








目录
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
看之前可以先了解一下MongoDB是什么:【MongoDB篇】万字带你初识MongoDB!
引言
好的!各位csdn的大佬们!🤯📈🚀
咱们已经把 MongoDB 的单节点能力、高可用和数据冗余(复制集)研究透了。现在,是时候挑战更高的山峰了!如果你的数据量达到TB甚至PB级别,或者你的读写吞吐量需求极高,即使是单个复制集,也可能会遇到瓶颈!
想象一下,你的“文件柜”(集合)已经堆满了整个“房间”(数据库),甚至一个“房间”已经装满了整个“仓库”(服务器)!再想通过提升服务器硬件(垂直扩展)来解决问题,成本会指数级上涨,而且硬件总有上限!💥🐢
这时候,我们就需要一种全新的思路——水平扩展 (Horizontal Scaling)!不是把现有的服务器变强,而是增加更多的服务器,把数据和负载分散到这些新的服务器上,让大家一起来分担压力!🤝💪
在 MongoDB 的世界里,实现水平扩展的终极武器,就是——分片 (Sharding)!🏆
分片 (Sharding),就是 MongoDB 用来解决海量数据存储和高吞吐量读写挑战的水平扩展方案!它能够让你突破单台服务器的硬件限制,理论上实现几乎无限的扩展!
第一节:分片核心概念:为什么要分片?它是什么? 🤔💥🚀
1.1 为什么要分片?单机瓶颈与数据爆炸!
- 垂直扩展的极限: 提升单台服务器的 CPU、内存、硬盘容量、网络带宽是垂直扩展 (Vertical Scaling)。但这有物理上限,而且成本越来越高,回报率越来越低。就像给一个水桶加高,总有加到顶的时候!📈➡️💸➡️🚧
- 单个复制集的限制: 即使是一个高可用的复制集,它的所有数据也存储在同一组服务器上。单个节点的存储容量是有限的;单个 Primary 节点的写入性能也是有上限的;整个复制集的读性能(即使有 Secondary 分流)也可能不足以应对极高的并发读请求。
- 数据量的挑战: 随着应用的发展,你的数据可能从 GB 级别增长到 TB、PB 级别。单个磁盘无法存储如此多的数据。
- 吞吐量的挑战: 用户量暴增,读写请求 QPS(每秒查询率)冲破天际!单个 Primary 节点成为写入瓶颈,Secondary 节点的读能力也跟不上。
分片就是为了解决这些问题而生的!它允许我们将一个庞大的数据集分割开来,分散存储在多个独立的服务器上,并能够将读写请求路由到存储相应数据的服务器上并行处理,从而提高整体的存储容量和处理能力!👍
1.2 什么是分片?水平扩展的解决方案!
分片是将数据分布到多个服务器上的过程。在 MongoDB 分片集群中,数据被分割成小的、独立的单元,称为数据块 (Chunk)。每个 Chunk 包含一个集合中某个特定范围(或哈希范围)的文档。这些 Chunk 被均匀地分布存储在集群中的不同服务器组上,每个服务器组称为一个分片 (Shard)。
客户端不再直接访问某个特定的服务器,而是通过一个特殊的查询路由器 (Mongos) 来访问集群。Mongos 知道数据 Chunk 分布在哪里,负责将客户端请求路由到正确的 Shard(s),并将结果合并返回。
第二节:分片架构的“三大金刚”:核心组件解析 🧱🧠🛣️
一个典型的 MongoDB 分片集群由三种核心组件组成,它们各司其职,协同工作:
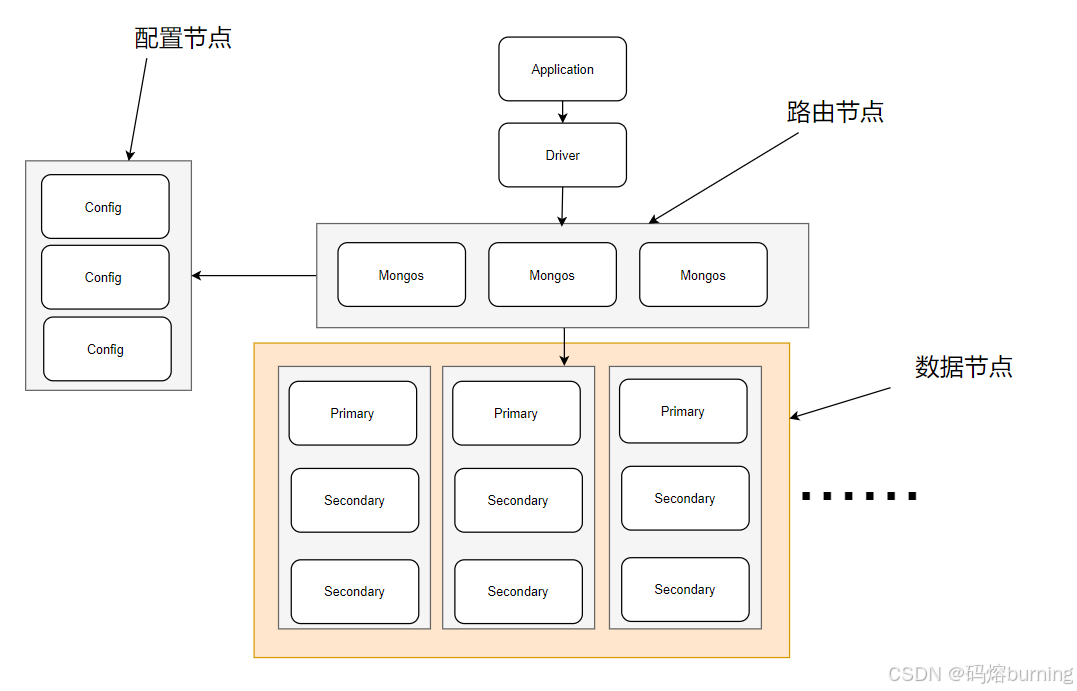
2.1 Shard (分片) 🧱🧱🧱
- 是什么? 一个 Shard 就是一个存储集群部分数据子集 (Subset) 的独立数据库系统。
- 关键: 每个 Shard 本身必须是一个复制集 (Replica Set)!这是为了保证 Shard 内部数据的高可用和冗余。即使某个 Shard 内的一个节点宕机,该 Shard 依然能够正常工作。💪🛡️
- 作用: Shard 负责存储实际的数据(即它被分配到的 Chunk),并执行 Mongos 路由器转发过来的读写请求。
2.2 Config Servers (配置服务器) 🧠🧠🧠
- 是什么? Config Servers 存储了整个分片集群的元数据 (Metadata)。这些元数据是集群正常运行的“大脑”!
- 关键: Config Servers 本身必须组成一个复制集 (Config Servers Replica Set - CSRS)!这是为了保证配置数据的安全、高可用和一致性。通常需要至少 3 个节点的 CSRS。🧠🧠🧠
- 作用: Config Servers 存储的元数据包括:
- 集群中有哪些 Shard。
- 每个集合是按照什么规则(Shard Key)进行分片的。
- 每个集合的数据被分割成了哪些 Chunk。
- 每个 Chunk 当前存储在哪个 Shard 上。
- Mongos 路由器需要连接 Config Servers 来获取这些元数据,以便正确地路由客户端请求。
2.3 Mongos (查询路由器) 🛣️➡️🧱➡️合并➡️💻
- 是什么? Mongos 是分片集群的入口!客户端应用程序只需要连接 Mongos 路由器,而不需要知道具体的 Shard 或 Config Server 地址。
- 关键: Mongos 是无状态 (Stateless) 的,它不存储数据(除了一些缓存的元数据)。这意味着你可以部署多个 Mongos 实例来提供高可用和负载均衡。客户端可以通过负载均衡器连接到多个 Mongos 中的任意一个。 👍
- 作用: Mongos 负责处理客户端的请求:
- 接收客户端的读写请求。
- 查询 Config Servers 获取元数据,了解请求涉及的数据存储在哪个 Shard 或哪些 Shard 上。
- 将请求路由到相应的 Shard(s)。对于需要访问多个 Chunk 或多个 Shard 的请求(例如,没有分片键的范围查询),Mongos 会将请求广播到所有相关的 Shard。
- 从 Shard(s) 接收执行结果。
- 合并 (Merge) 来自多个 Shard 的结果(如果需要),并返回给客户端。
这三个组件紧密协作,构成了 MongoDB 分片集群的强大骨架!
第三节:数据如何“分割”与“存储”:分片键与数据分布 🔑📊🚚⚖️
分片集群最重要的决策之一就是如何分割数据,这取决于你为集合选择的分片键 (Shard Key)!
3.1 Shard Key (分片键) 🔑🏆
- 定义: 分片键是集合中的一个字段或一个复合字段,它决定了文档如何被分割成 Chunk,并分配到不同的 Shard 上。
- 核心作用: 分片键是 MongoDB 分片数据和路由查询的唯一依据!选择一个合适的分片键是构建高效、可扩展的分片集群的最关键因素!🔑🏆
- 好的分片键的特点: 一个好的分片键能够将数据和读写请求均匀地分布到集群中的所有 Shard 上,避免出现数据热点和性能瓶颈。它通常具备以下特点:
- 高基数 (High Cardinality): 分片键的值域范围应该足够大,有足够多不同的值,这样才能将数据分割成大量的 Chunk,避免 Chunk 过少导致数据分布不均。
- 频率/分布 (Frequency/Distribution): 理想情况下,写入和读取操作应该能够均匀地命中不同的分片键值,从而将负载分散到不同的 Shard 上。避免某个 Shard 承受绝大部分的读写压力(热点问题)。🔥
- 单调性 (Monotonicity): 如果分片键的值是单调递增或递减的(比如时间戳、自增 ID),新的写入操作会集中在 Shard Key 范围的末尾,可能导致只有最后一个 Shard 持续接收写入流量,形成写入热点。除非你有特定的基于时间的查询需求,否则通常要避免强单调性的分片键。
- 分片键策略:
- 基于范围分片 (Range-based Sharding): 按照 Shard Key 值的范围来划分 Chunk。适合基于 Shard Key 的范围查询,Mongos 可以只将查询路由到包含该范围 Chunk 的 Shard 上(定向查询)。但是,如果 Shard Key 单调性强或某些范围的值写入频繁,容易造成热点。
// 在 orders 集合上按 order_date 字段进行范围分片 (升序) sh.shardCollection("ecommerce.orders", { order_date: 1 }); - 基于哈希分片 (Hashed Sharding): 对 Shard Key 的值进行哈希计算,然后按照哈希值的范围来划分 Chunk。哈希函数能够将单调递增的值映射到均匀分布的哈希值,因此非常适合解决单调性引起的热点问题,可以将写入均匀分散到所有 Shard 上。但是,哈希分片不利于基于 Shard Key 的范围查询,因为哈希打乱了原始值的顺序,范围查询可能需要查询所有 Shard(广播查询)。
// 在 users 集合上按 _id 字段进行哈希分片 sh.shardCollection("myapp.users", { _id: "hashed" }); - 基于区域分片 (Zone-based Sharding): 结合 Range 和 Tags。你可以定义 Shard Key 值的特定范围(称为 Zone 或 Tag),并将这些 Zone 关联到特定的 Shard 组。这样,属于某个 Zone 的 Chunk 就只会迁移到关联了该 Zone 的 Shard 上。适用于将数据分配到特定的硬件配置(比如 SSD Shard vs HDD Shard)或地理位置(比如将欧洲用户数据存储在欧洲的 Shard 上)的场景。📍🏢
- 基于范围分片 (Range-based Sharding): 按照 Shard Key 值的范围来划分 Chunk。适合基于 Shard Key 的范围查询,Mongos 可以只将查询路由到包含该范围 Chunk 的 Shard 上(定向查询)。但是,如果 Shard Key 单调性强或某些范围的值写入频繁,容易造成热点。
3.2 Chunk (数据块) 📦
- 定义: Chunk 是分片数据的逻辑单元。它包含了集合中 Shard Key 值在某个特定范围内的文档。
- 管理: Chunk 是由 MongoDB 自动创建、分裂和迁移的。
- 分裂 (Splitting): 当一个 Chunk 的大小增长到超过配置的阈值时(默认 128MB),MongoDB 会自动将其分裂成两个新的 Chunk。
- 迁移 (Migration): 当某个 Shard 上的 Chunk 数量过多或总大小超过某个阈值,导致数据分布不均时,均衡器 (Balancer) 会自动将 Chunk 从负载高的 Shard 迁移到负载低的 Shard。
3.3 Balancer (均衡器) ⚖️🚚
- 作用: Balancer 是一个运行在分片集群中的后台进程(通常运行在 Config Servers 上)。它的主要职责是监控 Shard 之间的数据分布(基于 Chunk 的数量和大小),并在需要时自动执行 Chunk 迁移。这是确保集群负载均衡、避免 Shard 过载的关键!
- 工作方式: Balancer 会定期检查 Shard 之间的 Chunk 数量差异。如果某个 Shard 的 Chunk 数量远多于其他 Shard,Balancer 会选择一些 Chunk,并将其从该 Shard 迁移到 Chunk 数量较少的 Shard。迁移过程是增量的,对正在进行的读写操作影响较小。
第四节:如何“组建”你的分片集群:部署步骤概览 🛠️🏗️
部署一个 MongoDB 分片集群比部署一个复制集复杂得多,因为它涉及到多种组件的协同工作。这是一个高级任务!
部署分片集群的基本步骤:
- 部署 Config Servers Replica Set (CSRS): 至少需要 3 个
mongod实例组成一个复制集,这些实例需要以configsvr: true选项启动,并维护集群的元数据。🧠🧠🧠 - 部署 Shard Replica Sets: 每个 Shard 本身就是一个复制集。你需要根据你的数据量和吞吐量需求,规划并部署至少一个 Shard 复制集。每个 Shard 复制集通常也至少需要 3 个成员。🧱🧱🧱
- 启动 Mongos 路由器: 启动一个或多个
mongos进程。这些进程不需要数据目录,但需要知道 Config Servers Replica Set 的地址,以便连接 Config Servers 获取集群元数据。🛣️ - 连接到 Mongos 并配置集群: 使用
mongosh连接到其中一个 Mongos 实例,然后执行一系列命令来配置分片集群:- 将 Shard Replica Sets 添加到集群中。
- 在需要分片的数据库上启用分片。
- 在需要分片的集合上指定 Shard Key 并开始分片。
- 客户端连接: 客户端应用程序连接到 Mongos 路由器来访问分片集群,而不是直接连接到 Shard 或 Config Server。
- 监控集群状态: 使用
mongosh连接到 Mongos,通过sh.status()等命令监控集群的健康状况、数据分布、Balancer 状态等。👁️🗨️
这个过程涉及到多个进程、多个服务器、多个复制集的协同,相对复杂。
第五节:Docker 模拟实验室:单服务器搭建分片集群演示 (学习专用!) 💻🐳🔬
在生产环境部署分片需要多台服务器。但是,为了学习和测试,我们可以使用 Docker Compose 在一台服务器上搭建一个模拟的分片集群环境!🐳🔬🤓
再次强调: 这个环境仅用于学习和演示! 它无法提供真正的高可用或分布式性能!所有组件都在同一台服务器上竞争资源。
使用 Docker Compose 的好处:
Docker Compose 允许你使用一个 YAML 文件来定义和配置多个 Docker 容器及其之间的依赖关系和网络。这比手动运行多个 docker run 命令来启动 Config Servers、Shards 和 Mongos 方便得多!👍
准备工作:
- 安装 Docker 和 Docker Compose: 确保你的服务器或本地电脑已经安装了 Docker Engine 和 Docker Compose。
- 充足的资源: 即使是模拟环境,启动多个 MongoDB 容器也会消耗不少 CPU 和内存。确保你的机器有足够的资源。
Docker Compose 文件 (docker-compose.yml) 详解与构建步骤:
我们将构建一个包含以下组件的模拟分片集群:
- 一个 3 节点的 Config Servers Replica Set (CSRS)。
- 一个 3 节点的 Shard Replica Set (Shard 1)。
- 一个 Mongos 路由器。
1. 创建 docker-compose.yml 文件:
在你的项目目录下创建一个名为 docker-compose.yml 的文件,并将以下内容粘贴进去:
# 定义服务 (容器)
services:
# --- Config Servers Replica Set (CSRS) ---
configsvr1:
image: mongo:latest # 使用最新的 MongoDB 镜像
container_name: configsvr1
command: mongod --replSet cfgReplSet --port 27017 --configsvr --dbpath /data/db --bind_ip_all # 启动命令
ports: # 端口映射 (可选,用于本地管理连接)
- "27017:27017"
volumes: # 数据卷持久化
- configdb1:/data/db
networks: # 连接到自定义网络
- mongo-sharding-net
configsvr2:
image: mongo:latest
container_name: configsvr2
command: mongod --replSet cfgReplSet --port 27017 --configsvr --dbpath /data/db --bind_ip_all
ports:
- "27018:27017" # 映射到宿主机不同端口
volumes:
- configdb2:/data/db
networks:
- mongo-sharding-net
configsvr3:
image: mongo:latest
container_name: configsvr3
command: mongod --replSet cfgReplSet --port 27017 --configsvr --dbpath /data/db --bind_ip_all
ports:
- "27019:27017"
volumes:
- configdb3:/data/db
networks:
- mongo-sharding-net
# --- Shard 1 Replica Set ---
shard1-node1:
image: mongo:latest
container_name: shard1-node1
command: mongod --replSet shard1ReplSet --port 27017 --shardsvr --dbpath /data/db --bind_ip_all # --shardsvr 参数
ports:
- "27020:27017"
volumes:
- shard1db1:/data/db
networks:
- mongo-sharding-net
shard1-node2:
image: mongo:latest
container_name: shard1-node2
command: mongod --replSet shard1ReplSet --port 27017 --shardsvr --dbpath /data/db --bind_ip_all
ports:
- "27021:27017"
volumes:
- shard1db2:/data/db
networks:
- mongo-sharding-net
shard1-node3:
image: mongo:latest
container_name: shard1-node3
command: mongod --replSet shard1ReplSet --port 27017 --shardsvr --dbpath /data/db --bind_ip_all
ports:
- "27022:27017"
volumes:
- shard1db3:/data/db
networks:
- mongo-sharding-net
# --- Mongos Router ---
mongos1:
image: mongo:latest
container_name: mongos1
command: mongos --port 27017 --configdb cfgReplSet/configsvr1:27017,configsvr2:27017,configsvr3:27017 --bind_ip_all # 指定 configdb 地址
ports:
- "27023:27017" # 客户端连接到 Mongos 的端口
networks:
- mongo-sharding-net
depends_on: # 依赖于 Config Servers 启动
- configsvr1
- configsvr2
- configsvr3
# 定义数据卷 (用于数据持久化)
volumes:
configdb1:
configdb2:
configdb3:
shard1db1:
shard1db2:
shard1db3:
# 定义网络 (让容器互相通信)
networks:
mongo-sharding-net:
driver: bridge # 使用桥接网络
文件解释:
services: 定义了我们将要运行的各个容器。configsvr1,configsvr2,configsvr3: 定义了三个 Config Server 容器。image: mongo:latest: 使用官方 MongoDB Docker 镜像。container_name: 给容器起个名字。command: 容器启动时执行的命令。mongod --replSet cfgReplSet --port 27017 --configsvr --dbpath /data/db --bind_ip_all: 启动mongod进程,指定复制集名称cfgReplSet,端口 27017(容器内部),数据路径/data/db,并加上--configsvr标志表明这是配置服务器。--bind_ip_all允许容器内部所有 IP 连接。
ports: 将容器内部的 27017 端口映射到宿主机的不同端口(方便本地管理工具连接)。volumes: 将命名卷挂载到容器内部/data/db,实现数据持久化。networks: 将容器连接到mongo-sharding-net网络。
shard1-node1,shard1-node2,shard1-node3: 定义了 Shard 1 的三个成员容器。command中的--shardsvr标志表明这是 Shard 的数据节点。--replSet shard1ReplSet指定 Shard 1 的复制集名称。ports: 映射到宿主机端口。volumes: 独立的命名卷。networks: 连接到同一个网络。
mongos1: 定义 Mongos 路由器容器。command:mongos --port 27017 --configdb cfgReplSet/configsvr1:27017,configsvr2:27017,configsvr3:27017 --bind_ip_all: 启动mongos进程,指定监听端口 27017(容器内部),并使用--configdb参数指定 Config Servers Replica Set 的名称和成员地址列表。这里的地址使用的是容器名称(在同一个 Docker 网络中容器可以通过名称互相解析),加上容器内部的端口。ports: 将容器内部的 27017 端口(Mongos 端口)映射到宿主机的端口(客户端连接这个端口)。networks: 连接到同一个网络。depends_on: 确保 Mongos 在 Config Servers 启动后才启动。
volumes: 定义了使用的命名卷,Docker 会自动创建和管理这些数据卷。networks: 定义了一个桥接网络,让所有容器可以在这个网络中通过容器名称互相通信。
2. 启动分片集群:
保存 docker-compose.yml 文件。打开终端,进入文件所在的目录,执行以下命令启动所有服务:
docker compose up -d
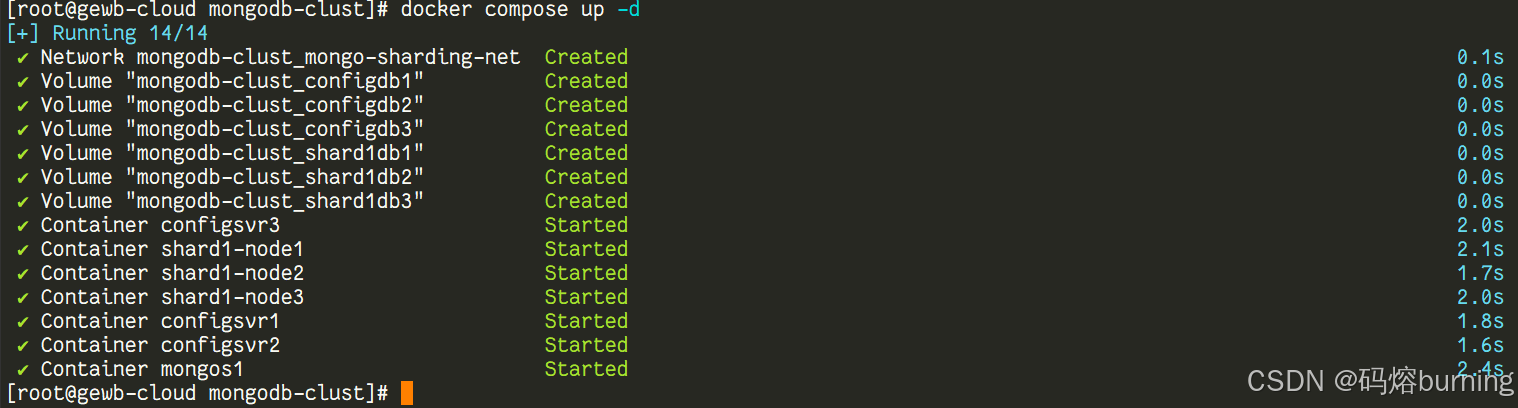
docker compose up -d 会在后台启动 docker-compose.yml 中定义的所有服务。Docker 会拉取镜像(如果本地没有),创建网络和数据卷,然后启动容器。
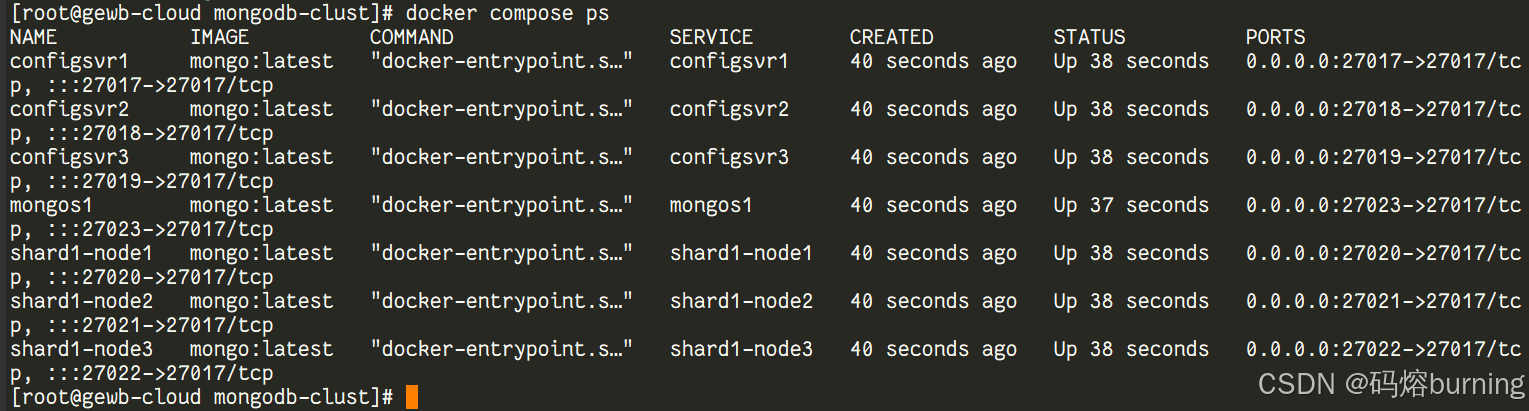
你可以使用 docker compose ps 查看容器是否都在运行。
3. 初始化 Config Servers Replica Set (CSRS):
Config Servers Replica Set 启动后,需要像普通的复制集一样进行初始化。连接到其中一个 Config Server 容器的 Shell,执行 rs.initiate() 命令。
首先找到 configsvr1 容器的 ID 或名称 (docker ps)。然后连接到它的 Shell:
docker exec -it configsvr1 mongosh --port 27017
进入 Shell 后执行:
rs.initiate({
_id: "cfgReplSet", # Config Servers 复制集名称,必须与 docker-compose.yml 一致
members: [
{ _id: 0, host: "configsvr1:27017" }, # 使用容器名称和内部端口
{ _id: 1, host: "configsvr2:27017" },
{ _id: 2, host: "configsvr3:27017" }
]
});
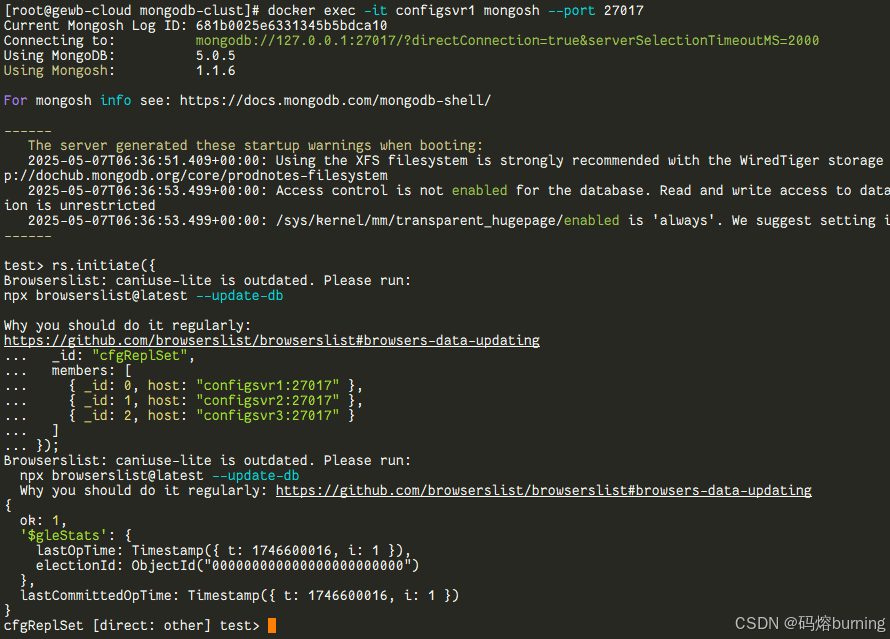
等待初始化完成,可以通过 rs.status() 查看状态。
4. 初始化 Shard 1 Replica Set:
Shard 1 也是一个复制集,也需要初始化。连接到 Shard 1 的任意一个成员容器(比如 shard1-node1)的 Shell。
docker exec -it shard1-node1 mongosh --port 27017
进入 Shell 后执行:
rs.initiate({
_id: "shard1ReplSet", # Shard 1 复制集名称,必须与 docker-compose.yml 一致
members: [
{ _id: 0, host: "shard1-node1:27017" }, # 使用容器名称和内部端口
{ _id: 1, host: "shard1-node2:27017" },
{ _id: 2, host: "shard1-node3:27017" }
]
});
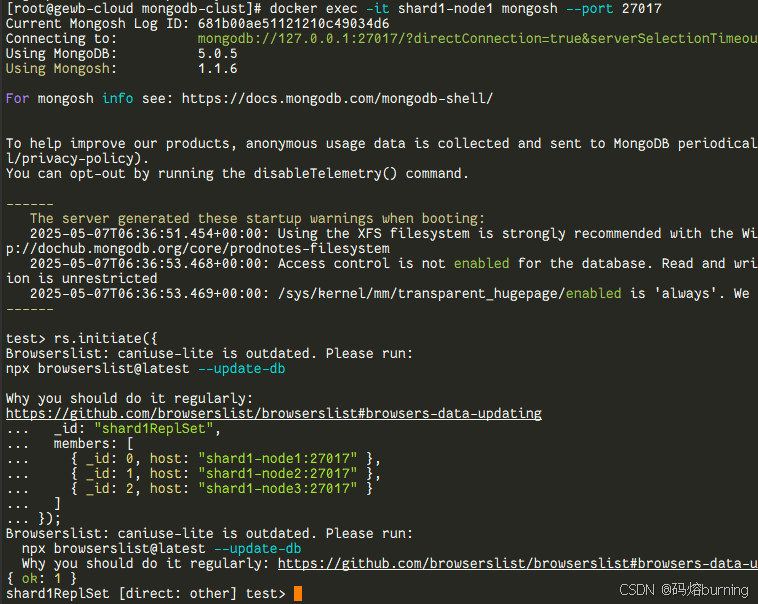
等待初始化完成,可以通过 rs.status() 查看状态。
5. 连接 Mongos 并配置分片:
现在 Config Servers 和 Shard 1 复制集都已就绪。连接到 Mongos 路由器容器的 Shell,进行分片配置!客户端应用程序最终会连接到 Mongos 的端口(在我们的例子中映射到了宿主机的 27023 端口)。
docker exec -it mongos1 mongosh --port 27017
进入 Mongos Shell 后执行以下命令:
-
添加 Shard 到集群: 告诉 Mongos 有哪些 Shard 可用。这里的地址是 Shard 复制集的名称加上成员列表(至少包含一个成员地址)。
sh.addShard("shard1ReplSet/shard1-node1:27017"); # 添加 Shard 1,指定其复制集名称和任一成员地址 // 如果有其他 Shard,也用 sh.addShard() 添加 // sh.addShard("shard2ReplSet/shard2-node1:27017");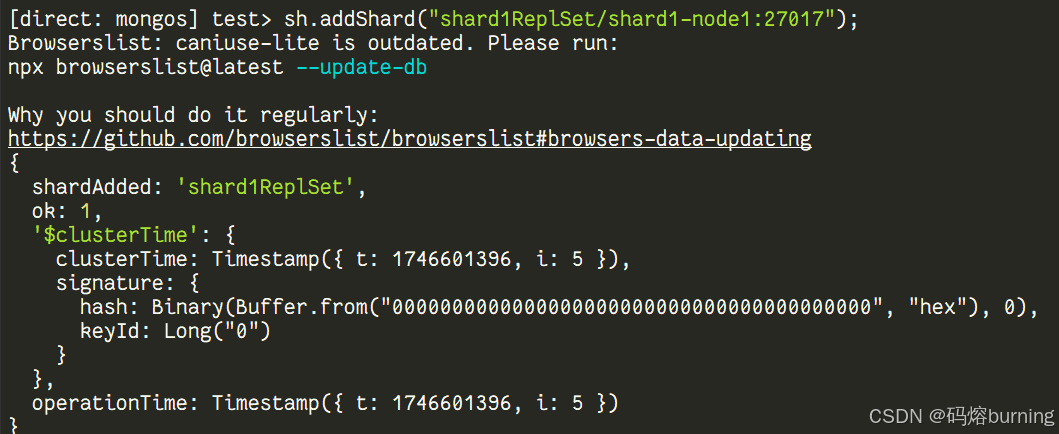
-
在数据库上启用分片: 指定哪个数据库需要启用分片。一旦启用,该数据库下的集合才能进行分片。
sh.enableSharding("mydatabase"); # 在 mydatabase 数据库上启用分片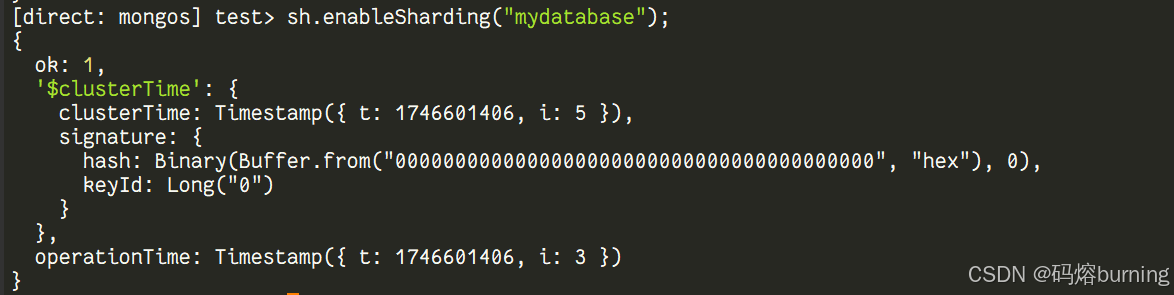
-
在集合上指定 Shard Key 并开始分片: 指定需要分片的集合,并选择一个 Shard Key。执行这个命令后,MongoDB 会开始根据 Shard Key 将集合中的数据分割成 Chunk,并分布到不同的 Shard 上。这是一个异步过程。
// 例如,在 mydatabase 数据库的 mycollection 集合上按 user_id 字段进行哈希分片 sh.shardCollection("mydatabase.mycollection", { user_id: "hashed" }); // 例如,在 products 集合上按 category 和 product_id 进行范围分片 // sh.shardCollection("ecommerce.products", { category: 1, product_id: 1 });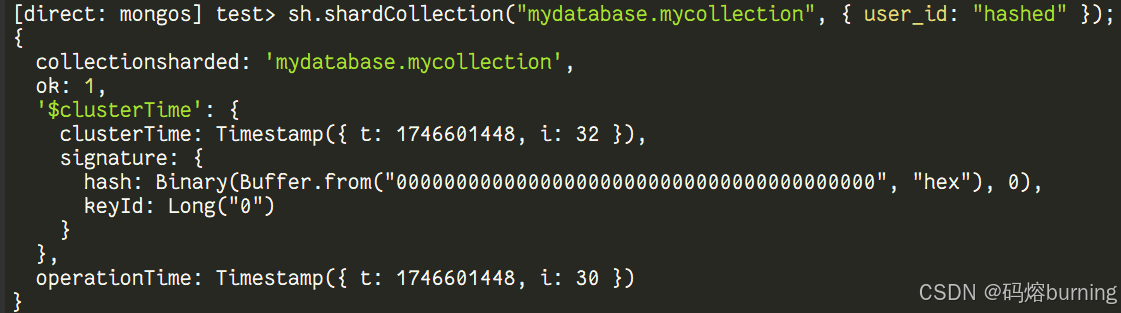
选择合适的 Shard Key 是最关键的一步!
6. 测试数据写入与分布:
连接到 Mongos (宿主机端口 27023),向分片后的集合中写入大量数据。
docker exec -it mongos1 mongosh --port 27017 # 连接到 Mongos
use mydatabase;
for (let i = 0; i < 1000; i++) {
db.mycollection.insertOne({ user_id: i, value: Math.random() });
}
等待一段时间,让 Balancer 有时间将 Chunk 迁移到不同的 Shard 上。你可以连接到 Mongos,使用 sh.status() 查看集群状态,特别是 chunks 部分,看数据 Chunk 是如何分布在不同 Shard 上的。你也可以连接到 Shard 1 的成员(比如宿主机端口 27020),查看 mydatabase.mycollection 中的数据,会发现它只包含部分数据。
7. 模拟故障 (可选):
可以使用 docker compose stop <container_name> 来停止某个 Config Server 或 Shard 成员容器,观察集群状态 (sh.status()) 和是否触发选举。模拟 Mongos 故障则可以连接到另一个 Mongos 实例。
8. 清理:
停止并移除所有容器、网络和数据卷:
docker compose down
docker compose down 会停止并删除 docker-compose.yml 中定义的所有服务、网络和数据卷。这会清除你的模拟环境。
第七节:单服务器 Docker 演示的“陷阱”——它不能取代生产环境!😕
再次强调,这个单服务器 Docker 演示仅用于学习和理解概念!它无法提供分片真正的优势,因为它所有的组件都在同一台服务器上运行,共同争夺资源!
- 无真正的高可用: 服务器宕机,所有容器一起宕机。💥
- 资源竞争严重: 多个
mongod和mongos进程互相争抢 CPU, RAM, 磁盘 IO。性能会非常差,甚至不稳定。🥊 - 无网络模拟: 无法模拟真实网络环境中的延迟和带宽限制。🌐❌
- 存储共享瓶颈: 虽然 Docker Volume 在逻辑上是分开的,但底层可能还在同一块物理硬盘上,受限于同一块硬盘的 IO 性能。
真正的生产环境分片集群,每个 Config Server 成员、每个 Shard 的成员都应该运行在独立的服务器上,拥有独立的存储和网络连接!Mongos 也应该部署在独立的服务器上,并有多台。 这是保障分片集群性能、高可用和可靠性的基础!🛡️🔒
第八节:生产环境的“硬核”考量与运维 🤔💾👁️🗨️🚨
将分片集群应用于生产环境,需要更深入的理解和更精细的运维:
- Shard Key 选择: 这是分片成功的最关键因素!投入时间和精力仔细设计和测试 Shard Key。理解 Range 和 Hashed 分片的优缺点,结合你的应用访问模式进行选择。一旦分片键确定并投入使用,修改或重新分片会非常复杂!🔑🏆🤔
- 数据分布监控: 持续监控 Chunk 的数量、大小以及在 Shard 上的分布是否均匀。关注 Balancer 的活动日志,确保均衡器在正常工作。如果数据分布不均,可能导致某些 Shard 过载。👁️🗨️⚖️
- Chunk 迁移: 了解 Chunk 迁移的过程。迁移是异步进行的,但大量迁移可能会对集群性能产生影响。在高负载期间可能需要暂停 Balancer。
- 资源规划: 根据预估的数据量增长和吞吐量需求,合理规划 Config Servers、各个 Shard (包括每个 Shard 的节点数量和硬件配置)、以及 Mongos 的数量和资源。Config Servers 和 Mongos 的资源需求相对较小,但 Shard 需要足够的存储和处理能力。📈📊
- 网络架构: Config Servers、Mongos、Shard 成员之间的网络是集群性能和稳定性的命脉!需要低延迟、高带宽、稳定可靠的网络。尤其是 Shard 内部(复制)和 Shard 之间(Chunk 迁移、广播查询)。
- 高可用: 再次强调,Config Servers 和所有 Shard 都必须是 Replica Set!Mongos 至少部署两台以上并通过负载均衡器连接,以消除单点故障。💪🛡️
- 备份与恢复: 分片集群的备份和恢复比复制集复杂得多,需要协调所有 Shard 和 Config Servers 的备份。使用 MongoDB 提供的分片感知备份工具(如
mongodump/mongorestore的--sharded选项,或 MongoDB Enterprise 的备份工具)。恢复时也要小心顺序和一致性。💾🔒 - 监控与告警: 监控所有组件的健康状况和关键性能指标。包括 Config Servers Replica Set (CSRS) 的状态和复制延迟,每个 Shard Replica Set 的状态和复制延迟,Mongos 的连接数和操作统计,Balancer 的状态和 Chunk 迁移进度,以及所有
mongod和mongos进程的系统资源使用。设置全面的告警系统,及时发现问题!👁️🗨️🚨 - 分片集群管理: 掌握
mongosh中sh.开头的各种命令,用于查看集群状态 (sh.status()), 添加/移除 Shard (sh.addShard,sh.removeShard), 管理 Balancer (sh.stopBalancer,sh.startBalancer), 查看 Chunk 分布 (sh.getBalancerState(),db.collection.getShardDistribution()) 等等。 - 版本管理与升级: 分片集群的版本升级通常需要按照特定的步骤进行滚动升级,确保升级过程不会中断服务。
- 安全: 在分片集群中启用认证和授权!包括客户端连接 Mongos 的认证,以及集群内部组件(Mongos, Config Servers, Shards)之间的认证(内部认证/Keyfile)。限制网络访问,配置防火墙。🔐🧱
第九节:总结与分片大师之路!🎉🤯🏆
太棒了!我们经历了一场关于 MongoDB 分片的深度探索之旅!我们理解了它解决海量数据和高吞吐挑战的必要性,掌握了 Shard、Config Server、Mongos 这“三大金刚”的架构和作用,学习了 Shard Key 的重要性、不同策略以及数据 Chunk 的分布和迁移。我们还通过一个详细的 Docker Compose 示例,亲手搭建并初步体验了一个模拟的分片集群!
核心要点:
- 分片用于水平扩展,应对海量数据和高吞吐。
- 核心组件是 Shard (复制集), Config Servers (复制集), Mongos (路由器)。
- Shard Key 是分片的关键,决定数据如何分布,选择至关重要。
- 数据被分割成 Chunk,并在 Shard 之间自动或手动迁移 (
Balancer)。 - Docker Compose 是单服务器模拟分片环境的利器,但仅用于学习,非生产!
- 生产环境分片需要多服务器、独立资源、高可用架构、精细运维和监控。
- 运维重点关注 Shard Key、数据分布、资源、网络、备份、监控告警。
掌握分片,你就掌握了构建能够处理超大规模数据、支撑极高访问量系统的能力!这是 MongoDB 的最高阶能力之一,也是挑战大型分布式系统的必经之路!🏆
从单机到复制集,再到分片,你已经逐步掌握了 MongoDB 的核心能力和分布式架构!继续保持这份探索和实践的热情吧!未来还有更多的技术等着你去挑战和征服!🚀
祝你在分片的世界里,数据飞驰,系统稳定,成为真正的海量数据驾驭者!🎉🔥
了解数据库操作请看:【MongoDB篇】MongoDB的数据库操作!
了解集合操作请看:【MongoDB篇】MongoDB的集合操作!
了解文档操作请看:【MongoDB篇】MongoDB的文档操作!
了解索引操作请看:【MongoDB篇】MongoDB的索引操作!
了解聚合操作请看:【MongoDB篇】MongoDB的聚合框架!
了解事务操作请看:【MongoDB篇】MongoDB的事务操作!
了解副本集操作请看:【MongoDB篇】MongoDB的副本集操作!

















 4198
4198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









