






 本文探讨了如何通过分析ANSI码和UTF-8编码的特征,识别文本类型并精确统计不同字符,包括英文、数字、空格及汉字的数量,以量化文本内容特性。
本文探讨了如何通过分析ANSI码和UTF-8编码的特征,识别文本类型并精确统计不同字符,包括英文、数字、空格及汉字的数量,以量化文本内容特性。
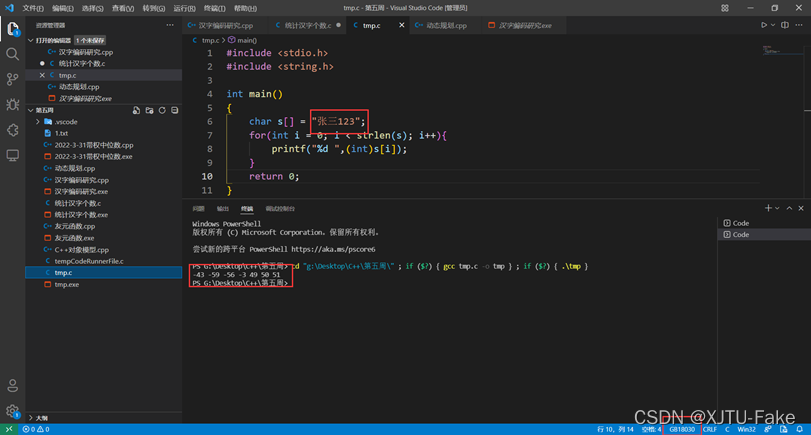
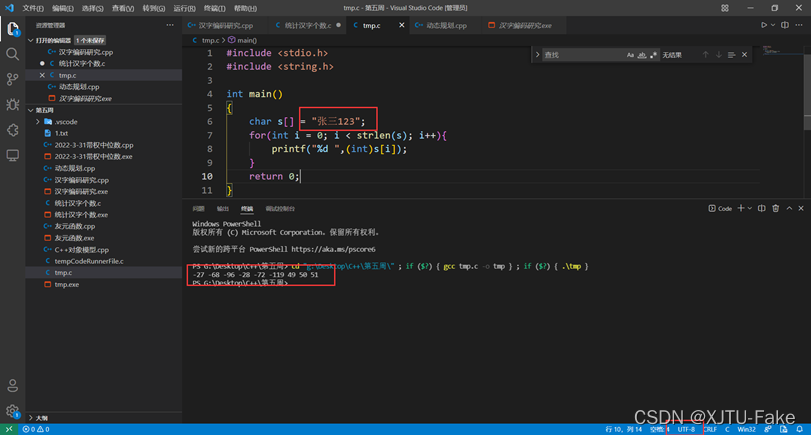
对于文本文件,常见的编码格式有ANSI码(无格式,但对于中文为GB2312,每个汉字三个字节),UTF-8(每个汉字2个字节),unicode等。现在主要分析ANSI码和UTF-8编码方式下,如何统计各种字符统计问题。
先进行分析:
ANSI编码方式
UTF-8编码方式
从上面可以看出ACSII码的编码方式,一个汉字2个字节,并且输出他的补码后两位均为负数;UTF-8的编码方式,一个汉字3个字节,输出其补码三位数字均为负数。依据上面的结论,就可以对汉字进行统计,先判断文本的编码方式,然后运用相应的方法进行计算即可。
ANSI码编码方式
UTF-8码编码方式
//code(ANSI)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX 20
typedef struct Statistics{
int total;
int upper;
int lower;
int number;
int blank;
int character;
int other;
}Statis;
int main()
{
Statis a;
/*初始化*/
a.blank = 0;
a.character = 0;
a.lower = 0;
a.number = 0;
a.other = 0;
a.total = 0;
a.upper = 0;
FILE* fp = NULL;
printf("请输入文件名:\n");
char filename[MAX],ch;
scanf("%s",filename);
if ((fp = fopen(filename, "r")) == NULL) {
perror("the file fail to read");
system("pause");//暂停显示
exit(1);
}
ch = fgetc(fp);
int tmp = 0;
while(!feof(fp)){
//printf("%d ",ch);
a.total++;
if(ch >= 'A' && ch <= 'Z'){
a.upper++;
}else if(ch >= 'a' && ch <= 'z'){
a.lower++;
}else if(ch >= '0' && ch <= '9'){
a.number++;
}else if(ch == ' '){
a.blank++;
}else if((int)ch<0){
tmp++;
}else{
a.other++;
}
ch = fgetc(fp);
}
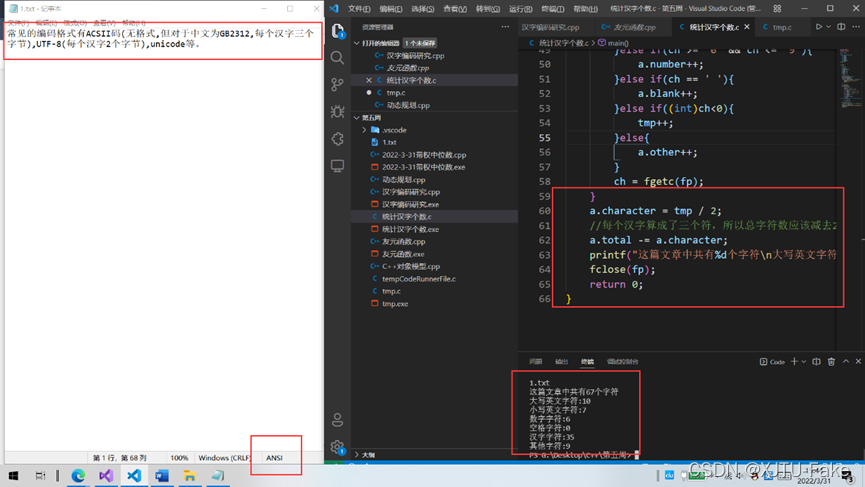
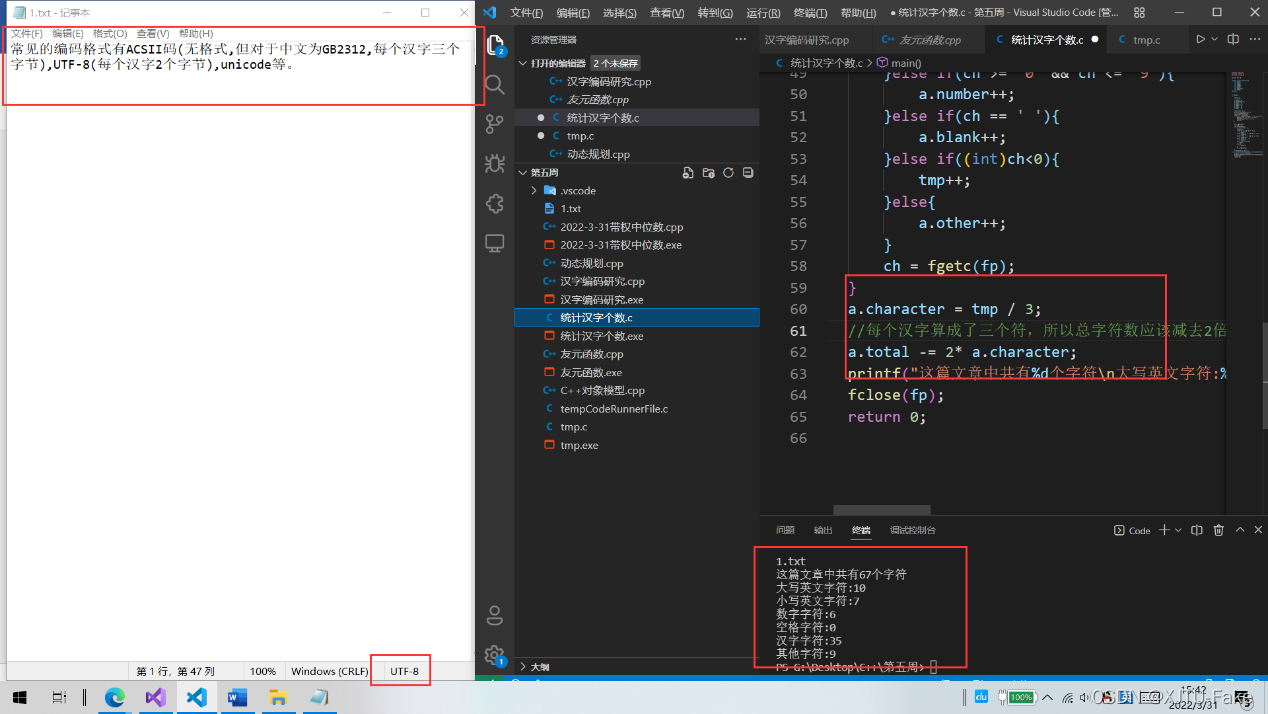
a.character = tmp / 2;
//ANSI:每个汉字算成了两个个符,所以总字符数应该减去字符个数
//UTF-8:每个汉字算成了三个个符,所以总字符数应该减去2*字符个数
a.total -= a.character;
printf("这篇文章中共有%d个字符\n大写英文字符:%d\n小写英文字符:%d\n数字字符:%d\n空格字符:%d\n汉字字符:%d\n其他字符:%d",a.total, a.upper, a.lower, a.number, a.blank, a.character, a.other);
fclose(fp);
return 0;
}


















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











