








目录
- 前言
- 核心全局参数解读与优化建议 ✨
- 1. max_connections:连接数的秘密花园 🚪
- 2. max_user_connections:给管理员留条路 🛣️
- 3. back_log:队列的容量 🚦
- 4. wait_timeout & interactive_timeout:空闲连接清理员 🧹
- 5. innodb_thread_concurrency:InnoDB 的并发管制 🚦
- 6. innodb_buffer_pool_size:InnoDB 的心跳血库 ❤️
- 7. innodb_lock_wait_timeout:行锁的等待时间 ⌛
- 8. innodb_flush_log_at_trx_commit & sync_binlog:数据安全与性能的权衡 🛡️⚡
- 9. sort_buffer_size & join_buffer_size:临时缓冲区的分配 📦
- 总结与思考 🤔
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
前言
大家好,我是你们的老朋友,一个幽默的程序员。在数据库的世界里,性能优化永远是一个绕不开的话题。我们都知道,SQL 和索引优化是提升性能的“王道”,因为它们直接作用于数据访问路径,效果最显著,而且成本相对最低。就像图里显示的那样:
MySQL 优化效果图 (这有一张展示优化成本 vs 效果的图,SQL & Index 位于效果好、成本低的区域)
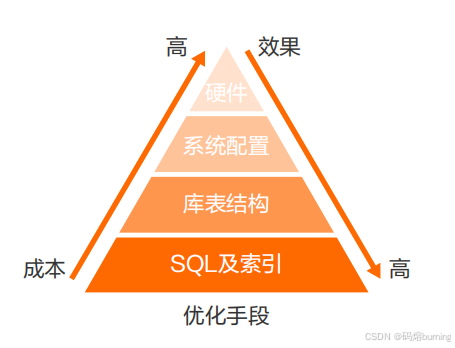
所以,在日常工作中,我们确实应该花大量时间去打磨 SQL 语句和设计合理的索引。💪
但是,除了 SQL 和索引,MySQL 的全局配置参数也对数据库整体性能有着举足轻重的影响!它们就像是数据库的心脏和血管,合理设置能让你的 MySQL 跑得更快、更稳!💖 今天,我们就来聊聊如何通过调整 MySQL 的配置文件 (my.ini 或 my.cnf) 中的一些关键全局参数来进行优化。
我们将以一个假设的服务器配置为例来讲解:
- CPU: 32 核 🧠
- 内存: 64GB 💾
- DISK: 2TB SSD 🚀
这些参数通常都在配置文件的 [mysqld] 标签下。准备好了吗?我们开始吧!
核心全局参数解读与优化建议 ✨
1. max_connections:连接数的秘密花园 🚪
max_connections=3000
这个参数决定了 MySQL 服务器允许的最大并发客户端连接数。连接就像是用户进入数据库的“门票”,每一个连接都需要消耗系统资源,比如内存和文件句柄。想象一下,如果你的系统有大量用户同时访问,就需要足够多的“门票”。🎫
这有一个很重要的概念:业务方说的“支持多少并发”通常是指每秒请求数 (QPS),而不是并发连接数。一个连接可以处理多个请求。
每个连接占用的内存可不是个小数字,从最小的 256KB 到最大的 64MB 不等。为什么会有这么大的差异?因为如果一个连接需要处理大量数据(比如进行大型排序操作),它可能会申请更多的临时空间,甚至会 spilling 到磁盘上,这可是会显著降低性能的!🐢
以我们的 64GB 内存服务器为例,如果设置 max_connections=3000:
- 最小内存消耗:3000 个连接 * 256KB/连接 = 约 750MB
- 最大内存消耗:3000 个连接 * 64MB/连接 = 约 192GB 😱
显然,最大内存消耗远远超过了我们的总内存 64GB。这说明,如果所有连接都申请了最大内存,系统就会发生内存交换 (SWAP),将部分内存数据写入磁盘,这将严重影响数据库性能。
优化建议:
max_connections不是越大越好!高并发连接不一定带来高吞吐量,反而可能因为资源争抢(尤其是内存)导致性能下降。- 要根据你的服务器硬件配置(特别是内存)和实际应用的需求来评估合适的连接数。可以通过观察历史的连接数峰值和内存使用情况来确定一个合理的值。
- 设置一个过高的
max_connections而硬件资源不足,就像是修了很多大门,但门后面的空间根本不够用,大家反而挤在一起,谁都进不去!🚧 - 设置成 3000 对于 64GB 内存的服务器来说可能偏高,需要结合实际负载测试来决定。
2. max_user_connections:给管理员留条路 🛣️
max_user_connections=2980
这个参数用于限制每个用户允许的最大连接数。设置这个参数是为了防止单个用户耗尽所有的连接资源,影响其他用户的正常访问。👍
优化建议:
- 保留一部分连接数给 DBA 或管理工具使用(比如上面的 3000 - 2980 = 20 个连接),这样即使应用占满了连接,管理员 still 可以连接上数据库进行维护操作。这是一个很好的实践!👨💼
3. back_log:队列的容量 🚦
back_log=300
当 MySQL 的连接数达到 max_connections 时,新的连接请求不会立刻被拒绝,而是会被放入一个等待队列中。back_log 参数就是这个等待队列的最大容量。
如果等待连接的数量超过了 back_log,新的连接请求才会被拒绝。🚪❌
优化建议:
back_log的值不宜过小,否则在高并发场景下,一旦连接数达到上限,很多请求会立刻被拒绝。- 这个值应该根据你的应用服务器的并发连接能力和 MySQL 处理连接的速度来调整。如果你的应用经常出现连接被拒绝的错误,可以适当增大
back_log。
4. wait_timeout & interactive_timeout:空闲连接清理员 🧹
wait_timeout=300
interactive_timeout=300
wait_timeout: 针对非交互式连接(例如应用程序通过 JDBC 连接)。它设置了连接在空闲多久后被服务器关闭,单位是秒。interactive_timeout: 针对交互式连接(例如通过 MySQL 客户端连接)。它设置了连接在空闲多久后被服务器关闭,单位是秒。
它们的默认值是 28800 秒(8 小时),这对于很多应用来说太长了!长时间保持空闲连接会占用服务器资源,而且如果网络出现问题,这些“死连接”可能会一直挂着,浪费资源。
优化建议:
- 根据你的应用场景,设置一个合理的
wait_timeout值。例如,对于 Web 应用,连接池通常会管理连接的生命周期,这个值可以设置得相对小一些,比如 300 秒(5 分钟)甚至更短,以便及时清理不再使用的连接。⏳ interactive_timeout可以根据 DBA 的实际操作习惯来设置,通常比wait_timeout长一些也可以接受,毕竟 DBA 可能需要长时间保持连接进行调试或观察。👀
5. innodb_thread_concurrency:InnoDB 的并发管制 🚦
innodb_thread_concurrency=64
这个参数限制了 InnoDB 存储引擎同时运行的线程数量。将其设置为一个合理的值可以避免线程之间因资源竞争(如锁)而导致的性能下降。
优化建议:
- 建议是将其设置为 CPU 核心数相同或两倍。对于我们 32 核的服务器,设置为 64 是一个基于这个经验法则的尝试。🚀
- 但是请注意,这只是一个经验值,不是绝对的真理!实际的最佳值需要通过负载测试来确定。设置过高可能导致更多的线程上下文切换和锁争用,反而降低性能。📉
- 默认值 0 表示不限制并发线程数,在某些情况下可能会导致问题。
6. innodb_buffer_pool_size:InnoDB 的心跳血库 ❤️
innodb_buffer_pool_size=40G
这是 InnoDB 存储引擎最重要的参数之一!它决定了 InnoDB 缓存数据和索引的大小。InnoDB 会优先将热点数据和索引加载到 buffer pool 中,从而显著减少磁盘 I/O,提升查询性能。
优化建议:
- 建议是设置为物理内存的 60%-70%,这是一个非常经典的经验值!👍 对于 64GB 内存的服务器,40GB (约 62.5%) 是一个合理的起点。
- 尽可能给
innodb_buffer_pool_size分配更多的内存,只要不超过物理内存的 80%(因为操作系统和其他进程也需要内存)。Buffer Pool 越大,能缓存的数据越多,命中率越高,性能越好!💯 - 这个值通常是提升 InnoDB 性能最有效的手段之一。
7. innodb_lock_wait_timeout:行锁的等待时间 ⌛
innodb_lock_wait_timeout=10
这个参数设置了事务等待行锁的最长时间(秒)。当一个事务试图获取一个已经被其他事务持有的行锁时,它会等待,如果等待时间超过 innodb_lock_wait_timeout,事务将会被回滚并报错。
优化建议:
- 默认值 50 秒在很多高并发场景下可能太长了,可能导致大量事务堆积,影响系统吞吐量。😱
- 建议是根据公司业务来定,没有标准值。这是一个非常明智的建议!💡
- 如果你的应用对锁等待比较敏感,或者希望快速发现死锁问题,可以适当减小这个值。但也要注意,设置得太小可能导致正常的长事务因为锁等待而频繁回滚。需要找到一个平衡点。⚖️
8. innodb_flush_log_at_trx_commit & sync_binlog:数据安全与性能的权衡 🛡️⚡
innodb_flush_log_at_trx_commit=1
sync_binlog=1
这两个参数,它们都与数据持久化和安全性密切相关,同时也对性能有很大影响。
innodb_flush_log_at_trx_commit: 这个参数控制着事务提交时,InnoDB 的事务日志(redo log)如何刷新到磁盘。1:每次事务提交时,redo log 都会同步刷新到磁盘。最安全,保证事务不丢失,但性能相对较低。适用于对数据一致性要求极高的场景。0:每秒将 redo log 刷新到磁盘,但事务提交时不做刷新。性能最好,但如果 MySQL 崩溃,可能丢失最后一秒的数据。2:每次事务提交时,将 redo log 写入操作系统的缓存,每秒由操作系统刷新到磁盘。安全性介于 0 和 1 之间,性能也介于两者之间。
sync_binlog: 这个参数控制着二进制日志(binlog)如何同步到磁盘。1:每次事务提交时,binlog 都会同步刷新到磁盘。最安全,保证 binlog 不丢失,对于主从复制的准确性至关重要,但性能相对较低。0:由操作系统决定何时将 binlog 刷新到磁盘。性能最好,但可能丢失一部分 binlog 数据。N(>1): 每间隔 N 个事务提交时,将 binlog 刷新到磁盘。在安全性和性能之间进行权衡。
优化建议:
innodb_flush_log_at_trx_commit = 1和sync_binlog = 1是最安全的设置,可以最大程度保证数据不丢失。如果你的业务对数据丢失零容忍,就应该坚持使用这两个设置。🔒- 然而,这两个设置会显著增加磁盘 I/O,在高并发写入场景下可能成为性能瓶颈。如果你的业务可以容忍少量数据丢失(例如,对于非核心业务或日志类数据),并且需要提升写入性能,可以考虑将它们设置为其他值。但这需要谨慎评估潜在风险!⚠️
- 选择合适的值需要在数据安全和性能之间进行权衡。
9. sort_buffer_size & join_buffer_size:临时缓冲区的分配 📦
sort_buffer_size=4M
join_buffer_size=4M
sort_buffer_size: 用于排序操作的缓冲区大小。当 MySQL 执行ORDER BY或GROUP BY操作时,会为每个需要排序的线程分配一个sort_buffer_size大小的缓冲区。增加这个值可以加速排序操作。🚀join_buffer_size: 用于表关联操作的缓冲区大小。当 MySQL 无法使用索引进行关联时,会使用 join buffer 来缓存关联的表数据,减少全表扫描的次数。
优化建议:
- 这里强调一下,这两个参数都是连接级别的!这意味着每个连接在需要时都会分配自己的缓冲区。
- 切忌设置过大! 如果你的
max_connections很高,并且sort_buffer_size或join_buffer_size也设置得很大,那么所有连接所需的缓冲区内存叠加起来将会消耗大量的系统内存,可能导致内存耗尽,甚至引发 SWAP,严重影响性能。😱 - 例如:500 个连接,每个分配 4MB 的 sort buffer,总共就需要 2GB 内存!
- 对于这两个参数,建议根据实际负载和内存使用情况进行调整,通常保持默认值或适度增加即可,除非通过慢查询日志发现排序或关联操作成为了主要瓶颈。可以通过
SHOW STATUS LIKE 'Sort_%'和SHOW STATUS LIKE 'Join_%'来观察相关状态变量。📈
总结与思考 🤔
MySQL 的全局优化是一个持续的过程,需要根据你的服务器硬件、业务负载和应用特性进行综合考虑和调整。本文介绍的这些参数只是众多配置选项中的一部分,但它们都是对性能影响较大的关键参数。
请记住:
- 没有一套配置适用于所有场景! 最佳的配置值需要通过实际的负载测试和性能监控来确定。📊
- 配置优化不是万能的! 如果你的 SQL 语句写得很糟糕,或者索引设计不合理,再怎么优化配置也可能事倍无补。SQL 和索引优化仍然是首要任务!🎯
- 监控是关键! 定期监控 MySQL 的各项性能指标(如连接数、QPS、TPS、缓存命中率、慢查询等),可以帮助你发现潜在问题并指导配置优化方向。🕵️♀️
希望这篇文章能帮助你更好地理解 MySQL 的全局配置参数,并为你进行数据库优化提供一些思路。如果你在优化过程中遇到了什么问题,或者有更高级的优化经验,欢迎在评论区分享交流!👇

















 53
53

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









