



 该文详细介绍了如何在Linux环境下安装配置Spark集群,包括上传安装包、解压、设置环境变量、修改配置文件如spark-defaults.conf和spark-env.sh,配置slaves文件,分发配置到所有节点,最后启动Spark并验证其运行情况,以及测试Spark-shell的启动。
该文详细介绍了如何在Linux环境下安装配置Spark集群,包括上传安装包、解压、设置环境变量、修改配置文件如spark-defaults.conf和spark-env.sh,配置slaves文件,分发配置到所有节点,最后启动Spark并验证其运行情况,以及测试Spark-shell的启动。
一、安装Spark集群环境
1.上传spark-2.4.5-bin-without-hadoop-scala-2.12文件到master节点的:/home目录下: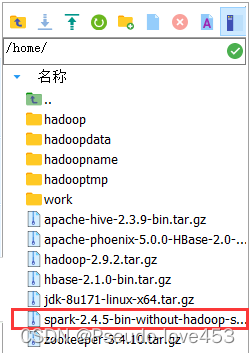
2.登录master节点,解压缩Spark安装部署文件到/opt目录下,并修改文件夹名称为:spark
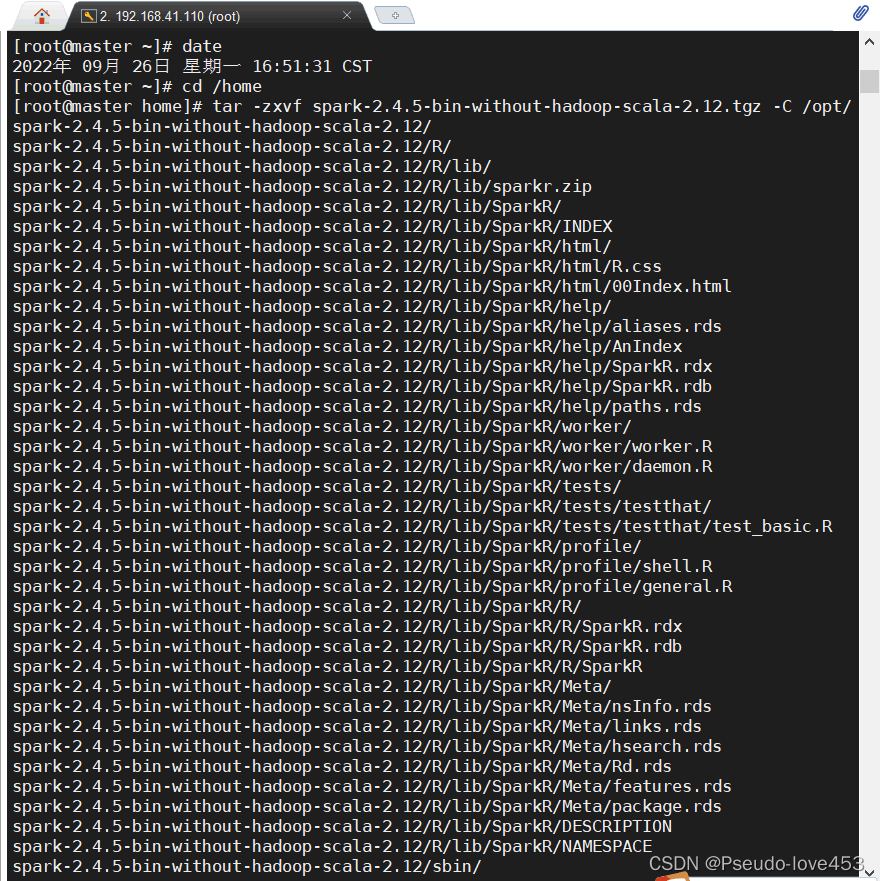
cd /home
tar -zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz -C /opt/
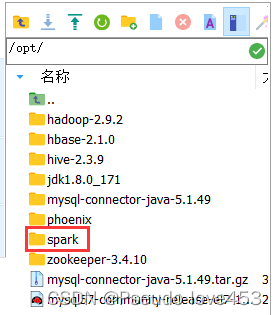
修改/opt/spark-2.4.5-bin-without-hadoop-scala-2.12/目录名称为spark:
cd /opt
mv spark-2.4.5-bin-without-hadoop-scala-2.12/ spark
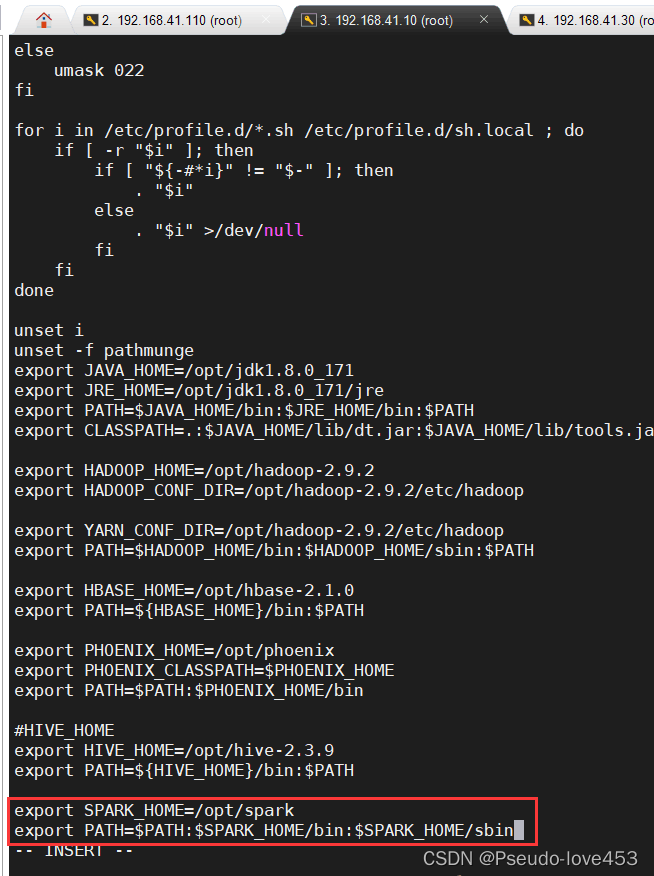
3.为集群所有节点配置相同的环境变量(master,slave1和slave2节点的环境变量):
vi /etc/profile
进入编辑状态,添加如下内容:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
4.登录master节点,修改Spark配置文件-1:
进入:/opt/spark/conf目录下,开始配置文件spark-defaults.conf(系统没有提供spark-defaults.conf文件,需要从spark-defaults.conf.template文件拷贝一份)
cd /opt/spark/conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
添加如下配置:
spark.master spark://master:7077
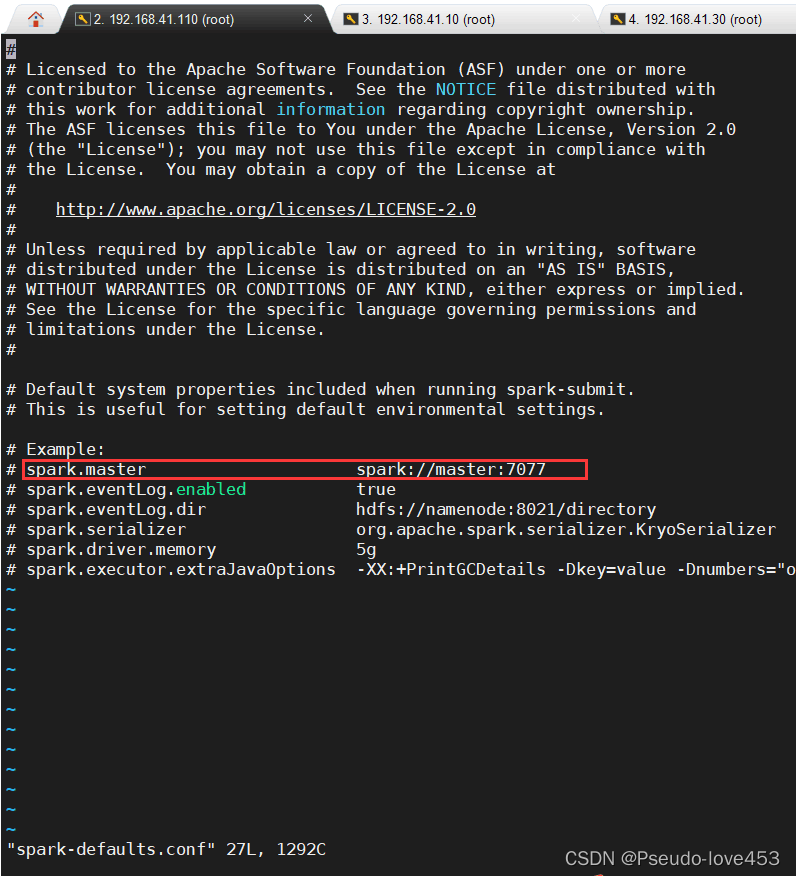
5.修改Spark配置文件-2
进入:/opt/spark/conf目录下,开始配置文件spark-env.sh(系统没有提供spark-env.sh文件,需要从spark-env.sh.template文件拷贝一份)
cd /opt/spark/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加如下配置:
export JAVA_HOME=/opt/jdk1.8.0_171/
export HADOOP_HOME=/opt/hadoop-2.9.2/
export HADOOP_CONF_DIR=/opt/hadoop-2.9.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.9.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
注:这里的jdk和hadoop版本号以及路径都要和自己的的对应
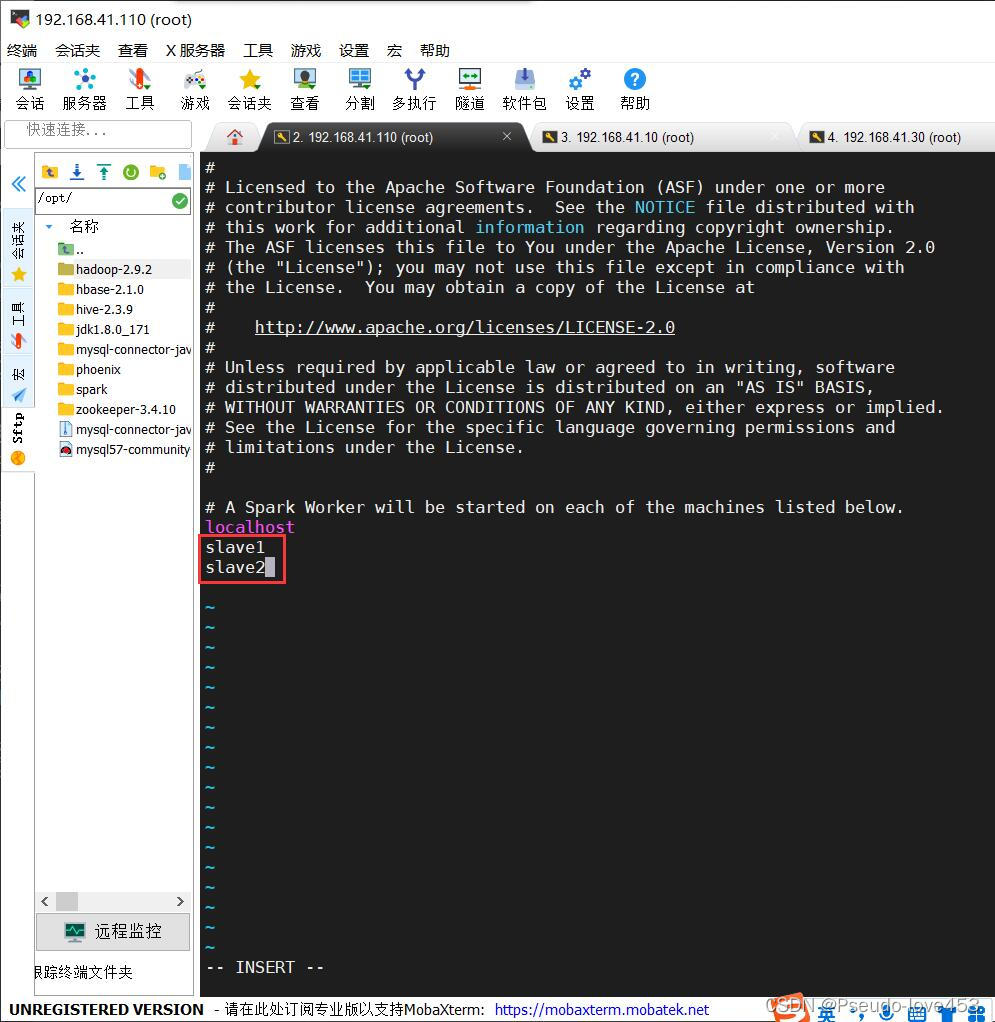
6.修改Spark配置文件(系统没有提供slaves文件,需要从slaves.template文件拷贝一份):
cp slaves.template slaves
vi slaves
#添加以下内容:
slave1
slave2
7.登录master节点,分发配置好的spark文件到slave1和slave2节点上:
scp -r /opt/spark root@slave1:/opt/
scp -r /opt/spark root@slave2:/opt/
三、开始启动Spark
1.登录master节点,开始启动Spark:
cd /opt/spark/sbin
./start-all.sh
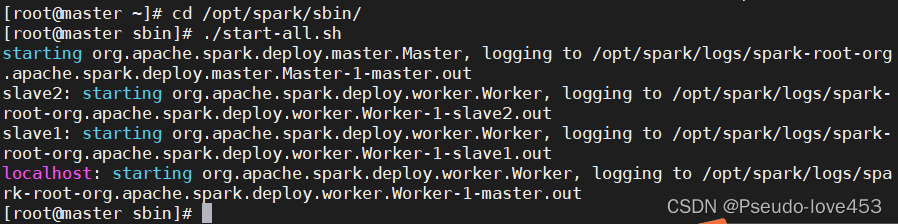
2.通过jps查看是否存在spark的相关进程:

3.在slave1和slave2节点上通过jps命令都能看到worker进程:
slave1:
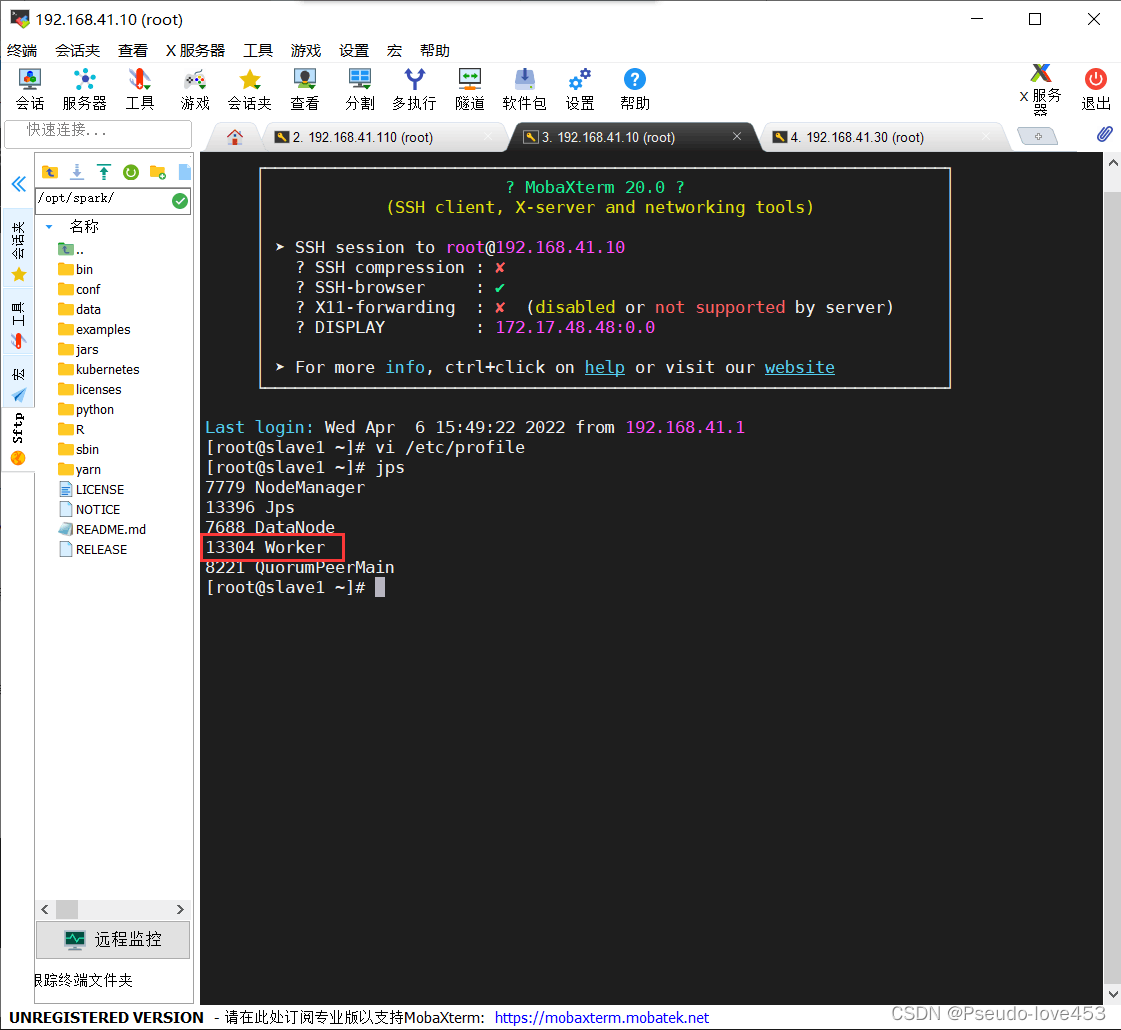
slave2: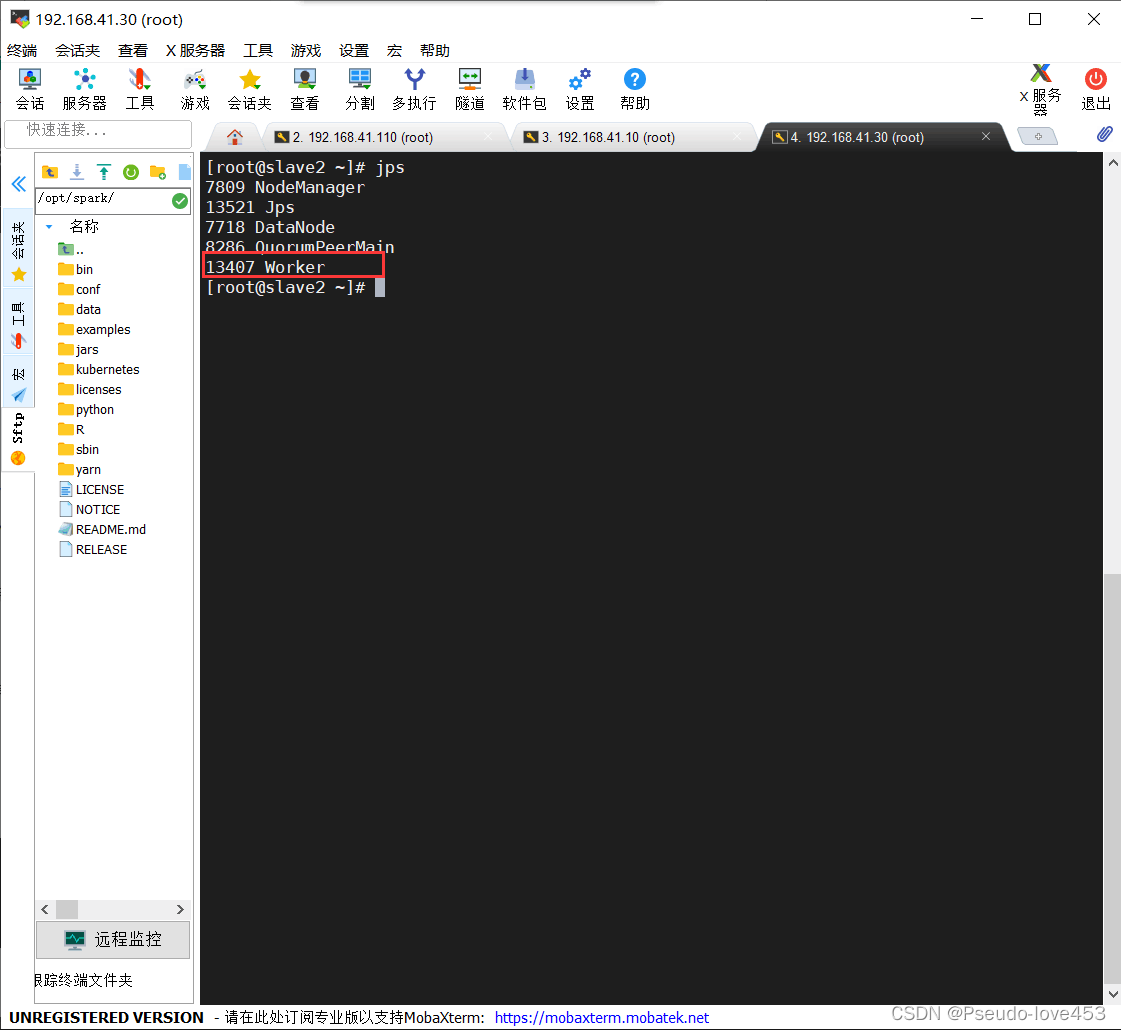
4.打开浏览器,输入: http://192.168.41.110:8080/
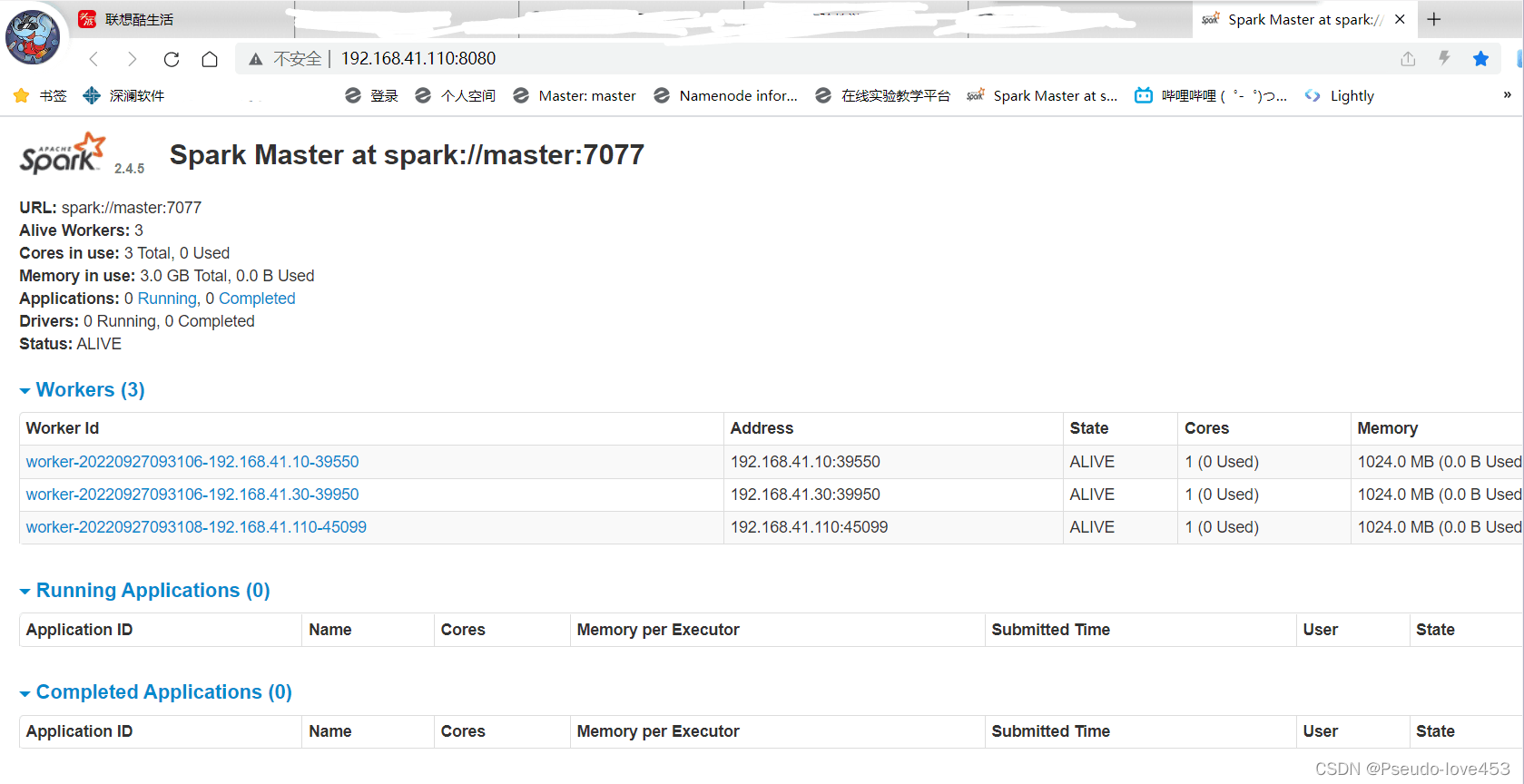
四、测试Spark-shell启动:
cd /opt/spark/bin/
./spark-shell
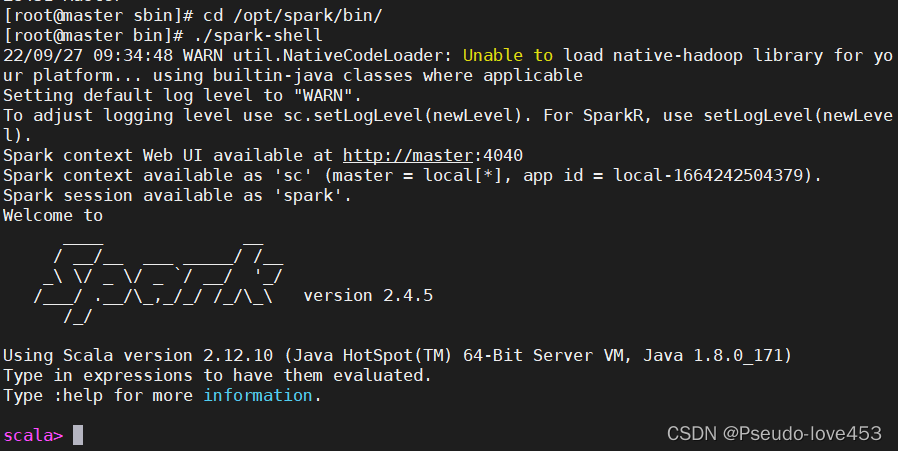
本实验完成!

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









