






 本文介绍了一种使用Python和pandas库对2004年至2016年的流感数据进行清洗、整合的方法,并展示了如何从多个CSV文件中读取数据、处理缺失值以及标准化地区名称的过程。
本文介绍了一种使用Python和pandas库对2004年至2016年的流感数据进行清洗、整合的方法,并展示了如何从多个CSV文件中读取数据、处理缺失值以及标准化地区名称的过程。
文章目录
一、目的
- 读取2004-2016年的流感数据,并拼接为一个数据框
- 读入人口数据,按年份和地区对流感数据填充人口数
使用工具:pandas,jupyter
编程语言:python3
二、代码步骤
1.引入库
代码如下:
import pandas as pd
import numpy as np
import os
import re2.小数据预处理
首先读取2004年的数据,并展示查看数据查看其格式。
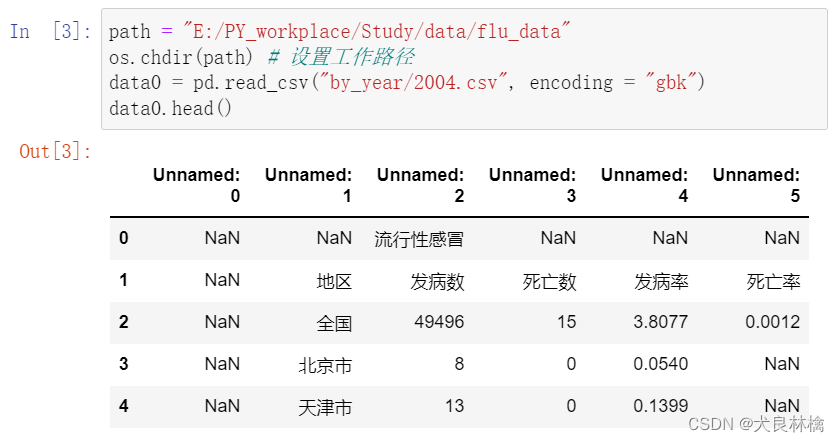
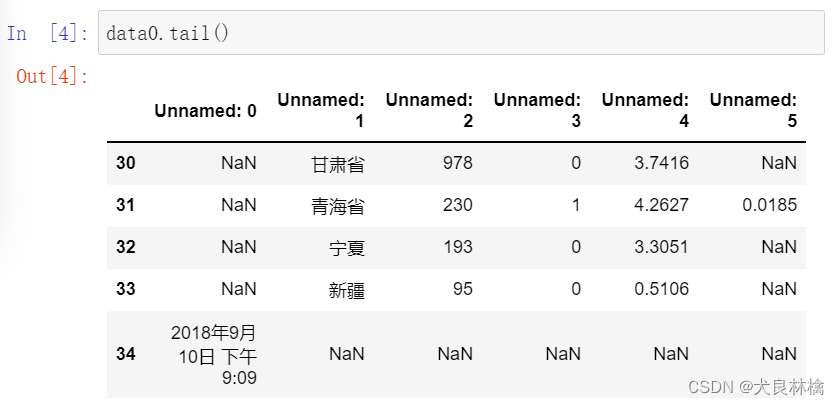
数据框的列名与实际需要的列名不符,并且数据框头尾均有不需要的空行。
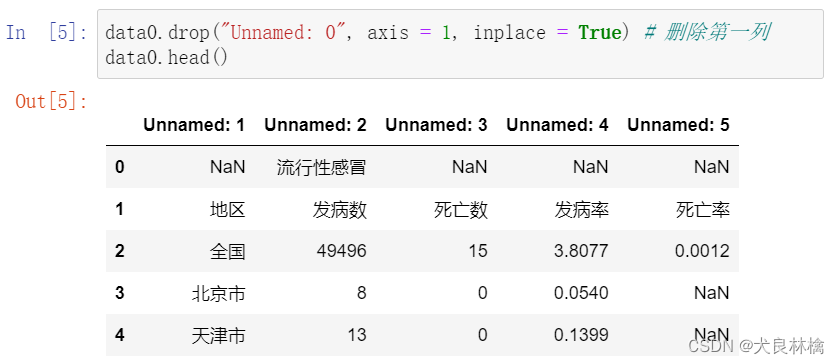
操作1:删除空列
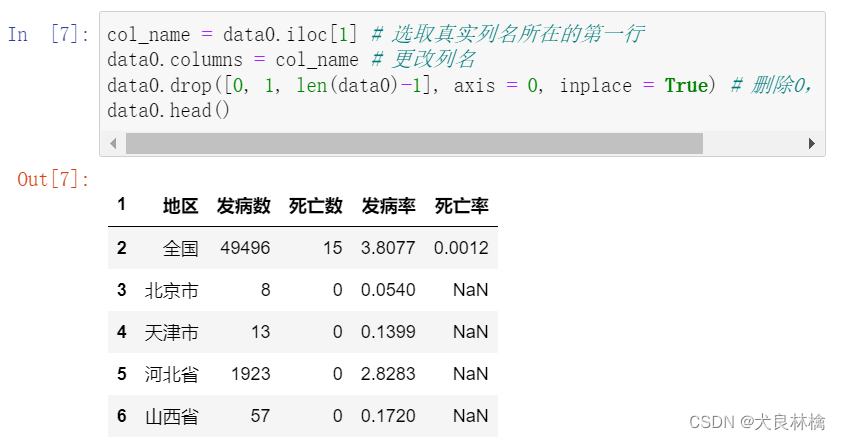
操作2:更改列名并删除多余行
操作3:重置index,并新增年份变量。
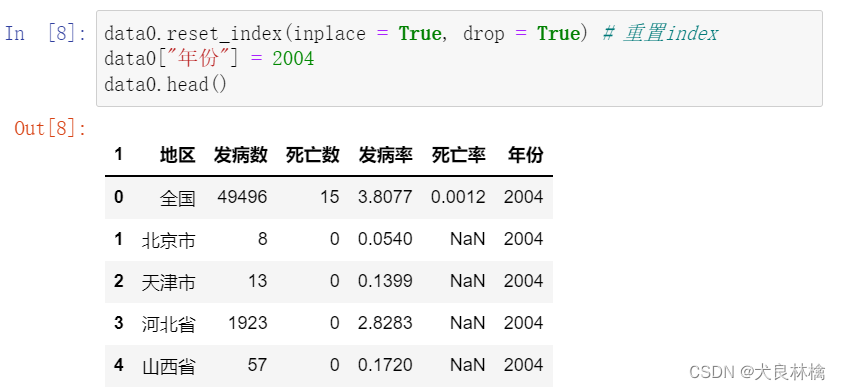
针对对第一年数据的预处理,我们可以知道对后续的数据的预处理操作,于是在这里自定义函数用于对后几年的数据进行预处理和重塑变量。
# 自定义函数对后续数据进行预处理
# input
# data:数据
# year:年份
# output:df
def Preprocess(data, year):
data.drop("Unnamed: 0", axis = 1, inplace = True) # 删除第0列
col_name = data.iloc[1]
data.columns = col_name # 重置列名
data.drop([0, 1, len(data)-1], axis = 0, inplace = True) # 删除0,1和最后一行
data.reset_index(inplace = True, drop = True) # 重置index
data["年份"] = year
return (data)
# 自定义函数进行批量读取拼接数据
# input
# file_name: 数据文件名
# this_path: 当前数据文件
# output: 拼接后的数据
def ReadData(file_name, this_path):
data_list = [];
# 循环遍历文件名
for i in range(len(file_name)):
data = pd.read_csv(this_path + file_name[i], encoding = "gbk")
year = 2004 + i + 1
Preprocess(data, year)
data_list.append(data)
other_data = pd.concat(data_list)
return(other_data) # concat合并list数据 3.流感数据批量处理
1.读入并拼接数据
在进行批量读取数据之前我们先获取需要读取的文件名,通过`os.listdir`得到数据的文件名列表,并删除之前已经读取过的2004年的数据。
代码如下:
file_name = os.listdir('by_year') # by_year文件夹内的文件名
file_name.remove('2004.csv')
file_name
读入2005-2016的流感数据
代码如下:
other_data = ReadData(file_name, "by_year/")
other_data.head()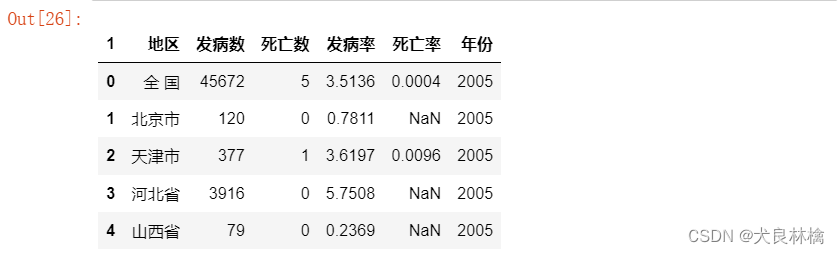
接下来就可以直接通过concat那两份数据连接起来,这里需要注意的是连接的数据需要放在一个list内。而且我们可以发现数据中存在部分的缺失值,在这里我们使用0对缺失值进行填补。
代码如下:
flu_data = pd.concat([data0, other_data]) # 连接所有数据
flu_data.fillna(0, inplace = True) # 用0填充缺失值
flu_data.head()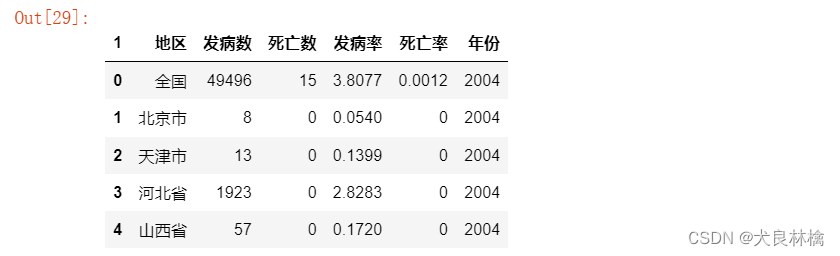
2.检查拼接后的数据
到这一步的时候,我们的第一个流感数据就算是大概出来了,但是该数据也不太规整,所以我们先对地区这一列进行一个计数,用于检查。
代码如下:
flu_data["地区"].value_counts() # 对地区这一列计数
通过输出现象可以看出数据缺失存在一些问题,如部分数据中存在空格;黑龙江有“黑龙江”和“黑龙江省”两种表现形式;在人口数据中没有建设兵团这一类型,需要删除这一类型所在的行。针对这些问题我们还需要进行预处理。
代码如下:
flu_data["地区"] = flu_data["地区"].apply(lambda x: x.replace(" ", "")) # 替换空格
flu_data = flu_data.loc[flu_data["地区"] != "建设兵团"] # 删除建设兵团的行
flu_data.loc[flu_data["地区"] == '黑龙江', '地区'] = '黑龙江省' # 统一地区名
flu_data["地区"].value_counts()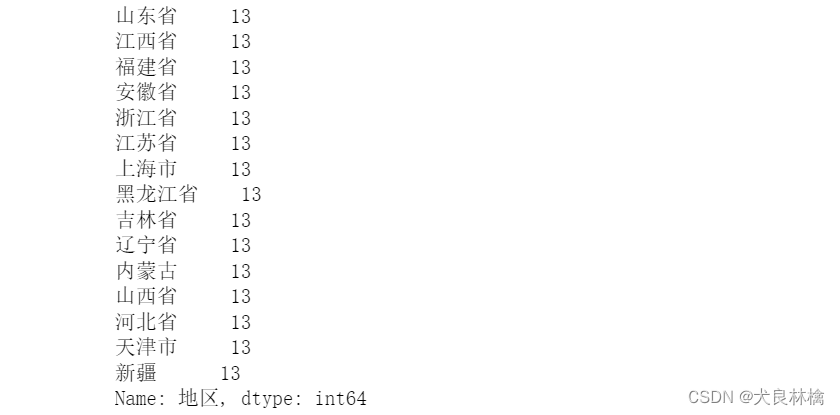
可见进行处理的地区变量的每一项均为13个,对应读入的13年的数据,说明数据处理规范。
4.人口数据的清洗与重塑
1.数据读入
读取人口数据,并展示查看它的前后5行。
代码如下:
cols = list(range(0, 14))
people = pd.read_csv("people.csv", encoding = "gbk", skiprows = 3, nrows = 31, usecols = cols)
people.head()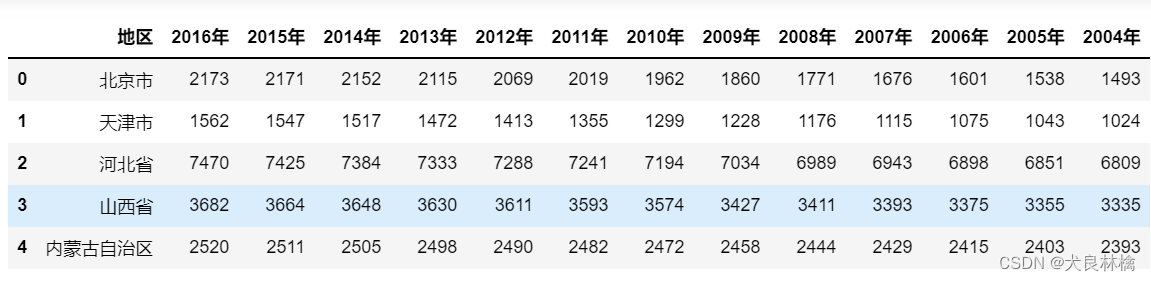
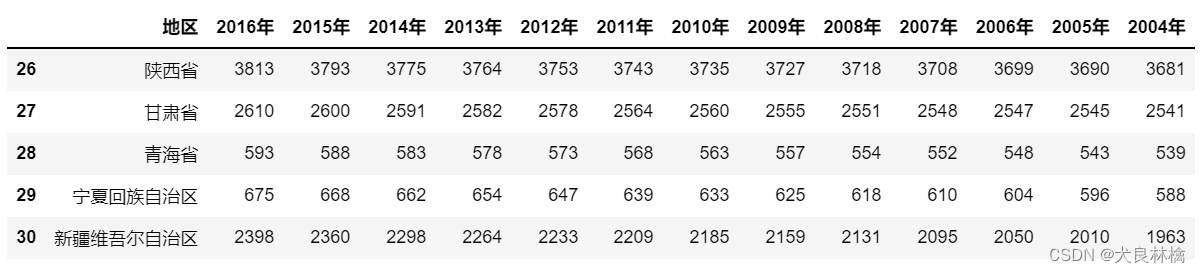
通过观察数据,我们可以发现人口数据的部分地区名与流感数据的地区名不一致,比如对于内蒙古,流感数据中的表现形式为“内蒙古”,而人口数据中的表现形式为“内蒙古自治区”。而后续对流感数据填充人口数时需要同时通过地区和年份两值进行填充,因此需要对统一二者地区名的格式,在这里选择统一对人口数据去掉“自治区”三个字进行处理。
代码如下:
people.loc[people['地区'] == '内蒙古自治区', '地区'] = '内蒙古'
people.loc[people['地区'] == '广西壮族自治区', '地区'] = '广西'
people.loc[people['地区'] == '西藏自治区', '地区'] = '西藏'
people.loc[people['地区'] == '宁夏回族自治区', '地区'] = '宁夏'
people.loc[people['地区'] == '新疆维吾尔自治区', '地区'] = '新疆'
2.拼接数据
将宽数据变为长数据
代码如下:
peo_name = list(people.columns)
peo_name.remove("地区")
change_people = pd.melt(people, id_vars = ["地区"], value_vars = peo_name,
var_name = "年份", value_name = "总人口数")
change_people["年份"] = change_people["年份"].apply(lambda x: re.findall("\d+", x)[0])
change_people["年份"] = change_people["年份"].astype(np.int)
change_people.head()
使用merge函数,按年份和地区对值进填充
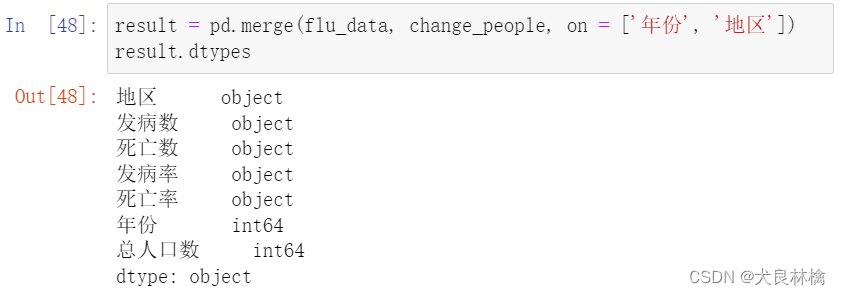
拼接成功



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









