







文章目录
一.引入
给出一个场景,要求使用Redis保存 5000 万个键值对,每个键值对大约是 512B,经计算一共需要花费约25G内存。通常我们想到的就是使用内存大小为32G的服务器来做Redis实例,还剩下7G甚至可以用作RDB,当Redis出现故障后,可以用作数据恢复。
如果使用上面这种方案,会发现在实际的运行当中Redis响应会非常慢。
- 传统方案的缺陷
使用INFO命令查看Redis的latest_fork_usec指标值(表示最近一次 fork 的耗时),结果这个指标值特别高,快到秒级别了
原因分析:与Redis的持久化有关。在使用RDB进行持久化时,主线程会fork一个子进程来完成,而fork这个操作是与Redis中数据的大小成正相关的,如果这个数据量非常大,那么这个fork耗时就多,就会以肉眼可见的时间来阻塞主线程,所以就导致Redis响应速度变慢了。
所以在要求对Redis存储大量数据且要保证数据不丢失,就不能采用这种只增加单个主机硬件性能的方法。
二.切片集群
这里就要引入切片集群了。
1.简介
切片集群,也叫分片集群,就是指启动多个 Redis 实例组成一个集群,然后按照一定的规则,把收到的数据划分成多份,每一份用一个实例来保存。回到我们刚刚的场景中,如果把 25GB 的数据平均分成 5 份(当然,也可以不做均分,实际根据每个实例主机的性能进行划分),使用 5 个实例来保存,每个实例只需要保存 5GB 数据。
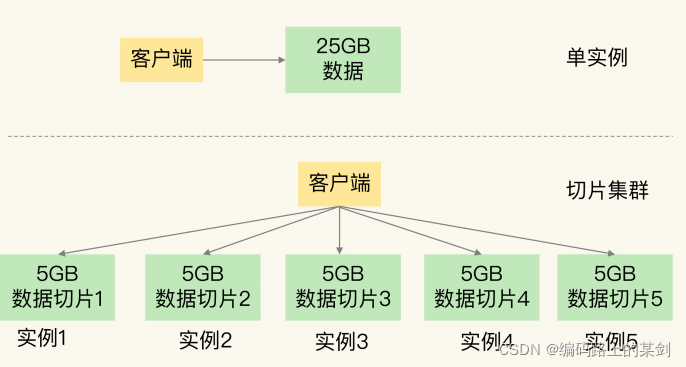
这样当每个实例需要进行RDB时,fork数据的压力就从25G降到了5G,就不容易阻塞子线程了,响应速度会变快。
2.数据存储方案:scale up和scale out`
其实上面讲到了两种数据的存储方式也有两个专有名词:纵向扩展(scale up)和横向扩展(scale out)
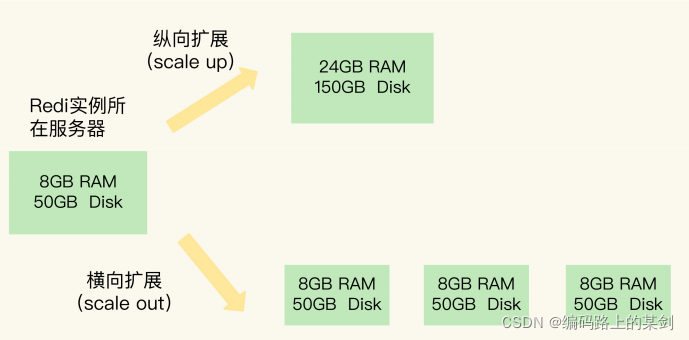
纵向扩展
升级单个 Redis 实例的资源配置,包括增加内存容量、增加磁盘容量、使用更高配置的 CPU。就像下图中,原来的实例内存是 8GB,硬盘是 50GB,纵向扩展后,内存增加到 24GB,磁盘增加到 150GB。
横向扩展
横向增加当前 Redis 实例的个数,就像下图中,原来使用 1 个 8GB 内存、50GB 磁盘的实例,现在使用三个相同配置的实例
3.两种方式优缺点对比:
-
纵向扩展:
优点:实施简单、直接。
缺点:如果要进行RDB持久化,就会因数据量的增多fork阻塞主线程。硬件的扩展成功高:把内存从 32GB 扩展到 64GB 还算容易,但是,要想扩充到 1TB,就会面临硬件容量和成本上的限制了 -
横向扩展:
优点:在面向百万、千万级别的用户规模时,横向扩展的 Redis 切片集群会是一个非常好的选择。
缺点:实现配置有点复杂
4.从横向扩展转换为纵向扩展就需要解决一下问题:
数据切片后,多个redis实例应该如何分布?
客户端怎么确定要访问的数据在哪个实例上?
三.数据切片与实例的对应分布关系
Redis Cluster 是切片集群的具体实现
切片集群是一种保存大量数据的通用机制,这个机制可以有不同的实现方案。在Redis 3.0 之前,官方并没有针对切片集群提供具体的方案。从 3.0 开始,官方提供了一个名为 Redis Cluster 的方案,用于实现切片集群。Redis Cluster 方案中就规定了数据和实例的对应规则。
具体来说,Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
具体映射过程
具体的映射过程分为两大步:首先根据键值对的 key,按照CRC16 算法计算一个 16 bit
的值;然后,再用这个 16bit 值对 16384 取模,得到0~16383范围内的模数,每个模数
代表一个相应编号的哈希槽。关于CRC16算法,不知到的读者可以将它看作hashmap中的hash函数。
那么,这些哈希槽又是如何被映射到具体的 Redis 实例上的呢?
我们在部署 Redis Cluster 方案时,可以使用 cluster create 命令创建集群,此时,Redis
会自动把这些槽平均分在集群实例上。例如,如果集群中有 N 个实例,那么,每个实例
上的槽个数为 16384/N 个。
当然, 我们也可以使用 cluster meet 命令手动建立实例间的连接,形成集群,再使用cluster addslots 命令,指定每个实例上的哈希槽个数。
什么情况下不均分哈希槽位数量
实际上我们应该根据不同实例所在主机的硬件的性能的不同分配合适数量的槽位。举个例子,假设集群中不同 Redis 实例的内存大小配置不一,如果把哈希槽均分在各个实例上,在保存相同数量的键值对时,和内存大的实例相比,内存小的实例就会有更大的容量压力。遇到这种情况时,你可以根据不同实例的资源配置情况,使用 cluster addslots命令手动分配哈希槽
假设有3个实例,5个槽位,下面是数据切片与实例的分布示意图:
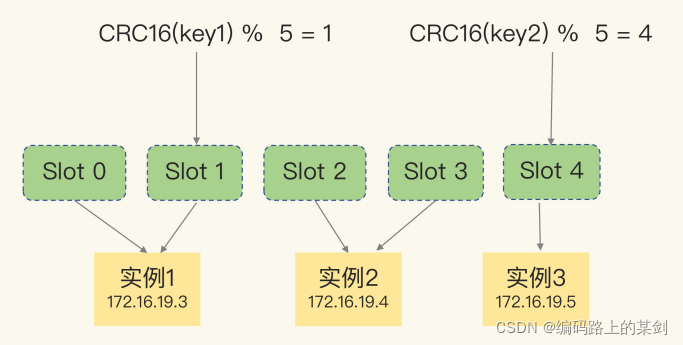
在手动分配哈希槽时,需要把 16384 个槽都分配完,否则Redis 集群无法正常工作。
现在我们知道数据是以怎么的形式保存到不同的实例当中,现在我们需要知道客户端是怎么知道数据在哪一个实例上的,这样我们才能到对应的实例上进行数据的操作。
四.客户端如何定位数据?
首先客户端可以根据键值对与CRC16算法推算出哈希槽,但是客户端开始可不知到这个哈希槽存放在哪个实例上。
实际上,在集群建立之初,每个Redis实例都会将自己分配了哪些槽位的信息发送给与之相连的其他槽位,这样每个实例的槽位信息在切片集群中不断扩散,以至于每个redis实例都有了不同槽位所在实例的映射关系。当客户端与集群建立连接后,实例就会将自己的哈希槽分配关系发送给客户端,客户端将哈希槽的信息保存到本地缓存中。当客户端发起命令时,会先得到哈希槽,在根据本地缓存中的哈希槽映射关系找到对应的实例ip和端口。
但是还会遇到一些问题:
在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;
为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍
以上两种问题会造成哈希槽与实例对应的关系的改变。
因为这种关系的改变是发生在redis实例上的,各个实例之间可以感受到哈希槽与实例关系的改变,但是客户端却感知不到,因为不是每时每刻客户端都与实例发生信息通讯。
如何解决?
五.重定向机制
Redis Cluster 方案提供了一种重定向机制,所谓的“重定向”,就是指,客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令。
当客户端计算得到哈希槽并通过本地缓存得到对应实例的位置后进行访问,如果最终并没有在这个示例中找到对应的哈希槽,实例就会返回给客户端一个MOVED命令响应结果,其中包含了指定哈希槽新的实例地址(为什么该实例能给出最新的地址?因为实例之间是感知到槽位和实例变化的,可以随时更新信息)
GET hello:key
(error) MOVED 13320 172.16.19.5:6379
其中,MOVED 命令表示,客户端请求的键值对所在的哈希槽 13320,实际是在
172.16.19.5 这个实例上。通过返回的MOVED命令,就相当于把哈希槽所在的新实例的
信息告诉给客户端了,客户端接收到信息后,将新的映射信息保存到本地缓存中。这样一来,客户端就可以直接和 172.16.19.5 连接,并发送操作请
求了。
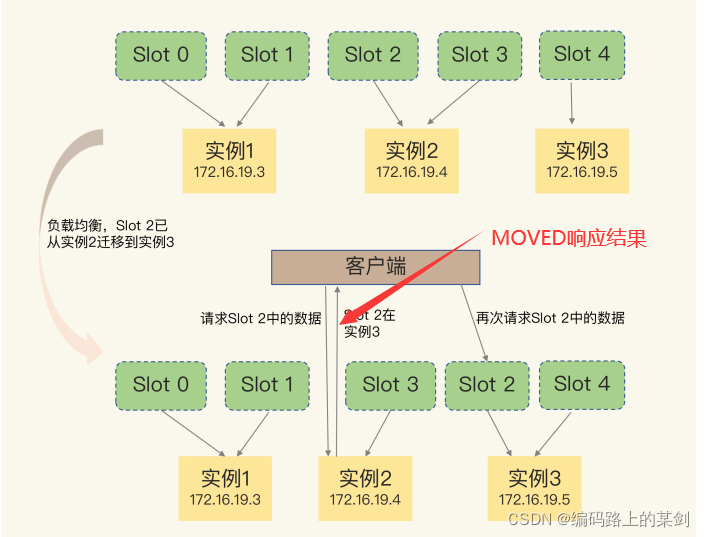
还有一种情况,就是槽位正从一个实例迁移到另一个实例的过程中,客户端发起了数据请求,这是因为槽位数据并没有完全迁移,此时如果没有在该实例找到哈希槽,服务端会返回ASK报错信息,该信息中也包含了槽位迁移后的实例的地址信息,但是客户端不会更新该信息到本地缓存(这是与MOVED结果最大的区别)
2 GET hello:key
(error) ASK 13320 172.16.19.5:6379
之后客户端需要给新实例地址发送发送一个 ASKING 命令。这个命令的意思是,让这个实例允许执行客户端接下来
发送的命令。然后,客户端再向这个实例发送 GET 命令,以读取数据。
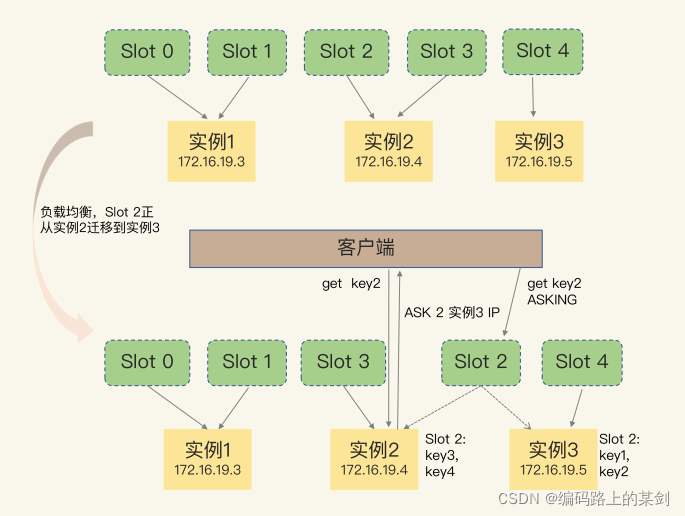
MOVED与ASK不同点
和 MOVED 命令不同,ASK 命令并不会更新客户端缓存的哈希槽分配信息。所以,在上图中,如果客户端再次请求 Slot 2 中的数据,它还是会给实例 2 发送请求。这也就是说,ASK 命令的作用只是让客户端能给新实例发送一次请求,而不像MOVED 命令那样,会更改本地缓存,让后续所有命令都发往新实例。这种ASK命令就保证了在槽位还没有完全迁移的情况下,客户端可以持续的从原实例和新实例中寻找槽位。
六.总结
在应对数据量扩容时,虽然增加内存这种纵向扩展的方法简单直接,但是会造成数据库的
内存过大,导致性能变慢。Redis 切片集群提供了横向扩展的模式,也就是使用多个实
例,并给每个实例配置一定数量的哈希槽,数据可以通过键的哈希值映射到哈希槽,再通
过哈希槽分散保存到不同的实例上。这样做的好处是扩展性好,不管有多少数据,切片集
群都能应对。
另外,集群的实例增减,或者是为了实现负载均衡而进行的数据重新分布,会导致哈希槽
和实例的映射关系发生变化,客户端发送请求时,会收到命令执行报错信息,知道
MOVED 和 ASK 命令就明白为什么有报错信息了。















 8135
8135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









