







检查网页源代码
首先分析网址的数据请求:
进入到新URL:
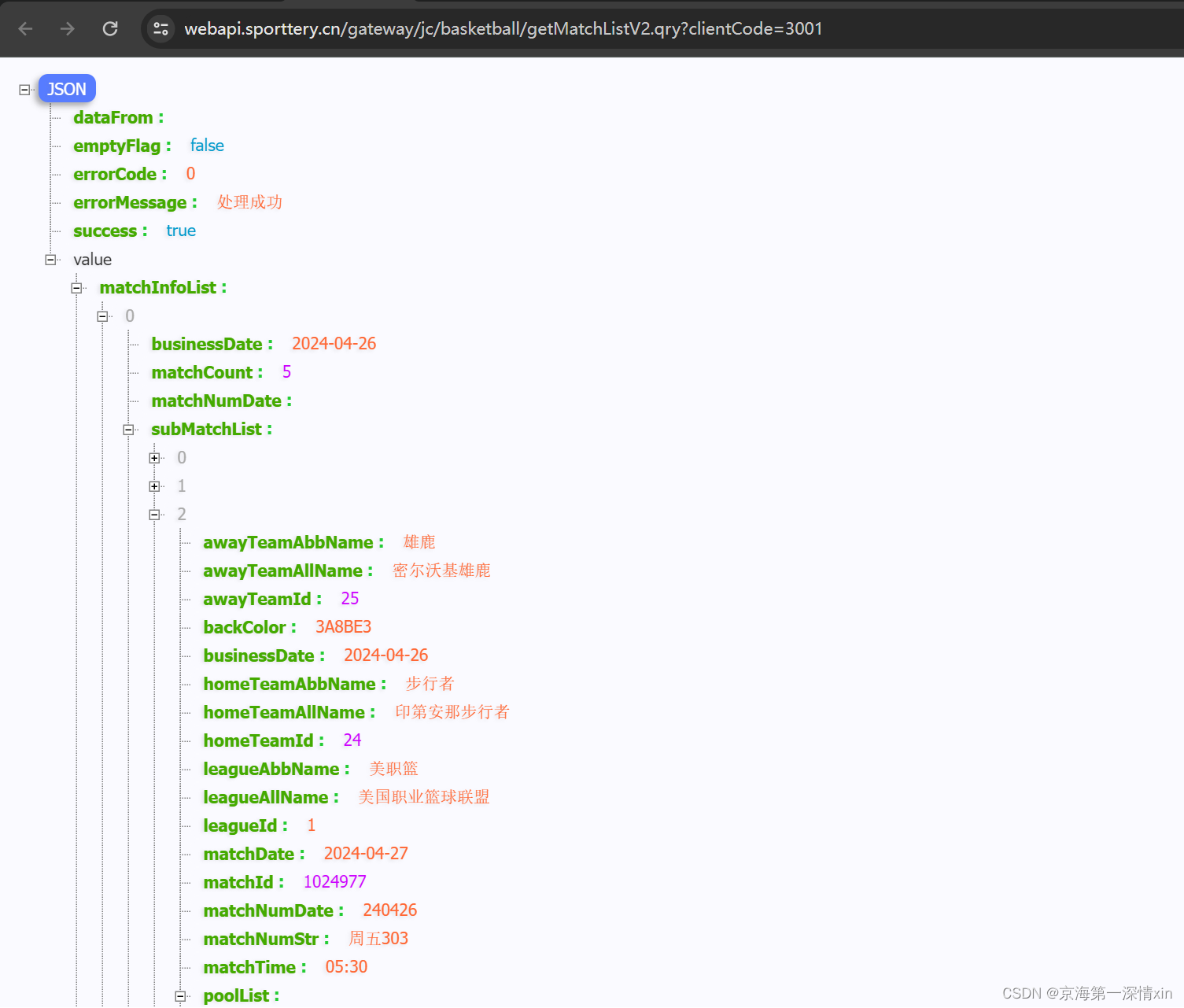
可发现是json数据格式(需要导入json)
import scrapy
import json
from scrapy import Request
from scrapy.http import TextResponseitems的使用
在items.py文件中,添加代码
import scrapy
class BaskStation(scrapy.Item):
no_str = scrapy.Field()
league = scrapy.Field()
datetime = scrapy.Field()
home = scrapy.Field()
away = scrapy.Field()
a_sf = scrapy.Field()
h_sf = scrapy.Field()
battle = scrapy.Field()
a_rate = scrapy.Field()
h_rate = scrapy.Field()
a_ds = scrapy.Field()
h_ds = scrapy.Field()使用json提取元素
name = "bask_station" # 爬虫名称
allowed_domains = ["webapi.sporttery.cn"]
start_urls = ["https://webapi.sporttery.cn/gateway/jc/basketball/getMatchListV1.qry"]
custom_settings = {
"ITEM_PIPELINES": {
"lottery_crawls.pipelines.pipelines_game.BaskStationPipeline": 300,
},
"DOWNLOADER_MIDDLEWARES": {
"lottery_crawls.middlewares.LotteryCrawlsDownloaderMiddleware": 300,
}
}当爬取其他页时,URL地址会改变,如果不在allowed_domains中,就不能爬取,所以要修改allowed_domains中的URL地址
def start_requests(self):
yield Request(
url=f"https://webapi.sporttery.cn/gateway/jc/basketball/getMatchListV1.qry?clientCode=3001&leagueId=1"
)可以根据自己的需要 重写此方法,来实现起始请求的其他功能 或者加入头部信息 或者是其他参数 等等
def parse(self, response: TextResponse, **kwargs):
date_group = json.loads(response.text)["value&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











