






目录
5、如果price列的值>3000,group列显示high,否则显示low
7、对category字段的值依次进行分列,并创建数据表,索引值为df_inner的索引列,列名称为category和size
8、判断city列里是否包含beijing和shanghai,然后将符合条件的数据提取出来
4、对city字段进行汇总,并分别计算prince的合计和均值
(^-^):导言
众所周知,现在是数据时代,掌握数据处理方法极为重要,pandas是python的众多库中非常优秀,运用特别广泛的第三方库。(我承认,那几句是水字数,小小蒟蒻已经不好意思再夸了,但是pandas确实是非常好用的库),pandas的快乐谁用谁知道[doge]。至少学了不亏~
必须要说明的是,作为一个蒟蒻,pandas的降解文章不是我所能写出来的,是参考了大佬的文章后根据自己学习时所感所悟做一些保姆级的讲解。(因为大佬文章中虽然有详细的代码,但是没有运行结果的展示,这对不方便自己尝试看效果的朋友是不友好的。不少小的细节对于初学者来说完全不知道,需要查阅其他小文章的降解才能理解,本蒟蒻就做一个汇总啦~)
大佬文章链接:pandas用法总结
前戏前摇很长,感谢大家可以看完!

一、安装pandas
常规操作:打开cmd(windows系统的可以再屏幕左下角搜索栏目输入cmd),输入pip install pandas (python3的也可以将pip改为pip3,二者没有区别)。
pip install pandas参考文章:pandas的安装
二、数据表的生成(通常是导入数据表)
1.导入库
首先解释,通常pandas与numpy二者是一起工作的,所以养成习惯——导入pandas的同时把numpy导入!
import numpy as np
import pandas as pd
关于numpy,如果有想学习的,我的大佬室友有讲解细致的文章,链接在此,大家随意。
2.导入文件
df = pd.DataFrame(pd.read_csv('name.csv',header=1))#导入名为name的csv文件
df = pd.DataFrame(pd.read_excel('name.xlsx'))#导入名为name的xlsx文件
#df是常见的一种名称,根据个人习惯改成其他名称也可,但不建议,因为多数程序员都认同这个,彼此代码间易读性高注意:header是标题行,通过指定具体的行索引,将该行作为数据的标题行,也就是整个数据的列名。默认首行数据(0-index)作为标题行,如果传入的是一个整数列表,那这些行将组合成一个多级列索引。没有标题行使用header=None。
!!!:来自个人经历的提醒,因为不同人电脑间的差异,
也许如:'name.csv'或'name.xlsx'之类的读取出现问题,解决方法可以尝试使用“绝对路径”!(绝对路径中如果还是出现问题可以尝试/与\互换来解决)
df=pd.read_excel('C:/Users/12345/Desktop/0/提瓦特大陆人物考.xlsx')或者一种不常用的方法
import pandas as pd
from collections import namedtuple
Item = namedtuple('Item', 'reply pv')
items = []
with codecs.open('reply.pv.07', 'r', 'utf-8') as f:
for line in f:
line_split = line.strip().split('\t')
items.append(Item(line_split[0].strip(), line_split[1].strip()))
df = pd.DataFrame.from_records(items, columns=['reply', 'pv'])
在这里,为了方便讲解,我们采用自己创建的方式给大家一个实例。
df = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
"date":pd.date_range('20130102', periods=6),
"city":['Beijing ', 'SH', ' guangzhou ', 'Shenzhen', 'shanghai', 'BEIJING '],
"age":[23,44,54,32,34,32],
"category":['100-A','100-B','110-A','110-C','210-A','130-F'],
"price":[1200,np.nan,2133,5433,np.nan,4432]},
columns =['id','date','city','category','age','price'])所产生的数据表df结果如下
id date city category age price
0 1001 2013-01-02 Beijing 100-A 23 1200.0
1 1002 2013-01-03 SH 100-B 44 NaN
2 1003 2013-01-04 guangzhou 110-A 54 2133.0
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0
4 1005 2013-01-06 shanghai 210-A 34 NaN
5 1006 2013-01-07 BEIJING 130-F 32 4432.0注意:NaN或者nan均代表空值的意思!
三、数据表信息查看
1.维度的查看
df.shape #表示维度,例如(6,6)表示一个6*6的表格
#这里只是告知此函数的书写,具体运行要看个人需求,比如print之类这是根据上部分我们自己创建的实例来运行的,方便大家理解,运行结果如下:
>>>print(df.shape)
(6, 6) #表示维度,例如(6,6)表示一个6*6的表格2、数据表基本信息(维度、列名称、数据格式、所占空间等)
df.info()
#这里只是告知此函数的书写,具体运行要看个人需求,比如print之类基本信息的查看,具体内容会因为不同数据表而出现不同结果(以下仍为示例)
>>>print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 6 non-null int64
1 date 6 non-null datetime64[ns]
2 city 6 non-null object
3 category 6 non-null object
4 age 6 non-null int64
5 price 4 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(2), object(2)
memory usage: 416.0+ bytes
None3、查看每一列数据的格式
df.dtypes
#这里只是告知此函数的书写,具体运行要看个人需求,比如print之类用于查看每一列数据的格式
id int64
date datetime64[ns]
city object
category object
age int64
price float64
dtype: object4、某一列格式
df["id"].dtype查看指定列(个人指定,更改中括号里面的"id"为其他即可)
>>>print(df["id"].dtype)
int64
>>>print(df["id"].dtypes)
int64
>>>print(df["city"].dtype)
object
#本蒟蒻在anocoda的spyder中运行结果是dtype是否加's'并不影响结果
#啰嗦一个稍微冷的小知识:spyder3或者spyder4并不是代表spyder的版本,而是spyder所配置的环境数量5、查看空值情况
df.isnull()
此方法的返回值是判断是否为空值,是则返回True,不为空值则返回False。
运行情况如下:
>>>print(df.isnull())
id date city category age price
0 False False False False False False
1 False False False False False True
2 False False False False False False
3 False False False False False False
4 False False False False False True
5 False False False False False False
#为了方便大家理解,我附上原数据表
id date city category age price
0 1001 2013-01-02 Beijing 100-A 23 1200.0
1 1002 2013-01-03 SH 100-B 44 NaN
2 1003 2013-01-04 guangzhou 110-A 54 2133.0
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0
4 1005 2013-01-06 shanghai 210-A 34 NaN
5 1006 2013-01-07 BEIJING 130-F 32 4432.06、查看某一列空值
df['B'].isnull()
这里是查看指定列(个人指定,更改中括号里面的"B"为其他即可)
>>>print(df["id"].isnull())
0 False
1 False
2 False
3 False
4 False
5 False
Name: id, dtype: bool
>>>print(df["city"].isnull())
0 False
1 True
2 False
3 False
4 True
5 False
Name: price, dtype: bool7、查看某一列的唯一值
df['B'].unique()
根据本蒟蒻的测试,该方法的效果是返回一个列表,内容是去重之后的集合。
>>>print(df['age'].unique())
[23 44 54 32 34]
#原表中,age一列的内容是
age
0 23
1 44
2 54
3 32
4 34
5 328、查看数据表的值
df.values
此方法为查看所有值
>>>print(df.values)
[[1001 Timestamp('2013-01-02 00:00:00') 'Beijing ' '100-A' 23 1200.0]
[1002 Timestamp('2013-01-03 00:00:00') 'SH' '100-B' 44 nan]
[1003 Timestamp('2013-01-04 00:00:00') ' guangzhou ' '110-A' 54 2133.0]
[1004 Timestamp('2013-01-05 00:00:00') 'Shenzhen' '110-C' 32 5433.0]
[1005 Timestamp('2013-01-06 00:00:00') 'shanghai' '210-A' 34 nan]
[1006 Timestamp('2013-01-07 00:00:00') 'BEIJING ' '130-F' 32 4432.0]]9、查看列的名称
df.columns
此方法为查看所有列的名称
>>>print(df.columns)#查看列名称
Index(['id', 'date', 'city', 'category', 'age', 'price'], dtype='object')10、查看前n行数据、后n行数据
df.head(6) #查看前5行数据(括号里面没有数字则默认5)
df.tail(6) #查看后5行数据(括号里面没有数字则默认5)根据个人需求可以更改条件,对比运行结果如下
>>>print(df.head())#查看前5行数据(括号里面没有数字则默认5)
id date city category age price
0 1001 2013-01-02 Beijing 100-A 23 1200.0
1 1002 2013-01-03 SH 100-B 44 NaN
2 1003 2013-01-04 guangzhou 110-A 54 2133.0
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0
4 1005 2013-01-06 shanghai 210-A 34 NaN
>>>print(df.head(6))#查看前5行数据(括号里面没有数字则默认5)
id date city category age price
0 1001 2013-01-02 Beijing 100-A 23 1200.0
1 1002 2013-01-03 SH 100-B 44 NaN
2 1003 2013-01-04 guangzhou 110-A 54 2133.0
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0
4 1005 2013-01-06 shanghai 210-A 34 NaN
5 1006 2013-01-07 BEIJING 130-F 32 4432.0
>>>print(df.tail())#查看后5行数据(括号里面没有数字则默认5)
id date city category age price
1 1002 2013-01-03 SH 100-B 44 NaN
2 1003 2013-01-04 guangzhou 110-A 54 2133.0
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0
4 1005 2013-01-06 shanghai 210-A 34 NaN
5 1006 2013-01-07 BEIJING 130-F 32 4432.0
>>>>>>print(df.tail(6))#查看后5行数据(括号里面没有数字则默认5)
id date city category age price
0 1001 2013-01-02 Beijing 100-A 23 1200.0
1 1002 2013-01-03 SH 100-B 44 NaN
2 1003 2013-01-04 guangzhou 110-A 54 2133.0
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0
4 1005 2013-01-06 shanghai 210-A 34 NaN
5 1006 2013-01-07 BEIJING 130-F 32 4432.0
相信大家看到这里也累了,下面有请本蒟蒻“诚哥壶”里两位老人为带来表演
有请“摩拉托斯”与“巴巴克斯”充满智慧的注视!


四、数据清洗
1、填充空值
df.fillna(value=0)
不同于我所学习的大佬的用0填充空值,事实上我通过尝试发现也可以用其他来填充。
>>>df=df.fillna(0)
>>>print(df['price'])#用数字0填充空值
0 1200.0
1 0.0
2 2133.0
3 5433.0
4 0.0
5 4432.0
Name: price, dtype: float64
>>>df=df.fillna(10)
>>>print(df['price'])#用数字10填充空值
0 1200.0
1 10.0
2 2133.0
3 5433.0
4 10.0
5 4432.0
Name: price, dtype: float64
>>>df=df.fillna('空值')
>>>print(df['price'])#用数字0填充空值
0 1200
1 空值
2 2133
3 5433
4 空值
5 4432
Name: price, dtype: object2、使用列price的均值对NaN进行填充:
df['price'].fillna(df['price'].mean())
#使用列price的均值对NaN进行填充(均值:不为空值的n项值之和,除以n。值的总个数>n)这个方法有个别小细节需要注意,所谓的均值mean,它的公式表达为:非零值之和/非零值个数。
运行结果如下
>>>print(df['price'])
0 1200.0
1 NaN
2 2133.0
3 5433.0
4 NaN
5 4432.0
Name: price, dtype: float64
>>>(1200+2133+5433+4432)/4
3288.5
>>>print(df['price'].fillna(df['price'].mean()))
0 1200.0
1 3299.5
2 2133.0
3 5433.0
4 3299.5
5 4432.0
Name: price, dtype: float643、清楚city字段的字符空格
df['city']=df['city'].map(str.strip)#去除空格,然后对齐。清楚city字段的字符空格
效果就是本蒟蒻所标识的:去除空格,然后对齐。清楚city字段的字符空格
>>>print(df['city'])
0 Beijing
1 SH
2 guangzhou
3 Shenzhen
4 shanghai
5 BEIJING
Name: city, dtype: object
>>>df['city']=df['city'].map(str.strip)
>>>print(df['city'])
0 Beijing
1 SH
2 guangzhou
3 Shenzhen
4 shanghai
5 BEIJING
Name: city, dtype: object4、大小写转换
df['city']=df['city'].str.lower()
df['city']=df['city'].str.upper()大小写转换,upper为转换为全部大写,lower为全部转换为小写。
>>>print(df['city'])
0 Beijing
1 SH
2 guangzhou
3 Shenzhen
4 shanghai
5 BEIJING
Name: city, dtype: object
>>>df['city']=df['city'].str.lower()
>>>print(df['city'])
0 beijing
1 sh
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: object
>>>df['city']=df['city'].str.upper()
>>>print(df['city'])
0 BEIJING
1 SH
2 GUANGZHOU
3 SHENZHEN
4 SHANGHAI
5 BEIJING
Name: city, dtype: object5、更改数据格式
df['price'].astype('int')
特别提醒:在更改数据格式之前一定记得查阅此数据内容!比如此处的将price所在列更改为'int'格式,但是原数据中的nan是空值,无法转换,会报错!所以联系第一步操作,用“0”来填充空值即可。
>>>df=df.fillna(0)
>>>print(df['price'])
0 1200.0
1 0.0
2 2133.0
3 5433.0
4 0.0
5 4432.0
Name: price, dtype: float64
>>>print(df['price'].astype('int'))
0 1200
1 0
2 2133
3 5433
4 0
5 4432
Name: price, dtype: int326、更改列名称
df.rename(columns={'category': 'category-size'})
运行效果如下
>>>print(df.rename(columns={'category': 'category-size'}))#更改列名称
id date city category-size age price
0 1001 2013-01-02 Beijing 100-A 23 1200.0
1 1002 2013-01-03 SH 100-B 44 NaN
2 1003 2013-01-04 guangzhou 110-A 54 2133.0
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0
4 1005 2013-01-06 shanghai 210-A 34 NaN
5 1006 2013-01-07 BEIJING 130-F 32 4432.07、删除后/先出现的重复值
df['city'].drop_duplicates()#删除后出现的重复值
df['city'].drop_duplicates(keep='last')#删除先出现的重复值运行效果如下
>>>df['city']=df['city'].map(str.strip).str.lower()#还记得这几个方法是什么意思吗?不记得的翻回去再看
>>>print(df['city'])
0 beijing
1 sh
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: object
>>>print(df['city'].drop_duplicates())#删除后出现的重复值
0 beijing
1 sh
2 guangzhou
3 shenzhen
4 shanghai
Name: city, dtype: object
>>>print(df['city'].drop_duplicates(keep='last'))#删除先出现的重复值
1 sh
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: object8、数据替换
df['city'].replace('sh', 'shanghai')
这个非常简洁易懂,我们看一下效果就行
>>>print(df['city'].replace('sh', 'shanghai'))#数据替换
0 beijing
1 shanghai
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: object学到这里,家妻不忍大家辛苦,给大家表演一个 “大家龟秀”

什么?想看好看的?那不行,吾恐各位有枭雄之姿,家妻与吾只求一处安隅[手动滑稽]
五、数据处理
重新给出一个实例来讲解
>>>df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male','female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y',],
"m-point":[10,12,20,40,40,40,30,20]})
>>>print(df1)
id gender pay m-point
0 1001 male Y 10
1 1002 female N 12
2 1003 male Y 20
3 1004 female Y 40
4 1005 male N 40
5 1006 female Y 40
6 1007 male N 30
7 1008 female Y 201、数据表合并
(1)merge
在这里,本蒟蒻为了理解merge,又拜读了一位大佬的文章,链接在此,大家随意。
本蒟蒻也就在这里给大家讲讲我的理解,首先下述参数都会是用得到的。


本蒟蒻略做改动,有了以下代码和效果展示
>>>d1=pd.DataFrame({'key':list('abcdef'),'data1':range(6)})
>>>print(d1)
key data1
0 a 0
1 b 1
2 c 2
3 d 3
4 e 4
5 f 5
>>>d2=pd.DataFrame({'key':['a','b','c','d'],'data2':range(3,7)})
>>>print(d2)
key data2
0 a 3
1 b 4
2 c 5
3 d 6
>>>print(pd.merge(d1,d2))#默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于on=‘key’。
key data1 data2
0 a 0 3
1 b 1 4
2 c 2 5
3 d 3 6也就是说,当合并两个表格的时候,如果不添加任何其他参数说明,默认为inner。即关键词key有共同之处的才会有结果(可以理解为交集,比如d1和d2中key都有a,b,c,d,而d2没有e,f,所以合并表中只有a,b,c,d)当然,也允许表格的key列中出现重复项,在合并的时候不会删去改动,详见下图。
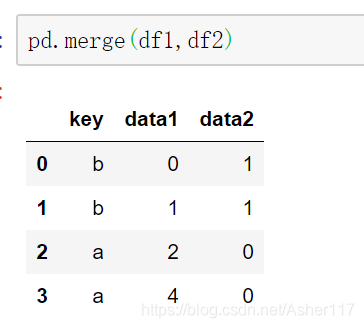
当两边合并字段不同时,可以使用left_on和right_on参数设置合并字段。当然这里合并字段都是key所以left_on和right_on参数值都是key。
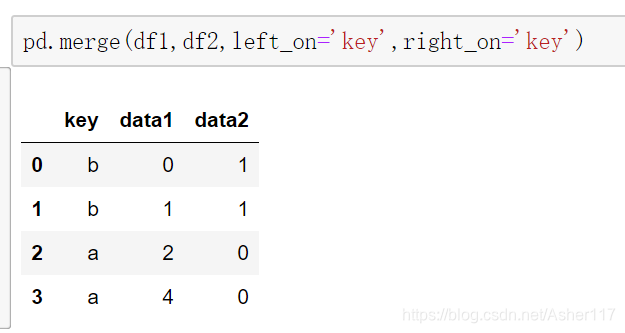
肯定有朋友会好奇,如果这里不用key会是什么结果?
>>>print(pd.merge(d1,d2,left_on='data1',right_on='data2'))
key_x data1 key_y data2
0 d 3 a 3
1 e 4 b 4
2 f 5 c 5这里将'data2'改为True也会有同样效果。相信聪明的朋友也猜到了,合并的关键词所在列在不作how的注明的条件下,要满足一个基本的要求:有相同的数值,否则会报错(这就是交集的理解,空集肯定不行鸭!)
另外顺道说一下,上面的key_x与key_y的x和y是因为两个表格中的key重名了,所以生成的后缀。就像你生活中在电脑桌面建立一个文本叫“学习资料”,再建立一个新的文本,也叫“学习资料”,但是你命名后回车,它会自动改为“学习资料(1)”。同样的道理,文本可以重命名,这个地方也可以重命名!(好吧,是加后缀来区分)
>>>print(pd.merge(d1,d2,left_on='data1',right_index=True,suffixes=('A','B')))
keyA data1 keyB data2
0 a 0 a 3
1 b 1 b 4
2 c 2 c 5
3 d 3 d 6既然有交集,那按照数学思维,肯定也有并集。没错!那就是outer!
merge的连接方式主要包括inner(内连接)、outer(外链接)、left(左连接)、right(右连接)。当采用outer外连接时,会取并集,并用NaN填充。
>>>print(pd.merge(d1,d2,how='outer',left_on='data1',right_index=True,suffixes=('A','B')))
keyA data1 keyB data2
0 a 0 a 3.0
1 b 1 b 4.0
2 c 2 c 5.0
3 d 3 d 6.0
4 e 4 NaN NaN
5 f 5 NaN NaN(2)append
result = df1.append(df2)
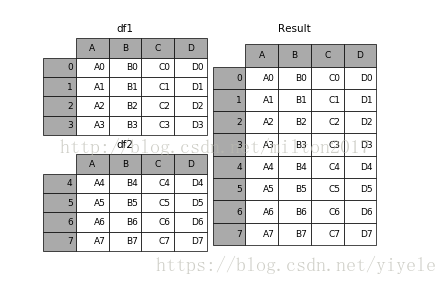
这里我同样也有一份查阅资料的链接,大家自便。
append可以添加的格式不少,其中一个就是字典
>>>import pandas as pd
>>>d1=pd.DataFrame({'key':list('abcdef'),'data1':range(6)})
>>>data=pd.DataFrame()
>>>print(data)
Empty DataFrame
Columns: []
Index: []
>>>a={"x":1,"y":2}
>>>data=data.append(a,ignore_index=True)
>>>print(data)
x y
0 1.0 2.0
>>>data=data.append(d1,ignore_index=True)
>>>print(data)
x y key data1
0 1.0 2.0 NaN NaN
1 NaN NaN a 0.0
2 NaN NaN b 1.0
3 NaN NaN c 2.0
4 NaN NaN d 3.0
5 NaN NaN e 4.0
6 NaN NaN f 5.0ignore_index=True在添加字典的时候要有,不然会报错,但是非字典的情况下也有特殊情况(就是多次使用append会出现相同index,然后报错),建议养成习惯,敲上这句代码保命。
添加list就直接添加,没什么大问题的。可能需要注意的就是list的维度问题:一维列二维行,三维列表作一空。
>>>data = pd.DataFrame()
>>>a = [[[1,2,3]]]
>>>data = data.append(a)
>>>print(data)
0
0 [1, 2, 3](3)join
在小蒟蒻查阅了一些资料之后发现其实掌握了merge就可以了,join和merge是十分相似。在这里不作过多赘述,大佬链接,大家随意(其实我写不动了,这个大家也容易看懂)
(4)concat
细心的朋友也发现了,这是写merge那篇大佬的另一篇文章,作为参考方便理解。
2、设置索引列
df_inner=df_inner.set_index('id')
#帮助大家回忆这两个数据表
>>>df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male','female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y',],
"m-point":[10,12,20,40,40,40,30,20]})
>>>print(df1)
id gender pay m-point
0 1001 male Y 10
1 1002 female N 12
2 1003 male Y 20
3 1004 female Y 40
4 1005 male N 40
5 1006 female Y 40
6 1007 male N 30
7 1008 female Y 20
>>>print(df)
id date city category age price
0 1001 2013-01-02 Beijing 100-A 23 1200.0
1 1002 2013-01-03 SH 100-B 44 NaN
2 1003 2013-01-04 guangzhou 110-A 54 2133.0
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0
4 1005 2013-01-06 shanghai 210-A 34 NaN
5 1006 2013-01-07 BEIJING 130-F 32 4432.0
>>>df_inner=pd.merge(df,df1,how='inner') # 匹配合并,交集
>>>print(df_inner)
id date city category age price gender pay m-point
0 1001 2013-01-02 Beijing 100-A 23 1200.0 male Y 10
1 1002 2013-01-03 SH 100-B 44 NaN female N 12
2 1003 2013-01-04 guangzhou 110-A 54 2133.0 male Y 20
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0 female Y 40
4 1005 2013-01-06 shanghai 210-A 34 NaN male N 40
5 1006 2013-01-07 BEIJING 130-F 32 4432.0 female Y 40
>>>df_inner=df_inner.set_index('id')
>>>print(df_inner)
date city category age price gender pay m-point
id
1001 2013-01-02 Beijing 100-A 23 1200.0 male Y 10
1002 2013-01-03 SH 100-B 44 NaN female N 12
1003 2013-01-04 guangzhou 110-A 54 2133.0 male Y 20
1004 2013-01-05 Shenzhen 110-C 32 5433.0 female Y 40
1005 2013-01-06 shanghai 210-A 34 NaN male N 40
1006 2013-01-07 BEIJING 130-F 32 4432.0 female Y 403、按照特定列的值排序
df_inner.sort_values(by=['age'])
>>>print(df_inner.sort_values(by=['age']))
id date city category age price gender pay m-point
0 1001 2013-01-02 Beijing 100-A 23 1200.0 male Y 10
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0 female Y 40
5 1006 2013-01-07 BEIJING 130-F 32 4432.0 female Y 40
4 1005 2013-01-06 shanghai 210-A 34 NaN male N 40
1 1002 2013-01-03 SH 100-B 44 NaN female N 12
2 1003 2013-01-04 guangzhou 110-A 54 2133.0 male Y 204、按照索引列排序
df_inner.sort_index()
>>>df_inner=df_inner.set_index('age')
>>>print(df_inner)
id date city category price gender pay m-point
age
23 1001 2013-01-02 Beijing 100-A 1200.0 male Y 10
44 1002 2013-01-03 SH 100-B NaN female N 12
54 1003 2013-01-04 guangzhou 110-A 2133.0 male Y 20
32 1004 2013-01-05 Shenzhen 110-C 5433.0 female Y 40
34 1005 2013-01-06 shanghai 210-A NaN male N 40
32 1006 2013-01-07 BEIJING 130-F 4432.0 female Y 40
>>>print(df_inner.sort_index())
id date city category price gender pay m-point
age
23 1001 2013-01-02 Beijing 100-A 1200.0 male Y 10
32 1004 2013-01-05 Shenzhen 110-C 5433.0 female Y 40
32 1006 2013-01-07 BEIJING 130-F 4432.0 female Y 40
34 1005 2013-01-06 shanghai 210-A NaN male N 40
44 1002 2013-01-03 SH 100-B NaN female N 12
54 1003 2013-01-04 guangzhou 110-A 2133.0 male Y 205、如果price列的值>3000,group列显示high,否则显示low
这里就要讲一下numpy的一个小知识了,where的作用就是是否满足条件,满足就返回前一个选项的结果,不满足就返回后者。(group没有就创建)
df_inner['group'] = np.where(df_inner['price'] > 3000,'high','low')
>>>df_inner['group'] = np.where(df_inner['price'] > 3000,'high','low')
>>>print(df_inner)
id date city category ... gender pay m-point group
0 1001 2013-01-02 Beijing 100-A ... male Y 10 low
1 1002 2013-01-03 SH 100-B ... female N 12 low
2 1003 2013-01-04 guangzhou 110-A ... male Y 20 low
3 1004 2013-01-05 Shenzhen 110-C ... female Y 40 high
4 1005 2013-01-06 shanghai 210-A ... male N 40 low
5 1006 2013-01-07 BEIJING 130-F ... female Y 40 high
[6 rows x 10 columns]6、对复合多个条件的数据进行分组标记
df_inner.loc[(df_inner['city'] == 'beijing') & (df_inner['price'] >= 4000), 'sign']=1
>>>df_inner.loc[(df_inner['city'] == 'beijing') | (df_inner['price'] >= 4000), 'sign']=1
>>>print(df_inner)
id date city category ... gender pay m-point sign
0 1001 2013-01-02 Beijing 100-A ... male Y 10 NaN
1 1002 2013-01-03 SH 100-B ... female N 12 NaN
2 1003 2013-01-04 guangzhou 110-A ... male Y 20 NaN
3 1004 2013-01-05 Shenzhen 110-C ... female Y 40 1.0
4 1005 2013-01-06 shanghai 210-A ... male N 40 NaN
5 1006 2013-01-07 BEIJING 130-F ... female Y 40 1.0
[6 rows x 10 columns]学到这里,各位大佬其实一个已经对其中套路有了感觉,那么我就不赘述了,直接搬运了!
7、对category字段的值依次进行分列,并创建数据表,索引值为df_inner的索引列,列名称为category和size
pd.DataFrame((x.split('-') for x in df_inner['category']),index=df_inner.index,columns=['category','size']))
8、将完成分裂后的数据表和原df_inner数据表进行匹配
df_inner=pd.merge(df_inner,split,right_index=True, left_index=True)
六、数据提取
主要用到的三个函数:loc,iloc和ix。loc函数按标签值进行提取,iloc按位置进行提取,ix可以同时按标签和位置进行提取。
1、按索引提取单行的数值
可以通过更改括号内的数值来实现对某一行的提取。
df_inner.loc[3]>>>print(df_inner.loc[3])
id 1004
date 2013-01-05 00:00:00
city Shenzhen
category 110-C
age 32
price 5433
gender female
pay Y
m-point 40
Name: 3, dtype: object
#注意这是一行,但是以一列的形式来表示2、按索引提取区域行数值
通过更改范围即可。
df_inner.iloc[0:5]
>>>print(df_inner.iloc[0:4])
id date city category age price gender pay m-point
0 1001 2013-01-02 Beijing 100-A 23 1200.0 male Y 10
1 1002 2013-01-03 SH 100-B 44 NaN female N 12
2 1003 2013-01-04 guangzhou 110-A 54 2133.0 male Y 20
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0 female Y 403、重设索引&设置其他索引&提取选定索引数据
有操作是设置索引列,而重设就是反向操作。
注意!关于提取选定数据,如果索引为str格式,就采用['strA':'strB']的方法。如果为int格式,就必须按照常规的顺序来提取!
df_inner=df_inner.set_index('age')
df_inner.reset_index()
df_inner=df_inner.set_index('date')
df_inner[:'2013-01-04']
>>>print(df_inner)
id date city category age price gender pay m-point
0 1001 2013-01-02 Beijing 100-A 23 1200.0 male Y 10
1 1002 2013-01-03 SH 100-B 44 NaN female N 12
2 1003 2013-01-04 guangzhou 110-A 54 2133.0 male Y 20
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0 female Y 40
4 1005 2013-01-06 shanghai 210-A 34 NaN male N 40
5 1006 2013-01-07 BEIJING 130-F 32 4432.0 female Y 40
>>>df_inner=df_inner.set_index('age')
>>>print(df_inner)
id date city category price gender pay m-point
age
23 1001 2013-01-02 Beijing 100-A 1200.0 male Y 10
44 1002 2013-01-03 SH 100-B NaN female N 12
54 1003 2013-01-04 guangzhou 110-A 2133.0 male Y 20
32 1004 2013-01-05 Shenzhen 110-C 5433.0 female Y 40
34 1005 2013-01-06 shanghai 210-A NaN male N 40
32 1006 2013-01-07 BEIJING 130-F 4432.0 female Y 40
>>>print(df_inner[:'54'])
#报错
>>>print(df_inner[:3])#输出前三位
id date city category price gender pay m-point
age
23 1001 2013-01-02 Beijing 100-A 1200.0 male Y 10
44 1002 2013-01-03 SH 100-B NaN female N 12
54 1003 2013-01-04 guangzhou 110-A 2133.0 male Y 20
>>>print(df_inner.reset_index())#重设索引
age id date city category price gender pay m-point
0 23 1001 2013-01-02 Beijing 100-A 1200.0 male Y 10
1 44 1002 2013-01-03 SH 100-B NaN female N 12
2 54 1003 2013-01-04 guangzhou 110-A 2133.0 male Y 20
3 32 1004 2013-01-05 Shenzhen 110-C 5433.0 female Y 40
4 34 1005 2013-01-06 shanghai 210-A NaN male N 40
5 32 1006 2013-01-07 BEIJING 130-F 4432.0 female Y 40
>>>df_inner=df_inner.set_index('category')
>>>print(df_inner)
id date city price gender pay m-point
category
100-A 1001 2013-01-02 Beijing 1200.0 male Y 10
100-B 1002 2013-01-03 SH NaN female N 12
110-A 1003 2013-01-04 guangzhou 2133.0 male Y 20
110-C 1004 2013-01-05 Shenzhen 5433.0 female Y 40
210-A 1005 2013-01-06 shanghai NaN male N 40
130-F 1006 2013-01-07 BEIJING 4432.0 female Y 40
>>>print(df_inner[:'110-C'])
id date city price gender pay m-point
category
100-A 1001 2013-01-02 Beijing 1200.0 male Y 10
100-B 1002 2013-01-03 SH NaN female N 12
110-A 1003 2013-01-04 guangzhou 2133.0 male Y 20
110-C 1004 2013-01-05 Shenzhen 5433.0 female Y 40
>>>df_inner=df_inner.set_index('date')
>>>print(df_inner[:'2013-01-04'])
id city category age price gender pay m-point
date
2013-01-02 1001 Beijing 100-A 23 1200.0 male Y 10
2013-01-03 1002 SH 100-B 44 NaN female N 12
2013-01-04 1003 guangzhou 110-A 54 2133.0 male Y 20以下几条易于理解,搬运给大家看即可~
4、使用iloc按位置区域提取数据
df_inner.iloc[:3,:2] #冒号前后的数字不再是索引的标签名称,而是数据所在的位置,从0开始,前三行,前两列。
5、适应iloc按位置单独提起数据
df_inner.iloc[[0,2,5],[4,5]] #提取第0、2、5行,4、5列
6、使用ix按索引标签和位置混合提取数据
df_inner.ix[:'2013-01-03',:4] #2013-01-03号之前,前四列数据
7、判断city列的值是否为北京
df_inner['city'].isin(['beijing'])
8、判断city列里是否包含beijing和shanghai,然后将符合条件的数据提取出来
df_inner.loc[df_inner['city'].isin(['beijing','shanghai'])]
9、提取前三个字符,并生成数据表
pd.DataFrame(category.str[:3])
七、数据筛选
使用与、或、非三个条件配合大于、小于、等于对数据进行筛选,并进行计数和求和。
1、使用“与”、“或”、“非”进行筛选
关于这三种逻辑判断及符号,作为一个之前一直学python的蒟蒻,确实比较陌生,但是当小蒟蒻有学习C语言的经历之后发现这三者实在是亲切~~~所以大家见怪不怪,记住就好。
df_inner.loc[(df_inner['age'] > 25) & (df_inner['city'] == 'beijing'), ['id','city','age','category','gender']]
#“与”=> &
df_inner.loc[(df_inner['age'] > 25) | (df_inner['city'] == 'beijing'), ['id','city','age','category','gender']].sort(['age'])
#“或”=> |
df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id'])
#“非”=> !=2、对筛选后的数据按city列进行计数
df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id']).city.count()
3、使用query函数进行筛选
df_inner.query('city == ["beijing", "shanghai"]')
>>>print(df_inner.query('city == ["beijing", "shanghai"]'))
id date city category age price gender pay m-point
4 1005 2013-01-06 shanghai 210-A 34 NaN male N 404、对筛选后的结果按prince进行求和
df_inner.query('city == ["beijing", "shanghai"]').price.sum()
>>>print(df_inner.query('city == ["beijing", "shanghai"]').price.sum())
0.0
#因为是空值所以和为0八、数据汇总
主要函数是groupby和pivote_table
1、对所有的列进行计数汇总
df_inner.groupby('city').count()
具体的理解不用我多说,大家看下面的对比就能明白 。
>>>print(df_inner.groupby('city').count())
id date category age price gender pay m-point
city
guangzhou 1 1 1 1 1 1 1 1
BEIJING 1 1 1 1 1 1 1 1
Beijing 1 1 1 1 1 1 1 1
SH 1 1 1 1 0 1 1 1
Shenzhen 1 1 1 1 1 1 1 1
shanghai 1 1 1 1 0 1 1 1
>>>print(df_inner.groupby('age').count())
id date city category price gender pay m-point
age
23 1 1 1 1 1 1 1 1
32 2 2 2 2 2 2 2 2
34 1 1 1 1 0 1 1 1
44 1 1 1 1 0 1 1 1
54 1 1 1 1 1 1 1 12、按年龄age对id字段进行计数
df_inner.groupby('age')['id'].count()
>>>print(df_inner.groupby('age')['id'].count())
age
23 1
32 2
34 1
44 1
54 1
Name: id, dtype: int643、对两个字段进行汇总计数
df_inner.groupby(['city','age'])['id'].count()
>>>print(df_inner.groupby(['city','age'])['id'].count())
city age
guangzhou 54 1
BEIJING 32 1
Beijing 23 1
SH 44 1
Shenzhen 32 1
shanghai 34 1
Name: id, dtype: int644、对city字段进行汇总,并分别计算prince的合计和均值
df_inner.groupby('city')['price'].agg([len,np.sum, np.mean])
>>>print(df_inner.groupby('city')['price'].agg([len,np.sum, np.mean]))
len sum mean
city
guangzhou 1.0 2133.0 2133.0
BEIJING 1.0 4432.0 4432.0
Beijing 1.0 1200.0 1200.0
SH 1.0 0.0 NaN
Shenzhen 1.0 5433.0 5433.0
shanghai 1.0 0.0 NaN九、数据统计
1、简单的数据采样(随机)
df_inner.sample(n=3)
>>>print(df_inner.sample(n=3))
id date city category age price gender pay m-point
5 1006 2013-01-07 BEIJING 130-F 32 4432.0 female Y 40
3 1004 2013-01-05 Shenzhen 110-C 32 5433.0 female Y 40
0 1001 2013-01-02 Beijing 100-A 23 1200.0 male Y 10
>>>print(df_inner.sample(n=3))
id date city category age price gender pay m-point
4 1005 2013-01-06 shanghai 210-A 34 NaN male N 40
1 1002 2013-01-03 SH 100-B 44 NaN female N 12
5 1006 2013-01-07 BEIJING 130-F 32 4432.0 female Y 402、手动设置采样权重
weights = [0, 0, 0, 0, 0.5, 0.5]
df_inner.sample(n=2, weights=weights)
>>>weights = [0, 0, 0, 0, 0.5, 0.5]
>>>print(df_inner.sample(n=2, weights=weights))
id date city category age price gender pay m-point
5 1006 2013-01-07 BEIJING 130-F 32 4432.0 female Y 40
4 1005 2013-01-06 shanghai 210-A 34 NaN male N 403、采样后不放回
df_inner.sample(n=6, replace=False)
4、采样后放回
df_inner.sample(n=6, replace=True)
往下是统计学相关内容
(本蒟蒻学过,但是又去翻教材解释太麻烦,就不多说了)
5、 数据表描述性统计
df_inner.describe().round(2).T #round函数设置显示小数位,T表示转置
>>>print(df_inner.describe().round(2))
id age price m-point
count 6.00 6.00 4.00 6.00
mean 1003.50 36.50 3299.50 27.00
std 1.87 10.88 1966.64 14.63
min 1001.00 23.00 1200.00 10.00
25% 1002.25 32.00 1899.75 14.00
50% 1003.50 33.00 3282.50 30.00
75% 1004.75 41.50 4682.25 40.00
max 1006.00 54.00 5433.00 40.00
>>>print(df_inner.describe().round(2).T) #round函数设置显示小数位,T表示转置
count mean std min 25% 50% 75% max
id 6.0 1003.5 1.87 1001.0 1002.25 1003.5 1004.75 1006.0
age 6.0 36.5 10.88 23.0 32.00 33.0 41.50 54.0
price 4.0 3299.5 1966.64 1200.0 1899.75 3282.5 4682.25 5433.0
m-point 6.0 27.0 14.63 10.0 14.00 30.0 40.00 40.06、计算列的标准差
df_inner['price'].std()
7、计算两个字段间的协方差
df_inner['price'].cov(df_inner['m-point'])
8、数据表中所有字段间的协方差
df_inner.cov()
>>>print(df_inner.cov())
id age price m-point
id 3.500000 -0.700000 3.243333e+03 25.400000
age -0.700000 118.300000 -2.255833e+03 -31.000000
price 3243.333333 -2255.833333 3.867667e+06 28771.666667
m-point 25.400000 -31.000000 2.877167e+04 214.0000009、两个字段的相关性分析
df_inner['price'].corr(df_inner['m-point']) #相关系数在-1到1之间,接近1为正相关,接近-1为负相关,0为不相关
10、数据表的相关性分析
df_inner.corr()
十、数据输出
下面都看得懂吧~
1、写入Excel
df_inner.to_excel('excel_to_python.xlsx', sheet_name='bluewhale_cc')
2、写入到CSV
df_inner.to_csv('excel_to_python.csv')
十一、最后一些话
最后感谢大家可以看到这里,本文内容就此结束了。下面是蒟蒻得到转载授权的截图,和代码汇总,嘿嘿~

# -*- coding: utf-8 -*-
"""
Created on Tue Jul 20 16:27:43 2021
@author: 86133
"""
import numpy as np
import pandas as pd
df = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
"date":pd.date_range('20130102', periods=6),
"city":['Beijing ', 'SH', ' guangzhou ', 'Shenzhen', 'shanghai', 'BEIJING '],
"age":[23,44,54,32,34,32],
"category":['100-A','100-B','110-A','110-C','210-A','130-F'],
"price":[1200,np.nan,2133,5433,np.nan,4432]},
columns =['id','date','city','category','age','price'])
#print(df)
'''
print(df.shape)#表示维度,例如(6,6)表示一个6*6的表格
print(df.info())#数据表基本信息(维度、列名称、数据格式、所占空间等)
print(df.dtypes)#每一列数据的格式
print(df["city"].dtypes)#某一列格式
print(df.isnull())#查看整个表的空值
print(df["price"].isnull())#查看某一列的空值
print(df['age'])
print(df['age'].unique())#查看某一列的唯一值
print(df.values)#查看数据表的值
print(df.columns)#查看列名称
print(df.head())#查看前5行数据(括号里面没有数字则默认5)
print(df.tail())#查看后5行数据(括号里面没有数字则默认5)
df=df.fillna('空值')
print(df['price'])#用数字0填充空值
print(df['price'])
print(df['price'].fillna(df['price'].mean()))
#使用列prince的均值对NA进行填充(均值:不为空值的n项值之和,除以n。值的总个数>n)
print(df['city'])
df['city']=df['city'].map(str.strip)#去除空格,然后对齐。清楚city字段的字符空格
print(df['city'])
print(df['city'])
df['city']=df['city'].str.upper()#大小写转换,upper为转换为全部大写,lower为全部转换为小写
print(df['city'])
df=df.fillna(0)
print(df['price'])
print(df['price'].astype('int'))#更改数据格式,原来为float.
print(df.rename(columns={'category': 'category-size'}))#更改列名称
df['city']=df['city'].map(str.strip).str.lower()
print(df['city'])
print(df['city'].drop_duplicates())#删除后出现的重复值
print(df['city'].drop_duplicates(keep='last'))#删除先出现的重复值
df['city']=df['city'].map(str.strip).str.lower()
print(df['city'].replace('sh', 'shanghai'))#数据替换
'''
df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male','female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y',],
"m-point":[10,12,20,40,40,40,30,20]})
#print(df1)
#print(df)
df_inner=pd.merge(df,df1,how='inner') # 匹配合并,交集
df_left=pd.merge(df,df1,how='left') #
df_right=pd.merge(df,df1,how='right')
df_outer=pd.merge(df,df1,how='outer') #并集
#print(df_inner)
'''
result = df1.append(df2)#上下添加
result = left.join(right, on='key')#左右添加
'''
'''
d1=pd.DataFrame({'key':list('abcdef'),'data1':range(6)})
#print(d1)
d2=pd.DataFrame({'key':['a','b','c','d'],'data2':range(3,7)})
#print(d2)
#print(pd.merge(d1,d2))
#print(pd.merge(d1,d2,left_on='data1',right_on='data2'))
print(pd.merge(d1,d2,how='outer',left_on='data1',right_index=True,suffixes=('A','B')))
'''
'''
d1=pd.DataFrame({'key':list('abcdef'),'data1':range(6)})
data=pd.DataFrame()
print(data)
a={"x":1,"y":2}
data=data.append(a,ignore_index=True)
print(data)
data=data.append(d1,ignore_index=True)
print(data)
'''
'''
df_inner=df_inner.set_index('id')
print(df_inner)
print(df_inner.sort_values(by=['age']))
df_inner=df_inner.set_index('age')
print(df_inner)
print(df_inner.sort_index())
df_inner['group'] = np.where(df_inner['price'] > 3000,'high','low')
print(df_inner)
df_inner.loc[(df_inner['city'] == 'beijing') | (df_inner['price'] >= 4000), 'sign']=1
print(df_inner)
print(pd.DataFrame((x.split('-') for x in df_inner['category']),index=df_inner.index,columns=['category','size']))
print(df_inner)
split=pd.DataFrame((x.split('-') for x in df_inner['category']),index=df_inner.index,columns=['category_0','size'])
df_inner=pd.merge(df_inner,split,right_index=True, left_index=True)
print(df_inner)
print(df_inner.loc[3])
print(df_inner.iloc[0:4])
print(df_inner)
df_inner=df_inner.set_index('age')
print(df_inner[:3])
df_inner=df_inner.set_index('category')
print(df_inner)
#print(df_inner.reset_index())#重设索引
print(df_inner[:'110-C'])
df_inner=df_inner.set_index('date')
print(df_inner)
print(df_inner[:'2013-01-04'])
print(df_inner['city'].isin(['shanghai']))
print(df_inner.loc[df_inner['city'].isin(['Beijing ','shanghai'])])
print(df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id']).city.count())
print(df_inner.query('city == ["beijing", "shanghai"]'))
print(df_inner.query('city == ["beijing", "shanghai"]').price.sum())
print(df_inner.groupby('age').count())
print(df_inner.groupby('age')['id'].count())
print(df_inner.groupby(['city','age'])['id'].count())
print(df_inner.groupby('city')['price'].agg([len,np.sum, np.mean]))
print(df_inner.sample(n=3))
weights = [0, 0, 0, 0, 0.5, 0.5]
print(df_inner.sample(n=2, weights=weights))
print(df_inner)
print(df_inner.sample(n=3, replace=False))
print(df_inner)
print(df_inner.sample(n=3, replace=True))
print(df_inner)
print(df_inner.describe().round(2).T) #round函数设置显示小数位,T表示转置
'''
print(df_inner.cov())














 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









