






一、实验目的
实现Kmeans聚类算法
- 实验主要过程与结果
1、算法描述
输入:iris数据集,提取1,3维作为聚类数据;初始化k=3
输出:聚类结果
- 随机生成k个初始点作为初试聚类中心,由中心代表各聚类;
a = [5.1, 1.4]
b = [4.9, 1.4]
c = [4.7, 1.3]
k = 3
- 计算所有点到这k个中心点的距离,并将点归到离其最近的聚类;
for i in range(150):
d1 = eucliDist(a, X[i, 0:2])
d2 = eucliDist(b, X[i, 0:2])
d3 = eucliDist(c, X[i, 0:2])
x = min(d1, d2, d3)
if (x == d1): A.append(X[i, 0:2])
if (x == d2): B.append(X[i, 0:2])
if (x == d3): C.append(X[i, 0:2])
- 将各个簇中的数据求平均值,作为新的类中心,重复上一步,直到所有的簇不再改变;
x = np.mean(A, axis=0)
y = np.mean(B, axis=0)
t = np.mean(C, axis=0)
x = np.round(x, 1)
y = np.round(y, 1)
t = np.round(t, 1)
if ((a == x).all() and (b == y).all() and (c == t).all()):
flag = 0
else:
a = x
b = y
c = t
2、扩展任务
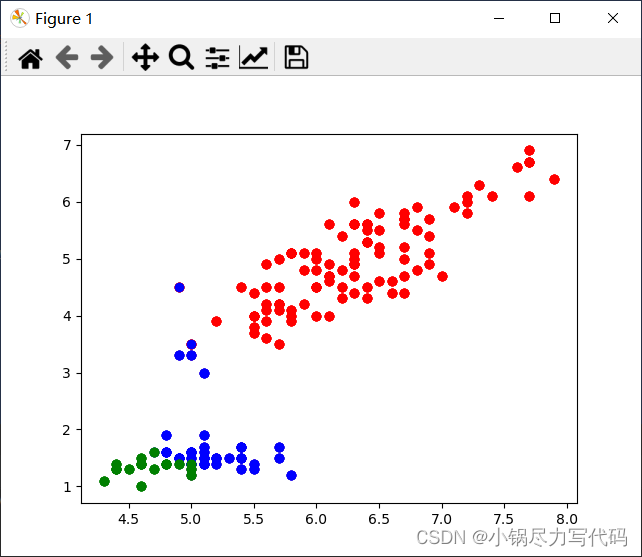
对聚类结果进行可视化
for i in range(len(A)):
q = A[i][0]
w = A[i][1]
plt.scatter(q, w, c='r')
for i in range(len(B)):
q1 = B[i][0]
w1 = B[i][1]
plt.scatter(q1, w1, c='b')
for i in range(len(C)):
q2 = C[i][0]
w2 = C[i][1]
plt.scatter(q2, w2, c='g')
plt.show()
- 最终所有代码:
import pandas as pd
import numpy as np
import random
from matplotlib import pyplot as plt
data = pd.read_csv("iris.csv", header=None)
data__value = data.values
z = data__value[:, 0]
t = data__value[:, 2]
X = np.vstack((z, t)).T # 矩阵
def eucliDist(A, B):
return np.sqrt(sum(np.power((A - B), 2)))
a = [5.1, 1.4]
b = [4.9, 1.4]
c = [4.7, 1.3]
k = 3
flag = 1
A = []
B = []
C = []
while flag == 1:
for i in range(150):
d1 = eucliDist(a, X[i, 0:2])
d2 = eucliDist(b, X[i, 0:2])
d3 = eucliDist(c, X[i, 0:2])
x = min(d1, d2, d3)
if (x == d1): A.append(X[i, 0:2])
if (x == d2): B.append(X[i, 0:2])
if (x == d3): C.append(X[i, 0:2])
x = np.mean(A, axis=0)
y = np.mean(B, axis=0)
t = np.mean(C, axis=0)
x = np.round(x, 1)
y = np.round(y, 1)
t = np.round(t, 1)
if ((a == x).all() and (b == y).all() and (c == t).all()):
flag = 0
else:
a = x
b = y
c = t
# 可视化
for i in range(len(A)):
q = A[i][0]
w = A[i][1]
plt.scatter(q, w, c='r')
for i in range(len(B)):
q1 = B[i][0]
w1 = B[i][1]
plt.scatter(q1, w1, c='b')
for i in range(len(C)):
q2 = C[i][0]
w2 = C[i][1]
plt.scatter(q2, w2, c='g')
plt.show()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









