







目录
简介
MyBatis 是一款优秀的开源持久层框架,支持自定义SQL,存储过程以及高级映射;
-
持久层:负责数据保存到数据库的的代码部分称为持久层(三层架构:表现层,业务层,持久层);
-
框架:框架就是一个半成品软件,可以重用,通用的,软件基础代码模型;在框架的基础上构建软件编写更加高效,规范通用,可扩展;
持久化:内存中的数据是断电即失的,而让程序的数据持久存在(即连接数据库)就是持久化;
在Java应用程序中,数据持久化层涉及到的工作 有:
-
将从数据库查询到的数据生成所需要的Java对象
-
将Java对象中的数据通SQL持久化到数据库中
MyBatis通过抽象底层的JDBC代码,自动化封装SQL结果集产生Java对象、Java对象的数据持久化数据库 中的过程使得对SQL的使用变得容易。
Mybatis的功能:数据持久化,简化JDBC的工作;
Mybatis的作用:帮助程序员将数据存入到数据库
MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以通过简单的 XML 或注解来配 置和映射原始类型、接口和 Java POJO(Plain Old java Objects,普通老式 Java 对象)为数据库中的记录。
Mybatis的优点:
-
简单易学,灵活
-
sql和代码的分离,提高了可维护性。
-
提供映射标签,支持对象与数据库的orm字段关系映射
-
提供对象关系映射标签,支持对象关系组建维护
-
提供xml标签,支持编写动态sql。
入门
1.导入mybatis的yi'lai
要使用mybatis,只需要将mybatis的相关jar包文件置于类路径(classpath)中即可;
如果使用Maven来构建项目,则需要将依赖导入pom.xml文件中;
<dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.5</version> </dependency>
2.从XML中构建SqlSessionFactory对象
核心配置文件:(一般情况)mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--管理数据库的连接信息,可以设置多个不同的environment,到时候通过default选择;-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--加载映射的SQL文件,映射的sql文件只有在这里注册才能够使用;-->
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
使用:
String resource = "org/mybatis/example/mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
3.SQL映射文件
***Mapper.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--命名空间,一般情况下我们在调用mapper里面的方法的时候,都是通过接口调用,所以命名空间中一般存放的都是对应接口文件的全限定名;然后接口中的方法与mapper中的SQL语句一一对应,语句的ID就是接口的方法名;-->
<mapper namespace="org.mybatis.example.BlogMapper">
<select id="selectBlog" resultType="Blog">
<!--select 查询语句标签-->
select * from Blog where id = #{id}
</select>
<!--insert 插入语句标签-->
<!--update 更新语句标签-->
<!--delete 删除语句标签-->
</mapper>
使用:
try (SqlSession session = sqlSessionFactory.openSession()) {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
}
详解
CRUD
CRUD是指在做计算处理时的增加(Create)、读取查询(Retrieve)、更新(Update)和删除(Delete)几个单词的首字母简写。主要被用在描述软件系统中DataBase或者持久层的基本操作功能;
ps:增删改需要提交事务
mapper.xml文件关键词解释:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.briup.mapper.StudentMapper">
<resultMap type="Student" id="StudentResult">
<id property="id" column="id" />
<result property="name" column="name" />
<result property="email" column="email" />
</resultMap>
<select id="findAllStudents" resultMap="StudentResult">
SELECT * FROM STUDENTS
</select>
<insert id="insertStudent" parameterType="Student">
INSERT INTO STUDENTS(ID,NAME,EMAIL)
VALUES(#{id },#{name},#{email})
</insert>
<update>修改的sql语句</update>
<delete>删除的sql语句</delete>
</mapper>
namespace
namespace中的包名要和Dao/mapper接口的包名保持一致,namespace绑定一个接口类;
<mapper namespace="com.briup.mapper.StudentMapper"> </mapper>
select
<select id="getUserById" resultType="com.rui.pojo.User" parameterType="int">
/*定义sql*/
select * from mybatis.user where id = #{id};
</select>
select标签放在上述mapper接口中;每个select其实对应mapper标签的接口类的一个方法;
id:就是对应的namespace中的方法名;
resultType:Sql语句执行的返回值!
parameterType:参数类型!
select标签中就是编写的sql语句
resultMap(结果集映射)
<resultMap id="UserMap" type="User">
<!--column数据库中的字段,property实体类中的属性-->
<result column="id" property="id"/>
<result column="name" property="name"/>
<result column="pwd" property="password"/>
</resultMap>
<select id="getUserById" resultMap="UserMap" parameterType="int">
/*定义sql*/
select * from mybatis.user where id = #{id};
ResultMap被用来将SELECT语句的结果集映射到java对象属性中。
ResultMap 的设计思想是,对于简单的语句根本不需要配置显式的结果映射,而对于复杂一点的语句只需要描述它们的关系就行了。
所以,ResultMap就是提前定义好的一个映射规则,select语句可以使用ResultMap的映射规则来处理查询 结果。
这是mybatis中的一个非常重要的元素,可以使用它指定sql查询出的结果集,会被怎么处理并封装成 对象,也可以使用它完成复杂查询的映射,例如一对一、一对多关系的SELECT语句。
常见的错误,需要注意:
-
标签不要匹配错误
-
resource绑定mapper,需要使用路径!
-
程序配置文件必须符合规范
-
NullPointerException,没有注册到资源
-
输出的xml文件中存在中文乱码问题
-
maven资源没有导出问题
万能的Map
实体类,或者数据库中的表,字段或者参数过多,我们应当考虑使用Map!
优点:
-
Map传递参数,直接在sql中取出key即可!【parameterType=“map”】
-
对象传递参数,直接在sql中取对象的属性即可!【parameterType=“Object”】
-
只有一个基本类型参数的情况下,可以直接在sql中取到!
-
多个参数用Map,或者注解!
模糊查询
既sql语句中的LIKE在mybatis中可以使用
假如说要查找名字中包含固定字符:
通配符:(可能存在SQL注入的问题)
select * from mybatis.user where name like "%"#{value}"%"
concat方法:
WHERE STU_NAME LIKE CONCAT('%',CONCAT(#{name}, '%'))
核心配置文件解析:
核心配置文件:mybatis.xml文件
作用:MyBatis的配置文件包含了会深深影响MyBatis行为的设置和属性信息
内部包含的标签如下:
configuration(配置)
-
properties(属性)
-
settings(设置)
-
typeAliases(类型别名)
-
typeHandlers(类型处理器)
-
objectFactory(对象工厂)
-
plugins(插件)
-
environments(环境配置)
environment(环境变量)
-
transactionManager(事务管理器)
-
dataSource(数据源)
-
-
databaseIdProvider(数据库厂商标识)
-
mappers(映射器)
环境配置(environments)
MyBatis可以配置成适应多种环境(即environments下面可以有多个environment,但是每个 SqlSessionFactory 实例只能选择一种环境)
MyBatis默认的事务管理器是JDBC,连接池是POOLED
属性(properties)
通过properties属性来实现引用配置文件
这些属性都是可外部配置且可动态替换的,既可以在典型的 Java 属性文件中配置,亦可通过 properties 元素的子元素来传递。
设置文件的引用由两种方式,但是都通过properties标签来实现:
<properties resource="db.properties"> <property name="username" value="root"/> <property name="password" value="Cc105481"/> </properties>
第一种:直接使用properties标签下的property标签来一个一个的写配置文件,name是起的别名,value是引用的具体内容;
第二种:直接引用相关的配置文件,通过properties的属性resource来实现;
使用:在需要的地方直接写
value="${name}"
ps:假如在引用配置文件的时候,这两种方式都用了,并且还有了相互重合的键值对,则优先使用外部配置文件的;
类型别名(typeAliases)
类型别名是为 Java 类型设置一个短的名字。 存在的意义仅在于用来减少类完全限定名的冗余。
因为我们在使用Java类的时候,一般是写的全限定名,而使用typeAliases后可以为冗长的全限定名起一个简短的名字(一般为类名改为小写)
typeAliases标签下有两个子标签:
第一:typeAlias,为一个实体类起别名
<typeAlias type="com.rui.pojo.User" alias="User"/>
第二:package,为一个包下的所有实体类起别名,别名默认为类名的全小写格式;
<package name="com.rui.pojo"/>
适用:
第一种一般建议在实体类比较少的时候使用,同时这个可以DIY别名
第二种建议在实体类较多的时候使用,第二种的别名是默认的;
映射器(Mappers)
<!--每一个Mapper.xml需要在Mybatis核心配置文件中注册--> <mappers> <!-- <mapper resource="com/newer/dao/UserMapper.xml"/>--> <!-- <mapper class="com.newer.dao.UserMapper"></mapper>--> <package name="com.newer.dao"/> </mappers>
上述是反射mapper.xml文件的三种方式:
第一种较为常用,无限制
第二种:接口和他的Mapper配置文件必须同名
第三种:接口和他的Mapper配置文件必须在同一个包下;
MyBatis生命周期和作用域
图示:
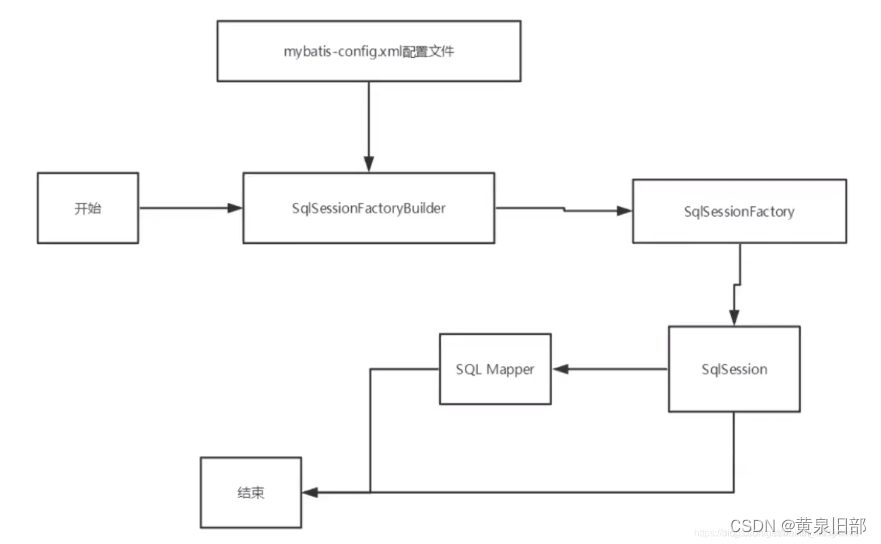
解释:
-
我们通过SqlSessionFactoryBuilder,加载mybatis-config.xml文件,生成具体的SqlSessionFactory工厂,然后在生成Sqlsession的实例对象,经由SQL session实例对象产生Mapper进行具体操作。
-
SqlSessionFactoryBuilder,目的只是为了创建SqlSessionFactory,一旦创建了SqlSessionFactory,就不再需要它,属于局部变量;
-
SqlSessionFactory:类似于数据库连接池,SqlSessionFactory 一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例,因此SqlSessionFactory的最佳作用域是应用作用域,同时也是单例的;
-
SqlSession:等同于连接到连接池的一个请求,因为SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是仅限于此次请求或方法作用域;用完之后需要赶紧关闭,否则会占用资源;
-
每一个Mapper,就代表一个具体的业务!
解决对应数据库字段名与类属性名不一致的问题:
解决方法:起别名
日志
日志工厂
记录程序的运行情况,帮助程序员排查错误;
现在比较常用的日志:
LOG4J
STDOUT_LOGGING(标准日志输出)
在MyBatis的核心配置文件中使用settings标签进行配置;例:
<settings> <setting name="logImpl" value="LOG4J"/> </settings>
Log4j
Log4j是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件 我们也可以控制每一条日志的输出格式
-
通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
-
通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
在pom.xml文件中进行依赖配置
<dependencies> <!-- https://mvnrepository.com/artifact/log4j/log4j --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> </dependencies>
Log4j的配置文件:log4j.properties
#将等级为DEBUG的日志信息输出到console和file这两个目的地,console和file的定义在下面的代码
log4j.rootLogger=DEBUG,console,file
#控制台输出的相关设置
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n
#文件输出的相关设置
log4j.appender.file = org.apache.log4j.RollingFileAppender
log4j.appender.file.File=./log/kuang.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=DEBUG
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c]%m%n
#日志输出级别
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
分页
分页的目的:减少数据的处理量
使用Limit分页
依靠Mybatis实现分页,核心还是SQL语句:
select * from user limit startIndex,pageSize
接口方法:
//分页 List<User> getUserByLimit(Map<String,Integer> map);
mapper.xml文件设置:
<!--分页-->
<select id="getUserByLimit" parameterType="map" resultMap="UserMap">
select * from mybatis.user limit #{startIndex},#{pageSize}
</select>
需要分页的话,直接调用方法:
@Test
public void getUserByLimit(){
SqlSession sqlSession = MyBatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
HashMap<String, Integer> map = new HashMap<>();
map.put("startIndex",0);
map.put("pageSize",2);
List<User> userList = mapper.getUserByLimit(map);
for (User user : userList) {
System.out.println(user);
}
sqlSession.close();
}
RowBounds分页
没有依靠sql实现分页:
mapper.xml文件:
<!--分页2--> <select id="getUserByRowBounds" resultMap="UserMap"> select * from mybatis.user </select>
不需要设置对应的接口方法,直接调用;
通过java代码层面实现分页
演示:
@Test
public void getUserByRowBounds(){
SqlSession sqlSession = MyBatisUtils.getSqlSession();
//RowBounds实现
RowBounds rowBounds = new RowBounds(1, 2);
//通过java代码层面实现分页
List<User> userList = sqlSession.selectList("com.rui.dao.UserMapper.getUserByRowBounds",null,rowBounds);
for (User user : userList) {
System.out.println(user);
}
sqlSession.close();
}
分页插件
MyBatis分页插件PageHelper
映射
一对一映射:
在进行一对一映射的时候,两张表通过一个公共的属性列进行链接,比如每个学生都有家庭住址,我们可以根据住址的id去在住址信息表中找到对应的信息,拼接起来,是数据更充分
方式一:直接按照sql语句的查询结果进行封装,(不推荐)
<!-- 一对一映射:方法一,直接将副表的数据封装入主表的映射-->
<resultMap type="com.wjl.pojo.Student" id="StudentWithAddressResult">
<id property="stuId" column="id" />
<result property="name" column="name" />
<result property="email" column="email" />
<result property="dob" column="dob"></result>
<result property="phone" column="phone" />
<result property="address.addrId" column="addr_id" />
<result property="address.street" column="street" />
<result property="address.city" column="city" />
<result property="address.state" column="state" />
<result property="address.zip" column="zip" />
<result property="address.country" column="country" />
</resultMap>
<select id="selectStudentWithAddress" parameterType="int"
resultMap="StudentWithAddressResult">
select
s.id, s.name, s.email,s.phone,s.dob,a.addr_id, a.street, a.city, a.state, a.zip, a.country
from students s left outer join addresses a on s.addr_id = a.addr_id
where s.id= #{stuId}
</select>
方式二:嵌套结果
<!-- 一对一映射:方式二:嵌套结果:分别封装主副表的映射-->
<resultMap id="AddressResult" type="com.wjl.pojo.Address">
<id property="addrId" column="ADDR_ID"></id>
<result property="street" column="STREET"></result>
<result property="city" column="CITY"></result>
<result property="state" column="state"></result>
<result property="zip" column="ZIP"></result>
<result property="country" column="COUNTRY"></result>
</resultMap>
<resultMap id="StudentResult" type="com.wjl.pojo.Student">
<id property="stuId" column="id" />
<result property="name" column="name" />
<result property="email" column="email" />
<result property="dob" column="dob"></result>
<result property="phone" column="phone" ></result>
<!-- 结果嵌套的核心语句-->
<association property="address" resultMap="Address"></association>
</resultMap>
<select id="selectStudentWithAddress02" parameterType="int" resultMap="StudentResult">
select * from students s left outer join addresses a on a.addr_id=a.addr_id
where s.id=#{id}
</select>
与方式一类似,但是更先进,优美;直接将外建列的查询结果给予主表对应实体类的属性;
方式三:嵌套查询:
<resultMap id="AddressResult" type="com.wjl.pojo.Address">
<id property="addrId" column="ADDR_ID"></id>
<result property="street" column="STREET"></result>
<result property="city" column="CITY"></result>
<result property="state" column="state"></result>
<result property="zip" column="ZIP"></result>
<result property="country" column="COUNTRY"></result>
</resultMap>
<resultMap id="StudentResult" type="com.wjl.pojo.Student">
<id property="stuId" column="id" />
<result property="name" column="name" />
<result property="email" column="email" />
<result property="dob" column="dob"></result>
<result property="phone" column="phone" ></result>
<!-- 查询嵌套的核心语句-->
<association property="address" column="addr_id" select="selectAddressByAddressId"></association>
</resultMap>
<select id="selectStudentWithAddress02" parameterType="int" resultMap="StudentResult">
select * from students s left outer join addresses a on a.addr_id=a.addr_id
where s.id=#{id}
</select>
<select id="selectAddressByAddressId" resultMap="AddressResult">
select * from addresses where addr_id=#{id}
</select>
<select id="selectStudentWithAddress03" resultMap="StudentResult">
select * from students where id=#{id}
</select>
解释;根据主表的外键列写了一个根据主表外键列查询附表的语句。然后再resultMap中将其与主表映射的外键列连接起来;
一对多映射
<!-- 一对多映射:一个讲师tutors可以教授一个或者多个课程course。这意味着讲师和课程之间存在一对多的映射关系。-->
<!-- 独立的Course与tutor封装映射-->
<resultMap id="CourseResult" type="com.wjl.pojo.Course">
<id property="courseId" column="course_id"></id>
<result property="name" column="name"></result>
<result property="description" column="description"></result>
<result property="startDate" column="startdate"></result>
<result property="endDate" column="enddate"></result>
</resultMap>
<resultMap id="TutorResult" type="com.wjl.pojo.Tutor">
<id property="tutorId" column="tutor_id"></id>
<result property="name" column="name"></result>
<result property="email" column="email"></result>
<result property="phone" column="phone"></result>
<!-- 嵌套结果核心语句-->
<!-- <association property="address" resultMap="AddressResult"></association>-->
<!-- <association property="courses" resultMap="CourseResult"></association>-->
<!-- 嵌套查询核心语句-->
<association property="address" column="addr_id" select="selectAddressByAddressId"></association>
<association property="courses" column="tutor_id" select="selectCoursesByTutorId"></association>
</resultMap>
<!-- 一对多映射,结果嵌套,多表连接查询,将查询的结果经过映射进行统一封装-->
<select id="selectTutorById" parameterType="int" resultMap="TutorResult">
select * from tutors t
left outer join addresses a on t.addr_id=a.addr_id
left outer join courses c on t.tutor_id=c.tutor_id
where t.tutor_id=#{id}
</select>
<!-- 一对多映射,查询嵌套,tutor封装映射时,将外键列直接与相关的副表查询sql语句连接,进行管理-->
<!-- 相关外建列的查询语句-->
<select id="selectCoursesByTutorId" parameterType="int" resultMap="CourseResult">
select * from courses where tutor_id=#{tutor_id}
</select>
<!-- tutor的查询语句-->
<select id="selectTutorById02" parameterType="int" resultMap="TutorResult">
select * from tutors where tutor_id=#{tutor_id}
</select>
多对多映射:
<!-- 多对多映射-->
<!-- 嵌套结果的resultMap进行级联查询-->
<resultMap id="StudentResult" type="com.wjl.pojo.m2m.Student">
<id property="id" column="sid" />
<result property="name" column="name" />
<result property="gender" column="gender" />
<result property="major" column="major" />
<result property="grade" column="grade" />
</resultMap>
<resultMap id="CourseResult" type="com.wjl.pojo.m2m.Course">
<id property="id" column="cid" />
<result property="courseCode" column="course_code" />
<result property="courseName" column="course_name" />
</resultMap>
<!-- 继承上述的Student基本映射,在扩展出级联查询-->
<resultMap id="StudentResultWithCourses" type="com.wjl.pojo.m2m.Student" extends="StudentResult">
<collection property="courses" resultMap="CourseResult"></collection>
</resultMap>
<select id="selectStudentByIdWithCouse" parameterType="int" resultMap="StudentResultWithCourses">
select s.id as sid,s.name,s.gender,s.major,s.grade,
c.id as cid,c.course_code,c.course_name,
sc.id as scid,sc.student_id,sc.course_id from m_student s,m_course c,m_student_course sc
where s.id=#{id} and s.id=sc.student_id and c.id=sc.course_id
</select>
嵌套查询与嵌套结果类似,参考一对多查询;
多对多查询可以看成是桥表与另外外键列表的一对多查询;
动态SQL
动态SQL就是指根据不同的条件生成不同的SQL语句,是 MyBatis 的强大特性之一;
mybaits通过以下标签对动态sql提供支持:
-
<if>
-
<choose>
-
<where>
-
<foreach>
-
<trim>
-
<set>
详解:
1,<if>标签被用来通过条件嵌入SQL片段,如果条件为true,则相应地SQL片段将会被添加到SQL语句中。
<select id="searchCourseByIf" resultMap="CourseResult">
SELECT * FROM COURSES
WHERE TUTOR_ID= #{tutorId}
<if test="courseName != null">
AND NAME LIKE #{courseName}
</if>
<if test="startDate != null">
AND START_DATE >= #{startDate}
</if>
<if test="endDate != null">
AND END_DATE <![CDATA[ <= ]]> #{endDate}
</if>
</select>
解释:在查询课程的时候,传入的参数是一个map集合,其中导师Id属于必选项;其他的可有可无,应为<if>标签的原因,其他条件的出现并不会对SQL语句的正确性造成影响;最终生成的查询语句如下(方括号括起来的意思是可能有也可能无):
SELECT * FROM COURSES WHERE TUTOR_ID= ? [AND NAME like ? ][AND START_DATE >= ?]
2,<choose>,在查询的时候,需要选择选择查询的类别:
<select id="searchCourseByChoose" resultMap="CourseResult">
SELECT * FROM COURSES
<choose>
<when test="searchBy == 'Tutor'">
WHERE TUTOR_ID = #{tutorId}
</when>
<when test="searchBy == 'CourseName'">
WHERE name like #{courseName}
</when>
<otherwise>
WHERE start_date >= sysdate
</otherwise>
</choose>
</select>
解释:在查询时首先判断是根据什么内容进行查询,然后再考虑由那一部分组成SQL语句,有点类似于Java基础的try catch语句;
3,<where>,使所有的查询条件变得可选。
<select id="searchCourseByWhere" resultMap="CourseResult">
SELECT * FROM COURSES
<where>
<if test="tutorId != null ">
TUTOR_ID= #{tutorId}
</if>
<if test="courseName != null">
AND name like #{courseName}
</if>
<if test="startDate != null">
AND start_date >= #{startDate}
</if>
</where>
</select>
解释:查询的任何条件都是可选的,纵然是都不选,传进来的map集合是个空的,也能运行,查询所有数据;
<where>元素只有在其内部标签有返回内容时才会在动态语句上插入WHERE条件语句。 并且,如果WHERE子句以AND或者OR打头,则打头的AND或OR将会被移除。
4,<trim>提供了添加 前缀/后缀 或者 移除 前缀/后缀 的功能
<select id="searchCourseByTrim" resultMap="CourseResult">
SELECT * FROM COURSES
<trim prefix="WHERE" suffixOverrides="and">
<if test=" tutorId != null ">
TUTOR_ID = #{tutorId} and
</if>
<if test="courseName != null">
name like #{courseName} and
</if>
</trim>
</select>
解释:与where类似,但是更加灵活;
prefix表示有一个if成立则插入where语句
suffix表示后缀,和prefix相反
suffixOverrides="and"表示如果最后生成的sql语句多一个and,则自动去掉. prefixOverrides的意思是处理前缀,和suffixOverrides相反
5,<foreach>可以迭代遍历一个数组或者集合,构造AND/OR条件或一个IN子句
<select id="searchCourseByForeach" resultMap="CourseResult">
SELECT * FROM COURSES
<if test="tutorIds != null">
<where>
<foreach item="tutorId" collection="tutorIds">
OR tutor_id = #{tutorId}
</foreach>
</where>
</if>
</select>
另一种更常用的形式:
<select id="searchCourseByForeach" resultMap="CourseResult">
SELECT * FROM COURSES
<if test="tutorIds != null">
<where>
tutor_id IN
<foreach item="tempValue" collection="tutorIds" open="("
separator="," close=")">
#{tempValue}
</foreach>
</where>
</if>
</select>
解释:主要是用来处理参数中的集合;
6,<set>和 <where>元素类似,但是set元素只是针对update更新语句使用
<update id="updateCourseByForeach">
update students
<set>
<if test="name != null">name=#{name},</if>
<if test="email != null">email=#{email},</if>
<if test="phone != null">phone=#{phone},</if>
</set>
where id=#{studId}
</update>
如果<if>条件返回了任何文本内容, <set>将会插入set关键字和其文本内容,并且会剔 除将末尾的逗号。
总结:动态SQL就像是针对SQL语句的拼接,在不同的情景下,拼出不同的SQL语句,适应多变的场景,我们只需要保证拼接出来的SQL的正确性即课;
缓存
-
存在内存中的临时数据。
-
将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,
-
从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
使用缓存的目的:减少和数据库的交互次数,减少系统开销,提高系统效率
mybatis缓存:
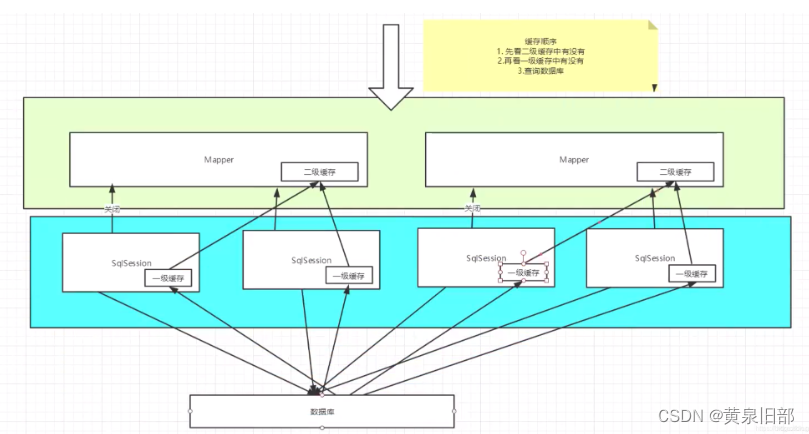
MyBatis包含一个非常强大的查询缓存特性,它可以非常方便地定制和配置缓存。缓存可以极大的提升查询效率。
MyBatis系统中默认定义了两级缓存:一级缓存和二级缓存
-
默认情况下,只有一级缓存开启。(SqlSession级别的缓存,也称为本地缓存)
-
二级缓存需要手动开启和配置,他是基于namespace级别的缓存。
-
为了提扩展性,MyBatis定义了缓存接口Cache。我们可以通过实现Cache接口来自定义二级缓存
ps:对于缓存,了解就好,知到这个机制;
枚举类型
MyBatis支持持久化enum类型属性。
默认情况下MyBatis使用 EnumTypeHandler 来处理enum类型的Java属性,并且将其存储为enum值的名 称。
我们不需要为此做任何额外的配置。可以像使用基本数据类型属性一样使用enum类型属性。
CLOB/
目录
BLOB
BLOB和CLOB都是大字段类型。
BLOB是按二进制来存储的,而CLOB是可以直接存储文字的。 通常像图片、文件、音乐等信息就用BLOB字段来存储,先将文件转为二进制再存储进去。文章或者是较长的文字,就用CLOB存储.
BLOB和CLOB在不同的数据库中对应的类型也不一样:
-
在MySQL中,clob对应text/longtext,
-
blob对应blob 在Oracle中,clob对应clob,blob对应blob
MyBatis提供了内建的对CLOB/BLOB类型列的映射处理支持,无需我们额外配置和操作。















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









