






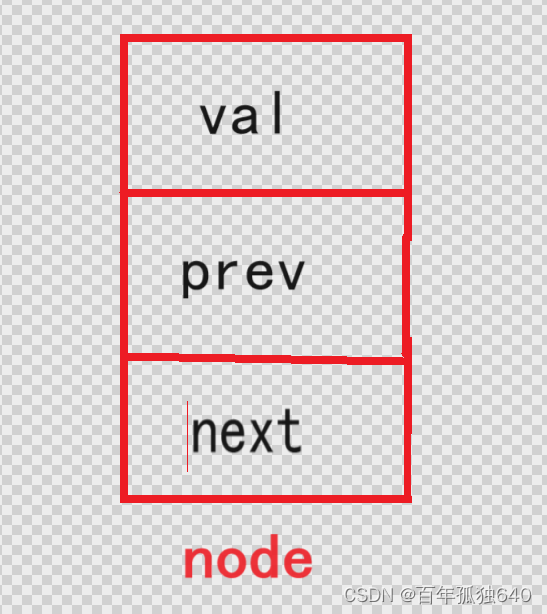
无头双向链表
无头双向链表是一种特殊的双向链表,它没有专门的头节点,链表的第一个节点即为实际数据节点,并且具有指向链表中前一个节点和后一个节点的引用。在实现时,对于第一个节点,其"前驱"指针通常会设置为 null 或者指向链表的最后一个节点,形成一个闭环(如果需要)。
基本结构:
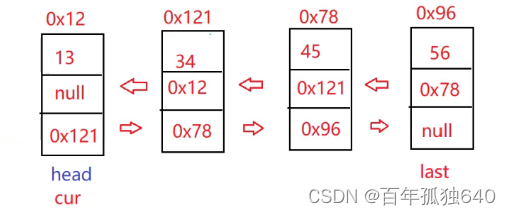
直奔主题:拆解双向链表
1.根据上图所示链表 定义链表结构以及构造方法初始化工作
static class listnode{
public int val;
private listnode next;
private listnode prev;
public listnode(int val) {
this.val = val;
}
}
public listnode head;
public listnode last;//双向链表除了有头还有尾部
2.头插法:头部插入新的元素节点
图解: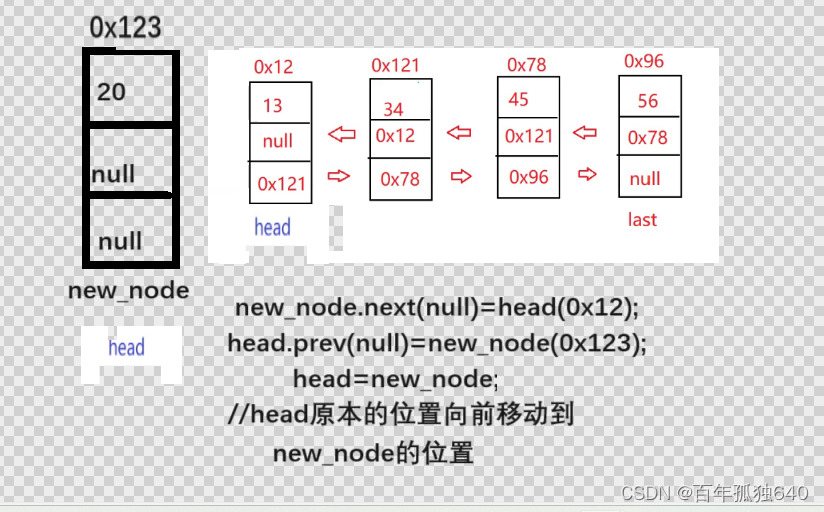
public void addFirst(int data) {
//头插法 插入节点
listnode new_node=new listnode(data);//实例化新的要插入的节点
if(head==null){
head=new_node;
last=new_node;
}else {
new_node.next = head;
head.prev = new_node;
head = new_node;
}
}
3.与之对应的尾插法:尾部插入
图解: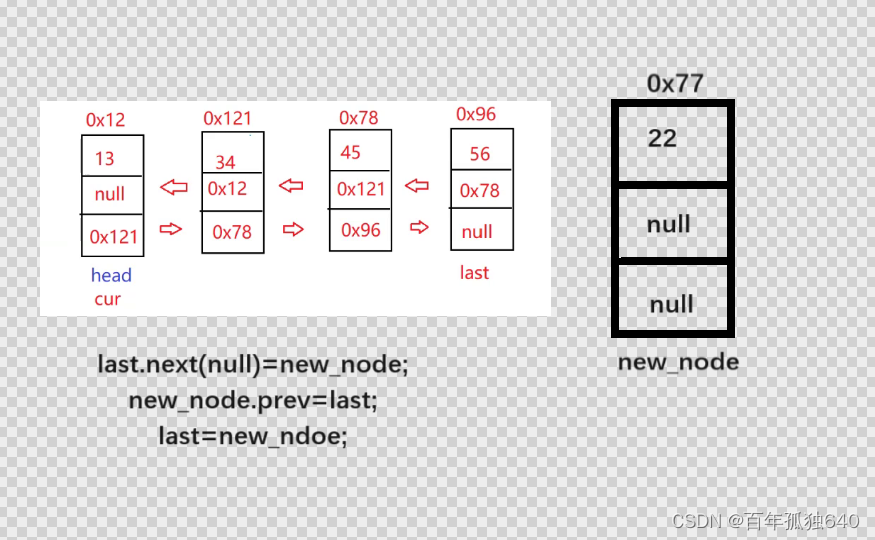
public void addLast(int data) {
listnode new_node=new listnode(data);
if(head==null){
head=new_node;
last=new_node;
}//使用last
listnode cur=this.last;
last.next=new_node;
new_node.prev=last;
last=new_node;
}
4.根据index索引位置插入对应的data:
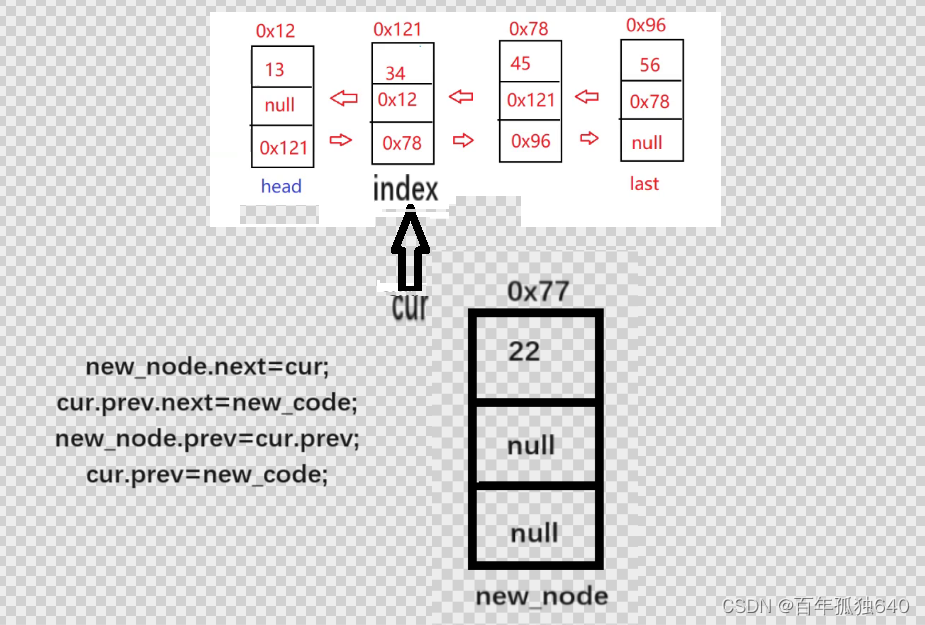
//首先要找到index的索引位置 定义一个私有方法 找到后返回当前节点cur
private listnode find_index(int index){
listnode cur=this.head;
while(index!=0){
cur=cur.next;
index--;
}
return cur;
}
public void addIndex(int index, int data) {
//检查index索引的合法性
int len=size();
if(index<0||index>len){
System.out.println("不合法");
return ;
}
if(index==len){
addLast(data);
return ;
}
if(index==0){
addFirst(data);
}
listnode cur=find_index(index);
listnode new_node=new listnode(data);
new_node.next=cur;
cur.prev.next=new_node;
new_node.prev=cur.prev;
cur.prev=new_node;
//这个过程有些绕
}
5.查找是否包含关键字key是否在单链表当中
这个很容易理解:按照循环结构一直走 遇到节点key返回true
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key) {
listnode cur=this.head;
while(cur!=null){
if(cur.val==key){
return true;
}
cur=cur.next;
}
return false;
}
6.比较难理解:移除特定的节点元素
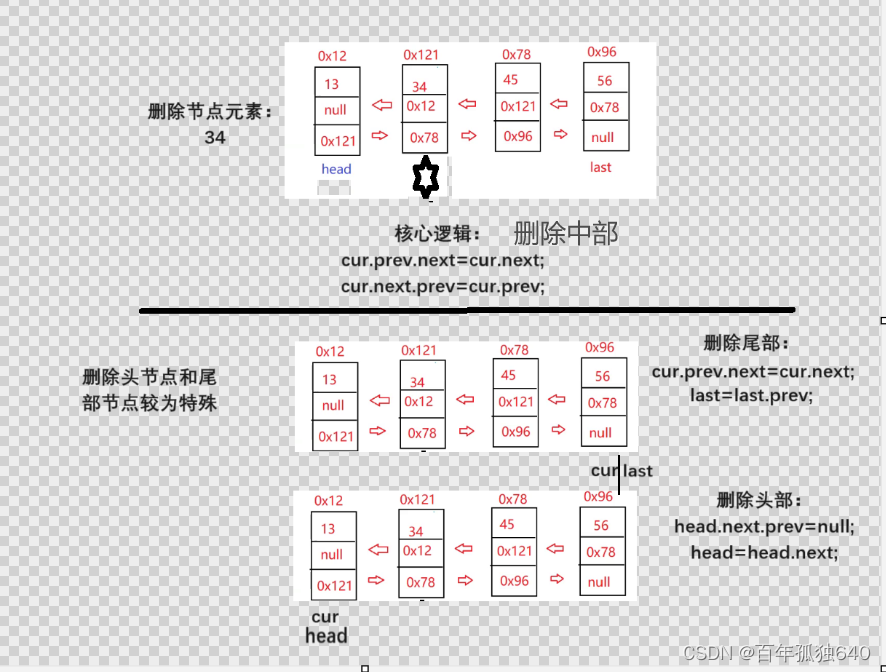
public void remove(int key) {
//移除特定的节点元素
listnode cur = this.head;
while(cur!=null) {
if (cur.val == key) {
if (cur == head) {
head = head.next;//head==null
if (head == null) {
last = null;
} else {
head.prev = null;
}
} else {
cur.prev.next = cur.next;
if (cur.next == null) {
last = last.prev;
} else {
cur.next.prev = cur.prev;
}
}
return;
}
else{
cur=cur.next;
}
}
}
7.删除全部key节点的元素
public void removeAllKey(int key) {
//移除所有的的节点元素
listnode cur = this.head;
while(cur!=null) {
if (cur.val == key) {
if (cur == head) {
head = head.next;//head==null
if (head == null) {
last = null;
} else {
head.prev = null;
}
} else {
cur.prev.next = cur.next;
if (cur.next == null) {
last = last.prev;
} else {
cur.next.prev = cur.prev;
}
}
}
cur=cur.next;
}
}
注:与删除一个key的原理相同:
在上述remove(int key)中移除结束直接return
这里无须返回直接走下一个节点持续删除有关key的节点,直到删除完毕
8.链表size();同单链表
```java
public int size() {
int count=0;
listnode cur=head;
while(cur!=null){
cur=cur.next;
count++;
}
return count;
}```
9.display();
public void display() {
listnode cur=this.head;
while(cur!=null){
System.out.println(cur.val+" ");
cur=cur.next;
}
System.out.println();
}
10.清空数据操作;
public void clear() {
listnode cur=this.head;
while(cur!=null){
listnode tmp=cur.next;
//listnode tmp=cur.next;:
//创建一个临时节点变量 tmp,并将它指向当前节点 cur 的下一个节点。//
//这样做的目的是为了在接下来释放当前节点时,保持对链表其余部分的访问
cur.prev=null;
//cur.prev=null;:将当前节点的前驱指针设为 null,切断该节点与其前一个节点的连接。
cur.next=null;
//cur.next=null;:将当前节点的后继指针设为 null,切断该节点与其后一个节点的连接。
cur=tmp;
}
head=null;//head=null;:将头节点引用设为 null,表示链表为空
last=null;//last=null;:将尾节点引用设为 null,同样表示链表为空。
}
11.整体代码如下:
package double_linklist;
public class doublie_list implements Ilist{
static class listnode{
public int val;
private listnode next;
private listnode prev;
public listnode(int val) {
this.val = val;
}
}
public listnode head;
public listnode last;//双向链表除了有头还有尾部
@Override
public void addFirst(int data) {
//头插法 插入节点
listnode new_node=new listnode(data);//实例化新的要插入的节点
if(head==null){
head=new_node;
last=new_node;
}else {
new_node.next = head;
head.prev = new_node;
head = new_node;
}
}
@Override
public void addLast(int data) {
listnode new_node=new listnode(data);
if(head==null){
head=new_node;
last=new_node;
}//使用last
listnode cur=this.last;
last.next=new_node;
new_node.prev=last;
last=new_node;
}
@Override
public void addIndex(int index, int data) {
int len=size();
if(index<0||index>len){
System.out.println("不合法");
return ;
}
if(index==len){
addLast(data);
return ;
}
if(index==0){
addFirst(data);
}
listnode cur=find_index(index);
listnode new_node=new listnode(data);
new_node.next=cur;
cur.prev.next=new_node;
new_node.prev=cur.prev;
cur.prev=new_node;
//这个过程有些绕
}
//定义新的方法找到index 的位置
private listnode find_index(int index){
listnode cur=this.head;
while(index!=0){
cur=cur.next;
index--;
}
return cur;
}
//查找是否包含关键字key是否在单链表当中
@Override
public boolean contains(int key) {
listnode cur=this.head;
while(cur!=null){
if(cur.val==key){
return true;
}
cur=cur.next;
}
return false;
}
@Override
public void remove(int key) {
//移除特定的节点元素
listnode cur = this.head;
while(cur!=null) {
if (cur.val == key) {
if (cur == head) {
head = head.next;//head==null
if (head == null) {
last = null;
} else {
head.prev = null;
}
} else {
cur.prev.next = cur.next;
if (cur.next == null) {
last = last.prev;
} else {
cur.next.prev = cur.prev;
}
}
return;
}
else{
cur=cur.next;
}
}
}
@Override
public void removeAllKey(int key) {
//移除所有的的节点元素
listnode cur = this.head;
while(cur!=null) {
if (cur.val == key) {
if (cur == head) {
head = head.next;//head==null
if (head == null) {
last = null;
} else {
head.prev = null;
}
} else {
cur.prev.next = cur.next;
if (cur.next == null) {
last = last.prev;
} else {
cur.next.prev = cur.prev;
}
}
}
cur=cur.next;
}
}
@Override
public int size() {
int count=0;
listnode cur=head;
while(cur!=null){
cur=cur.next;
count++;
}
return count;
}
@Override
public void display() {
listnode cur=this.head;
while(cur!=null){
System.out.println(cur.val+" ");
cur=cur.next;
}
System.out.println();
}
@Override
public void clear() {
listnode cur=this.head;
while(cur!=null){
listnode tmp=cur.next;
cur.prev=null;
cur.next=null;
cur=tmp;
}
head=null;
last=null;
}
}
package double_linklist;
public interface Ilist {
//无头双向链表
//头插法
public void addFirst(int data);
//尾插法
public void addLast(int data);
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index,int data);
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key);
//删除第一次出现关键字为key的节点
public void remove(int key);
//删除所有值为key的节点
public void removeAllKey(int key);
//得到单链表的长度
public int size();
public void display();
public void clear();
package double_linklist;
public class test {
public static void main(String[] args) {
doublie_list my_linklist=new doublie_list();
my_linklist.addFirst(1);
my_linklist.addFirst(2);
my_linklist.addFirst(3);
my_linklist.addFirst(4);
my_linklist.addLast(100);
my_linklist.addLast(100);
my_linklist.remove(100);
my_linklist.remove(100);
my_linklist.remove(2);
my_linklist.display();
}
}
}
11。双向链表优势:双向链表相比单向链表具有以下优势:
-
双向遍历:双向链表中的每个节点都有两个指针,一个指向后继节点(next),另一个指向前驱节点(prev)。因此,可以从任意节点开始方便地向前或向后遍历链表,提高了数据访问的灵活性。
-
快速删除和插入操作:在需要频繁进行插入、删除操作且需要快速定位前驱节点的情况下,双向链表的优势尤为明显。比如,在双向链表中删除一个给定节点时,可以直接通过该节点的前驱指针找到前一个节点并修改其指针,不需要像单链表那样从头节点开始搜索或者额外记录前驱信息,这使得操作效率更高。
-
查找优化:在某些情况下,可以利用双向链表的特点来改进查找算法,例如采用双向同步查找策略,可以在一定程度上提高查找效率,尤其是在链表两端附近的数据项查找时。
-
循环结构便利:在实现循环双向链表时,尾节点可以通过前驱指针直接连接到头节点,形成自然的循环结构,这对于需要连续访问所有节点直到回到起点的应用场景非常有用。
-
更高的空间局部性:对于一些特定应用场景,如LRU缓存淘汰算法等,双向链表能更好地支持“新近最少使用”原则,因为可以从当前节点出发迅速到达最近使用的节点或者最久未使用的节点。
然而,这些优点也伴随着额外的空间开销,因为每个节点都需要存储两个指针而不是单链表的一个指针。此外,由于涉及到更多的指针更新操作,在进行插入和删除时可能需要更复杂的逻辑处理。
12。扩展+了解
双向链表在许多数据结构和算法中都有具体的应用,以下是一些实例:
-
LRU缓存淘汰策略:在计算机系统设计中,Least Recently Used(最近最少使用)是一种常用的缓存替换策略。当缓存满了时,需要移除最近最少使用的数据项以腾出空间存放新数据。在这种情况下,可以使用双向链表存储缓存中的数据项,并结合哈希表进行快速定位。链表的头节点是最近被访问过的元素,尾节点则是最久未访问的元素。当有新的访问请求时,可以直接将该数据项移动到链表头部,如果需要淘汰数据,则直接删除链表尾部的数据项。
-
文本编辑器中的撤销/重做操作:在文本编辑器中,撤销和重做功能通常依赖于记录用户的操作序列。每个操作都可以表示为一个节点,通过双向链表链接起来,前向遍历代表撤销操作,后向遍历则代表重做操作。
-
浏览器的历史记录管理:用户在浏览网页过程中,浏览器会保存历史记录以便用户回退或前进。这些记录可以通过双向链表实现,方便用户向前或向后导航。
-
操作系统进程调度:在某些调度算法中,如双链队列(Double Ended Queue, DEQUE)调度算法,双向链表可用于维护就绪队列,方便高效地对两端的进程进行处理。
-
数据库索引结构:双向链表也可用于构建数据库的B树、B+树等索引结构,其中叶节点间的链接采用双向链表形式,从而实现双向顺序查找和范围查询。
-
图形界面组件的布局管理:在一些GUI框架中,组件的添加、删除、移动操作可以借助双向链表来灵活调整布局顺序。
总之,双向链表因其可双向遍历和快速插入删除的特点,在很多涉及动态更新和频繁访问邻近元素的场景下都能发挥重要作用。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









