






什么是正则表达式
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式的匹配规则
正则表达式由一些普通字符和一些特殊字符(metacharacters)组成。普通字符包括大小写的字母和数字,而特殊字符则具有特殊的含义,我们下面会给予解释。
普通字符:
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
| 字符 | 描述 |
|---|---|
| [abc] | 匹配 […] 中的所有字符,例如 [aeiou] 匹配字符串中所有的a或e或i或o或u |
| [a-c] | 相当于[abc] |
| [a-fA-F0-9] | 匹配大写小写或者数字 |
| [^0-9] | 匹配非数组字符 |
| [\d] | 数字字符 |
| [\D] | 非数字字符 |
| [\w] | 单词字符(数字字母下划线) |
| [\W] | 非单词字符 |
| [\s] | 空格换行tab |
| [\S] | 非空白符 |
| [.] | 任意字符(除了换行,tab) |
| [\n] | 换行符 |
特殊字符:
特殊字符大致可以分为限定符和修饰符,因为特殊字符本身具有意义所以如果要匹配特殊字符可以在前面加限定符\,例如要匹配*可以用\*来指定
限定符:
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 “do” 、 “does”、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 “Bob” 中的 o,但能匹配 “foooood” 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,} | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于 {0,}。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 “fooooood” 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
| | | Buy more (milk|bread|juice) 表示Buy more后匹配milk或bread或juice |
| [abc] | 方括号表达式,在中括号中表达式中匹配其中任意一个成立的项 |
| ^ | 在方括号中表示匹配不满足的情况例如[^123xyz]表示匹配非123和xyz的字符 |
| () | 选择,用圆括号 () 将所有选择项括起来,相邻的选择项之间用|分隔。并且子表达式可以获取供以后使用,() 会把每个分组里的匹配的值保存起来,叫做捕获分组, 多个匹配值可以通过数字 n 来查看 |
定位符:
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
正则表达式的定位符有:
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符。不要将 ^ 的这种用法与方括号表达式内的用法混淆。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。\b的位置很重要如果x\b则在单词结尾查找匹配项如果\bx则在单词开头查找匹配项 |
| \B | 非单词边界匹配,即在非\b的地方查找匹配项 |
贪婪和懒惰匹配
* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,在它们的后面加上一个 ? 就可以实现懒惰匹配。
例如,您可能搜索HTML文档,以查找h1标签的内容。HTML代码如下:
<h1>this is a test</h1>
如果用 /<.*>/ 那么得到的将是 <h1>this is a test</h1> 因为*默认匹配尽可能多的它修饰的.字符,而前面提到了.代表任意除了换行符以外的字符
所以如果想要得到<h1>可以在*后面加一个?,即 /<.*?>/,这样得到的就是 <h1>
推荐教程和网站
RegexOne
有教程和若干可以实时测试以及讲解的练习,英文也不算难懂
这里是里面测试的答案
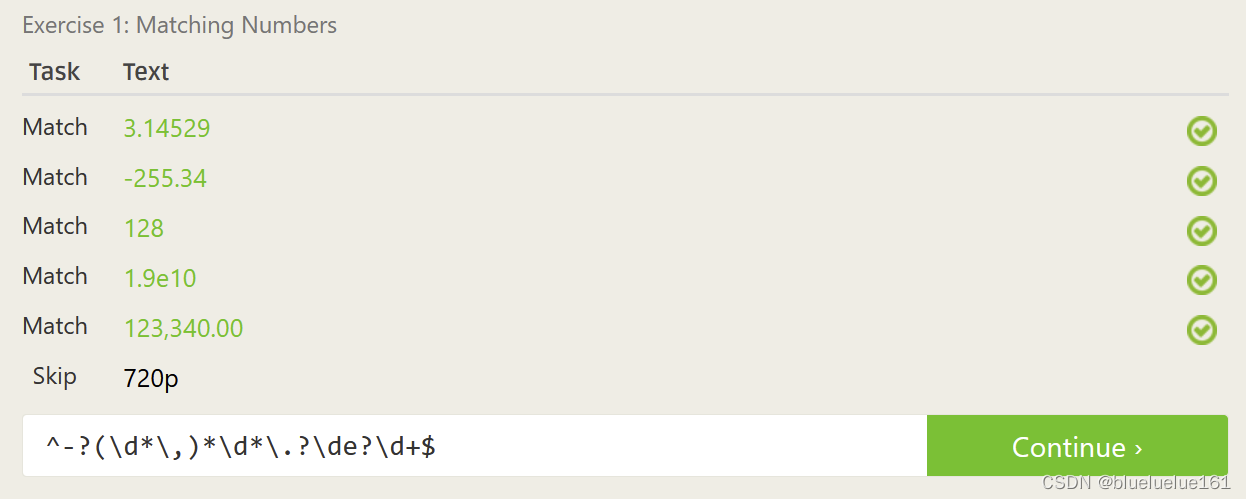
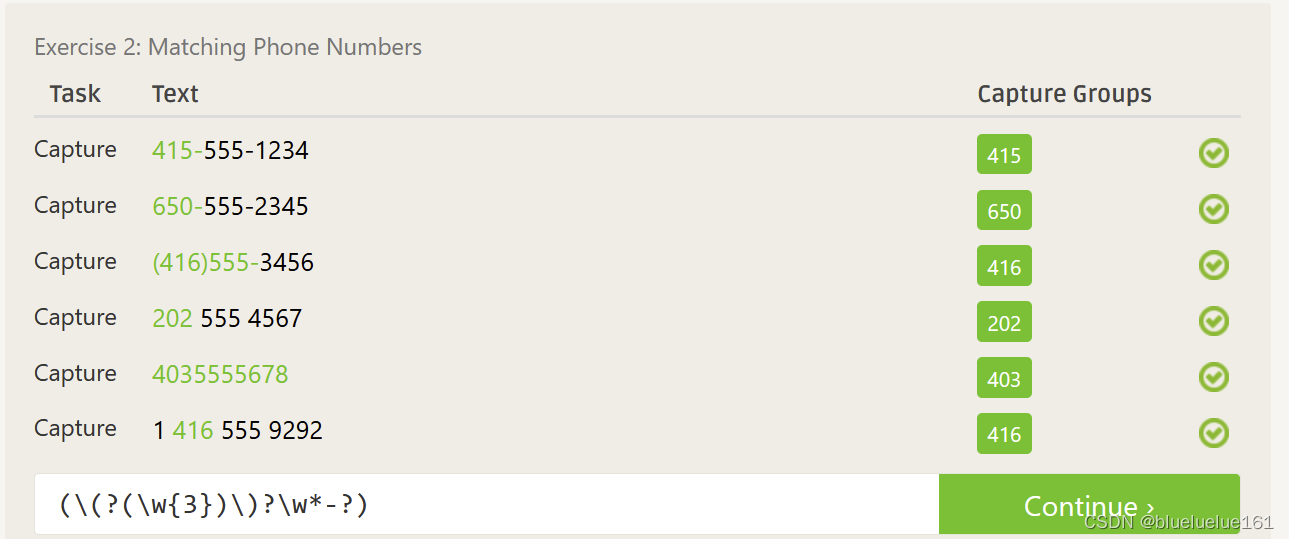
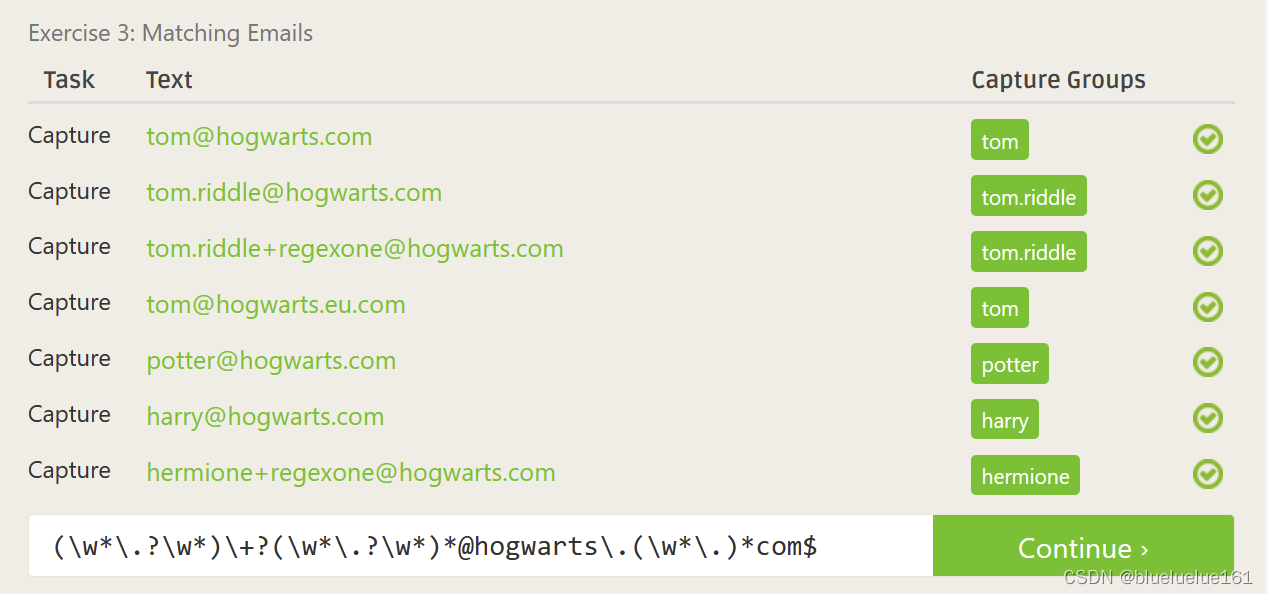
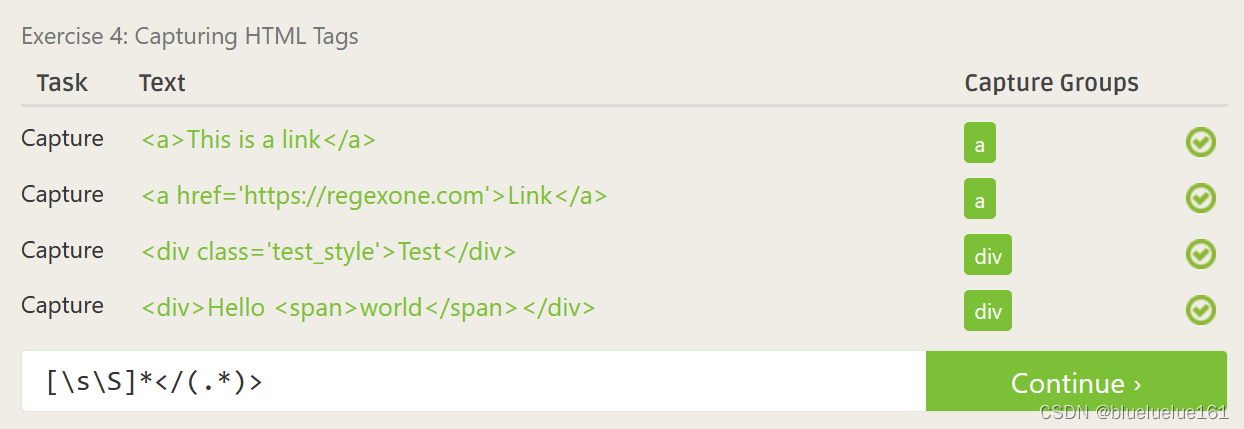
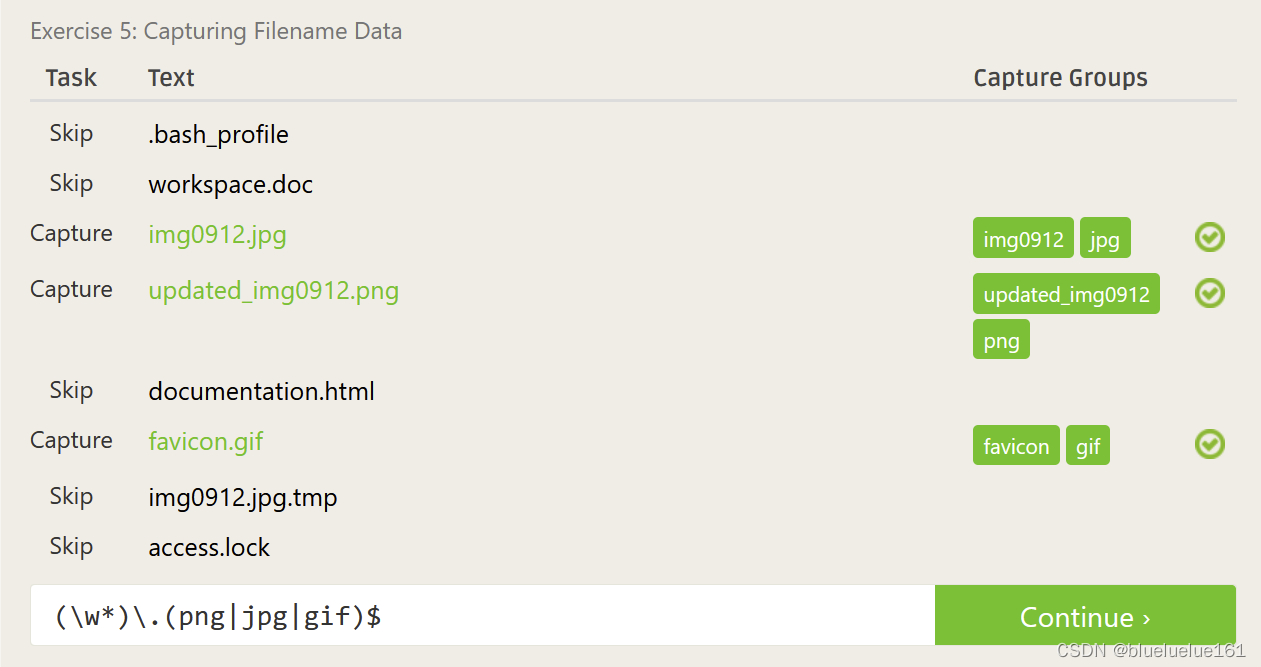
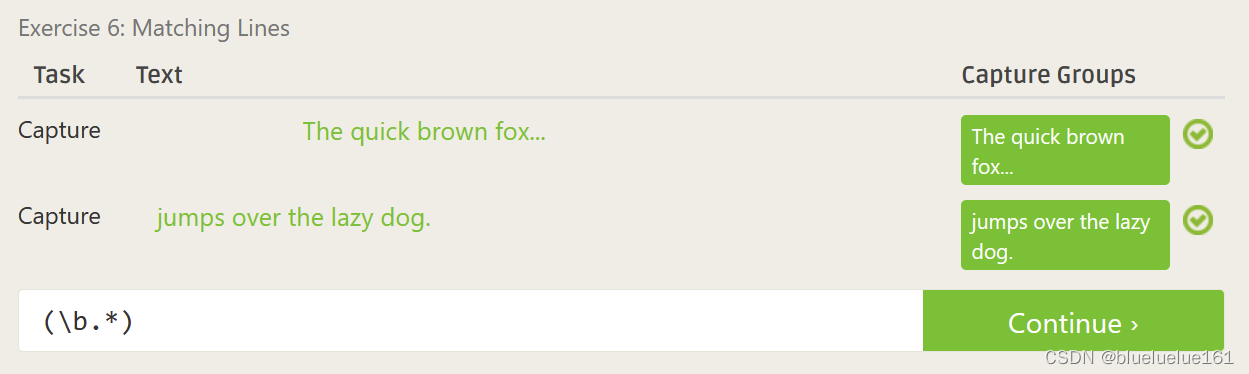
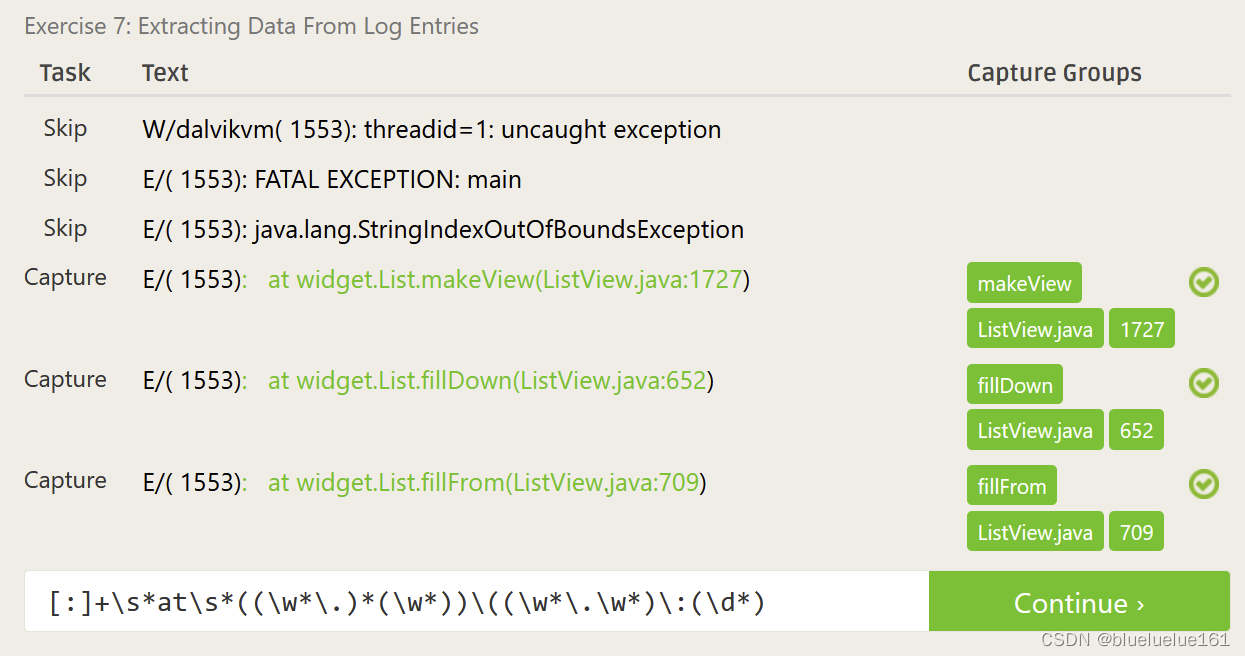
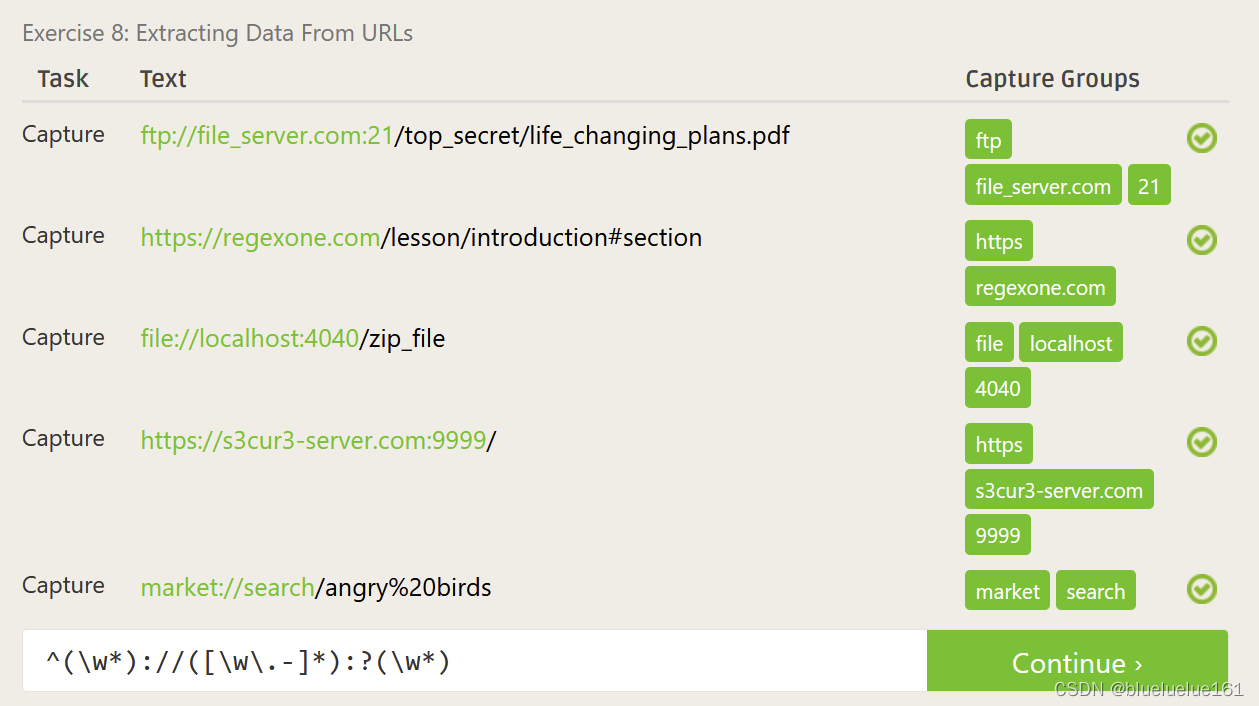
Regex101
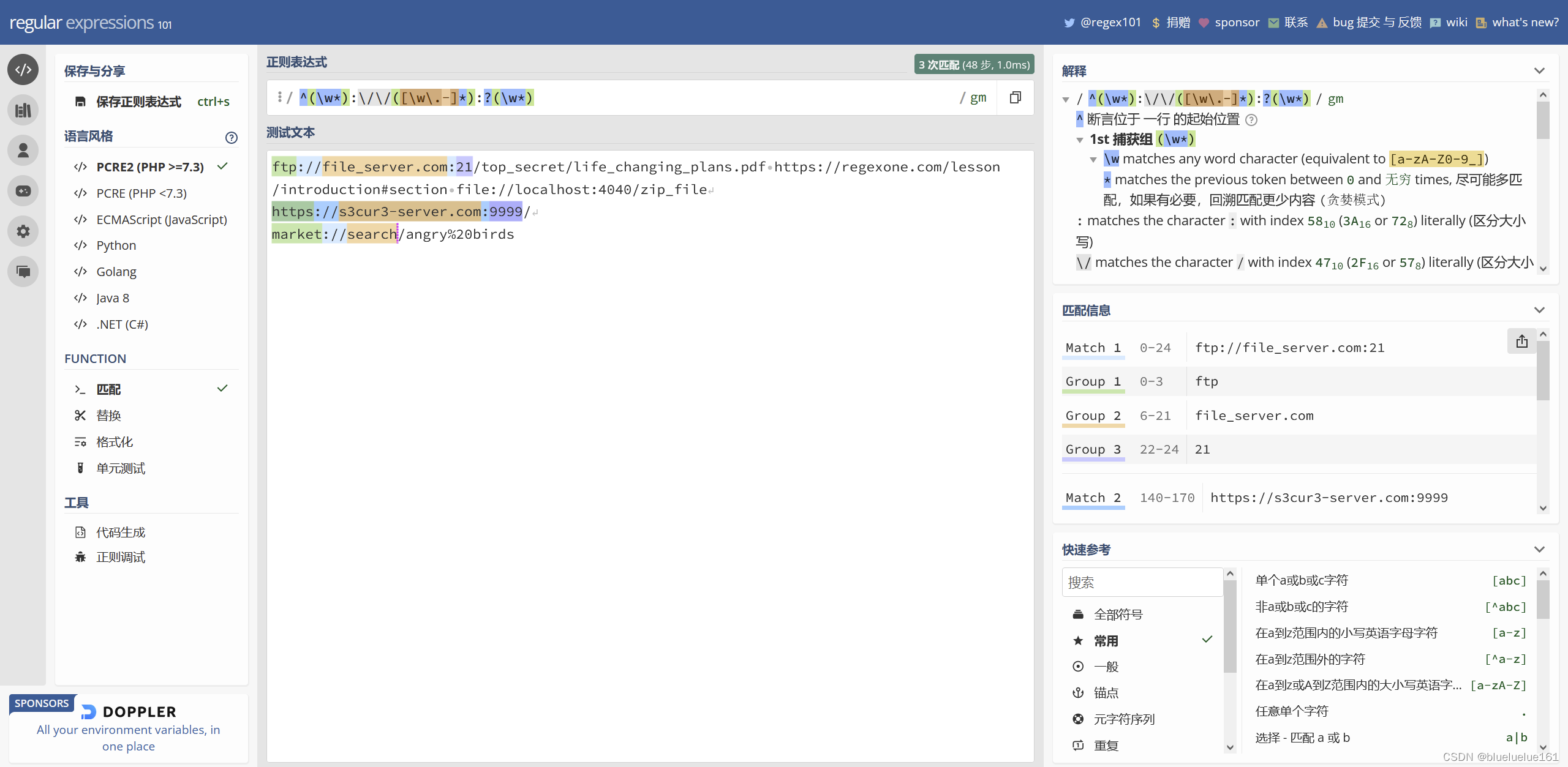
正则表达式一直公认是一个很难搞的东西,例如下面就是一个匹配email格式的正则表达式,为了方便写正则表达式就有了正则表达式调试器

而regex101就是一个正则表达式调试器,支持简体中文,可以动态显示当前表达式效果,高亮显示各个捕获分组和解释各个语句的效果,并且还有一些标准的业界公认的工具库可以调用
Python中正则表达式的应用
首先来辨析两个问题
1.python中单引号和双引号的区别?
可以当作没有区别,用哪个都可以,单引号和双引号的区别只是在单引号中用双引号不用转意和在双引号中用单引号不用转义,但是其它都要转义,这两个互相之间使用不用转义又有什么区别呢?所以当作没有区别即可,但是实际上这一点在向sql数据库中插入数据的时候是比较有用的,比如
name='霸王别姬'
rating=9.8
subject='陈凯歌的作品'
sql = "insert into tb_top_movie (title,rating,subject) values ('%s',%s,'%s')" % (name, rating, subject)
cursor.execute(sql)
因为在数据库里面name和subject是char类型的,所以相当于最后在数据库执行的时候是"霸王别姬",9.8,“陈凯歌的作品”
2.为什么正则表达式的字符串前面都要有r这个字母?
在字符串前加r可防止字符串转义,比如print(r’\n’),输出为\n,print(‘\n’),输出为换行
3.如果我们要用到的都是自己输入的倒还好直接加一个r即可,那如果是一个str呢?怎么防止转义?
用re.escape函数即可,如:
str='\n\s\w'
pattern=re.compile(r'123'+re.escape(str)+r'123')
python中正则表达式模块为re,主要有三个函数
re.match
re.match 尝试从字符串的起始位置匹配一个模式,匹配成功则返回的是一个匹配对象group(这个对象包含了我们匹配的信息),如果不是起始位置匹配成功的话,match()返回的是空
例子如下
import re
content='Hello 1234567 World This is a Regex Demo'
result=re.match(r'^Hello\s(\d+).*(\w+)$',content)
print(result)
print(result.group(0))
print(result.group(1))
print(result.group(2))
<_sre.SRE_Match object; span=(0, 40), match='Hello 1234567 World This is a Regex Demo'>
Hello 1234567 World This is a Regex Demo
1234567
o
其中result返回的是一个group对象,group(0)返回的是总的匹配结果,group(1)返回第一个捕获分组,group(2)返回第二个捕获分组…
对于group对象,如果我们觉得group(n)这种方式来获取对象不太直观,还可以在捕获分组的()中加入(?P<name>…) 语法
例子如下
import re
content='Hello 1234567 World This is a Regex Demo'
result=re.match(r'^Hello\s(?P<first_group>\d+).*(?P<second_group>\w+)$',content)
print(result.group(0))
print(result.group('first_group'))
print(result.group('second_group'))
Hello 1234567 World This is a Regex Demo
1234567
o
re.search
re.search与re.match方法基本相同,不同点在于re.search 扫描整个字符串,匹配成功则返回的是第一个匹配成功的对象group(这个对象包含了我们匹配的信息)
re.findall
re.findall 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表,其中列表中的每个元素如果该匹配没有捕获分组,返回的是一整个匹配成功的字符串,否则返回的是一个元组,元组中的每个元素是各个捕获分组
例子:
如果没有设置捕获分组
import re
content='Hello 1234567 Hello 456789'
result=re.findall(r'Hello\s*\d{6}',content)
print(result)
['Hello 123456', 'Hello 456789']
如果设置了捕获分组
import re
content='Hello 1234567 Hello 456789'
result=re.findall(r'(Hello)\s*(\d{6})',content)
print(result)
[('Hello', '123456'), ('Hello', '456789')]
python正则表达式中\1 \2 等的使用
python的正则表达式中\1代表正则表达式中第一个分组,\2代表第二个分组
import re
str='Hello'
content='HelloHello'
print(re.findall(r"(Hello)(\1)",content))
等价于
str='Hello'
content='HelloHello'
print(re.findall(r"(Hello)(Hello)",content))
python正则表达式插入自己定义的外部字符串
使用r加format来实现
import re
str='Hello'
content='HelloHello'
print(re.findall(r'({})(\1)'.format(str),content))
等价于
import re
content='HelloHello'
print(re.findall(r"(Hello)(\1)".format(str),content))














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









