







Shell基础编程
1、函数
1.1、定义
- Shell 函数的命名规则和变量一样。
- 一个函数必须至少包含一条命令。
#!/bin/bash
TITLE="System Information Report For $HOSTNAME"
CURRENT_TIME=$(date +"%x %r %Z")
TIME_STAMP="Generated $CURRENT_TIME, by $USER"
report_uptime () { # 函数1
return
}
report_disk_space () { # 函数2
return
}
report_home_space () { # 函数3
return
}
cat << _EOF_
<HTML>
<HEAD>
<TITLE>$TITLE</TITLE>
</HEAD>
<BODY>
<H1>$TITLE</H1>
<P>$TIME_STAMP</P>
$(report_uptime)
$(report_disk_space)
$(report_home_space)
</BODY>
</HTML>
_EOF_
运行结果:
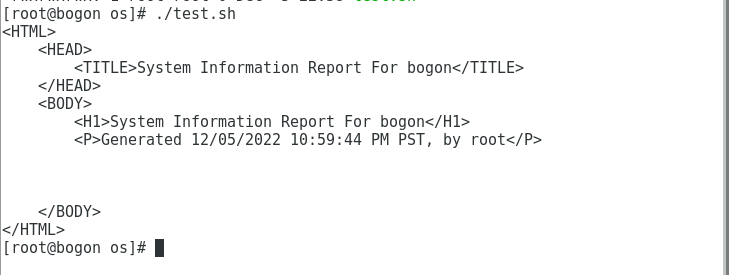
1.2、局部变量
通过在变量名之前加上单词 local,来定义局部变量。这就创建了一个 只对其所在的 shell 函数起作用的变量。在这个 shell 函数之外,这个变量不再存在。
#!/bin/bash
foo=0 # 全局变量 foo
funct_1 () {
local foo # 局部变量 foo
foo=1
echo "funct_1: foo = $foo"
}
funct_2 () {
local foo # 局部变量 foo
foo=2
echo "funct_2: foo = $foo"
}
echo "global: foo = $foo"
funct_1
echo "global: foo = $foo"
funct_2
echo "global: foo = $foo"
运行结果:
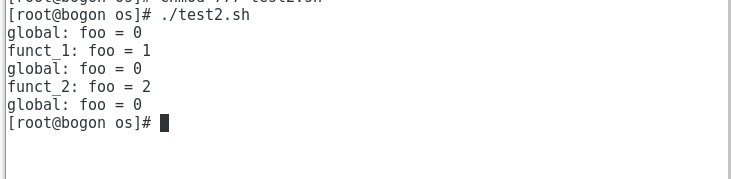
1.3、保持脚本运行
实际开发中,保持代码可执行是非常重要的,因此我们可能会在函数里只写一句return
完善1.1里的脚本文件
#!/bin/bash
# Program to output a system information page
TITLE="System Information Report For $HOSTNAME"
CURRENT_TIME=$(date +"%x %r %Z")
TIME_STAMP="Generated $CURRENT_TIME, by $USER"
report_uptime () {
cat <<- _EOF_
<H2>System Uptime</H2>
<PRE>$(uptime)</PRE>
_EOF_
return
}
report_disk_space () {
cat <<- _EOF_
<H2>Disk Space Utilization</H2>
<PRE>$(df -h)</PRE>
_EOF_
return
}
report_home_space () {
cat <<- _EOF_
<H2>Home Space Utilization</H2>
<PRE>$(du -sh /home/*)</PRE>
_EOF_
return
}
cat << _EOF_
<HTML>
<HEAD>
<TITLE>$TITLE</TITLE>
</HEAD>
<BODY>
<H1>$TITLE</H1>
<P>$TIME_STAMP</P>
$(report_uptime)
$(report_disk_space)
$(report_home_space)
</BODY>
</HTML>
_EOF_
执行结果:

2、流程控制
2.1、if
2.1.1、普通if
x=5
if [ $x = 5 ]; then
echo "x equals 5."
else
echo "x does not equal 5."
fi
[root@bogon os]# ./test4.sh
x equals 5.
2.1.2、多重if
x=3
if [ $x = 5 ]; then
echo "x = 5."
elif [ $x -lt 5 ]; then
echo "x < 5."
else
echo "x > 5."
fi
关于在shell中如何比较大小可以自行去搜索
2.1.3、嵌套if
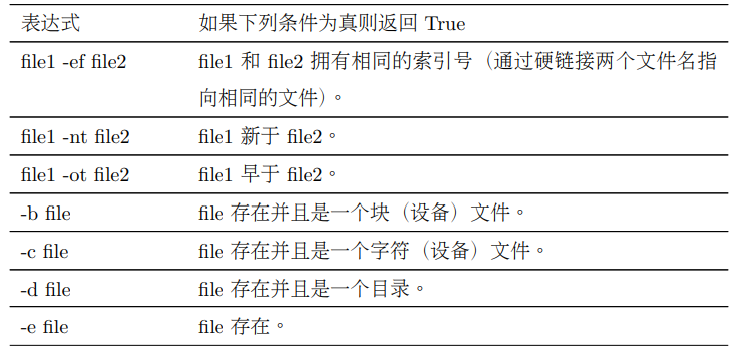
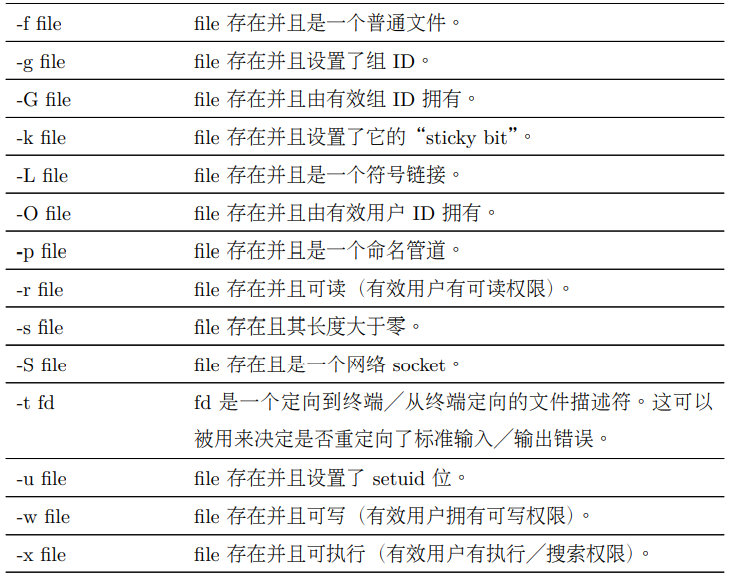
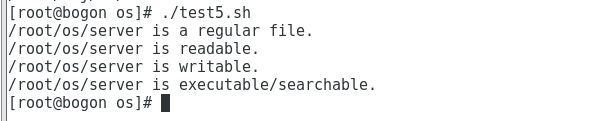
#!/bin/bash
FILE=/home/zwj/os/
if [ -e "$FILE" ]; then
if [ -f "$FILE" ]; then
echo "$FILE is a regular file."
fi
if [ -d "$FILE" ]; then
echo "$FILE is a directory."
fi
if [ -r "$FILE" ]; then
echo "$FILE is readable."
fi
if [ -w "$FILE" ]; then
echo "$FILE is writable."
fi
if [ -x "$FILE" ]; then
echo "$FILE is executable/searchable."
fi
else
echo "$FILE does not exist"
exit 1
fi
exit
判断条件中&&,||,!同样可用
2.2、常用表达式
2.2.1、整数

#!/bin/bash
INT=-5
if [ -z "$INT" ]; then
echo "INT is empty." >&2
exit 1
fi
if [ $INT -eq 0 ]; then
echo "INT is zero."
else
if [ $INT -lt 0 ]; then
echo "INT is negative."
else
echo "INT is positive."
fi
if [ $((INT % 2)) -eq 0 ]; then
echo "INT is even."
else
echo "INT is odd."
fi
fi
2.2.2、字符串
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZyBlFzpW-1670944537789)(null)]
#!/bin/bash
# test-string: evaluate the value of a string
ANSWER=maybe
if [ -z "$ANSWER" ]; then
echo "There is no answer." >&2
exit 1
fi
if [ "$ANSWER" = "yes" ]; then
echo "The answer is YES."
elif [ "$ANSWER" = "no" ]; then
echo "The answer is NO."
elif [ "$ANSWER" = "maybe" ]; then
echo "The answer is MAYBE."
else
echo "The answer is UNKNOWN."
fi
2.2.3、文件
在2.1.3嵌套if里
2.3、键盘输入
2.3.1、read
read 内部命令被用来从标准输入读取单行数据。这个命令可以用来读取键盘输入,当使用重定向的时候,读取文件中的一行数据。
# 语法格式
read [-options] [variable...]
这里的 options 是其可用选项中的一个或多个, variable 是用来存储输入数值的一个或多个变量名。
read常用选项:
- a array 把输入赋值到数组 array 中,从索引号0开始。
- -d delimiter 用字符串 delimiter 中的第一个字符指示输入结束,而不是 一个换行符。
- -e 使用 Readline 来处理输入。这使得与命令行相同的方式编 辑输入。
- -n num 读取 num 个输入字符,而不是整行。
- -p prompt 为输入显示提示信息,使用字符串 prompt。
- -r Raw mode. 不把反斜杠字符解释为转义字符。
- -s Silent mode. 不会在屏幕上显示输入的字符。当输入密码和 其它确认信息的时候,这会很有帮助。
- -t seconds 超时. 几秒钟后终止输入。若输入超时,read 会返回一个非 零退出状态。
- -u fd 使用文件描述符 fd 中的输入,而不是标准输入。
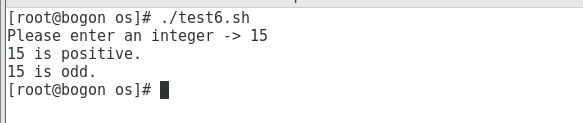
eg:读取一个整数
#!/bin/bash
# echo -n 相当于c里面的print,输出不换行
echo -n "Please enter an integer -> "
read int
if [[ "$int" =~ ^-?[0-9]+$ ]]; then
if [ $int -eq 0 ]; then
echo "$int is zero."
else
if [ $int -lt 0 ]; then
echo "$int is negative."
else
echo "$int is positive."
fi
if [ $((int % 2)) -eq 0 ]; then
echo "$int is even."
else
echo "$int is odd."
fi
fi
else
echo "Input value is not an integer." >&2
exit 1
fi
当我们读取一行信息赋值给多个变量时
#!/bin/bash
echo -n "Enter one or more values > "
read var1 var2 var3 var4 var5
echo "var1 = '$var1'"
echo "var2 = '$var2'"
echo "var3 = '$var3'"
echo "var4 = '$var4'"
echo "var5 = '$var5'"
运行结果
# 定义5个变量输入5个
Enter one or more values > a b c d e
var1 = 'a'
var2 = 'b'
var3 = 'c'
var4 = 'd'
var5 = 'e'
# 定义5个输入<5
Enter one or more values > a
var1 = 'a'
var2 = ''
var3 = ''
var4 = ''
var5 = ''
# 定义5个输入>5
Enter one or more values > a b c d e f g
var1 = 'a'
var2 = 'b'
var3 = 'c'
var4 = 'd'
var5 = 'e f g'
如果我们没有写变量名进行接收,则一个 shell 变量, REPLY将会包含所有的输入
#!/bin/bash
echo -n "Enter one or more values > "
read
echo "REPLY = '$REPLY'"
运行结果
Enter one or more values > a b c d
REPLY = 'a b c d'
2.3.2、IFS
通常,shell 对提供给 read 的输入按照单词进行分离。正如我们所见到的,这意味着多个由一 个或几个空格分离开的单词在输入行中变成独立的个体,并被 read 赋值给单独的变量。
这种行 为由 shell 变量 IFS (内部字符分隔符)配置。IFS的默认值包含一个空格,一个 tab,和一个换行符,每一个都会把字段分割开。 我们可以调整 IFS 的值来控制输入字段的分离。
例如,这个 /etc/passwd 文件包含的数据行使用冒号作为字段分隔符。通过把 IFS 的值更改为单个冒号,我们可以使用 read 读取 /etc/ passwd 中的内容,并成功地把字段分给不同的变量。
#!/bin/bash
FILE=/etc/passwd
read -p "Enter a user name > " user_name
# 这一行把 grep 命令的输入结果赋值给变量 file_info。
# grep 命令使用的正则表达式确保用户名只会在 /etc/passwd 文件中匹配一行。
file_info=$(grep "^$user_name:" $FILE)
if [ -n "$file_info" ]; then
# 以:为间隔读取file_info字符串并赋值
IFS=":" read user pw uid gid name home shell <<< "$file_info"
echo "User = '$user'"
echo "UID = '$uid'"
echo "GID = '$gid'"
echo "Full Name = '$name'"
echo "Home Dir. = '$home'"
echo "Shell = '$shell'"
else
echo "No such user '$user_name'" >&2
exit 1
fi

2.3.3、数据校验
在前面章节中的计算程序,我们已经这样做了一点儿,我们检查整数值,甄别空值和非数字字 符。
每次程序接受输入的时候,执行这类的程序检查非常重要,为的是避免无效数据。
#!/bin/bash
invalid_input () {
echo "Invalid input '$REPLY'" >&2
exit 1
}
read -p "Enter a single item > "
# input is empty (invalid)
[[ -z $REPLY ]] && invalid_input
# input is multiple items (invalid)
(( $(echo $REPLY | wc -w) > 1 )) && invalid_input
# is input a valid filename?
if [[ $REPLY =~ ^[-[:alnum:]\._]+$ ]]; then
echo "'$REPLY' is a valid filename."
if [[ -e $REPLY ]]; then
echo "And file '$REPLY' exists."
else
echo "However, file '$REPLY' does not exist."
fi
# 输入是浮点数吗
if [[ $REPLY =~ ^-?[[:digit:]]*\.[[:digit:]]+$ ]]; then
echo "'$REPLY' is a floating point number."
else
echo "'$REPLY' is not a floating point number."
fi
# 输入是整数吗
if [[ $REPLY =~ ^-?[[:digit:]]+$ ]]; then
echo "'$REPLY' is an integer."
else
echo "'$REPLY' is not an integer."
fi
else
echo "The string '$REPLY' is not a valid filename."
fi
这个脚本提示用户输入一个数字。随后,分析这个数字来决定它的内容。
2.3.4、菜单
一种常见的交互类型称为菜单驱动。在菜单驱动程序中,呈现给用户一系列选择,并要求用户选择一项。
例如,我们可以想象一个展示以下信息的程序:
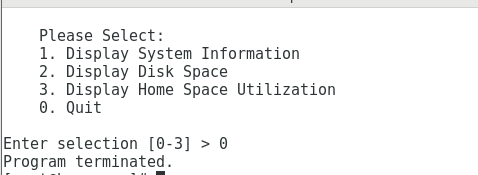
#!/bin/bash
# 首先清屏
clear
# 输出菜单选项
echo "
Please Select:
1. Display System Information
2. Display Disk Space
3. Display Home Space Utilization
0. Quit
"
# 接收选项
read -p "Enter selection [0-3] > "
# 根据选项执行不同任务
if [[ $REPLY =~ ^[0-3]$ ]]; then
if [[ $REPLY == 0 ]]; then
echo "Program terminated."
exit
fi
if [[ $REPLY == 1 ]]; then
echo "Hostname: $HOSTNAME"
uptime
exit
fi
if [[ $REPLY == 2 ]]; then
df -h
exit
fi
if [[ $REPLY == 3 ]]; then
if [[ $(id -u) -eq 0 ]]; then
echo "Home Space Utilization (All Users)"
du -sh /home/*
else
echo "Home Space Utilization ($USER)"
du -sh $HOME
fi
exit
fi
else
echo "Invalid entry." >&2
exit 1
fi
2.4、while/until
2.4.1、while
循环输出1-5
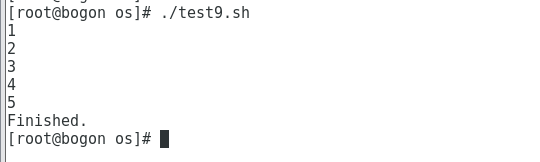
#!/bin/bash
count=1
while [ $count -le 5 ]; do
echo $count
count=$((count + 1))
done
echo "Finished."
在2.3.4的菜单一节中,我们的菜单运行任意一个指令后都会退出,如果想要执行多个操作就只能多运行几次脚本,可以用while循环来改进,只有输入0才会结束脚本!
#!/bin/bash
DELAY=3 # 显示结果停留的时间
while true; do
clear
echo "
Please Select:
1. Display System Information
2. Display Disk Space
3. Display Home Space Utilization
0. Quit
"
read -p "Enter selection [0-3] > "
if [[ $REPLY =~ ^[0-3]$ ]]; then
if [[ $REPLY == 1 ]]; then
echo "Hostname: $HOSTNAME"
uptime
sleep $DELAY
continue
fi
if [[ $REPLY == 2 ]]; then
df -h
sleep $DELAY
continue
fi
if [[ $REPLY == 3 ]]; then
if [[ $(id -u) -eq 0 ]]; then
echo "Home Space Utilization (All Users)"
du -sh /home/*
else
echo "Home Space Utilization ($USER)"
du -sh $HOME
fi
sleep $DELAY
continue
fi
if [[ $REPLY == 0 ]]; then
break
fi
else
echo "Invalid entry."
sleep $DELAY
fi
done
echo "Program terminated."
2.4.2、until
一个 until 循环会继续执行直到它接受了一个退出状态零。
在我们的循环输出1-5脚本 中,我们继续执行循环直到 count 变量的数值小于或等于 5。
#!/bin/bash
count=1
# count>5时mcount -gt 5 = 0
until [ $count -gt 5 ]; do
echo $count
count=$((count + 1))
done
echo "Finished."
2.4.3、使用循环读取文件
我们准备一个data.txt
20200741 朱文杰 河南周口
20200801 白冰玉 辽宁沈阳
shell脚本
#!/bin/bash
while read sno name address; do
printf "学号: %s\t姓名: %s\t地址: %s\n" \
$sno \
$name \
$address
done < data.txt
运行结果
[root@bogon os]# ./test11.sh
学号: 20200741 姓名: 朱文杰 地址: 河南周口
学号: 20200801 姓名: 白冰玉 地址: 辽宁沈阳
2.5、case
2.5.1、case改进菜单程序
#!/bin/bash
clear
echo "
Please Select:
1. Display System Information
2. Display Disk Space
3. Display Home Space Utilization
0. Quit
"
read -p "Enter selection [0-3] > "
case $REPLY in
0) echo "Program terminated."
exit
;;
1) echo "Hostname: $HOSTNAME"
uptime
;;
2) df -h
;;
3) if [[ $(id -u) -eq 0 ]]; then
echo "Home Space Utilization (All Users)"
du -sh /home/*
else
echo "Home Space Utilization ($USER)"
du -sh $HOME
fi
;;
*) echo "Invalid entry" >&2
exit 1
;;
esac
case 命令检查一个变量值,在我们这个例子中,就是 REPLY 变量的变量值,然后试图去 匹配其中一个具体的模式。
当与之相匹配的模式找到之后,就会执行与该模式相关联的命令。 若找到一个模式之后,就不会再继续寻找。
2.5.2、case常用模式
- a) 若单词为“a”,则匹配
- [[:alpha:]]) 若单词是一个字母字符,则匹配
- *.txt) 若单词以“.txt”字符结尾,则匹配
- ???) 若单词只有 3 个字符,则匹配
- *) 匹配任意单词。把这个模式做为 case 命令的最后一个模式, 是一个很好的做法,可以捕捉到任意一个与先前模式不匹配 的数值;也就是说,捕捉到任何可能的无效值。
2.5.3、case使用或
还可以使用竖线字符作为分隔符,把多个模式结合起来。
这就创建了一个“或”条件模式。 这对于处理诸如大小写字符很有用处。例如:
#!/bin/bash
# case-menu: a menu driven system information program
clear
echo "
Please Select:
A. Display System Information
B. Display Disk Space
C. Display Home Space Utilization
Q. Quit
"
read -p "Enter selection [A, B, C or Q] > "
case $REPLY in
q|Q) echo "Program terminated."
exit
;;
a|A) echo "Hostname: $HOSTNAME"
uptime
;;
b|B) df -h
;;
c|C) if [[ $(id -u) -eq 0 ]]; then
echo "Home Space Utilization (All Users)"
du -sh /home/*
else
echo "Home Space Utilization ($USER)"
du -sh $HOME
fi
;;
*) echo "Invalid entry" >&2
exit 1
;;
esac
这里,我们更改了 case-menu 程序的代码,用字母来代替数字做为菜单选项。
注意新模式 如何使得大小写字母都是有效的输入选项。
2.5.4、执行多个动作
有的时候,我们希望case去匹配一个之后,执行完成还能去匹配其它的函数
#!/bin/bash
# case4-2: test a character
read -n 1 -p "Type a character > "
echo
case $REPLY in
[[:upper:]]) echo "'$REPLY' is upper case." ;;&
[[:lower:]]) echo "'$REPLY' is lower case." ;;&
[[:alpha:]]) echo "'$REPLY' is alphabetic." ;;&
[[:digit:]]) echo "'$REPLY' is a digit." ;;&
[[:graph:]]) echo "'$REPLY' is a visible character." ;;&
[[:punct:]]) echo "'$REPLY' is a punctuation symbol." ;;&
[[:space:]]) echo "'$REPLY' is a whitespace character." ;;&
[[:xdigit:]]) echo "'$REPLY' is a hexadecimal digit." ;;&
esac
运行
Type a character > a
'a' is lower case.
'a' is alphabetic.
'a' is a visible character.
'a' is a hexadecimal digit.
添加的“;;&”的语法允许 case 语句继续执行下一条测试,而不是简单地终止运行。
2.6、for
2.6.1、传统shell格式
语法
for variable [in words]; do
commands
done
eg:
for i in A B C D;
do
echo $i;
done
result:
A
B
C
D
2.6.2、C语言格式
语法:
for (( expression1; expression2; expression3 ));
do
commands
done
eg:
#!/bin/bash
for (( i=0; i<5; i=i+1 ));
do
echo $i
done
result:
0
1
2
3
4
2.6.3、实战
改进1.3的代码
#!/bin/bash
TITLE="System Information Report For $HOSTNAME"
CURRENT_TIME=$(date +"%x %r %Z")
TIME_STAMP="Generated $CURRENT_TIME, by $USER"
report_uptime () {
cat <<- _EOF_
<H2>System Uptime</H2>
<PRE>$(uptime)</PRE>
_EOF_
return
}
report_disk_space () {
cat <<- _EOF_
<H2>Disk Space Utilization</H2>
<PRE>$(df -h)</PRE>
_EOF_
return
}
report_home_space () {
local format="%8s%10s%10s\n"
local i dir_list total_files total_dirs total_size user_name
if [[ $(id -u) -eq 0 ]]; then
dir_list=/home/*
user_name="All Users"
else
dir_list=$HOME
user_name=$USER
fi
echo "<H2>Home Space Utilization ($user_name)</H2>"
for i in $dir_list; do
total_files=$(find $i -type f | wc -l)
total_dirs=$(find $i -type d | wc -l)
total_size=$(du -sh $i | cut -f 1)
echo "<H3>$i</H3>"
echo "<PRE>"
printf "$format" "Dirs" "Files" "Size"
printf "$format" "----" "-----" "----"
printf "$format" $total_dirs $total_files $total_size
echo "</PRE>"
done
return
}
cat << _EOF_
<HTML>
<HEAD>
<TITLE>$TITLE</TITLE>
</HEAD>
<BODY>
<H1>$TITLE</H1>
<P>$TIME_STAMP</P>
$(report_uptime)
$(report_disk_space)
$(report_home_space)
</BODY>
</HTML>
_EOF_
3、数组
3.1、创建数组
[root@bogon os]# a[0]=foo
[root@bogon os]# echo ${a[0]}
foo
也可以使用declare命令创建数组
declare -a a
3.2、数组赋值
单个值赋值
name[subscript]=value
多个值赋值
#1
days=(Sun Mon Tue Wed Thu Fri Sat)
#2
days=([0]=Sun [1]=Mon [2]=Tue [3]=Wed [4]=Thu [5]=Fri [6]=Sat)
3.3、访问数组元素
有的时候我们需要检查一个特定 目录中文件的修改次数。
从这些数据中,我们的脚本将输出一张表,显示这些文件最后是在一 天中的哪个小时被修改的。
这样一个脚本可以被用来确定什么时段一个系统最活跃。
指定当前目录作为目标目录。它打印出一张表显示一天(0-23 小 时)每小时内,有多少文件做了最后修改。
eg:
#!/bin/bash
usage () {
echo "usage: $(basename $0) directory" >&2
}
# Check that argument is a directory
if [[ ! -d $1 ]]; then
usage
exit 1
fi
# Initialize array
for i in {0..23};
do
hours[i]=0;
done
# Collect data
for i in $(stat -c %y "$1"/* | cut -c 12-13);
do
j=${i/#0}
((++hours[j]))
((++count))
done
# Display data
echo -e "Hour\tFiles\tHour\tFiles"
echo -e "----\t-----\t----\t-----"
for i in {0..11}; do
j=$((i + 12))
printf "%02d\t%d\t%02d\t%d\n" $i ${hours[i]} $j ${hours[j]}
done
printf "\nTotal files = %d\n" $count
result:
Hour Files Hour Files
---- ----- ---- ----
00 0 12 11
01 1 13 7
02 0 14 1
03 0 15 7
04 1 16 6
04 1 17 5
06 6 18 4
07 3 19 4
08 1 20 1
09 14 21 0
10 2 22 0
11 5 23 0
Total files = 80
这个脚本由一个函数(名为 usage),和一个分为四个区块的主体组成。
在第一部分,我们检查是否有一个命令行参数,且该参数为目录。如果不是目录,会显示脚本使用信息并退出。
第二部分初始化一个名为 hours 的数组。给每一个数组元素赋值一个 0。虽然没有特殊需要 在使用之前准备数组,但是我们的脚本需要确保没有元素是空值。注意这个循环构建方式很有趣。通过使用花括号展开({0…23}),我们能很容易为 for 命令产生一系列的数据(words)。
接下来的一部分收集数据,对目录中的每一个文件运行 stat 程序。我们使用 cut 命令从结 果中抽取两位数字的小时字段。在循环里面,我们需要把小时字段开头的零清除掉,因为 shell 将试图(最终会失败)把从“00”到“09”的数值解释为八进制。
下一步,我们 以小时为数组索引,来增加其对应的数组元素的值。最后,我们增加一个计数器的值(count), 记录目录中总共的文件数目。 脚本的最后一部分显示数组中的内容。我们首先输出两行标题,然后进入一个循环产生两栏输出。最后,输出总共的文件数目。
3.4、数组操作
3.4.1、输出整个数组的内容
根据格式自行选择:
[root@bogon os]$ animals=("a dog" "a cat" "a fish")
[root@bogon os]$ for i in ${animals[*]}; do echo $i; done
a
dog
a
cat
a
fish
[root@bogon os]$ for i in ${animals[@]}; do echo $i; done
a
dog
a
cat
a
fish
[root@bogon os]$ for i in "${animals[*]}"; do echo $i; done
a dog a cat a fish
[root@bogon os]$ for i in "${animals[@]}"; do echo $i; done
a dog
a cat
a fish
3.4.2、确定数组元素个数
我们创建了数组 b,并把100赋值给数组元素 100。
下一步,我们使用参数展开 来检查数组的长度,使用 @ 表示法。
最后,我们查看了包含字符串“foo”的数组元素 100 的 长度。有趣的是,尽管我们把字符串赋值给数组元素 100,bash 仅仅报告数组中有一个元素。 这不同于一些其它语言的行为,这种行为是数组中未使用的元素(元素 0-99)会初始化为空值, 并把它们计入数组长度。
[root@bogon os]# b[100]=100
[root@bogon os]# echo ${#b[@]} # number of array elements
1
[root@bogon os]# echo ${#b[100]} # length of element 100
3
3.4.3、找到数组使用的下标
因为 bash 允许赋值的数组下标包含“间隔”,有时候确定哪个元素真正存在是很有用的。为做 到这一点,可以使用以下形式的参数展开: ${!array[*]} ${!array[@]} 这里的 array 是一个数组变量的名字。和其它使用符号 * 和 @ 的展开一样,用引号引起来 的 @ 格式是最有用的,因为它能展开成分离的词。
[root@bogon os]$ foo=([2]=a [4]=b [6]=c)
[root@bogon os]$ for i in "${foo[@]}"; do echo $i; done
a
b
c
[root@bogon os]$ for i in "${!foo[@]}"; do echo $i; done
2
4
6
3.4.4、在数组末尾添加元素
通过使用 += 赋值运算符,我们能够自动地把值附加到数组末尾。
这里,我们把三个值赋 给数组 foo,然后附加另外三个。
eg:
[me@linuxbox~]$ foo=(a b c)
[me@linuxbox~]$ echo ${foo[@]}
a b c
[me@linuxbox~]$ foo+=(d e f)
result:
[me@linuxbox~]$ echo ${foo[@]}
a b c d e
3.4.5、数组排序
eg:
#!/bin/bash
a=(f e d c b a)
echo "Original array: ${a[@]}"
a_sorted=($(for i in "${a[@]}"; do echo $i; done | sort))
echo "Sorted array: ${a_sorted[@]}"
result:
Original array: f e d c b a
Sorted array:
a b c d e f
3.4.6、删除数组
删除一个数组,使用 unset 命令:
# 删除数组
[root@bogon os]$ foo=(a b c d e f)
[root@bogon os]$ echo ${foo[@]}
a b c d e f
[root@bogon os]$ unset foo
[root@bogon os]$ echo ${foo[@]}
# 删除单个元素
[me@linuxbox~]$ foo=(a b c d e f)
[me@linuxbox~]$ echo ${foo[@]}
a b c d e f
[me@linuxbox~]$ unset 'foo[2]'
[me@linuxbox~]$ echo ${foo[@]}
a b d e f
任何没有对下标的引用索引都是0
# foo= <===> foo[0]=
[root@bogon os]$ foo=(a b c d e f)
[root@bogon os]$ foo=
[root@bogon os]$ echo ${foo[@]}
b c d e f
# foo=A <===> foo[0]=A
[me@linuxbox~]$ foo=(a b c d e f)
[me@linuxbox~]$ echo ${foo[@]}
a b c d e f
[me@linuxbox~]$ foo=A
[me@linuxbox~]$ echo ${foo[@]}
A b c d e f
3.5、关联数组
关联数组使用字符串而不是整数作为数组索引。这种功能给出了一种有趣的新方法来管理数据。
例如,我们可以创建一个叫做“colors”的数组,并 用颜色名字作为索引。
eg:
[root@bogon os]# declare -A colors
[root@bogon os]# colors["red"]="#ff0000"
[root@bogon os]# colors["green"]="#00ff00"
[root@bogon os]# colors["blue"]="#0000ff"
result:
[root@bogon os]# echo ${colors["blue"]}
#0000ff
4、实战
问题
做核酸检测前个人需要向核酸检测系统申报本人信息,填写本人姓名、身份证号、住址、电话等信息后提交,生成申报二维码,个人可以保存二维码备用。系统将所有申报信息保存在申报表persons.txt中。用于存放采集样本的每个试管都有条形码标识。核酸检测时,拿到一个新的试管时扫描试管上的条形码,试管的编号、采集地址、采集员、被采人本管序号、采集日期时间作为一条记录被添加到采集信息表sample.txt中。当被采人接受采集时,由扫码器扫描被采人的申报二维码,被采人的信息记录被从申报表persons.txt中检索出来添加到sample.txt中当前记录的被采人身份证号、被采人姓名、被采人本管序号、采集日期时间字段。一个试管可以容纳10个人的采样。采样结束,采集样品由专人检测。每个人的检测结果被添加到sample.txt中该人的检验员、检测日期时间、检测结果字段。个人可以凭身份证号查询自己的检测结果,检测结果显示自己的姓名、检测日期时间、检测结果。请编写Shell脚本实现如下功能:
(1)被采集人个人信息申报功能。填写个人信息,将个人信息保存在申报表persons.txt中。显示该表中的信息。
(2)核酸检测样本信息记录功能。每当采集核酸样本时,采样时,被采人提供身份证号,记录容纳该样本的试管信息、采集人信息和被采人信息及采集地址、采集日期时间等信息到采集信息表sample.txt中。显示该表中的信息。
(3)核酸样本检测结果记录功能。将检测结果记录到sample.txt中的检测结果和检测日期时间字段。显示该表中的信息。
(4)个人检测结果查询功能。个人输入身份证号或姓名,从sample.txt中查询和显示本人的检测结果信息。
分析
- 个人申报实际上就是根据用户填写的信息追加一行数据到persons.txt文件
实现:
# 用户输入姓名、身份证、地址、电话号码,追加到persons.txt文件中
add () { # 个人信息申报
read -p "请输入姓名-> " name
read -p "请输入身份证号-> " pid
read -p "请输入地址-> " address
read -p "请输入电话号码-> " tel
echo "$name|$pid|$address|$tel" >> persons.txt
echo "申报成功!"
getchar
return
}
- 信息记录功能实际上也是写一行数据到samples.txt,可以先将检测员等信息填为未知
实现:
# 用户给出试管号和身份证号,采集员给出其编号,采集地址,真实场景是扫码,不考虑身份证号不存在的情况
# 在persons.txt中找到这个身份证号对应的姓名写入,检测信息先置为未知
# 我认为采集员信息和检测员信息都应该是一个编号,详细信息对应在医护人员表中,因此这里我用编号来代替
example_record () { # 样本信息记录
read -p "请输入试管号-> " id
read -p "请输入采集人编号->" collect_id
read -p "请输入被采集人身份证号-> " pid
read -p "请输入采集地址-> " address
file_info=$(grep $pid persons.txt)
IFS="|" read name a b c <<< "$file_info"
echo "$id|$collect_id|$name|$pid|$address|$(date "+%Y-%m-%d-%H:%M:%S")|未知|未知|未知" >> sample.txt
echo "采集成功!"
getchar
return
}
- 检测结果记录实际上就是在文件中找到所有在这个管里的核酸记录,并将其写入相同的检测人、检测时间、检测结果
实现
# 首先输入试管号,查询出该试管对应的行数放入数组,更新数组里每一行的检测信息
update () { # 核酸结果记录
read -p "请输入试管号-> " id
read -p "请输入检测人编号-> " inspect_id
read -p "请输入核酸检测结果->" result
arr=(`cat -n sample.txt |grep $id|awk '{print $1}'`)
date=$(date "+%Y-%m-%d-s%H:%M:%S")
for (( i=0; i<${#arr[@]}; i=i+1 ));
do
sed -i ''${arr[i]}s'/未知|未知|未知/'$inspect_id'|'$date'|'$result'/g' sample.txt
done
echo "记录成功!"
getchar
return
}
- 核酸查询实际上就是从samples.txt中查找身份证号或姓名=输入信息的人
# 进行查找即可,真实业务不可能在txt里存数据,所以我默认每次核酸前都是先清空txt,所以身份证号每次一定只能查出来一个人,没考虑多条记录以及同名的情况
# 如果此时检测结果还没出,查询结果会是 姓名,身份证号,检测时间->未知,检测结果->未知
search () { # 查询核酸结果
read -p "请输入姓名或身份证号-> " option
file_info=$(grep $option sample.txt)
IFS="|" read a b name pid c d e time result <<< "$file_info"
echo "姓名-> $name 身份证号-> $pid 检测时间-> $time 检测结果-> $result"
getchar
return
}
解决
persons.txt
姓名|身份证号|住址|电话
bby|202024100801|辽宁沈阳|13575446031
zwj|202024100741|河南周口|16968564591
zqj|202024100737|河南长垣|15545689572
cxt|202024100802|陕西延安|19555555555
sample.txt
试管号|采集人编号|被采人姓名|被采人身份证|采集地址|采集时间|检测员编号|检测时间|检测结果
1|1001|zwj|202024100741|河南周口|2022-12-06-08:05:56|未知|未知|未知
1|1001|zwj|202024100741|河南周口|2022-12-06-08:05:56|未知|未知|未知
os.sh
#!/bin/bash
getchar () { # 吞掉一个字符
echo "请按任意键返回主菜单"
read -N 1 var1
return
}
add () { # 个人信息申报
read -p "请输入姓名-> " name
read -p "请输入身份证号-> " pid
read -p "请输入地址-> " address
read -p "请输入电话号码-> " tel
echo "$name|$pid|$address|$tel" >> persons.txt
echo "申报成功!"
getchar
return
}
example_record () { # 样本信息记录
read -p "请输入试管号-> " id
read -p "请输入采集人编号->" collect_id
read -p "请输入被采集人身份证号-> " pid
read -p "请输入采集地址-> " address
file_info=$(grep $pid persons.txt)
IFS="|" read name a b c <<< "$file_info"
echo "$id|$collect_id|$name|$pid|$address|$(date "+%Y-%m-%d-%H:%M:%S")|未知|未知|未知" >> sample.txt
echo "采集成功!"
getchar
return
}
update () { # 核酸结果记录
read -p "请输入试管号-> " id
read -p "请输入检测人编号-> " inspect_id
read -p "请输入核酸检测结果->" result
arr=(`cat -n sample.txt |grep $id|awk '{print $1}'`)
date=$(date "+%Y-%m-%d-s%H:%M:%S")
for (( i=0; i<${#arr[@]}; i=i+1 ));
do
sed -i ''${arr[i]}s'/未知|未知|未知/'$inspect_id'|'$date'|'$result'/g' sample.txt
done
echo "记录成功!"
getchar
return
}
search () { # 查询核酸结果
read -p "请输入姓名或身份证号-> " option
file_info=$(grep $option sample.txt)
IFS="|" read a b name pid c d e time result <<< "$file_info"
echo "姓名-> $name 身份证号-> $pid 检测时间-> $time 检测结果-> $result"
getchar
return
}
menu () { # 显示主菜单
while true;
do
clear
echo "
请选择:
1. 个人信息申报
2. 样本信息记录
3. 核酸结果记录
4. 核酸检查查询
0. 退出
"
read -p "请输入 [0-4] > "
case $REPLY in
0) echo "程序退出"
exit
;;
1) add
;;
2) example_record
;;
3) update
;;
4) search
;;
*) echo "无效输入!请重新选择" >&2
getchar
;;
esac
done
return
}
menu;















 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









