







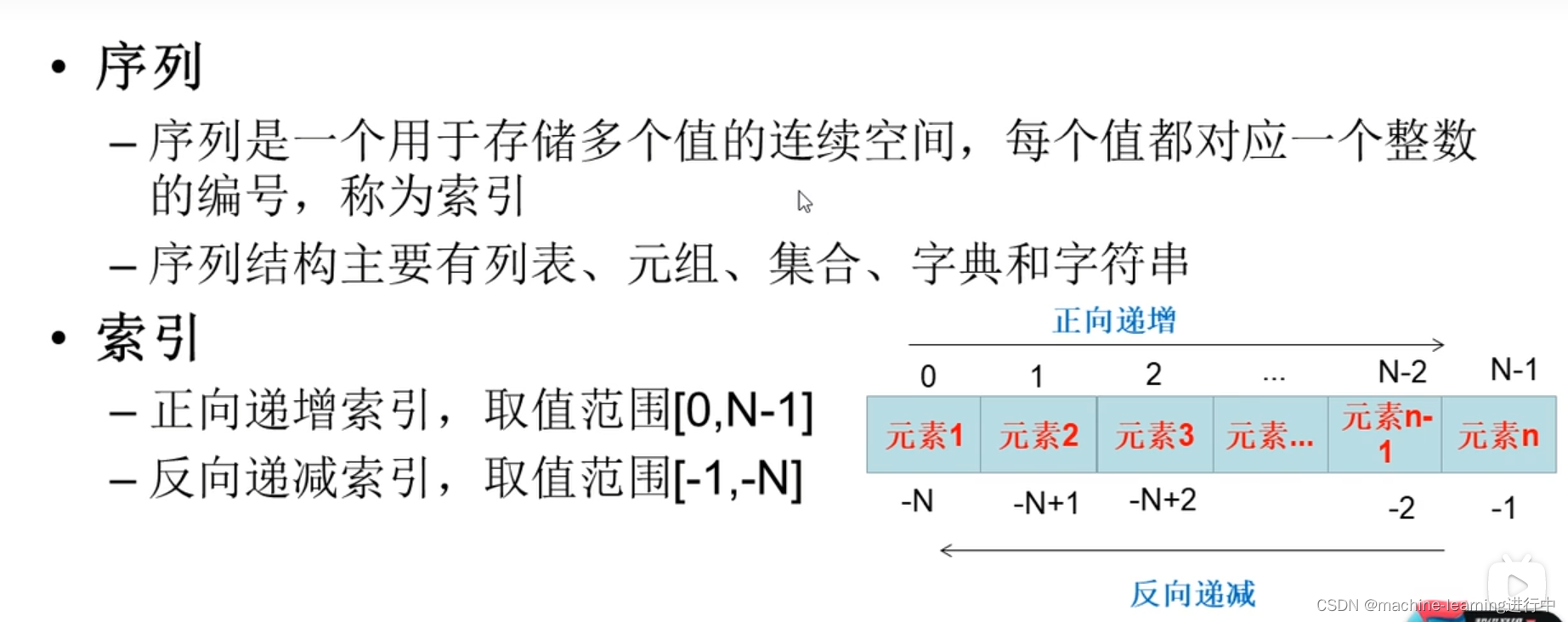
(一)序列
1,序列的索引
len()函数可计算字符串的字符个数
注意正向和反向的索引序号
2,序列的相关操作
(1)切片操作

切片的各个参数:start,end,step
注意各参数的含义和默认值
s="helloworld"
s1=s[0:5:1] #指定起始和结束位置以及步长
print(s1) #输出为hello(2)序列的相关操作_操作符_函数

序列相加:要求序列类型相同(序列的类型有列表、元组、集合、字典和字符串),元素的 类型可以是字符型或整型。理解序列类型和序列中的元素类型

(二)列表
1,列表的创建与删除
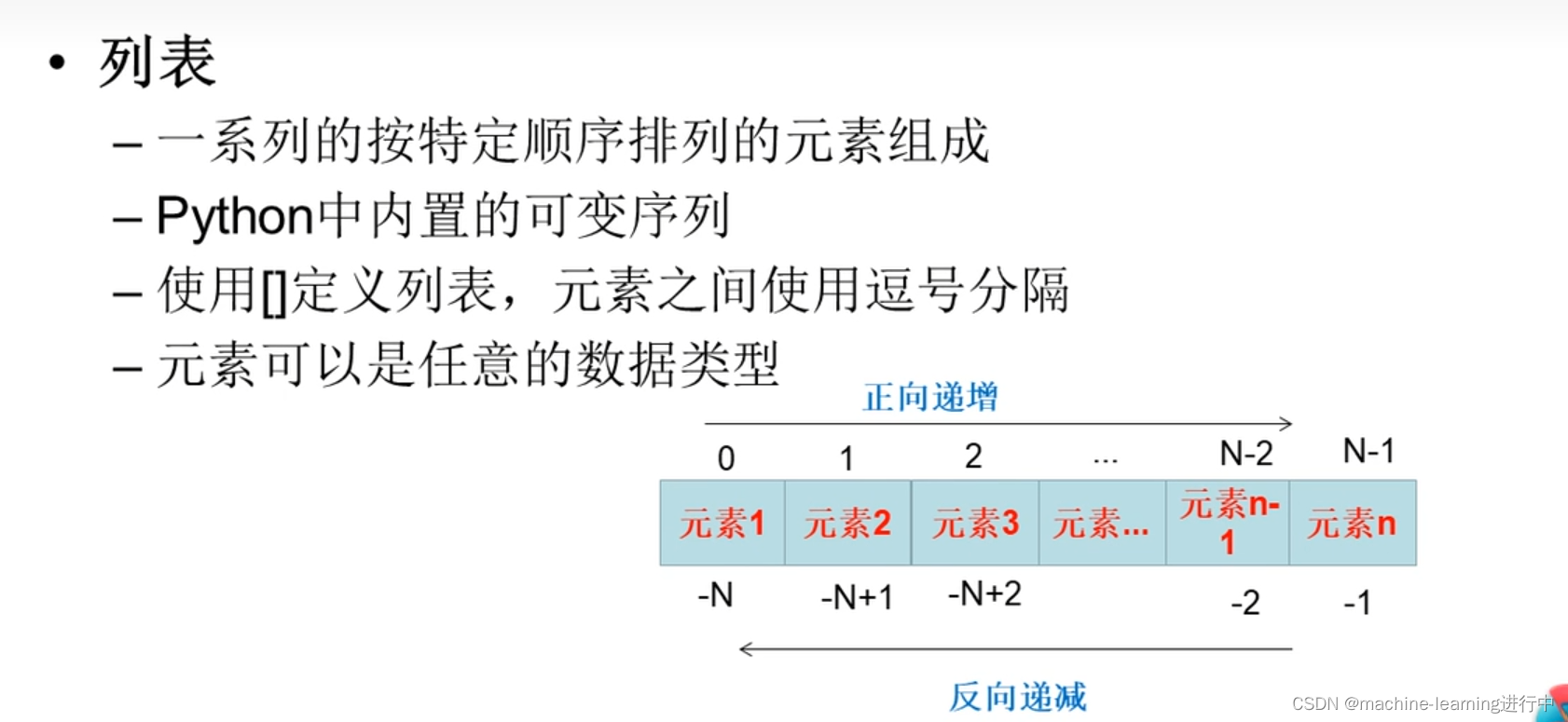

列表是可变长序列,因为其可以增加、删除元素
#列表的创建
#直接使用[]创建
lst=["hello","world",99.8,] #变量名为lst不是list,因为list是内置函数
#使用内置函数list()创建
lst2=list("hello") #结果为["h","e","l","l","0"]
lst3=list(range(1,10,2)) #从1开始,到10结束(不包括10)且步长是2,输出结果为[1,3,5,7,9]
#列表中的操作
print(lst2+lst3) #结果为["h","e","l","l","0",1,3,5,7,9]
print(lst2*3) #结果为["h","e","l","l","0","h","e","l","l","0","h","e","l","l","0"]
print(len(lst2))
print(max(lst3)) #序列的操作同样适用
print(min(lst3))
#列表的删除
del lst #删除列表,则列表不存在
del lst2
del lst3
2,列表元素的遍历

#使用for循环遍历列表元素
lst=["hello","world","python","php"]
for item in lst:
print(item)
#使用for循环,range()函数,len()函数,根据索引进行遍历元素
for i in range(len(lst)):
print(i,"-->",lst[i])
#使用for循环,enumerate()函数进行遍历
for index,item in enumerate(lst): #默认index序号从0开始
print(index,item)
for index,item in enumerate(lst,1): #修改index序号从1开始
print(index,item)
3,列表元素的新增_修改_删除操作
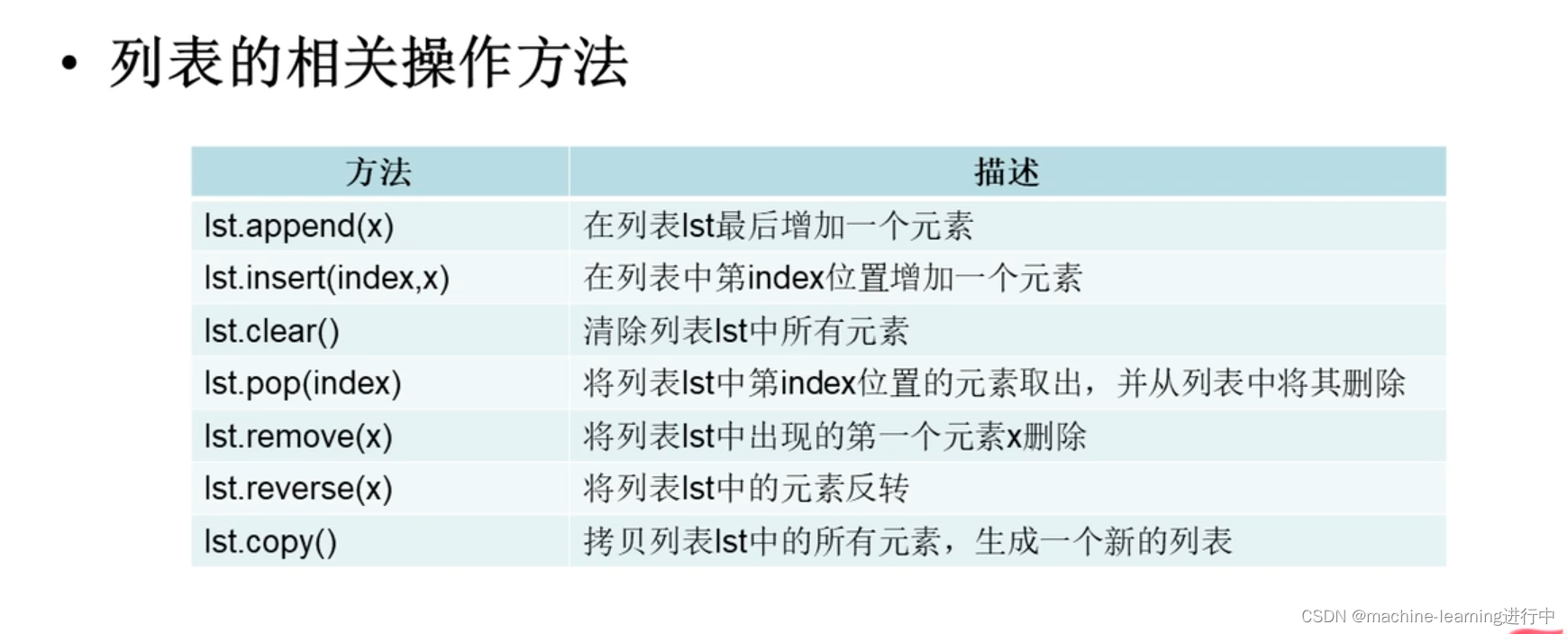
lst=["hello","python","php"]
print("原列表:",lst,id(lst)) #id()函数表示该地址,输出为原列表:["hello","python","php"]
#使用insert(index,x)在指定位置插入元素
lst.insert(1,100) #在位置1处插入元素100(默认位置从0开始)
#删除元素
lst.remove("hello")
#使用pop(index),根据索引移出元素,先将元素取出,再将元素删除
lst.pop(1) #该语句直接在窗口输出100
#清空列表所有元素
lst.clear()
#将列表中元素的位置反转
lst.reverse()
#列表的拷贝,并产生新的列表
new_lst=lst.copy() #两个列表的内存地址不一样
#列表元素的修改
lst[1]="mysql"4,列表的排序

sort方法:reverse=True,则降序排序;False是升序排序,默认是升序排序对
sorted函数:是内置函数
注意sort()是方法,而sorted()是内置函数
对中文的排序效果不是很好,但可以对英文排序,按照首字母的unicode码值进行排(ASCII码是unicode码的一部分)
#用sort()方法进行排序
lst=[5,15,46,3,59,62]
lst.sort() #默认是升序排序
lst.sort(reverse=True) #降序排序
#对英文排序
lst2=["banana","apple","Cat","Orange"]
lst2.sort() #默认升序排序,先排大写再排小写(按照首字母的unicode码排序)
lst2.sort(reverse=True) #降序排序,先排小写在排大写
#忽略大小写进行排序
lst2.sort(key=str.lower) #默认升序排序且部分大小写,用到参数key(是比较排序的键)#用sorted()内置函数进行排序
lst=[5,15,23,86,3,87]
asc_lst=sorted(lst) #默认是升序排序
print(lst)
print(asc_lst) #输出会发现lst未改变,asc_lst排序改变
#sorted()函数的参数和sort()方法相同,可采用一样的形式
5,列表生成式

expression是表达式的意思,即前面的可以是任何表达式
#列表生成式
#生成整数列表
lst=[i for i in range(1,11)]
lst1=[i*i for i in range(1,11)] #前面是表达式
#产生10个随机数列表
import random #要产生随机数要导入random模块
lst3=[random.randint for _ in range(10)] #因为前面没有用到循环变量,所以用下划线代替则该循环表示循环的次数
#从列表中选择符合条件的元素组成新的列表
lst4=[i for i in range(10) if i%==0] #产生0~9之间的偶数列表6,二维列表
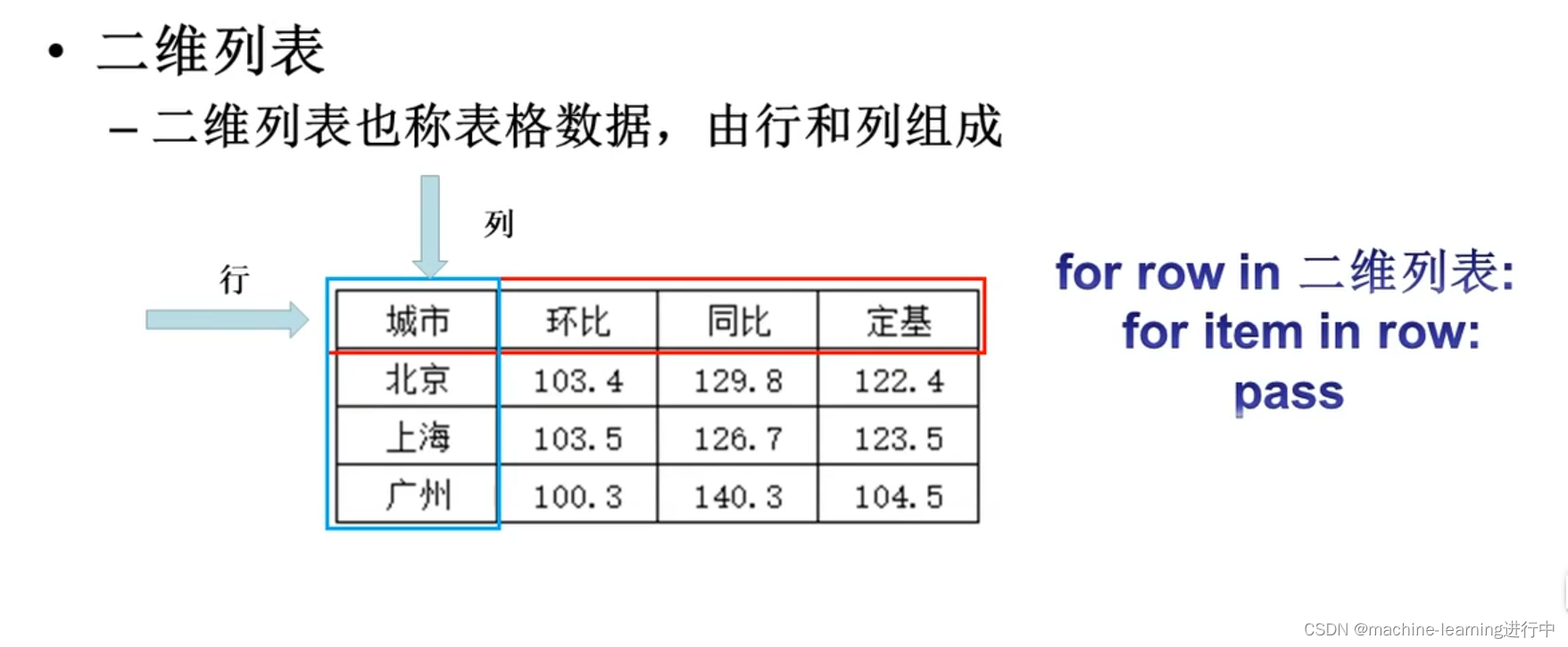
#创建二维列表
lst=[["城市","环比","同比"],
["北京",102,103],
["上海",104,504],
["深圳",103,205]
]
#遍历二位列表
for row in lst
for item in row
print(item,end="\t")
print()
#列表生成式创建四行五列的列表
lst2=[[j for j in range(5)]for i in range(4)]
print(lst2) #输出是[[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4]]
#也可效仿一维列表生成式添加条件筛选(三)元组
1,元组的创建与删除

元组是不可变序列
元组中的数据类型可以是字符串、整型、也可以是列表,元组
#直接使用()创建元组
t=("hello","python",[0,1,2],10)
print(t) #输出是("hello","python",[0,1,2],10),输出中带有()
#使用内置函数tuple()创建元组
t=tuple("hello")
print(t) #输出为("h","e","l","l","o")
t=tuple([1,2,3])
print(t) #输出是(1,2,3)
t=tuple(range(1,5))
print(t) #输出是(1,2,3,4)
#元组的相关操作和序列的操作一样
#若元组中只有一个元素,括号中应带“,”
z=(10)
print(type(z)) #输出<class:int>
m=(10,)
print(type(m)) #输出<class:tuple>
#删除元组
del m
print(m) #报错:nameerror:m is not defined
2,元组的访问与遍历
t=("python","php","hello")
print(t[0]) #输出为python,根据索引访问
t1=t[0:3:1]
print(t1) #输出是("python","php","hello"),切片操作
#元组的遍历
#1,直接使用for循环遍历
t=("python","php","hello")
for item in t:
print(item)
#2,for循环+range()+len()组合遍历
t=("python","php","hello")
for i in range(0,len(t)):
print(t[i])
#3,enumerate()函数遍历
for index,item in enumerate(t):
print(index,item) #使用enumerate()函数时index默认从0开始3,元组生成式

t=(i for i in range(1,4))
print(t) #结果是<generator object <genexpr>>生成器对象
#1,生成器对象可转换成元组类型输出
t=tuple(t)
print(t) #输出(1,2,3)
#2,生成器对象可以直接只用for循环遍历,不用转成元组类型
for item in t:
print(item)
#3,生成器对象方法__next__()方法遍历
print(t.__next__()) #拿到第一个元素
print(t.__next__()) #拿到第二个元素
print(t.__next__()) #拿到第三个元素
t=tuple(t)
print(t) #输出会发现元素为空
#生成器遍历之后,再想重新遍历必须重新创建一个生成器对象,因为遍历之后原生成器对象不存在注意:生成器遍历之后,再想重新遍历必须重新创建一个生成器对象,因为遍历之后原生成器对象不存在
4,元组和列表的区别
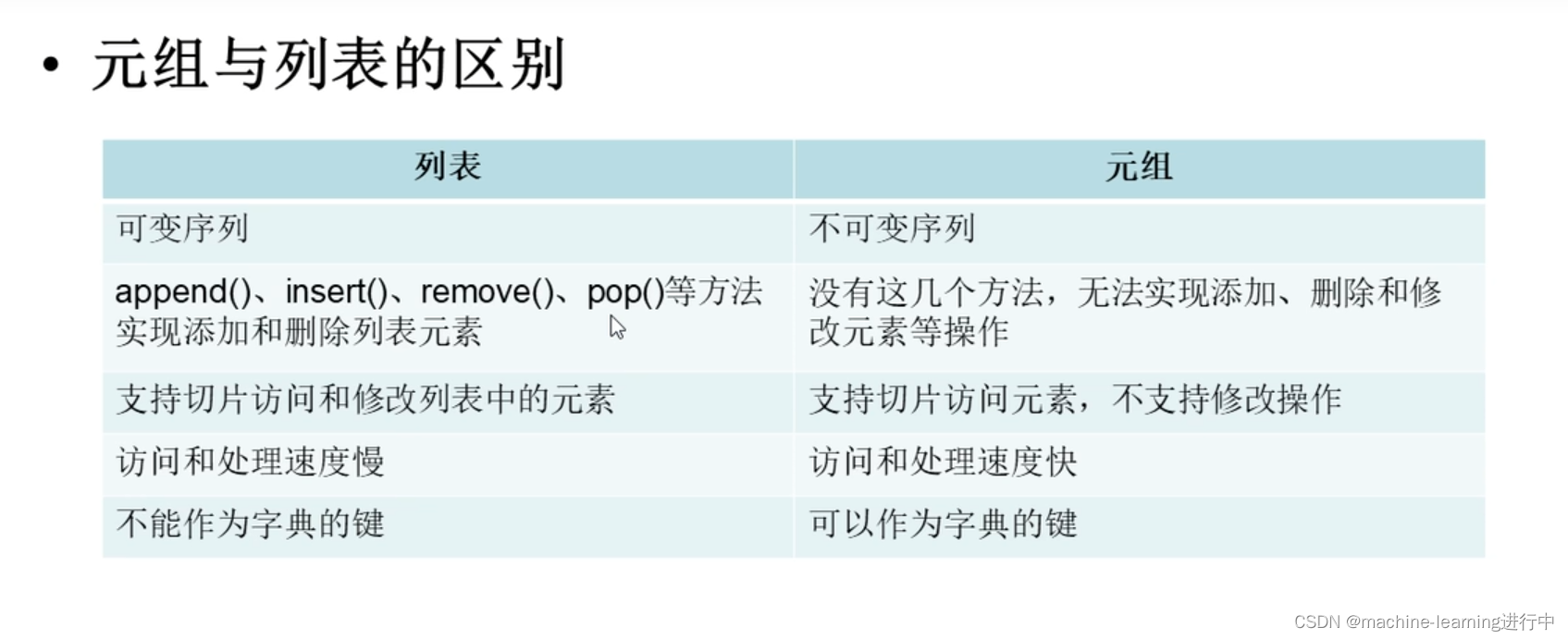
1,列表时可变序列,可进行添加删除操作;元组是不可变序列。
2,列表是可变序列故不能作为字典的键;元组是不可变序列可作为字典的键
3,当只需要访问元素而不修改元素时,用元组
(四)字典
1,字典创建与删除


字典没有索引,只能通过键来访问
字典中的键必须是不可变序列,值可以是任意类型
字典是可变序列,可以添加和删除元素

字典的删除:del 字典名
#1,直接使用{}创建
d={10:"car",20:"dog",30:"pet"}
#2,映射函数zip()函数结合dict()使用
lst1=[10,20,30,40]
lst2=["cat","dog","car","zoo"]
ziph=zip(lst1,lst2) #映射函数的结果是zip对象
#zip()函数将两个列表中对应位置的元素作为元组结合,并产生zip对象
#print(ziph) #输出是<zip object>
#print(list(ziph)) #zip对象需转化成列表或元组才能输出
d=dict(ziph)
print(d) #输出是{10:"cat",20:"dog",30:"car",40:"zoo"}
#3,使用dict()并用参数创建字典
d=dict(cat=10,dog=20,car=30) #括号若写成10=cat则报错因为变量不能是数字
print(d) #输出是{"cat":10,"dog":20,"car":30}
t=(10,20,30)
m={t:10} #键必须是不可变序列
print(m) #输出是{(10,20,30):10}
n=[10,20,30]
m={n:10}
print(m) #报错typeError:unhashable type:"list"
#删除字典
del m #删除后就不存在
del n2,字典的访问和遍历

字典元素遍历:方法items()指的是键值对
d={"hello":10,"world":20,"php":30}
#访问字典元素
#1,使用[key]
print(d["hello"])
#2,使用d.get(key)
print(d.get("hello"))
#[key]和d.get(key)的区别,若键不存在时会出现区别
#print(d["java"]) 直接报错:KeyError键错误
print(d.get("java")) #不会报错,输出None,d.get("java")默认值None
print(d.get("java","不存在")) #输出默认值不存在
#字典的遍历
for item in d.items():
print(item) #输出是元组形式,即("hello",10)形式,因为items是键值对形式
for key,value in d.items():
print(key,value) #输出对应的值3,字典的相关操作

d={1001:"李梅",1002:"王华",1003:"张锋"}
#向字典中添加数据
d[1004]="张丽" #直接使用d[key]=value赋值运算,添加数据
#获取字典中所有的key
key=d.keys() #d.keys()结果是dict_keys,python中的一种内部数据类型,专用于表示字典的key
#若希望更好的显示数据,可用list()或tuple()转为列表或元组
print(list(key))
print(tuple(key))
#获取字典中所有的value
value=d.values() #d.values()结果是dict_values
print(list(value))
print(tuple(value))
#使用pop()方法
print(d.pop(1008,"不存在")) #若键不存在,输出默认值“不存在”
#清除字典
d.clear()
print(bool(d)) #输出False4,字典生成式

#使用指定范围的数做键key
import random
d={item:random.randint(1,100) for item in range(4)}
print(d) #输出{0:39,1:25,2:45,3:56}
#使用映射函数zip()作为生成表达式
lst1=[1001,1002,1003]
lst2=["刘伟","张强","李华"]
d={key:value for key,value in zip(lst1,lst2)}
print(d)
(五)集合
1,集合的创建与删除


集合中的元素不能重复,若重复则自动降重,可实现字符串的降重
本博客只叙述可变集合set
#第一种创建集合方法
s={10,20,30,40]
print(s) #输出为{40,10,20,30},因为集合是无序的
s={[10,20],[30,40]}
print(s) #报错TypeError,因为列表是可变的
s={} #创建的是空字典
s=set() #创建的是空集合
#第二种创建集合,set(可迭代对象),可迭代对象就是能用for循环遍历的类型
s1=set("hello")
s2=set([10,20,30])
s3=set(range(1,10))
print(s1) #输出{"h","l","o","e"},集合中的元素不能重复,可实现字符串的去重
print(s2)
print(s3)
del s1 #删除s32,集合的操作符
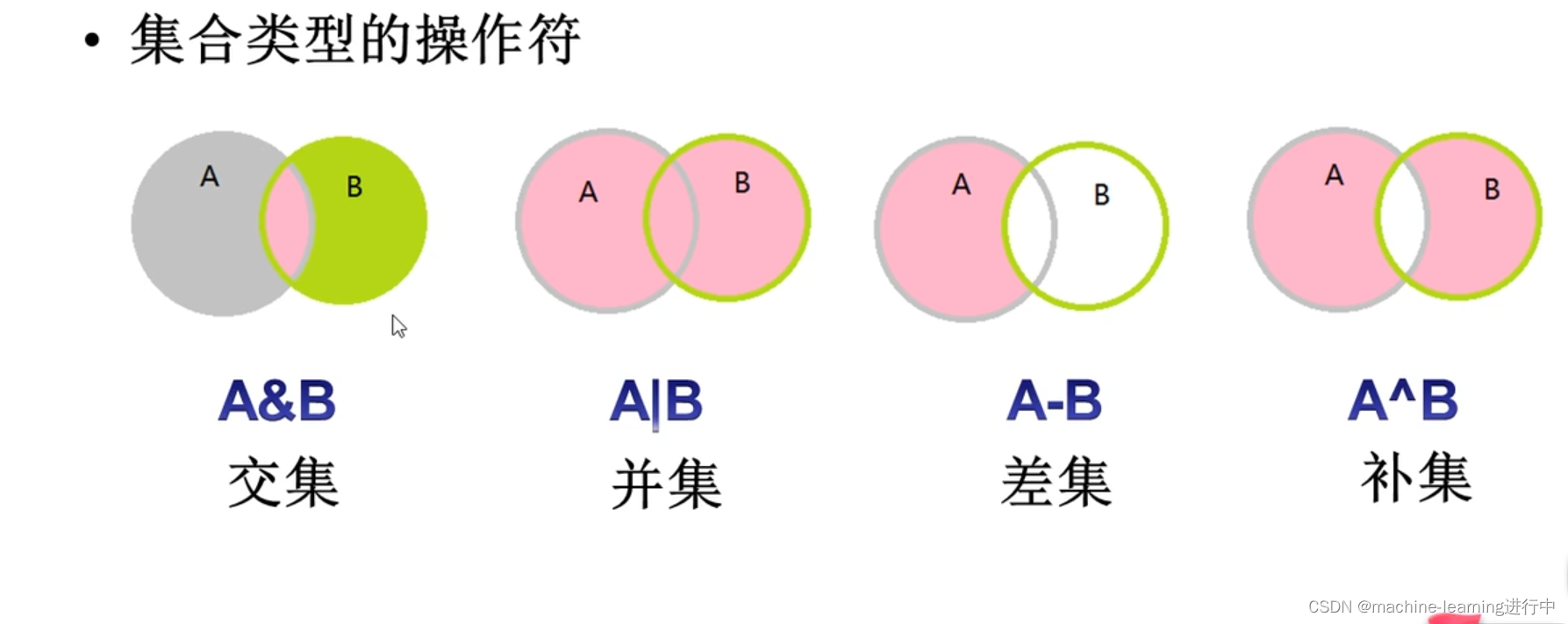
a={10,20,30,60}
b={20,30,40,80}
print(a&b) #输出是{20,30},仍为集合
print(a|b) #输出仍是集合
print(a-b)
print(a^b) #补集,即去掉a和b中重复的元素后剩下的所有元素3,集合的相关操作,遍历和生成式

s={10,20,30}
#添加元素
s.add(100) #结果是{100,10,20,30}
#删除元素
s.remove(20)
#清除集合中所有元素
s.clear()
#遍历集合元素
for i in s:
print(i)
#使用ennumerate()函数遍历
for index,value in ennumerate(s,1): #index是序号,不是索引
print(index,value)
#集合生成式
s={i for i in range(1,10)}
m={i for i in range(1,10) if i%2==0}
(六)组合数据类型的总结

实战小任务
#千年虫
lst=[88,89,90,98,00,99] #表示员工的两位整数的出生年份
#遍历列表
for index in range(len(lst)):
if str(lst[index])!="0":
lst[index]="19"+str( lst[index])#拼接之后再赋值
else:
lst[index]="200"+str( lst[index])
#使用enumerate()函数遍历列表
for index,value in enumerate(lst):
if value!=0:
lst[index]="19"+str(value)
else:
lst[index]="200"+str(value)#模拟京东购物流程
#创建列表,用来存放入库的商品信息
lst=[]
for i in range(1,6):
goods=input("输入商品编号和商品名称,每次输入一件")
lst.append(goods)
#输出所有的商品信息
for item in lst:
print(item)
#创建空列表,用来存放购物车的商品
cart=[]
while True:
flag=False
num=input("请输入要购买的商品编号")
#遍历商品列表,查询购买的商品是否存在
for item in lst:
if num==item[0:4]
cart.append(item)
print("商品已添加到购物车")
break
if flag==False and num!="q":
print("该商品不存在")
if num="q":
break
print("购物车已选择的商品为")
#反向
cart.reverse()
for item in cart:
print(item)
#模拟12306购票流程,字典的应用
#创建字典,用来存储车票信息,车次做key,使用其他信息做value
dict_ticket={"G1569":["北京南-天津北","18:06","18:39"],"G1567":["北京南-天津南","18:15","18:50"],"G1845":["北京南-天津西","18:13","18:36"],"G1902":["北京南-天津东","18:23","18:56"]}
#遍历字典元素
for key in dict_ticket.keys():
print(key,end="")
#遍历车次详细信息
for item in dict_ticket.get(key):#根据key获取值,dict_ticket[key]
print(item,end="")
print()
#输入用户的购票车次
train_no=input("输入用户购买的车次")
#根据键获取值
info=dict_ticket.get(train_no,"车次不存在")#get()方法若没有对应的key,则输出默认参数"车次不存在"
if info!="车次不存在":
person=input("输入乘车人")
#获取车次详细信息
s=info[0]+" "+"开"+info[1]
print("已购买"+train_no + person + s + "换取车票【铁路12306】")
else:
print("车次不存在")
#模拟手机通讯录,集合的应用
#创建空集合
phones=set()
for i in range(5):
info=input("请输入第"+str(i)+"位人间好友")
#添加到集合中
phones.add(info)
for item in phones:
print(item)













 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









