







数据可视化开发是指将数据呈现为漂亮的统计图表,然后进一步发现数据中包含的规律以及隐藏的信息。数据可视化开发跟数据挖掘和大数据分析紧密相关,这些领域以及当下被热议的“深度学习”其最终的目标都是为了实现从过去的数据去对未来的状况进行分析和预测以及可视化展现。
天气数据是每个人基本都会关注的,具体到个人,主要是为了预防疾病,尤其是感冒,关注天气变化,加减衣服。而且很重要的一点是,如果要去外地,更要知道当地是什么天气情况,决定穿衣和携带的衣服。特别是突然下雨或者降温,加减衣服不当很容易生病。所以对其进行预测是很重要的
2.1 数据获取
在“getweather.py”文件中
采用requests.get()方法,请求网页,如果成功访问,则得到的是网页的所有字符串文本
添加了文字的输出让我们能直观地看到访问是否成功
def getHTMLtext(url):
"""请求获得网页内容"""
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding # 是中文正常显示
print("访问成功")
return r.text
except:
print("访问失败")
return " "主函数部分则是存好需要的链接,获取到需要的html文件方便后续使用
def main():
"""主函数"""
print("武汉天气数据获取")
url1 = 'http://www.weather.com.cn/weather/101200101.shtml' # 7天天气中国天气网
url2 = 'http://www.weather.com.cn/weather15d/101200101.shtml' # 8-15天天气中国天气网
url_m1 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202201.html'
url_m2 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202202.html'
url_m3 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202203.html'
url_m4 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202204.html'
url_m5 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202205.html' # 天气后报网2022年1~5月
html1 = getHTMLtext(url1)
data1, data1_7 = get_content(html1) # 获得1-7天和当天的数据
html2 = getHTMLtext(url2)
data8_14 = get_content2(html2) # 获得8-14天数据
data14 = data1_7 + data8_142.2 数据预处理
因为天气预报7天,8-15天,天气后报三个网页的格式不同,所以需要写三个处理的函数。
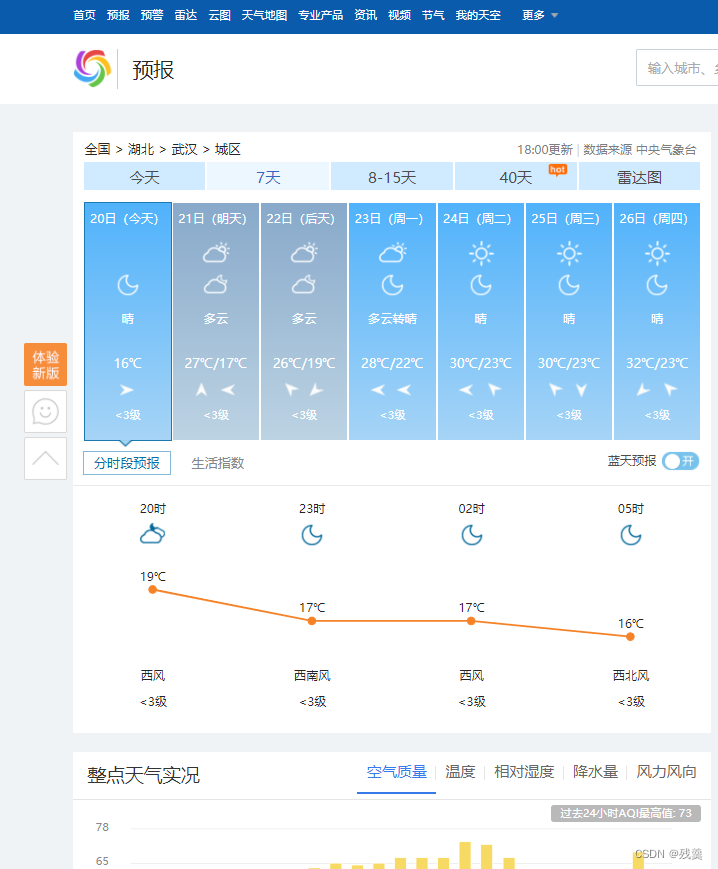



天气预报部分
先建立一个列表储存数据,创建BeautifulSoup对象
def get_content(html): # getHTMLtext返回的文件是此函数的参数
"""处理得到有用信息保存数据文件,1-7天和当天的数据"""
final = [] # 初始化一个列表保存数据class为left-div里面找所有的div
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body使用网页的开发者工具找到找到需要的数据所在位置
当天的数据在'left-div'中,存在data2中
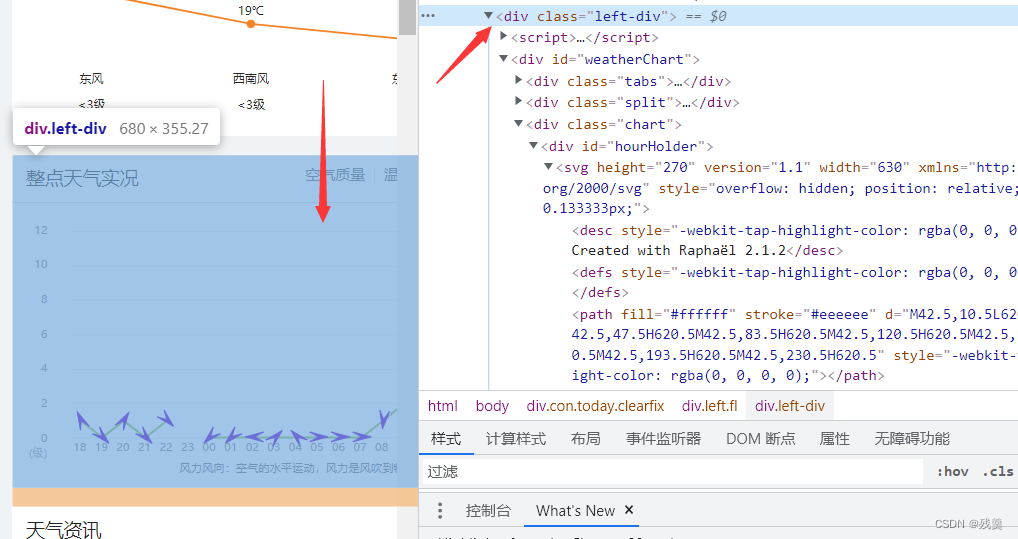
data2 = body.find_all('div', {'class': 'left-div'})首先爬取当天的数据
因为存放当天数据的div是第三个,所以取data2[2]中的文本
text = data2[2].find('script').string# 移除改var data=将其变为json数据
text = text[text.index('=') + 1:-2] # 移除改var data=将其变为json数据
jd = json.loads(text)
dayone = jd['od']['od2'] # 找到当天的数据
final_day = [] # 存放当天的数据将24小时的数据爬下来,存进final_day中(od是网页中的标签名)
count = 0
for i in dayone:
temp = []
if count <= 23:
temp.append(i['od21']) # 添加时间
temp.append(i['od22']) # 添加当前时刻温度
temp.append(i['od24']) # 添加当前时刻风力方向
temp.append(i['od25']) # 添加当前时刻风级
temp.append(i['od26']) # 添加当前时刻降水量
temp.append(i['od27']) # 添加当前时刻相对湿度
temp.append(i['od28']) # 添加当前时刻控制质量
# print(temp)
final_day.append(temp)
count = count + 1下面爬7天的数据
可以看到7天的数据在id为“7d”的div中,存在data中
# 下面爬取7天的数据
ul = data.find('ul') # ul 里是在data里找到第一个的ul标签
li = ul.find_all('li') # li 里是在ul里找到所有的li标签并且存在ul和li标签里,所以使用一个循环来遍历每一天的数据,将每一项数据取出并进行预处理
具体在注释中
i = 0 # 控制爬取的天数
for day in li: # 遍历找到的每一个li
if i < 7 and i > 0:
# for i in range(7):
temp = [] # 临时存放每天的数据
date = day.find('h1').string # 得到日期
date = date[0:date.index('日') + 1] # 为从开头到“日”在date总的索引号->取出日期号
temp.append(date) # append:在列表末尾添加新的对象
inf = day.find_all('p') # 找出li下面的p标签,提取第一个p标签的值,即天气
temp.append(inf[0].string) # temp后面加上inf第一项(第一个p)中的文本
tem_low = i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3775
3775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









