http_requests_total) without (instance)等价于
sum(http_requests_total) by (code,handler,job,method)2、如果只需要计算整个应用的HTTP请求总量,可以直接使用表达式:
sum(http_requests_total)3、count_values用于时间序列中每一个样本值出现的次数。count_values会为每一个唯一的样本值输出 一个时间序列,并且每一个时间序列包含一个额外的标签。
count_values("count",http_request_total)4、topk和bottomk则用于对样本值进行排序,返回当前样本值前n位,或者后n位的时间序列。 获取HTTP请求数前5位的时序样本数据,
topk(5, http_requests_total)
5、quantile用于计算当前样本数据值的分布情况quantile(φ, express)其中0 ≤ φ ≤ 1。 例如,当φ为0.5时,即表示找到当前样本数据中的中位数
quantile(0.5, http_requests_total)案例:
(1)每台主机 CPU 在最近 5 分钟内的平均使用率
(1-avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)) )* 100
(2)查询 1 分钟的 load average 的时间序列是否超过主机 CPU 数量 2 倍
node_load1 > on (instance) 2 * count (node_cpu_seconds_total{mode="idle"}) by (instance)
(3)计算主机内存使用率,可用内存空间:空闲内存、buffer、cache 指标之和
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100(4)计算K8S所有 node 节点所有容器总计内存:
sum by (instance) (container_memory_usage_bytes{instance=~"node*"})/1024/1024/1024
(5)计算最近 1m 所有容器 cpu 使用率
sum by (id) (rate(container_cpu_usage_seconds_total{id!="/"}[1m]))
4、Prometheus内置函数介绍
Prometheus 内置不少函数,方便查询以及数据格式化,详情参考内置函数
参考官网:Query functions | Prometheus


5、Prometheus API使用PromQL
Prometheus当前稳定的HTTP API可以通过/api/v1访问。
(1)API响应格式
Prometheus API使用了JSON格式的响应内容。 当API调用成功后将会返回2xx的HTTP状态码。 反之,当API调用失败时可能返回以下几种不同的HTTP状态码:
- 404 Bad Request:当参数错误或者缺失时。
- 422 Unprocessable Entity 当表达式无法执行时。
- 503 Service Unavailiable 当请求超时或者被中断时。
所有的API请求均使用以下的JSON格式:
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>"
}(2)在HTTP API中使用PromQL
通过HTTP API我们可以分别通过 /api/v1/query 和 /api/v1/query_range 查询PromQL表达式当前或者 一定时间范围内的计算结果。
1、瞬时数据查询
通过使用query API我们可以查询PromQL在特定时间点下的计算结果。
GET /api/v1/query
URL请求参数:
- query=:PromQL表达式。
- time=:用于指定用于计算PromQL的时间戳。可选参数,默认情况下使用当前系统时间。
- timeout=:超时设置。可选参数,默认情况下使用-query,timeout的全局设置。
例如使用以下表达式查询表达式up在时间点2015-07-01T20:10:51.781Z的计算结果:
请求体:
$ curl 'http://localhost:9090/api/v1/query?query=up&time=2015-07-
01T20:10:51.781Z'返回数据:
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"value": [ 1435781451.781, "1" ]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
},
"value" : [ 1435781451.781, "0" ]
}
] }
}响应数据类型
当API调用成功后,Prometheus会返回JSON格式的响应内容,格式如上小节所示。并且在data节点 中返回查询结果。data节点格式如下:
{
"resultType": "matrix" | "vector" | "scalar" | "string", # 数据类型 "result": <value> }
2、区间数据查询
通过使用query_range API我们可以查询PromQL在一段时间内下的计算结果。
GET /api/v1/query_range
URL请求参数:
- query=: PromQL表达式。
- start=: 起始时间。
- end=: 结束时间。
- step=: 查询步长。
- timeout=: 超时设置。可选参数,默认情况下使用-query,timeout的全局设置。
当使用QUERY_RANGE API查询PromQL表达式时,返回结果一定是一个区间向量。
需要注意的是,在QUERY_RANGE API中PromQL只能使用瞬时向量选择器类型的表达式
例如使用以下表达式查询表达式up在30秒范围内以15秒为间隔计算PromQL表达式的结果。
请求体:
$ curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-
01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'返回数据:
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
] },
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
] }
] }
}6、使用Recoding Rules优化PromQL查询性能
通过PromQL可以实时对Prometheus中采集到的样本数据进行查询,聚合以及其它各种运算操作。而 在某些PromQL较为复杂且计算量较大时,直接使用PromQL可能会导致Prometheus响应超时的情况。 这时需要一种能够类似于后台批处理的机制能够在后台完成这些复杂运算的计算,对于使用者而言只需 要查询这些运算结果即可。Prometheus通过Recoding Rule规则,支持这种后台计算的方式,可以实现对复杂查询的性能优化,提高查询效率。
定义Recoding rules
在Prometheus配置文件中,通过rule_files定义recoding rule规则文件的访问路径
rule_files:
[ - <filepath_glob> ... ]
一个简单的规则文件可能是这个样子的,一个group下可以包含多条规则rule。
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum # 定义指标名称
expr: sum(http_inprogress_requests) by (job) # 定义PromQL计算表达式,在当前时间计算
labels: # 添加标签
[job: test]根据规则中的定义,Prometheus会在后台完成expr中定义的PromQL表达式计算,并且将计算结果 保存到新的时间序列record中。还可以通过labels为这些样本添加标签。
这些规则文件的计算频率与告警规则计算频率一致,都通过global.evaluation_interval定义。
七、AlertManager 告警配置
1、Prometheus告警简介
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义 AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向 Alertmanager发送告警信息。
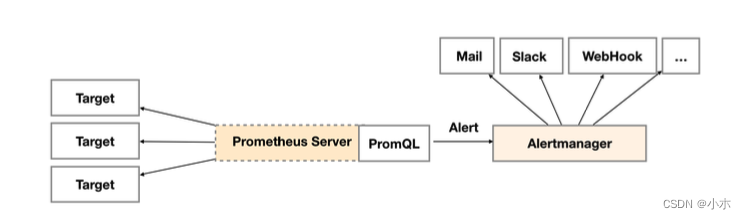
Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户 端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如当接收到大量重复告 警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方,Prometheus内置 了对邮件,Slack等多种通知方式的支持,同时还支持与Webhook的集成,以支持更多定制化的场景。 例如,目前Alertmanager还不支持钉钉,那用户完全可以通过Webhook与钉钉机器人进行集成,从而 通过钉钉接收告警信息。同时AlertManager还提供了静默和告警抑制机制来对告警通知行为进行优化。
2、AlertManager特性
Alertmanager除了提供基本的告警通知能力以外,还主要提供了如:分组、抑制以及静默等告警特性。
- 根据标签对大量告警进行高效处理,提取对用户最为关键的信息。
- 根据时间生成通知组,避免重复通知引起“告警疲劳”。
- 灵活的路由规则,将不同类别的告警发送到合适的接收器。
- 集群部署,每个实例都处理完全相同的告警,无单点故障。
- 支持丰富的 API 与 webhook 集成,灵活扩展接收器方式。
(1)分组
- 分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
- 例如,当集群中有数百个正在运行的服务实例,并且为每一个实例设置了告警规则。假如此时发生了 网络故障,可能导致大量的服务实例无法连接到数据库,结果就会有数百个告警被发送到 Alertmanager。
- 而作为用户,可能只希望能够在一个通知中中就能查看哪些服务实例收到影响。这时可以按照服务所在集群或者告警名称对告警进行分组,将这些告警内聚在一起成为一个通知。
- 告警分组、告警时间、以及告警接收方式可通过AlertManager的配置文件进行配置。
(2)抑制
- 抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
- 例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有 告警。这样可以避免接收到大量与实际问题无关的告警通知。
- 抑制机制同样通过Alertmanager的配置文件进行设置。
(3)静默
- 静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配 置,Alertmanager则不会发送告警通知。
- 静默设置需要在Alertmanager的Werb页面上进行设置。
3、定义Prometheus告警规则
Prometheus中的告警规则允许你基于PromQL表达式定义告警触发条件,Prometheus后端对这些触 发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过 Prometheus的Web界面查看这些告警规则以及告警的触发状态。当Promthues与Alertmanager关联之 后,可以将告警发送到外部服务如Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。
(1)定义告警规则
(Prometheus.yml中的“rule_files”)
默认情况下Prometheus会每分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期, 则可以通过 evaluation_interval 来覆盖默认的计算周期:
groups: # 告警组 对一组相关的告警进行统一定义,下面可定义多个告警规则
- name: test-rules
rules:
- alert: InstanceDown # 告警规则的名称
expr: up{job="myjob"} == 0 # 告警的判定条件,参考PromQL高级查询来设定
for: 10s # 满足告警条件持续时间多久后,才会发送告警
labels: #标签项
severity: error
annotations: # 解析项,详细解释告警信息;在告警产生时会一同作为参数发送到alertmanager
summary: "{{$labels.instance}}: has been down,is {{$value}}" #摘要
description: "{{$labels.instance}}: job {{$labels.job}} has been down " #描述(2)模板化
一般来说,在告警规则文件的annotations中使用summary描述告警的概要信息, description用于描述告警的详细信息。同时Alertmanager的UI也会根据这两个标签值,显示告警信息。为了让告警信息 具有更好的可读性,Prometheus支持模板化label和annotations的中标签的值。
通过变量 $labels.<labelname> 可以访问当前告警实例中指定标签的值。$value则可以获取当前 PromQL表达式计算的样本值。
# To insert a firing element's label values:
{{ $labels.<labelname> }} # To insert the numeric expression value of the firing element: {{ $value }}
例如,可以通过模板化优化summary以及description的内容的可读性:
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down
for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s
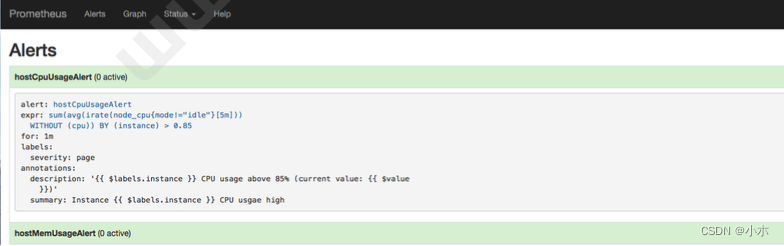
(current value: {{ $value }}s)"(3)查看告警状态
如下所示,用户可以通过Prometheus WEB界面中的Alerts菜单查看当前Prometheus下的所有告警规 则,以及其当前所处的活动状态。
同时对于已经pending或者firing的告警,Prometheus也会将它们存储到时间序列ALERTS{}中。
可以通过表达式,查询告警实例:
ALERTS{alertname="<alert name>", alertstate="pending|firing", <additional alert labels>}注:样本值为1表示当前告警处于活动状态(“pending”还未发送到AlertManager 或者 “firing”已经发送到AlertManager),当告警从活动状态转换为非活动状态时,样本值则为0。
4、配置AlertManager告警
(1)获取安装包,解压安装
export VERSION=0.15.2
curl -LO https://github.com/prometheus/alertmanager/releases/download/v$VERSION/alertmanager-$VERSION.darwin-amd64.tar.gz
tar xvf alertmanager-$VERSION.darwin-amd64.tar.gz(2)编辑AlertManager配置文件
例如配置QQ邮箱告警,vi alertmanager.yml
global:
resolve_timeout: 5m
smtp_from: "2379811111@qq.com"
smtp_smarthost: "smtp.qq.com:25"
smtp_auth_username: "2379811111@qq.com"
smtp_auth_password: "vasdsajfjSFsda"
smtp_requer_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 5m
receiver: 'email' # 与receiver保持一致
receivers:
- name: 'email' # 与route保持一致
email_configs:
- to: '2379811111@qq.com'
send_resolved: true #告警恢复后,发送恢复通知
headers:
subject: "邮件标题"
from: "发送人"
to: "接收人"
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']Alertmanager的配置主要包含两个部分:路由(route)以及接收器(receivers)。所有的告警信息都会从 配置中的顶级路由(route)进入路由树,根据路由规则将告警信息发送给相应的接收器。
在Alertmanager中可以定义一组接收器,比如可以按照角色(比如系统运维,数据库管理员)来划分多 个接收器。接收器可以关联邮件,Slack以及其它方式接收告警信息。
当前配置文件中定义了一个默认的接收者default-receiver由于这里没有设置接收方式,目前只相当于 一个占位符。
在配置文件中使用route定义了顶级的路由,路由是一个基于标签匹配规则的树状结构。所有的告警信 息从顶级路由开始,根据标签匹配规则进入到不同的子路由,并且根据子路由设置的接收器发送告警。 目前配置文件中只设置了一个顶级路由route并且定义的接收器为default-receiver。因此,所有的告警都会发送给default-receiver
(3)启动AlertManager
/etc/systemd/system/alertmanager.service
[Unit]
Description=Prometheus AlertManager
After=network.target
[Service]
Restart=on-failure
ExecStart=/usr/bin/alertmanager --config.file=/apps/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target
systemctl start alertmanager1、Alermanager会将数据保存到本地中,默认的存储路径为 data/ 。因此,在启动Alertmanager之前需要创建相应的目录
2、用户也在启动Alertmanager时使用参数修改相关配置。 用于指定alertmanager配置文件路径, 用于指定数据存储路径
3、Alertmanager启动后可以通过9093端口访问
4、Alertmanager页面 Alert菜单可以查看Alertmanager接收到的告警内容;Silences菜单下可以通过UI创建静默规则;进入Status菜单,可以看到当前系统的运行状态以及配置信息。
--web.route-prefix=/alertmanager # 指定基础路径,默认无,加上后访问web UI则为 ip:9093/alertmanager
--config.file=/etc/alertmanager/alertmanager.yml # 指定配置文件
--storage.path=/alertmanager/data/ # 指定存储文件路径
--data.retention=120h # 数据保留时间
--web.listen-address=:9093 # 指定端口
--web.external-url=https://xxx.com/alertmanager/ # 外部访问目录
--web.enable-lifecycle # 设置热加载 开启后可通过“/-/reload”接口加载配置
--web.enable-admin-api # 开启管理接口(不常用)
--cluster.listen-address="0.0.0.0:9094" # 监听集群地址。设置为空字符串表示关闭HA模式(4)关联Prometheus与AlertManager
编辑Prometheus配置文件prometheus.yml,并添加以下内容
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093','alertmanager2:9093'] # 可设置多个节点高可用重启Prometheus服务,成功后,可以从http://localhost:9090/config查看alerting配置是否生效。
5、注:AlertManager配置介绍
(1)配置文件概述
在上面的部分中已经简单介绍过,在Alertmanager中通过路由(Route)来定义告警的处理方式。路由 是一个基于标签匹配的树状匹配结构。根据接收到告警的标签匹配相应的处理方式。这里将详细介绍路 由相关的内容。
Alertmanager主要负责对Prometheus产生的告警进行统一处理,因此在Alertmanager配置中一般会 包含以下几个主要部分:
- 全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
- 模板(templates):用于定义告警通知时的模板,如HTML模板,邮件模板等;
- 告警路由(route):根据标签匹配,确定当前告警应该如何处理;
- 接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者 Webhook等,接收人一般配合告警路由使用;
- 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生
在全局配置中需要注意的是 resolve_timeout ,该参数定义了当Alertmanager持续多长时间未接收 到告警后标记告警状态为resolved(已解决)。该参数的定义可能会影响到告警恢复通知的接收时间,可根据自己的实际场景进行定义,其默认值为5分钟。
其完整配置格式如下:
# 全局配置
global:
[ smtp_from: <tmpl_string> ] #默认的SMTP From报头字段。
[ smtp_smarthost: <string> ] #用于发送邮件的默认SMTP智能主机,包括端口号。端口号一般是25,或587的SMTP over TLS(有时称为STARTTLS)。示例:smtp.example.org:587
[ smtp_hello: <string> | default = "localhost" ] #SMTP服务器的默认主机名。
[ smtp_auth_username: <string> ] # SMTP认证使用CRAMM-MD5, LOGIN和PLAIN。如果为空,则Alertmanager不向SMTP服务器进行身份验证。
[ smtp_auth_password: <secret> ] # SMTP认证使用LOGIN和PLAIN。
[ smtp_auth_password_file: <string> ] # SMTP认证使用LOGIN和PLAIN。
[ smtp_auth_identity: <string> ] # SMTP认证使用PLAIN。
[ smtp_auth_secret: <secret> ] # SMTP认证使用CRAM-MD5
[ smtp_require_tls: <bool> | default = true ] #默认的SMTP TLS要求。注意Go不支持未加密的远程SMTP端点连接。
# 用于Slack通知的API URL。
[ slack_api_url: <secret> ]
[ slack_api_url_file: <filepath> ]
[ victorops_api_key: <secret> ]
[ victorops_api_key_file: <filepath> ]
[ victorops_api_url: <string> | default = "https://alert.victorops.com/integrations/generic/20131114/alert/" ]
[ pagerduty_url: <string> | default = "https://events.pagerduty.com/v2/enqueue" ]
[ opsgenie_api_key: <secret> ]
[ opsgenie_api_key_file: <filepath> ]
[ opsgenie_api_url: <string> | default = "https://api.opsgenie.com/" ]
[ wechat_api_url: <string> | default = "https://qyapi.weixin.qq.com/cgi-bin/" ] # 企业微信API地址
[ wechat_api_secret: <secret> ] # 企业微信API SECRET
[ wechat_api_corp_id: <string> ] # 企业微信CORP ID信息
[ telegram_api_url: <string> | default = "https://api.telegram.org" ]
[ webex_api_url: <string> | default = "https://webexapis.com/v1/messages" ]
[ http_config: <http_config> ] # 默认的HTTP客户端配置
# 当Alertmanager持续多长时间未接收 到告警后标记告警状态为resolved(已解决)。该参数的定义可能会影响到告警恢复通知的接收时间。
[ resolve_timeout: <duration> | default = 5m ]
# 读取自定义通知模板定义的文件。可以使用通配符匹配器,例如”templates/*.tmpl“。
templates:
[ - <filepath> ... ]
# 路由树的根节点。
route: <route>
# 告警接收者列表
receivers:
- <receiver> ...
# 抑制规则列表。
inhibit_rules:
[ - <inhibit_rule> ... ]
# DEPRECATED: use time_intervals below.
# 路由静音时间间隔列表。
mute_time_intervals:
[ - <mute_time_interval> ... ]
# 静默/激活路由的时间间隔列表。
time_intervals:
[ - <time_interval> ... ](2)route 告警路由与告警分组
对于不同级别的告警,我们可能有不同的处理方式,因此在route中,我们还可以在routes中定义更多的子route(不同的match和receiver等信息)。
route的完整配置如下:
route:
receiver: <string> # 根路由,默认的告警接收器,对应receiver配置中的name
group_by: [' <labelname>, ... '] # 可通过prometheus告警规则中的标签名称将告警进行分组(alertmanager将同组告警合并一起发送,例如一封邮件通知包含2个告警信息);group_by:['…'] 禁用分组聚合
group_wait: <duration> | default = 30s # 30s内接收到的同组的告警,会合并成一个通知向receiver发送
group_interval: <duration> | default = 5m # 相同的组之间发送告警通知的时间间隔(同组告警的发送间隔)
repeat_interval: <duration> | default = 4h # 未恢复的告警重复发送的时间间隔(告警升级)
####################
routes: # 下面配置所有子路由(根路由的配置,若子路由未定义,则会使用根路由配置;子路由有的配置,以子路由为准)
- receiver: '<string>' # 指定告警接收器,对应receiver配置中的name
group_by: [' <labelname>, ... ']
match: # 匹配器
[ <labelname>: <labelvalue>, ... ] # 匹配prometheus告警规则中的label
match_re: # 正则匹配器
[ <labelname>: <regex>, ... ] # 使用正则表达式匹配prometheus告警规则中的label
matchers: # 一个匹配器列表,必须满足该列表所有匹配规则
[ - <matcher> ... ]
[ continue: <boolean> | default = false ] # 是否继续匹配后续的子route规则,true/false
mute_time_intervals: # 路由被静音的次数。这些必须与mute_time_interval部分中定义的静音时间间隔的名称相匹配。根节点不能设置静音时间。当路由被静音时,它将不发送任何通知,但其他方面正常运行(包括如果未设置“continue”选项,则结束路由匹配过程)。
[ - <string> ...]
active_time_intervals: # 路由激活的次数。这些必须与time_interval部分中定义的时间间隔名称相匹配。空值表示该路由始终处于活动状态。此外,根节点不能有任何活动时间。路由只有在激活时才会发送通知,否则会正常运行(包括在未设置“continue”选项时结束路由匹配过程)。
[ - <string> ...]路由匹配规则:
- 每一个告警都会从配置文件中顶级的route进入路由树,需要注意的是顶级的route必须匹配所有告警 (即不能有任何的匹配设置match和match_re),每一个路由都可以定义自己的接收人以及匹配规则。默认情况下,告警进入到顶级route后会遍历所有的子节点,直到找到最深的匹配route,并将告警发送到 该route定义的receiver中。但如果route中设置continue的值为false,那么告警在匹配到第一个子节点之后就直接停止。如果continue为true,报警则会继续进行后续子节点的匹配。如果当前告警匹配不到任何的子节点,那该告警将会基于当前路由节点的接收器配置方式进行处理。
- 对Prometheus告警规则的匹配有两种方式可以选择。一种方式基于字符串验证,通过设置match规则判断当前告警 中是否存在标签labelname并且其值等于labelvalue。第二种方式则基于正则表达式,通过设置 match_re验证当前告警标签的值是否满足正则表达式的内容。
- 如果警报已经成功发送通知, 如果想设置重复发送告警通知之前的等待时间,则可以通过repeat_interval 参数进行设置。(告警升级)
- 注意根路由的配置,若子路由未定义,则子路由会带上该根路由的配置
- Alertmanager可以对告警通知进行分组,将多条告警合并为一个通知。使用group_by来定义分组规则,基于prometheus告警规则中的标签名称。
配置案例:
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [cluster, alertname]
routes:
- receiver: 'database-pager'
#group_by: [alertname]
group_wait: 10s
matchers:
- service=~"mysql|cassandra"
- receiver: 'frontend-pager'
group_by: [product, environment]
matchers:
- team="frontend"
- receiver: 'dev-pager'
matchers:
- service="inhouse-service"
mute_time_intervals:
- offhours
- holidays
continue: true
- receiver: 'on-call-pager'
matchers:
- service="inhouse-service"
active_time_intervals:
- offhours
- holidays(3)receiver 告警通知配置
alertmanager支持的集成告警方式:
# The unique name of the receiver.
name: <string>
# Configurations for several notification integrations.
discord_configs:
[ - <discord_config>, ... ]
email_configs:
[ - <email_config>, ... ]
msteams_configs:
[ - <msteams_config>, ... ]
opsgenie_configs:
[ - <opsgenie_config>, ... ]
pagerduty_configs:
[ - <pagerduty_config>, ... ]
pushover_configs:
[ - <pushover_config>, ... ]
slack_configs:
[ - <slack_config>, ... ]
sns_configs:
[ - <sns_config>, ... ]
telegram_configs:
[ - <telegram_config>, ... ]
victorops_configs:
[ - <victorops_config>, ... ]
webex_configs:
[ - <webex_config>, ... ]
webhook_configs:
[ - <webhook_config>, ... ]
wechat_configs:
[ - <wechat_config>, ... ](4)templates 告警通知模板配置
默认情况下Alertmanager使用了系统自带的默认通知模板,模板源码可以从https://github.com/prometheus/alertmanager/tree/main/template获得。Alertmanager的通知模板基于Go 的模板系统。Alertmanager也支持用户定义和使用自己的模板,一般来说有两种方式可以选择。
1、基于模板字符串。用户可以直接在Alertmanager的配置文件中使用模板字符串
例如:
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
text: 'https://internal.myorg.net/wiki/alerts/{{ .GroupLabels.app }}/{{.GroupLabels.alertname }}'2、自定义可复用的模板文件。
例如,可以创建自定义模板文件custom-template.tmpl
{{ define "slack.myorg.text" }}https://internal.myorg.net/wiki/alerts/{{.GroupLabels.app }}/{{ .GroupLabels.alertname }}{{ end}}在Alertmanager的全局设置中定义templates配置来指定自定义模板的访问路径:
# Files from which custom notification template definitions are read.
# The last component may use a wildcard matcher, e.g. 'templates/*.tmpl'.
templates:
[ - <filepath> ... ]在设置了自定义模板的访问路径后,用户则可以直接在配置中使用该模板:
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
text: '{{ template "slack.myorg.text" . }}'
templates:
- '/etc/alertmanager/templates/myorg.tmpl'
配置案例:
1、自定义告警模板文件 "email-test.tmpl"
cat email-test.tmpl{{ define "email.tmpl" }} # 定义模块名称,与receiver中的 html - template 定义的模板名称保持一致
{{- if gt (len .Alerts.Firing) 0 -}}{{ range.Alerts }}
告警名称: {{ .Labels.alertname }} <br>
实例名: {{ .Labels.instance }} <br>
摘要: {{ .Annotations.summary }} <br>
详情: {{ .Annotations.description }} <br>
级别: {{ .Labels.severity }} <br>
开始时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++<br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range.Alerts }}
Resolved-告警恢复了。<br>
告警名称: {{ .Labels.alertname }} <br>
实例名: {{ .Labels.instance }} <br>
摘要: {{ .Annotations.summary }} <br>
详情: {{ .Annotations.description }} <br>
级别: {{ .Labels.severity }} <br>
开始时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
恢复时间: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++<br>
{{ end }}{{ end -}}
{{- end }}
2、修改alertmanager.yml配置文件
# 加载告警模板的路径位置
global:
resolve_timeout: 5m
templates:
- '/usr/local/prometheus/alertmanager/templates/*.tmpl'
# receivers使用自定义邮件告警模板
receivers:
- name: 'default-receiver'
email_configs:
- to: 'it_xxx_software@163.com'
send_resolved: true
html: '{{ template "email.tmpl" . }}' # email.tmpl与模板文件中的define定义的模板名保持一致
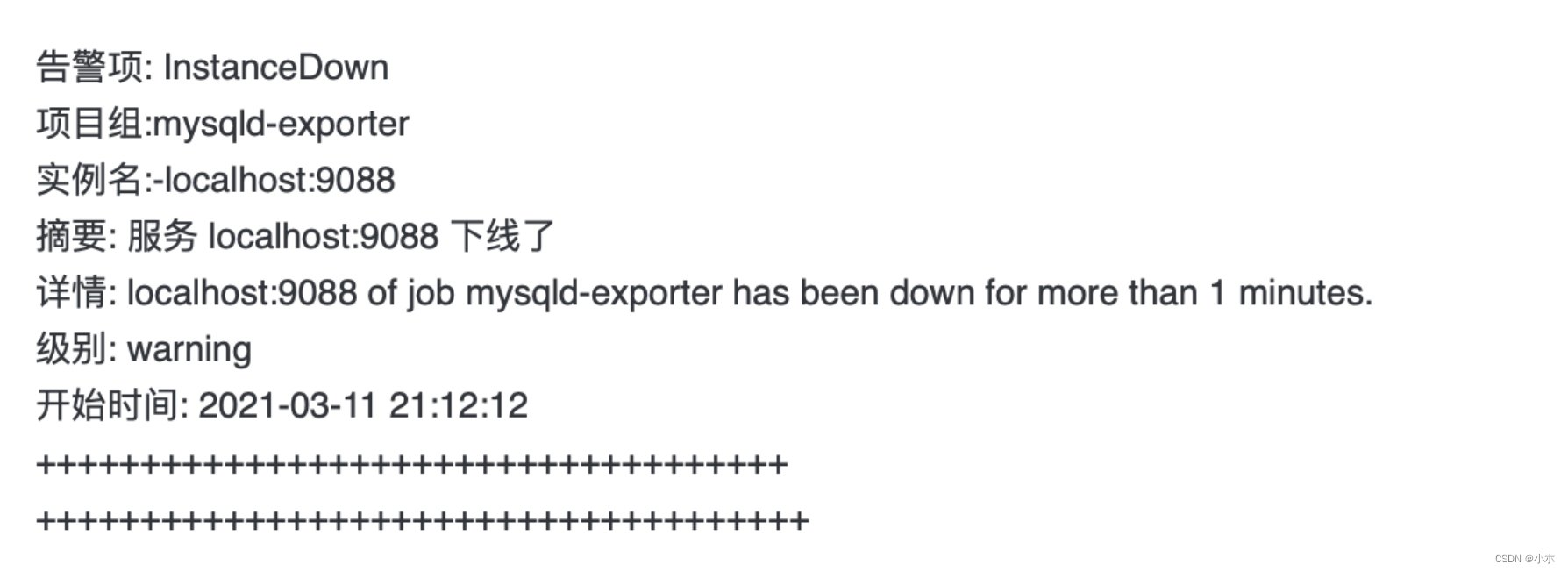
告警通知结果:
(5)inhibit_rules 抑制规则配置
Alertmanager提供了方式可以帮助用户控制告警抑制通知的行为,包括预先定义的抑制机制和临时定义的静默规则。
抑制机制
在Alertmanager配置文件中,使用inhibit_rules定义一组告警的抑制规则:
inhibit_rules:
[ - <inhibit_rule> ... ]
每一条抑制规则的具体配置如下:
source_match: # 源告警匹配器
[ <labelname>: <labelvalue>, ... ]
source_match_re: # 源告警正则匹配器
[ <labelname>: <regex>, ... ]
source_matchers: # 源告警匹配器列表,需要全满足
[ - <matcher> ... ]
target_match: # 目标告警匹配器
[ <labelname>: <labelvalue>, ... ]
target_match_re: # 目标告警正则匹配器
[ <labelname>: <regex>, ... ]
target_matchers: # 目标告警匹配器列表,需要全满足
[ - <matcher> ... ]
[ equal: '[' <labelname>, ... ']' ] # 在源和目标告警中必须具有相等值的标签以下3个条件同时满足,则启动抑制机制,新的告警不会发送。
- 当已经发送的告警通知匹配 source_match 规则
- 有新的告警满足 target_match 匹配规则
- 并且已发送的告警与新产生的告警中,equal定义的标签完全相同
注意:
1、在语义上,缺失的标签和空值的标签是相同的意思。因此,如果在源警报和目标警报中,
equal中列出的所有标签名称都不存在,也会启动抑制规则。2、为了防止警报抑制自身,建议 target_match 和 source_match 一般不要设置的一样。
配置案例:
- source_match:
alertname: NodeDown
severity: critical
target_match:
severity: critical
equal:
- node例如当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警 级别severity=critical。由于主机异常宕机,该主机上部署的所有服务,中间件会不可用并触发报警。根 据抑制规则的定义,如果有新的告警级别为severity=critical,并且告警中标签node的值与NodeDown告警的相同,则启动抑制机制停止发送告警通知。
(5)AlertManager 临时静默配置(维护期)
除了基于抑制机制可以控制告警通知的行为以外,用户或者管理员还可以直接通过Alertmanager的UI页面临时屏蔽特定的告警通知。通过定义标签的匹配规则(字符串或者正则表达式),如果新的告警通知满足静 默规则的设置,则停止向receiver发送通知。
进入Alertmanager UI,点击"New Silence"显示如下内容:
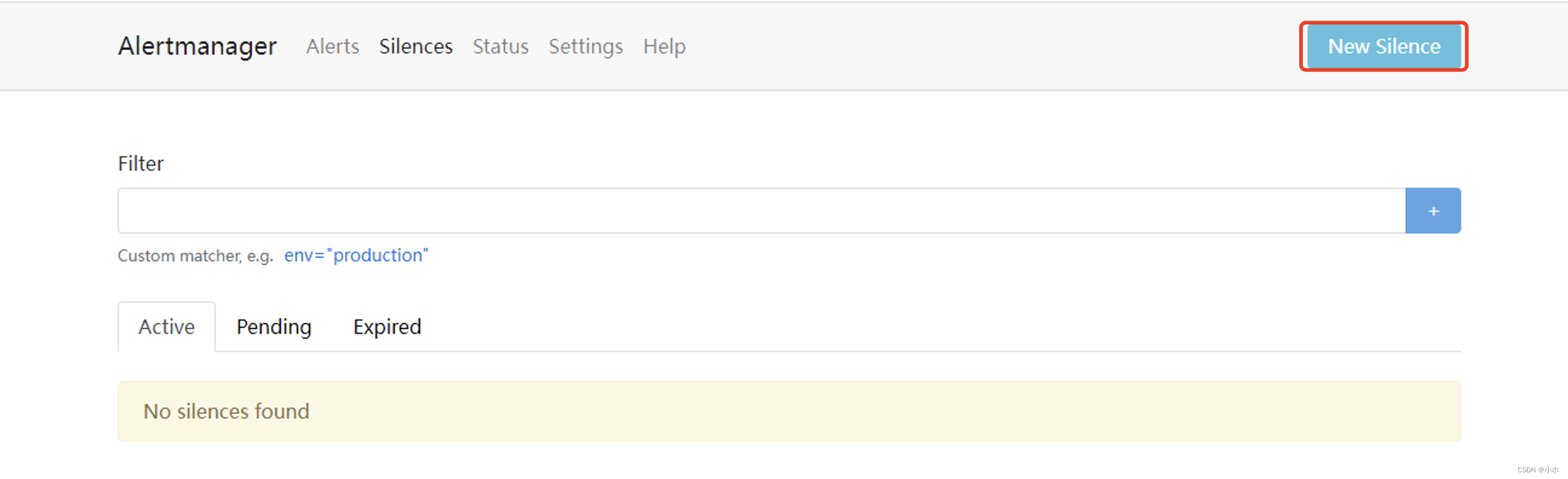
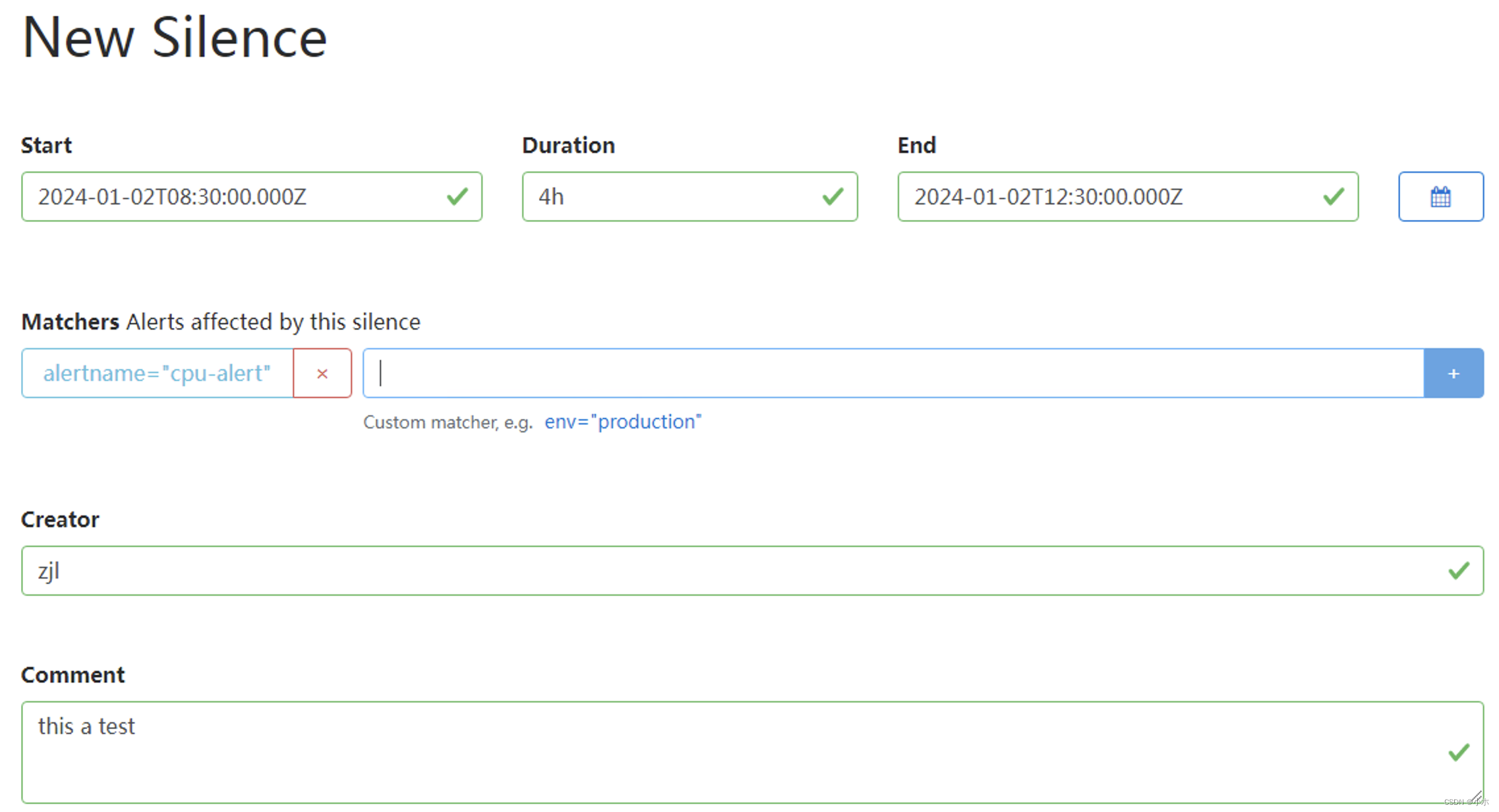
- 用户可以通过该UI定义新的静默规则的开始时间以及持续时间
- 通过Matchers部分可以设置多条匹配规则(字符串匹配或者正则匹配)。
- 填写当前静默规则的创建者以及创建原因后,点击"Create"按钮即可。
- 通过"Preview Alerts"可以查看预览当前匹配规则匹配到的告警信息。静默规则创建成功后,Alertmanager会加载该规则设置状态为Pending,规则生效后进入Active状态。
- 静默规则生效后,Alerts页面下不能看到静默规则匹配的告警信息。
- 对于已经生效的规则,可以手动点击“Expire”使当前规则过期

















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









