








目录
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
前言
好的各位程序猿/媛们,大佬们!👋
作为一名幽默的程序员,今天咱们不讲那些高大上的分布式、微服务,来聊点接地气、但也经常让人头疼的小家伙——MySQL的“回表”。
这“回表”啊,就像你在图书馆查书,索引卡片找到了(索引命中),但卡片上只有书名和索书号,你还得屁颠屁颠跑到书架去把书拿出来看具体内容(回到数据行)。这个“屁颠屁颠跑到书架”的过程,就是咱们今天的主角——回表(Lookup / Back-to-Table)!😎
一、 什么是回表?(讲个小故事,别睡着!😂)
想象一下,你经营着一家超大的图书馆(MySQL数据库),里面堆满了各种书籍(数据行),每本书都有一个唯一的编号(主键ID)。
为了方便大家找书,你弄了几套索引卡片(索引)。
- 第一套索引卡片:按索书号排序 ——— 这就是你的主键索引(Clustered Index,InnoDB里直接就是数据文件本身),每个索书号(主键ID)都直接指向了书本身(整行数据)。这是最直接、最高效的找书方式。
- 第二套索引卡片:按书名排序 ——— 这就是你的二级索引(Secondary Index)。每个卡片上只有“书名”和这本书的“索书号”(主键ID)。注意,这里没有书的具体内容!
为了大家方便理解,我这里挂一张黑马的图(里面的数据可能和我讲的不一样!):
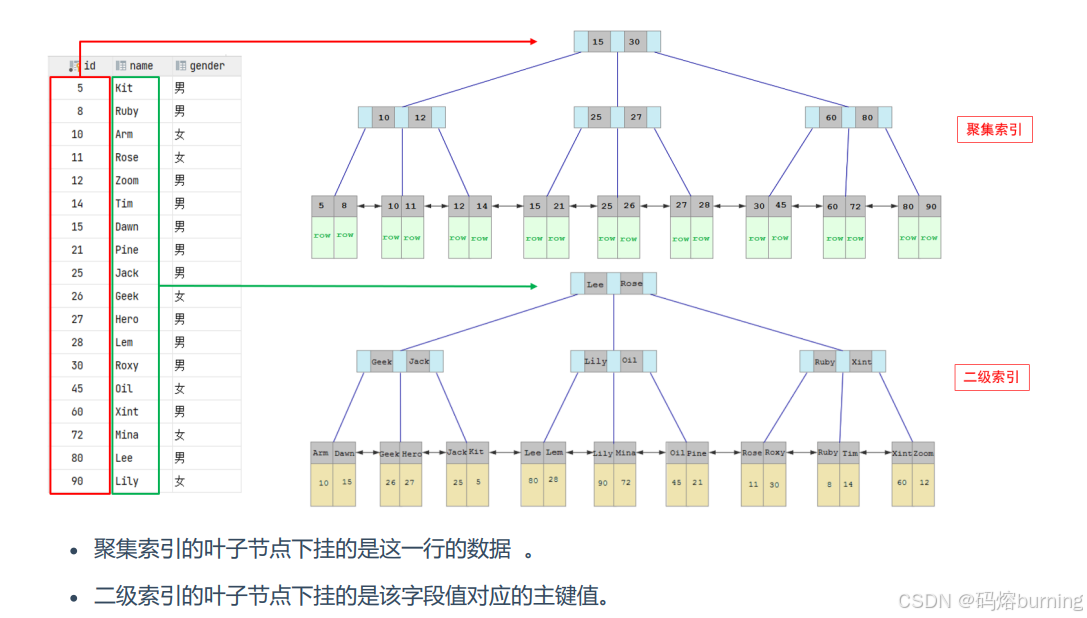
好了,现在有个读者想找所有书名包含“MySQL”的书,并且想知道这些书的作者和出版社。
- 第一步:你跑到“按书名排序”的索引卡片那里(使用二级索引)。你很快找到了所有书名包含“MySQL”的卡片。
- 第二步:这些卡片上只有书名和索书号。读者要的“作者和出版社”怎么办?索引卡片里没有啊!🤔
- 第三步:没办法,你只能拿着在索引卡片上找到的每一个“索书号”,再屁颠屁颠跑到“按索书号排序”的那套索引(主键索引)那里,根据索书号找到对应的书本,把书拿出来,看看作者和出版社是什么。
这个“拿着索书号,再回到主键索引去查找完整数据行”的过程,就是 回表!💥
是不是听起来有点绕?没事,简单来说,就是通过二级索引找到了主键ID,但二级索引里没有你想要的所有字段,所以需要再根据主键ID去聚簇索引(或者说数据文件本身)里把其他字段查出来。
二、 回表为什么会发生?(都是索引惹的祸?😉)
回表主要发生在 二级索引查询 之后。
为什么二级索引不直接存所有数据呢?
- 节省空间:如果每个二级索引都存所有字段,那索引文件会爆炸般增长,硬盘吃不消啊!😱
- 维护成本:数据更新时,只需要更新主键索引和相关的二级索引包含的少量字段,如果二级索引存所有字段,那每次更新数据,所有二级索引都要跟着更新,写操作的效率会非常低。
所以,二级索引的设计哲学就是:哥们我只存索引列的值,再加一个指向主键的值(在InnoDB里,二级索引的叶子节点存的就是索引列的值 + 主键ID)。这样够精简,查找速度快。但当你查询的需求超出了索引包含的字段,那就得“回表”去找了。
三、 结合代码,实战回表!💪
光说不练假把式!咱们来建个简单的表模拟一下。
假设我们有一个用户表 user_info:
CREATE TABLE user_info (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
age INT,
city VARCHAR(50),
email VARCHAR(100),
-- 其他可能的字段...
PRIMARY KEY (id) -- 这个就是主键索引
) ENGINE=InnoDB;
-- 给city字段加一个二级索引
CREATE INDEX idx_city ON user_info (city);
-- 插入一些测试数据
INSERT INTO user_info (name, age, city, email) VALUES
('张三', 28, '北京', 'zhangsan@example.com'),
('李四', 35, '上海', 'lisi@example.com'),
('王五', 22, '北京', 'wangwu@example.com'),
('赵六', 30, '深圳', 'zhaoliu@example.com'),
('钱七', 25, '上海', 'qianqi@example.com');
现在,我们想查询所有住在“上海”的用户的姓名(name)和邮箱(email)。
SQL查询是这样的:
SELECT name, email FROM user_info WHERE city = '上海';
我们来看看MySQL是怎么执行这条SQL的,用神器 EXPLAIN!
EXPLAIN SELECT name, email FROM user_info WHERE city = '上海';
执行后,你可能会看到类似这样的结果(不同版本和环境略有差异):
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | user_info | NULL | ref | idx_city | idx_city | 52 | const | 2 | 100.0 | Using index condition; Using where |
🚨 重点来了!看 Extra 列! 🚨
这里显示的是 Using index condition; Using where。
Using index condition: 表示使用了索引进行条件过滤(WHERE city = '上海'这个条件在idx_city索引上判断了)。这个是MySQL 5.6 引入的 Index Condition Pushdown (ICP) 特性,能减少回表次数,但在满足条件后,仍然需要回表获取其他字段。Using where: 在这里通常意味着MySQL还需要回到主表数据行中,获取除了索引列 (city) 和主键 (id) 之外的其他字段(name和email)。
为什么会这样?
- MySQL通过
idx_city索引找到了city = '上海'的记录,比如它找到两条记录,对应的id分别是2和5。 idx_city索引的叶子节点只存了city和id。查询需要name和email。- 于是,MySQL拿着
id = 2,去主键索引(或数据文件)里找到id为2的完整数据行,获取name和email。 - 接着,MySQL拿着
id = 5,再去主键索引(或数据文件)里找到id为5的完整数据行,获取name和email。
这个过程,就是发生了两次回表!如果你上海的用户有几万、几十万,那就要回几万、几十万次表!想象一下那个画面… MySQL都要跑到断腿啊!🚶♂️🚶♀️
四、 回表的性能影响 (甜蜜的烦恼,变苦涩了😭)
回表次数多了,性能影响是显而易见的:
- 磁盘I/O增加:每次回表都要去读取数据行的完整数据,这些数据行可能分散在磁盘的各个地方,导致大量的随机I/O。随机I/O比顺序I/O慢得多。
- 缓存失效:如果需要回表的数据行不在缓存中,就得从磁盘加载,冲刷掉缓存中已有的数据,影响后续查询效率。
所以,虽然二级索引提高了查找效率,但如果你的查询需要很多非索引字段,且通过索引找到的记录数很多,那么频繁的回表操作可能会成为新的性能瓶颈。
五、 如何优化,避免或减少回表?(拯救图书馆管理员!🦸♂️🦸♀️)
既然回表是个潜在的性能杀手,那有没有办法制服它呢?当然有!
大招一:创建覆盖索引(Covering Index)!🎉
什么是覆盖索引?简单说,就是一个二级索引,它包含(覆盖)了你查询语句中所有需要的字段。这样,MySQL只需要通过这个索引就能获取所有需要的数据,不需要再回表去查找数据行了!
回到上面的例子,我们的查询需要 city, name, email 字段。我们的 idx_city 只有 city 和 id。如果能建一个索引,包含 city, name, email 呢?
我们可以这样建一个联合索引:
-- 创建一个联合索引,包含 city, name, email
CREATE INDEX idx_city_name_email ON user_info (city, name, email);
注意:这个索引的顺序很重要,通常把用在WHERE条件、ORDER BY或GROUP BY的列放在前面。这里 city 在WHERE条件里,所以放在第一个。name 和 email 是select列表里的,放在后面。
现在,我们再用 EXPLAIN 分析一下同样的查询:
EXPLAIN SELECT name, email FROM user_info WHERE city = '上海';
这次的 EXPLAIN 输出可能会变成这样:
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | user_info | NULL | ref | idx_city,idx_city_name_email | idx_city_name_email | 52 | const | 2 | 100.0 | Using index |
看到 Extra 列了吗?这次是 Using index!
这意味着什么?恭喜你,成功创建了一个覆盖索引,并且MySQL查询时只使用了这个索引,全程在索引内部就获取了所有需要的 name 和 email 信息,根本没去回表! 図書館管理员可以坐着喝茶了!☕️
覆盖索引的优点:
- 减少磁盘I/O:只需要读索引文件,不需要读数据文件。
- 减少随机I/O:索引通常是顺序存储的,读取索引页是顺序I/O。
- 提升查询速度:直接从索引获取数据,跳过了回表步骤。
当然,覆盖索引也不是万能的:
- 索引文件会变大:因为索引里包含了更多的字段。
- 写入性能可能略有下降:数据更新时需要维护更多的索引字段。
所以,是否创建覆盖索引需要权衡,主要看你的查询模式和业务需求。对于读多写少的场景,覆盖索引往往能带来显著的性能提升。
大招二:只查询必要的字段!
有时候,回表是因为你 SELECT * 或者选择了你根本不需要的字段。如果你只查询索引中已经包含的字段,那自然也不会回表。
例如,如果你只查询上海用户的 id 和 city:
SELECT id, city FROM user_info WHERE city = '上海';
再次 EXPLAIN:
EXPLAIN SELECT id, city FROM user_info WHERE city = '上海';
Extra 列很可能也是 Using index。因为 idx_city 索引本身就包含 city 和 id(二级索引叶子节点默认包含主键ID),所以这个查询直接就可以在 idx_city 索引内部完成。
大招三:调整业务需求(有时候…🤔)
这个比较激进,但有时候如果某个查询是性能瓶颈,而通过索引实在无法优化到极致,可以考虑是否能调整业务逻辑,比如:
- 先用索引查出符合条件的主键ID列表。
- 再根据这些ID批量查询完整数据(减少单次回表的开销,虽然总的回表次数没变,但批量操作效率更高)。
- 或者考虑数据冗余/反范式设计(慎用,会增加数据一致性维护的复杂度)。
不过,大部分情况下,通过覆盖索引已经能解决很多回表带来的性能问题了。
六、 总结一下(打完收工!🚀)
回表,是MySQL在使用二级索引时,发现索引不包含查询所需的所有字段,不得不拿着主键ID回到数据文件(聚簇索引)去获取完整数据行的过程。
它发生的根本原因在于二级索引的设计:只存索引列值+主键ID。
回表会增加磁盘的随机I/O,成为查询性能的瓶颈,尤其是在索引命中大量行的情况下。
优化的主要手段是:
- 创建覆盖索引:让索引包含查询所需的所有字段,避免回表。
- 只查询必要的字段:避免因不必要的字段而触发回表。
理解回表,就像理解图书馆的工作流程一样,能帮助你更好地设计索引、编写SQL,写出更高效、更优雅的代码!💪
希望今天的讲解没有让你睡着,反而能让你对MySQL的回表有个更清晰、更幽默的认识!
如果觉得有帮助,点个赞,留个评论,或者请我喝杯咖啡(醒醒,搬砖去了☕️)!咱们下期再见!👋👋👋


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









