







一、创建RDD
1、textFile(url)从文件系统中加载数据创建RDD:
url可以是本地文件系统的地址,也可以是分布式文件系统DFS,亦或是Amazon S3地址。
from pyspark import SparkContext,SparkConf
#从本地文件系统
lines = sc.textFile("file:///root/class/score.txt")
#从分布式文件系统,下面三种写法等价
lines = sc.textFile("hdfs://localhost:9000/usr/local/score.txt")
lines = sc.textFile("/usr/local/score.txt")
lines = sc.textFile("score.txt")
上面本地文件系统 file:///root/class/score.txt 中file://相当于网页http:// ,而后面 /root是绝对地址。
2、通过并行集合创建RDD
parallelize()从一个已存在的集合(列表)上创建RDD
array = [1,2,3,4]
rdd = sc.parallelize(array)
rdd.collect()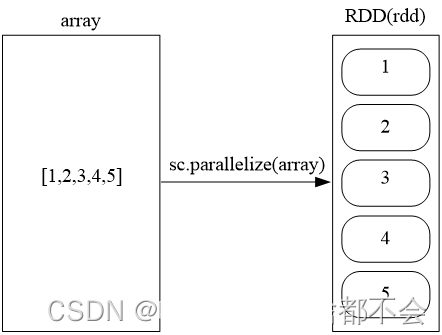
二、RDD操作
rdd的操作分为转换(transformation)以及行动(action)。
1、转换(transformation)
对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用 转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。
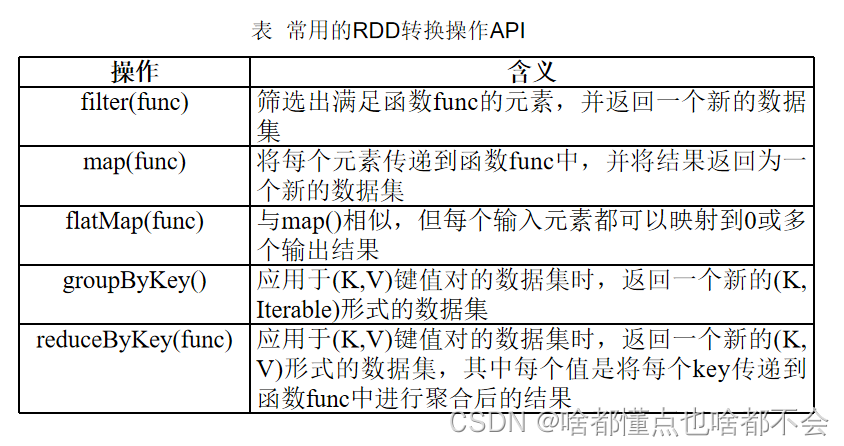
1、1 filter(func):筛选出满足函数func的元素,并返回一个新的数据
lines = sc.textFile("file:///usr/local/word.txt")
lines_1 = lines.filter(lambda line: "Spark" in line)
lines_1.collect()

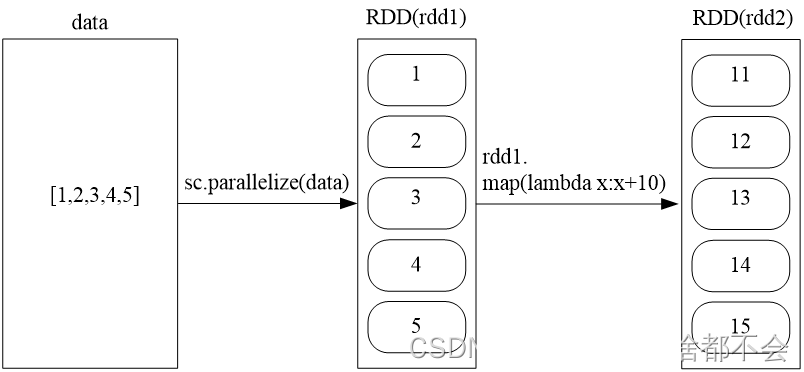
1、2 map(func):操作将每个元素传递到函数func中,并将结果返回为一个新的数据集
data = [1,2,3,4,5]
rdd1 = sc.parallelize(data)
rdd2 = rdd1.map(lambda x:x+10)
rdd2.collect()
1、3 flatMap(func)
#map()
lines = sc.textFile("file:///usr/local/word.txt")
words = lines.map(lambda line:line.split(" "))
words.collect()
#flatMap()
words = lines.flatMap(lambda line:line.split(" "))
words.collect()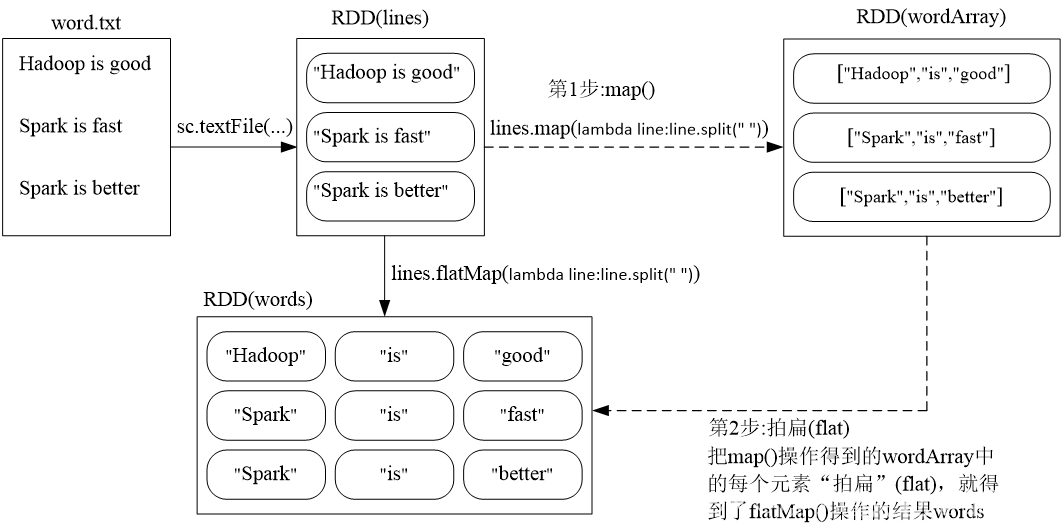
1、4 groupByKey():应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
words = sc.parallelize([("Hadoop",1),("is",1),("good",1), \
... ("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
words1 = words.groupByKey()
words1.collcet()
#输出
('Hadoop', <pyspark.resultiterable.ResultIterable object at 0x7fb210552c88>)
('better', <pyspark.resultiterable.ResultIterable object at 0x7fb210552e80>)
('fast', <pyspark.resultiterable.ResultIterable object at 0x7fb210552c88>)
('good', <pyspark.resultiterable.ResultIterable object at 0x7fb210552c88>)
('Spark', <pyspark.resultiterable.ResultIterable object at 0x7fb210552f98>)
('is', <pyspark.resultiterable.ResultIterable object at 0x7fb210552e10>)

可以这么理解, 例如(‘is',1)、(‘is',1)、(‘is',1)三个元素的key一样,groupByKey()将三个进行合并生成 (’is',(1,1,1)),这个时候key为is,value为(1,1,1),最后将vlaue封装成Iterable对象(可迭代对象)。
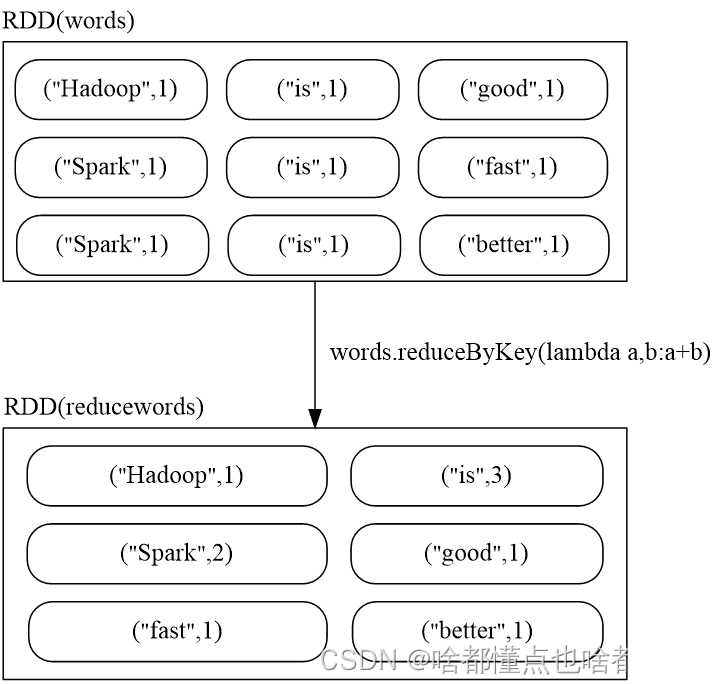
1、6 reduceByKey(func):应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果
words = sc.parallelize([("Hadoop",1),("is",1),("good",1),("Spark",1), \
... ("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
\words1 = words.reduceByKey(lambda a,b:a+b)
words1.collect()
#输出
('good', 1)
('Hadoop', 1)
('better', 1)
('Spark', 2)
('fast', 1)
('is', 3)
2、行动(action)
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
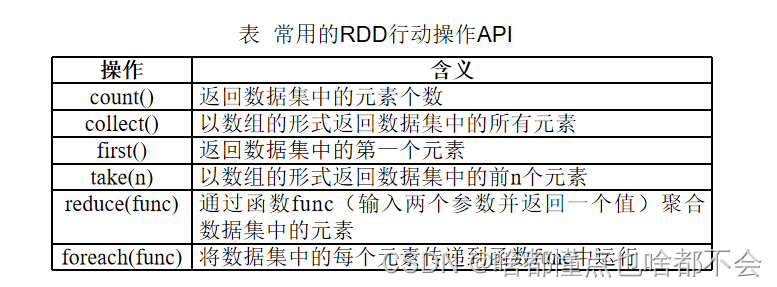
rdd = sc.parallelize([1,2,3,4,5])
rdd.count() #输出:5
rdd.first() #输出:1
rdd.take(3) #输出:[1, 2, 3]
rdd.reduce(lambda a,b:a+b) #输出:15
rdd.collect() #输出:[1, 2, 3, 4, 5]
rdd.foreach(print)
#输出:
1
2
3
4
5
三、持久化
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据。
list = ["Hadoop","Spark","Hive"]
rdd = sc.parallelize(list)
print(rdd.count()) //行动操作,触发一次真正从头到尾的计算 3
print(','.join(rdd.collect())) //行动操作,触发一次真正从头到尾的计算 Hadoop,Spark,Hive
可以通过持久化(缓存)机制避免这种重复计算的开销
可以使用persist()方法对一个RDD标记为持久化 。之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化 持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
四、分区
1、分区的作用
- 增加并行度
- 减少通信开销
2、分区原则
RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目
对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
*本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
*Apache Mesos:默认的分区数为8
*Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值
3、设置分区个数
3、1 创建RDD时手动指定分区个数
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下: sc.textFile(path, partitionNum) 其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。
3、2 使用reparititon方法重新设置分区个数
通过转换操作得到新 RDD 时,直接调用 repartition 方法即可。例如:
rdd_1 = sc.parallelize([1,2,4,5,6,7],3) #第一种方法
rdd_1.glom().collect() #读取数据
#输出: [[1, 2], [4, 5], [6, 7]]
rdd_2 = rdd_1.repartition(1) #第二种方法
rdd_2.glom().collect()
#输出: [[1, 2, 4, 5, 6, 7]]
















 1468
1468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











