







线性表概览
- 线性表是具有相同数据类型的 n (n≥0) 个数据元素的有限序列,其中 n 为表长,当 n 为 0 时是一个空表。用 L 命名线性表: L = ( a 1 , a 2 , a 3 , … , a n ) L=(a_1,a_2,a_3,…,a_n) L=(a1,a2,a3,…,an)
- 顺序表和链表都是线性结构。
顺序表
- 用顺序存储的方式实现线性表的顺序存储;只有数据域。
- 优缺点:
- 优点:
- 随机访问,在时间复杂度 O ( 1 ) O(1) O(1)内可以找到第 i 个元素。
- 存储密度高,每个节点只存储数据,无需耗费额外内存存储指针。
- 缺点:
- 改变容量不方便,即使采用动态顺序表,其扩展长度的时间复杂度也很高。
- 插入、删除元素不便,需要移动大量元素。
- 优点:
//动态顺序表结构体
#define ElemType int
#define LIST_INIT_SIZE 10 //存储空间的初始分配量
#define LIST_INCREMENT 2 //存储空间的分配增量
typedef struct {
ElemType *elem; //存储空间基址
int length; //当前长度
int listsize; //当前分配的存储容量(以sizeof(ElemType)为单位)
}SqList;
//初始化顺序表,创建一个空顺序表
void InitList(SqList *L) {
(*L).elem=(ElemType*)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!(*L).elem)
exit(1); //存储分配失败
(*L).length=0; //空表长度为0
(*L).listsize=LIST_INIT_SIZE; //初始存储容量
}
//销毁顺序表
void DestroyList(SqList *L) {
free((*L).elem);
(*L).elem=NULL;
(*L).length=0;
(*L).listsize=0;
}
//在顺序表中第i个位置之前插入数据e,表长加 1
void Status ListInsert(SqList *L,int i,ElemType e) {
ElemType *newbase,*q,*p;
if(i<1||i>(*L).length+1) //i值不合法
return;
if((*L).length>=(*L).listsize) { //存储空间已满时,增加分配
newbase=(ElemType *)realloc((*L).elem,((*L).listsize+LIST_INCREMENT)*sizeof(ElemType));
if(!newbase)
exit(1); //存储分配失败
(*L).elem=newbase; //新基址
(*L).listsize+=LIST_INCREMENT; //增加存储容量
}
q=(*L).elem+i-1; //q为插入位置
for(p=(*L).elem+(*L).length-1;p>=q;--p) //插入位置及之后的元素右移
*(p+1)=*p;
*q=e; //插入e
++(*L).length; //表长增1
return;
}
链表
-
每个节点将其空间分成两部分:
- 数据域:数据元素本身存在的区域
- 指针域:指向下一节点的指针所在的区域。
-
优缺点:
- 优点:
- 不要求大片连续空间,改变容量方便。
- 缺点:
- 不可随机存取,时间复杂度为 O ( n ) O(n) O(n)。
- 信息密度低,要耗费一定空间存放指针。
- 优点:
-
实现方式:
- 带头结点:不存任何数据的空节点,通常作为链表的第一个节点;当存在头结点时,头指针指向此结点。
- 不带头结点:数据直接从第一个节点开始存储。
-
单链表:每个元素只存在指向后一个元素的单向指针。
- 缺点:每个节点只能找到后续节点。
- 倒置链表:头插法

-
双链表:每个元素节点存在指向其前后元素的双向指针。每个节点可以向前向后查找元素。

-
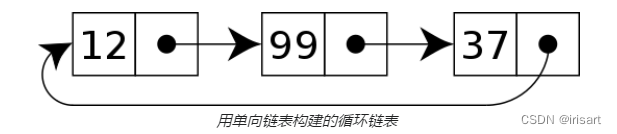
循环链表:是对单、双链表的改进,将其最后一个元素指向下一个位置的指针由 NULL 改为指向头结点。
- 循环单链表:从一个节点向后查找可以找到所有节点。从表头(尾)操作数据的时间复杂度为O(1)
- 循环双链表:头结点指针指向尾节点;尾结点指针指向头结点。
- 判定链表是否为空:头结点指向自己。
-
静态链表:分配整片连续空间,各个节点集中安置。
- 数据全部存储在数组中(和顺序表一样),元素在表内存储位置是随机的,数据之间"一对一"的逻辑关系通过一个整形变量(称为"游标",和指针功能类似)来维持。
- 通常,静态链表会将第一个数据元素放到数组下标为 1 的位置( a[1] )中。
- 数据链表:连接静态链表中已使用空间(占据数据)的链表。
- 备用链表:除开表中被占用的数据空间,其余未使用的空间连接起来组成的链表。
- 优缺点:
- 优点:增删改查无需移动大量元素。
- 缺点:容量固定,不能随机存取,只能从头结点开始查找。
- 使用场景:
- 不支持指针的低级语言;
- 数据元素固定不变等场景。
// 单向链表的节点结构体
struct node_st {
void *datap; // 数据指针
struct node_st *next; // 指向下一个节点的指针
};
// 单向链表结构体
struct llist_st {
struct node_st *head; // 头节点指针
int elmsize; // 元素大小
};
// 创建链表
struct llist_st *llist_new(int elmsize) {
struct llist_st *newlist = malloc(sizeof(struct llist_st));
if (newlist == NULL) return NULL;
newlist->head = NULL;
newlist->elmsize = elmsize;
return newlist;
}
// 销毁链表
void llist_delete(struct llist_st *ptr) {
struct node_st *curr, *save;
for (curr = ptr->head; curr != NULL; curr = save) {
save = curr->next;
free(curr->datap);
free(curr);
}
free(ptr);
}
顺序表和链表的对比
- 创建:
- 顺序表:
- 静态分配:容量不可变。需连续分配空间,过小则不便拓展,过大则浪费资源。
- 动态分配:容量可变,增加元素需要移动大量元素,时间代价大。
- 链表:只声明一个头结点(或不带头结点)和头指针即可。
- 顺序表:
- 销毁:
- 顺序表:
- 静态数组:系统自动进行内存回收。
- 动态数组:需手动销毁相应内存空间。
- 链表:手动销毁,系统才能回收相应内存。
- 顺序表:
- 增删:
- 顺序表:数据要进行整体前后移,时间复杂度主要来源为数据移动 O ( n ) O(n) O(n)。如果数据过大,则时间开销很大。
- 链表:只需修改指针,时间复杂度主要来源为查找元素 O ( n ) O(n) O(n)。
- 查:
- 顺序表:(效率更高)
- 按位查找: O ( 1 ) O(1) O(1)
- 按值查找:无序排列 O ( n ) O(n) O(n);有序排列 O ( log 2 n ) O(\log_2n) O(log2n)
- 链表:
- 按位查找: O ( n ) O(n) O(n)
- 按值查找: O ( n ) O(n) O(n)
- 顺序表:(效率更高)
- 使用场景:
- 顺序表:表长固定,查(读)频繁。
- 链表:表长不固定,增删(写)频繁。
广义表
- 广义表,又称列表,也是一种线性存储结构,既可以存储不可再分的元素,也可以存储广义表。记作: L S = ( a 1 , a 2 , … , a n ) LS = (a_1,a_2,…,a_n) LS=(a1,a2,…,an),其中, L S LS LS 代表广义表的名称, a n a_n an 表示广义表存储的数据,广义表中每个 a i a_i ai 既可以代表单个元素,也可以代表另一个广义表。
- 广义表中存储的单个元素称为 “原子”,而存储的广义表称为 “子表”。
- A = ( ) A = () A=():A 表示一个广义表,只不过表是空的。
- B = ( e ) B = (e) B=(e):广义表 B 中只有一个原子 e。
- C = ( a , ( b , c , d ) ) C = (a,(b,c,d)) C=(a,(b,c,d)) :广义表 C 中有两个元素,原子 a 和子表 ( b , c , d ) (b,c,d) (b,c,d)。
- D = ( A , B , C ) D = (A,B,C) D=(A,B,C):广义表 D 中存有 3 个子表,分别是A、B和C。这种表示方式等同于 D = ( ( ) , ( e ) , ( b , c , d ) ) D = ((),(e),(b,c,d)) D=((),(e),(b,c,d)) 。
- E = ( a , E ) E = (a,E) E=(a,E):广义表 E 中有两个元素,原子 a 和它本身。这是一个递归广义表,等同于: E = ( a , ( a , ( a , … ) ) ) E = (a,(a,(a,…))) E=(a,(a,(a,…)))。
- 表头和表尾:
- 当广义表不是空表时,称第一个数据(原子或子表)为"表头",剩下的数据构成的新广义表为"表尾"。
- 除非广义表为空表,否则广义表一定具有表头和表尾,且广义表的表尾一定是一个广义表。
- 广义表长度:指的是广义表中所包含的元素的个数。(一个元素或表算作一个元素)
- 广义表深度:可以通过观察该表中所包含括号的层数间接得到。
// 定义广义表节点结构体
struct GList {
int is_atom; // 标记当前节点是否是原子(1表示是,0表示不是)
union {
int atom; // 如果是原子,则存储原子值
struct GList *sublist; // 如果不是原子,则存储子表指针
};
struct GList *next; // 指向下一个节点的指针
};
// 创建原子节点
struct GList *create_atom(int value) {
struct GList *node = (struct GList *)malloc(sizeof(struct GList));
if (node != NULL) {
node->is_atom = 1;
node->atom = value;
node->next = NULL;
}
return node;
}
// 创建子表节点
struct GList *create_sublist(struct GList *sublist) {
struct GList *node = (struct GList *)malloc(sizeof(struct GList));
if (node != NULL) {
node->is_atom = 0;
node->sublist = sublist;
node->next = NULL;
}
return node;
}
// 销毁广义表
void destroy_glist(struct GList *glist) {
if (glist == NULL) return;
if (glist->is_atom) {
free(glist);
} else {
destroy_glist(glist->sublist); // 递归销毁子表
free(glist);
}
}
int main() {
// 创建原子节点
struct GList *node1 = create_atom(1);
struct GList *node2 = create_atom(2);
struct GList *node3 = create_atom(3);
struct GList *node4 = create_atom(4);
// 创建子表节点 (2, 3)
struct GList *sublist = create_sublist(node2);
sublist->next = create_sublist(node3);
// 创建根节点 (1, (2, 3), 4)
struct GList *root = create_sublist(node1);
root->next = create_sublist(sublist);
root->next->next->next = node4;
// 销毁广义表
destroy_glist(root);
}















 474
474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









