







数据的表示和运算
考纲内容
- 数制与编码
进位计数制及其相互转换;定点数的编码表示 - 运算方法和运算电路
基本运算部件:加法器;算数逻辑单元(ALU)
加/减运算:补码加/减运算器;标志位的生成
乘/除运算:乘/除运算的基本原理;惩罚电路和出发电路的基本结构 - 整数的表示和运算
无符号整数的表示和运算;有符号整数的表示和运算 - 浮点数的表示和运算
浮点数的表示:IEEE754标准;浮点数的加/减运算
unsigned、short、int、long、float、double等在C语言中的表示、运算、溢出判断、隐式类型转换、强制类型转换、IEEE754浮点数的表示,以及浮点数的运算,都是考查重点
思考以下问题:
1、在计算机中,为什么要采用二进制来表示数据?
2、计算机在字长足够的情况下能够精准的表示每个数吗?
3、字长相同的情况下,浮点数和定点数的表示范围与精度有什么区别
4、用移码表示浮点数的阶码有什么好处
数制与编码
进位计数制及其相互转换
在计算机系统内部,所有信息都是用二进制进行编码的,这样做的原因:
- 二进制**
只有两种状态**,使用有两个稳定状态的物理器件就可以表示二进制数的每一位,制造成本比较低 - 二进制位**
1和0正好与逻辑值真和假**相对应,为计算机实现逻辑运算和程序中的逻辑判断提供了便利条件 - 二进制的编码和运算规则都很简单,通过逻辑门电路能方便地实现算数运算
进位计数法
常用的进位计数法有十进制、二进制、八进制、十六进制等
- 二进制。基数为2,0 / 1
- 八进制。基数为8,0 ~ 7
- 十六进制。技术为16,0 ~ 9,A ~ F
用B表示二进制,用O表示八进制,用D表示十进制(通常直接省略),用H表示十六进制,有时也用前缀0x表示十六进制数
不同进制数之间的相互转换
1、二进制数转换八进制数和十六进制数
对于一个二进制混合数(既包含整数部分,又包含小数部分),在转换时应以小数点为界
其整数部分,从小数点开始往左,将一串二进制数分为3位(八进制)一组或4位(十六进制)一组,在最左边加“0”补⻬
对于小数部分,从小数点开始往右,将一串二进制数分为3位一组或4位一组,在数的最右边加“0”补⻬
最终使总的位数为3或4的整数倍,然后分别用对应的八进制数或十六进制数取代
八进制数或十六进制数转换为二进制数,只需将每位改为3位或4位二进制数即可
十六进制数转换为八进制数(或八进制数转换为十六进制数)时,先将十六进制(八进制)数转换为二进制数,然后由二进制数转换为八进制(十六进制)数较方便
2、任意进制数转换十进制数
按权展开相加法:将任意进制数的各位数码与它们的权值相乘,再把乘积相加,就得到了一个十进制数
3、十进制数转换任意进制数
基数乘除法:对十进制数的整数部分和小数部分将分别进行处理。对整数部分采用**除基取余法,对小数部分采用乘基取整法**,最后将整数部分与小数部分的转换结果拼接起来
除基取余法(整数部分):整数部分除基取余,最先取得的余数为数的最低位,最后取得的余数为数的最高位(即除基取余,先余为低,后余为高),商为0时结束
乘基取整法(小数部分):小数部分乘基取整,最先取得的整数为数的最高位,最后取得的整数为数的最低位(即乘基取整,先整为高,后整为低),乘积为1.0(或满足精度要求)时结束
注:在计算机中,小数和整数不一样,整数可以连续表示,但小数是离散的,所以并不是每个十进制小数都可以准确地用二进制表示,即**任意二进制小数都可以用十进制小数表示,但任意十进制小数不一定能用二进制小数表示**
定点数的编码表示
真值和机器数
真值是机器数所代表的实际值
在计算机中,通常将数的符号和数值部分一起编码,将数据的符号数字化,通常用**0表示正,用1表示负**
这种把符号“数字化”的数称为机器数。常用的有原码、补码和反码表示法
机器数的定点表示
根据**小数点的位置是否固定,在计算机中有两种数据格式:定点表示和浮点表示**
现代计算机中,通常用**补码整数表示整数,用原码小数表示浮点数的尾数部分,用移码表示浮点数的阶码部分**
定点表示法用来表示**定点小数和定点整数**:
- 定点小数。定点小数是纯小数,约定**
小数点位置在符号位之后、有效数值部分最高位之前**
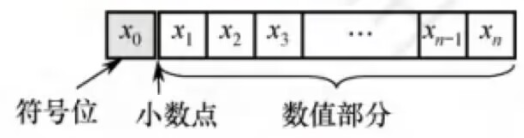
- 定点整数。定点整数是纯整数,约定**
小数点位置在有效数值部分最低位之后**
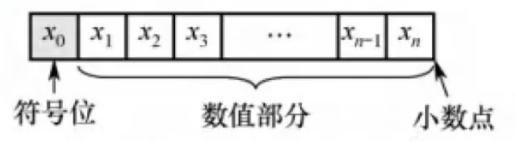
事实上,在机器内部并没有小数点,只是人为约定了小数点的位置。因此,在定点数的编码和运算中不用考虑对应的定点数是小数还是整数,而只需关心它们的符号位和数值位即可
定点数的编码表示法主要有以下4种:原码、补码、反码和移码
原码、补码、反码、移码
1、原码表示法
用机器数的**最高位表示数的符号,其余各位表示数的绝对值**
若字长为**n+1,则原码整数的表示范围为:-(2n - 1) ≤ x ≤ 2n - 1**(关于原点对称)
注:零的原码表示有正零和负零两种形式,即[+0] = 0000 0000和[-0] = 1000 0000
原码表示的优点:
- 与真值的对应关系简单、直观,与真值的转换简单
- 用原码实现乘除运算比较简便
缺点:
- 1、0的表示不唯一,有+0、-0两个编码
- 原码加減运算比较复杂
2、补码表示法
补码表示法中的加减运算统一采用加法操作实现
正数的补码和原码相同
负数的补码等于原码除符号位各位取反,末尾加1
若字长为**n+1,则原码整数的表示范围为:-(2n) ≤ x ≤ 2n - 1**(关于原点对称)
几个特殊数据的补码表示:
[+0] = [-0] = 000...0 (符号位为0,后面有效数据位为n个0)
[-1] = 2^(n+1) = 111...1 (符号位为1,后面有效数据位为n个1)
[2^n - 1] = 011...1 (符号位为0,后面有效数据位为n个1)表示n+1位补码能表示的最大整数
[-2^n] = 100...0 (符号位为1,后面有效数据位为n个0)表示n+1位补码能表示的最小整数
补码与真值之间的转换:
- 真值转换为补码
对于**正数,与原码的方式一样
对于负数**,符号位取1,其余各位由真值各位取反,末位加1得到 - 补码转换为真值
若符号位为0,与原码的方式一样
若符号位为1,真值的符号为负,数值部分各位由补码各位取反,末位加1得到;或符号位取1,末尾减1后各位取反得到
变形补码:一种采用双符号位的补码表示,也称模4补码,若变形补码的位数为n+1,则符号位占2位,数值位占n-1位
模4补码双符号位**00表示正,11表示负,用在执行算术运算的ALU中**
3、反码表示法
正数反码和相应的补码(或原码)表示相同
负数补码保留符号位为1,其余各位取反,没有末尾加1操作
反码表示存在以下几个方面的不足:
- 1、0的表示不唯一(即存在+0、-0)
表示范围比补码少一个最小负数
反码在计算机中很少使用,通常用作数码变换的中间表示形式
4、移码表示法
移码常用来**表示浮点数的阶码,它只能表示整数**
移码就是在真值上加上一个常数(偏置值),通常这个常数取 2n
特点:
- 移码中**
零的表示唯一,[+0] = 2n + 0 = [-0] = 2n - 0 = 100…0** - 一个**
真值的移码和补码仅差一个符号位,[x]补** 的符号位取反即得 [x]移 (1表示正,0表示负,这与其他机器数的符号位取值正好相反),反之亦然 - 移码**
全0时,对应真值的最小值 -2n ;移码全1**时,对应真值的最大值 2n - 1 - 移码**
保持了数据原有的大小顺序**,移码大真值就大,移码小真值就小
原码、补码、反码和移码这4种编码表示的总结如下:
- 原码、补码、反码的符号位相同,移码符号位相反。正数的机器码相同
- **
原码、反码的表示在数轴上对称,二者都存在 +0 和 -0**两个0 补码、移码的表示在数轴上不对称,零的表示唯一,它们比原码、反码多表示一个数- 整数的补码、移码的符号位相反,数值位相同
- 负数的补码、反码末位相差1
- 原码很容易判断大小。而**
负数的补码、反码很难直接判断大小,可采用如下规则快速判断:对于负数,数值位部分越小,其绝对值越大,即负得越多**
整数的表示
无符号整数的表示
无符号整数,简称无符号数,编码的全部二进制位均为数值位而**没有符号位,默认数的符号为正**
无符号整数省略了一位符号位,在字⻓相同的情况下,它能表示的最大数比有符号整数能表示的大
可用无符号整数进行地址运算,或用它来表示指针
对于8位无符号整数,最小数为0000 0000(值为0),最大数1111 1111(值28 - 1 = 255),表示范围为0 ~ 255
对于8位有符号整数,最小数为1000 0000(值-27 = -128),最大数为0111 1111(值为2n - 1 = 127),表示范围为-128 ~ 127
有符号整数的表示
将符号数值化,并将符号位放在有效数字的前面,就组成了有符号整数
计算机中的有符号整数都用补码表示,故n位有符号整数的表示范围是 -2n-1 ~ 2n-1 - 1
C语言中的整型数据类型
C语言中的整型数据类型
C语言中的整型数据就是**定点整数,根据位数的不同,可分为字符型(char,8位)、短整型(short或short int,16位)、整型(int,32位)、⻓整型(long或long int,在32位机器中为32位,在64位机器中为64位)**
其中**char类型默认是无符号整数**
无符号整数(unsigned short/int/long)的全部二进制位均为数值位,没有符号位,相当于数的绝对值
signed/unsigned整型数据都是按补码形式存储的,只是signed型的最高位代表符号位,而在unsigned型中表示数值位
有符号数和无符号数的转换
不同数据类型之间的类型转换为强制类型转换,强制类型转换的结果是保持位值不变,仅改变了解释这些位的方式
如下所示,x为有符号数,y为无符号数,在计算机中的补码x与y是相同的,只是解释成了不同的数值
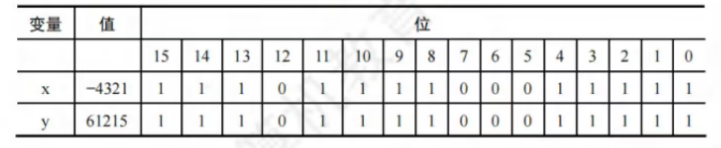
有符号数转换为等长的无符号数时,符号位解释为数值的一部分,负数转换为无符号数时数值将发生变化
无符号数转换为有符号数时最高位解释为符号位,也可能发生数值变化
注:若同时有无符号数和有符号数参与运算,则C语言标准规定按无符号数进行运算
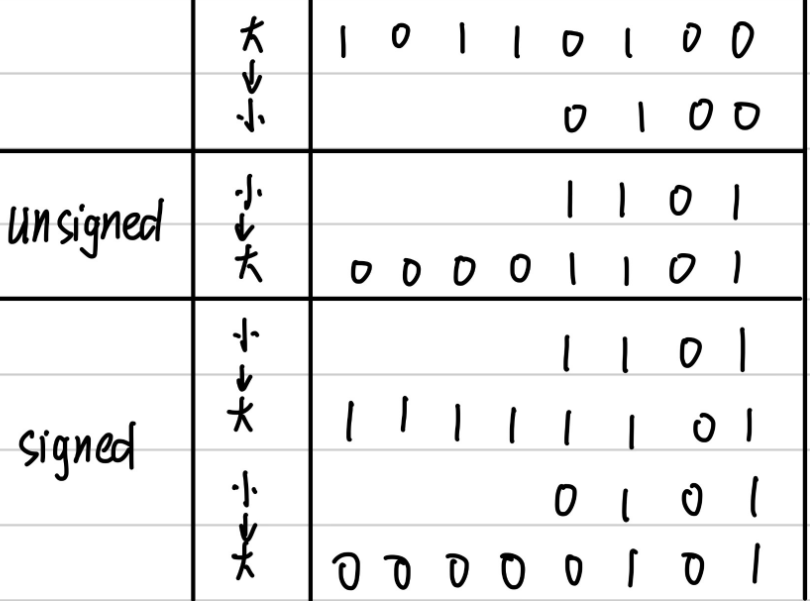
不同字长整数之间的转换
大字长变量向小字长变量转换时,系统会把多余的高位部分直接截断,低位部分直接赋值
小字长变量向大字长变量转换时,不仅要使相应的位值相等,还要对高位部分进行扩展
若**原数字是无符号整数,则进行零扩展,扩展后高位部分用0填充**
若**原数字是有符号整数,则进行符号扩展,扩展后的高位部分用原数字符号位填充**
运算方法和运算电路
说明:
在运算器中都有一些标志信息位,对于有符号或无符号数的运算起到相当重要的作用
- 零标志ZF:
ZF = 1表示结果F为0,对于无符号数和有符号数的运算,ZF都有意义 - 溢出标志OF:
判断有符号数运算是否溢出,它是**符号位进位与最高数位进位的异或结果,即OF = Cn xor Cn - 1**。对于无符号数运算,OF没有意义
如,无符号数加法010 + 011 = 101,C2 = 1、C3 = 0,此时OF = 1,但结果未溢出 - 符号标志SF:
表示结果的符号,即**结果F的最高位。对于无符号数运算,SF没有意义** - 进/借位标志CF:
表示无符号数运算时的进位/借位,判断是否发生滥出
加法时,CF = 1表示**结果溢出,因此CF等于进位输出Cout
减法时,CF = 1表示有借位**,即不够减,故CF等于进位输出Cout取反
综合可得:CF = Sub xor Cout
如,无符号数加法110 + 011最高位产生进位,无符号数减法000 - 111最高位产生借位,结果均发生溢出(即CF=1)
对于有符号数运算,CF没有意义
基本运算部件
在计算机中,运算器由**算数逻辑单元(ALU)、移位器、状态寄存器(PSW)和通用寄存器组**等组成
运算器的基本功能包括加、减、乘、除四则运算,与、或、非、异或等逻辑运算,以及位移、求补等操作
ALU的核心部件是加法器
带标志加法器
无符号数加法器**只能用于两个无符号数相加,不能进行有符号整数的加/减运算**
在无符号数加法器的基础上增加相应的逻辑⻔电路,使得加法器不仅能计算和/差,还要能**生成相应的标志信息**
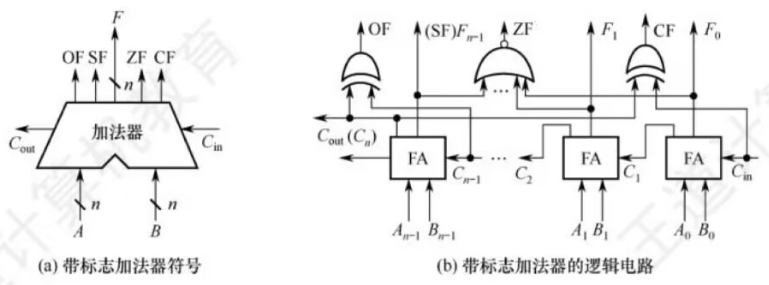
算术逻辑单元(ALU)
ALU是一种功能较强的组合逻辑电路,它能进行多种算术运算和逻辑运算,同时,也可以实现左移或右移的移位操作
由于加、减、乘、除运算最终都能归结力加法运算,因此**ALU的核心是带标志加法器**,同时也能执行与、或、非等逻辑运算

ALU的基本结构如上所示
- A和B是两个n位操作数输入端
- Cin是进位输入端
- ALUop是操作控制端(发出控制信号),用来**
决定ALU所执行的处理功能**
ALUop的位数决定了操作的种类。如,当位数为3时,ALU最多只有8种操作
定点数的移位运算
可以通过加法和移位相结合的方法来实现乘/除法运算。对于任意二进制整数:
左移一位,若不产生溢出,相当于乘以2(与十进制数的左移一位相当于乘以10类似)
右移一位,若不考虑因移出而舍去的末位尾数,相当于除以2
根据操作数的类型不同,移位运算可以分为**逻辑移位和算术移位**
逻辑移位
逻辑移位**将操作数视为无符号整数**
逻辑移位的规则:左移时,高位移出,低位补0;右移时,低位移出,高位补0
对于无符号整数的**逻辑左移,若高位的1移出,则发生溢出**
算术移位
算术移位需要考虑符号位的问题,即**将操作数视为有符号整数**
计算机中的有符号整数都是用补码表示的,因此对于有符号整数的移位操作应**采用补码算术移位方式**
算术移位的规则:
左移时,高位移出,低位补0,若移出的高位不同于移位后的符号位,即**左移前后的符号位不同,则发生溢出**
右移时,低位移出,高位补符号位,若**低位的1移出,则影响精度**
即,11或00开头不会溢出;0结尾,不会丢失精度
定点数的加减运算
补码的加减法运算
补码运算的特点如下:
- 按二进制运算规则运算,逢二进一
- 若做**
加法,两个数的补码直接相加;若做减法,将被减数与减数的负数补码相加** 符号位与数值位一起参与运算,加、减运算结果的符号位也在运算中直接得出- 最终运算结果的高位丢弃,保留n + 1位,
运算结果亦为补码
溢出判别方法
仅当两个符号相同的数相加或两个符号相异的数相减才可能产生溢出
如两个正数相加,而结果的符号位却为1(结果为负);一个负数减去一个正数,结果的符号位却为0(结果为正)
补码定点数加减运算溢出判断的方法有3种:
- 采用一位符号位
由于减法运算在机器中是用加法器实现的,因此无论是加法还是减法,只要参加操作的两个数的符号相同,结果又与原操作数的符号不同,则表示结果溢出 - 采用双符号位
双符号位法也称**模4补码。运算结果的两个符号位相同,表示未溢出;运算结果的两个符号位不同,表示溢出,此时最高位符号位代表真正的符号**
两位符号位的各种情况如下:
1、00:表示结果为正数,无溢出
2、01:表示结果正溢出
3、10:表示结果负溢出
4、11:表示结果负数,无溢出 - 采用**
一位符号位根据数值位的进位情况判断溢出**
若**符号位(最高位)的进位Cn,与最高数位(次高位)的进位Cn-1相同,说明无溢出**,否则说明有溢出
加减运算电路
已知一个数的补码表示为Y,则这个数的负数的补码只要在原加法器的Y输入端加n个反向器以实现各位取反的功能,然后加一个2选1多路选择器,用一个**控制端Sub来控制,以选择是将Y输入加法器还是将非Y输入加法器,并将Sub同时作为低位进位送到加法器(做减法时实现末位加1)**
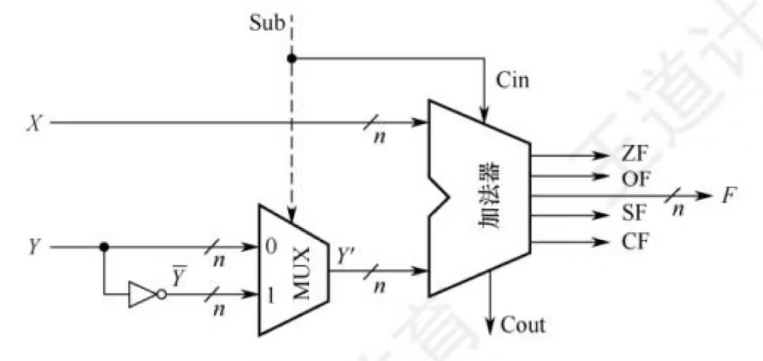
如上所示,该电路可实现模2n补码加减运算
当Sub为1时,做减法,实现X + 非Y = [x]补 + [-y]补
当Sub为0时,做加法,实现X + Y= [x]补 + [y]补
无符号整数相当于正整数的补码表示,上图电路也能实现无符号数的加/减运算
对于有符号数x和y,X和Y分别是x和y的补码表示;对于无符号数x和y,图中X和Y分别是x和y的二进制表示
不论是补码减法还是无符号数减法,都是用被减数加上减数的负数的补码(即非Y+1)来实现的
注:运算器本身无法识别所处理的二进制串是有符号数还是无符号数,只能通过标志信息来区分有符号整数运算结果和无符号整数运算结果
1、无符号数大小的比较
对于**无符号数的运算,零标志ZF、进/借位标志CF才有意义**
假设有两个无符号数A和B,下面以执行A - B为例来说明ZF、CF标志的几种可能情况:
- 若A = B,如A - B = 011 - 011 = 000,此时**
结果为零ZF = 1,无借位CF = 0** - 若A > B,如A - B = 010 - 001 = 001,此时**
结果非零ZF = 0,无借位CF = 0** - 若A < B,如A - B = 000 - 001 = (1)000 - 001 = 111,此时**
ZF = 0,有借位CF = 1**
当ZF = 1时,说明A = B;当ZF = 0且CF = 0时,说明A > B;当CF = 1时,说明A < B
2、有符号数大小的比较
对于有符号数的运算,零标志ZF、溢出标志OF、符号标志SF才有意义
假设两个有符号数A和B,用补码表示,以执行[A]补 - [B]补为例来说明ZF、OF、SF标志的几种可能情况:
- 若A = B
如[A]补 - [B]补 = 011 - 011 = [A]补 + [-B]补 = 011 + 101 = (1)000,此时C1 = 1;C2 = 1;C3 = 1,结果为零ZF = 1,最高位进位与次高位进位的异或结果**OF =** C3 xor C2 =0,结果的最高位SF = 0 - 若A > B
如[A]补 - [B]补 = 010 - 001 = 010 + 111 = (1)001,此时C1 = 0;C2 = 1;C3 = 1,ZF = 0,OF = 0,SF = 0
如[A]补 - [B]补 = 011 - 101 = 011 + 011 = 110,此时C1 = 1;C2 = 1;C3 = 0,ZF = 0,OF = 1,SF = 1 - 若A < B
如[A]补 - [B]补 = 000 - 001 = 000 + 111 = 111,此时C1 = 0;C2 = 0;C3 = 0,ZF = 0,OF = 0,SF = 1
如[A]补 - [B]补 = 101 - 011 = 101 + 101 = (1)010,此时C1 = 1;C2 = 0;C3 = 1,ZF = 0,OF = 1,SF = 0
当ZF = 1时,说明A = B
当ZF = 0
未发生溢出时,即OF = 0时,若SF = 0,则表示结果非负,说明A > B
当发生溢出时,即OF = 1时,若SF = 1,则必然是正数减去负数发生溢出导致结果为负
因此,当OF = SF且ZF = 0时,说明A > B
当ZF = 0
未发生溢出时,即OF = 0时,若SF = 1,则表示结果为负,说明A < B
当发生溢出时,即OF = 1时,若SF = 0,则必然是负数减去正数发生溢出导致结果为正
因此,当OF ≠ SF且ZF = 0时,说明A < B
原码的加减法运算
在原码加減运算中,将**符号位和数值位分开处理**,具体的规则如下:
加法规则:遵循**同号求和,异号求差**的原则,先判断两个操作数的符号位
符号位相同,则数值位相加,结果符号位不变,若最高数值位相加产生进位,则发生溢出
符号位不同,则做减法,绝对值大的数减去绝对值小的数,结果符号位与绝对值大的数相同
减法规则:先将减数的符号取反,然后将被减数与符号取反后的减数按原码加法进行运算
定点数的乘除运算
定点乘法运算
1、乘法运算的基本原理
原码乘法的特点是符号位与数值位是分开求的
原码乘法运算分为两步:
- 乘积的**
符号位由两个乘数的符号位异或得到** - 乘积的**
数值位是两个乘数的绝对值之积**
两个定点数的数值部分之积可视为两个无符号数的乘积
乘法运算可用加法和移位运算来实现(乘以2相当于做一次右移)。两个n位无符号数相乘共需进行n次加法和n次移位运算
注:由于参与运算的是两个数的数值位,因此运算过程中的右移操作均为逻辑右移
2、乘法运算电路
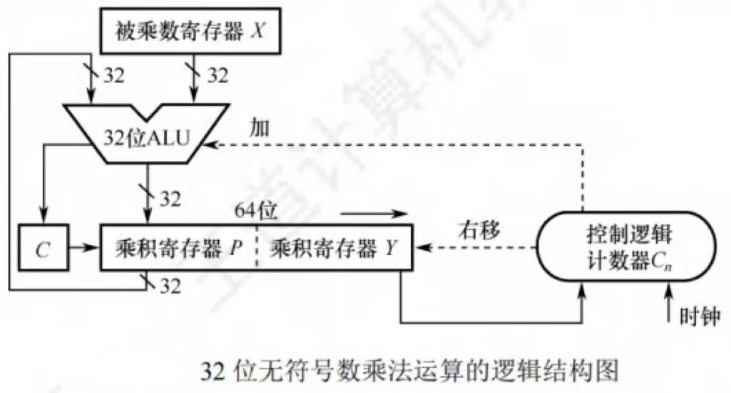
如上所示,为32位无符号数乘法运算的逻辑结构图
- 部分积和被乘数X做无符号数加法时,可能产生进位,因此设置一个专⻔的进位位C
乘积寄存器P初始置0。计数器Cn初值为32,每循环一次减1 ALU是乘法器的核心部件,对乘积寄存器P和被乘数寄存器X的内容做无符号加法运算,结果送回寄存器P,进位存放在C每次循环都对进位位C、寄存器P和寄存器Y实现同步逻辑右移,此时,进位位C移入寄存器P的最高位,寄存器Y的最低位移出。每次从寄存器Y移出的最低位都被送到控制逻辑,以决定被乘数是否加到部分积上
以0.1101 x 0.1011为例:
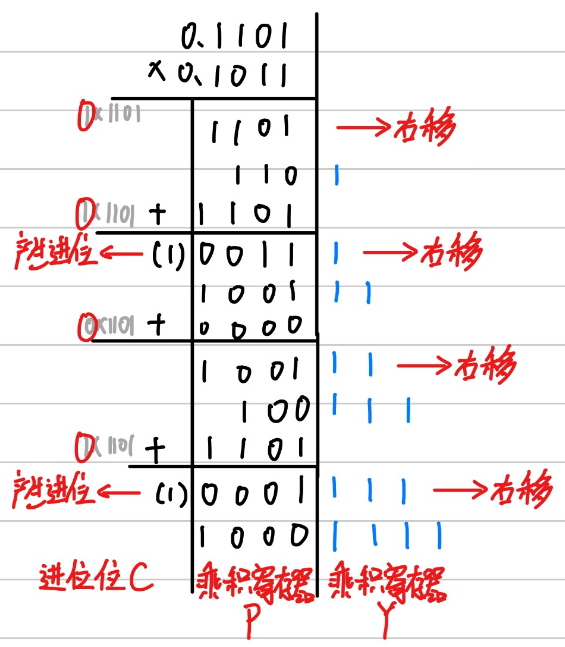
最后得到结果:0.1000 1111
在字⻓为32位的计算机中,对于两个int型变量x和y的乘积,若乘积高32位的每一位都相同,且都等于乘积低32位的符号,则表示不溢出,否则表示溢出
当x和y都为unsigned int型变量时,若乘积的高32位全为0,则表示不溢出,否则表不溢出
除法运算
1、除法运算的基本原理
n位定点数的除法运算,需统一为:一个2n位的数除以一个n位的数,得到一个n位的商,因此**需要对被除数进行扩展**
对于**定点正小数(即原码小数),只需在被除数低位添n个0即可
对于定点正整数(即无符号数),只需在被除数高位添n个0**即可
做整数除法时,若除数为0,则发生“除数为0”异常,此时需调出操作系统相应的异常处理程序进行处理
除数运算可归纳为:
被除数与除数相减,够减则上商为1,不够减则上商为0每次得到的差为中间余数,将除数右移后与上次的中间余数比较
用中间余数减除数,够减则上商为1,不够减则上商为0
如此重复,直到商的位数满足要求为止
若是2n位除以n位的无符号数,商的位数为n+1位,当**第一次试商为1时,则表示结果溢出(即无法用n位表示商)
若是两个n位的无符号数相除,则第一位商为0,且结果肯定不会溢出**
对于浮点数尾数的原码小数相除,第一次试商为1,则说明尾数部分有溢出,可通过**右规消除**(后面会讲)
原码除法运算也要将符号位和数值位分开处理,商的**符号位是两个数的符号位的异或结果,商的数值位是两个数的绝对值之商**
2、除法运算电路
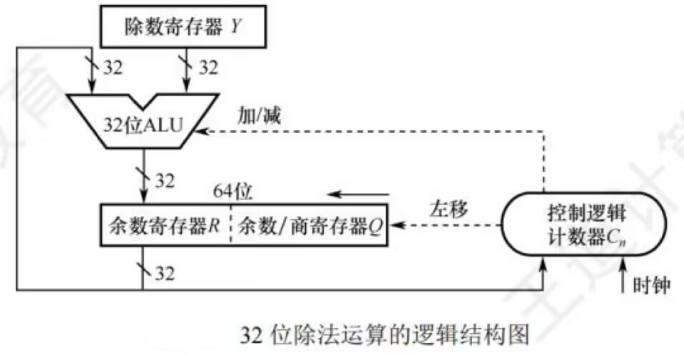
如上所示,为一个32位除法逻辑结构图
- 寄存器Y存放除数
寄存器R初始时存放扩展被除数的高32位,运算过程中存放中间余数的高位部分,结束时存放的是余数
寄存器Q初始时存放扩展被除数的低32位,运算过程中部分存放中间余数的低位部分、部分存放商,结束时存放的是32位商 ALU是除法器的核心部件,对寄存器R和Y的内容做加/减运算,运算结果被送回寄存器R- 计数器Cn,初值为32,每循环一次减1
每次循环,寄存器R和Q实现同步左移,左移时,Q的最高位移入R的最低位,Q中空出的量低位被上商。从低位开始,逐次把商的各个数位左移到Q中。每次由控制逻辑根据ALU运算结果的符号来决定上商是0还是1
以0000 1111 / 0010为例:

最后结果为:余数 = 0001;商 = 0111
注:若是两个32位int型整数相除,则除了-2^31 - 1会溢出,其余情况都不会溢出
提醒:
1、单纯的ALU不能存储运算结果和中间变量,因此往往将ALU和寄存器或暂存器相连,因此ALU由组合逻辑电路构成
2、储存模4补码仅需要一个符号位,因为正确的数值,模4补码的两个符号位总是相同的;而运算时,在ALU中需要两个符号位
3、对于加法器中的两个输入,在加法时不变,在减法时,减数直接取反(不论有符号还是无符号),末尾不需要加1。最后是通过低位进位符Sub来确定是加法还是减法的。当Sub为0表示加法;当Sub为0表示减法,单独把Sub推进加法器以实现再结果末尾加1
4、逻辑右移和算术右移的区别:主要区别在于它们处理符号位的方式。逻辑右移不考虑符号位,右移时在左侧补零;而算术右移需要考虑符号位,如果符号位为1(即负数),则在左侧补1,否则补0
5、加法器中,对于进/借位标志符CF,减法运算只需要判断借位,加法运算只需要判断进位
6、有符号数OF有意义,无符号数CF有意义,当题目未表明数是否有符号时,最好分两种情况讨论
浮点数的表示与运算
浮点数的表示
浮点数表示法是指以适当的形式将比例因子表示在数据中,让小数点的位置根据需要而浮动
这样,在位数有限的情况下,既扩大了数的表示范围,又保持了数的有效精度
浮点数的表示格式
N = ( − 1 ) S ∗ M ∗ R E N=(-1)^S*M*R^E N=(−1)S∗M∗RE
- S取0或1,用来决定浮点数的符号
- M是一个二进制定点小数,称为尾数,一般用定点原码小数表示
- E是一个二进制定点整数,称为阶码或指数,用移码表示
- R是基数(隐含),可以约定为2、4、16等
浮点数由符号、尾数和阶码三部分组成。如下所示,为一个32位短浮点数的格式

- 第0位:符号位S,正为0;负为1
- 第1 ~ 7位:移码表示的阶码E(偏置值为2n-1 = 64)
- 第8 ~ 31位:24位二进制原码小数表示的尾数M
- 基数R:为2(所有数中都没有体现,但由于计算机的为二进制,则规定为2)
阶码的值反映浮点数的小数点的实际位置;阶码的位数反映浮点数的表示范围;尾数的位数反映浮点数的精度
举个例子:
32位的浮点数:-8.25
写成二进制:1 1000.01
除去符号位可以表示为:1.00001 x 10^3
因为偏置值为2^(n-1) = 2^6 = 64
则阶码为:64 + 3 = 67,用二进制表示为100 0011
尾数为上面小数点后的数,为00001
即最后的表示为:1 1000011 00001 ...后面用0补满32位
浮点数的表示范围
浮点数的范围与原码一样是关于原点对称的:

- 运算结果**
大于最大正数时称为正上溢,小于绝对值最大负数时称负上溢,正上溢和负上溢统称上溢**
数据一旦产生上溢,计算机必须**中断运算操作,进行溢出处理** - 运算结果**
在0至最小正数之间时称为正下溢,在0至绝对值最小负数之间时称为负下溢,正下溢和负下溢统称下溢**
数据下溢时,浮点数值趋于零,计算机将其当作机器零处理
浮点数的规格化
规格化操作,是指通过调整一个非规格化浮点数的尾数和阶码的大小,使非零浮点数在尾数的最高数位上保证是一个有效值。在浮点数运算过程中尽可能多地保留有效数字的位数,使有效数字尽量占满尾数数位
- 左规:当运算结果的**
尾数的最高数位不是有效位,即出现±0.0…0x…x的形式(又或者说数不是按照如0.01 x 2n 的形式表示)时,需要进行左规
左规时,尾数每左移一位、阶码减1(基数为2时)。左规可能要进行多次** - 右规:当运算结果的**
尾数的有效位进到小数点前面时,即出现类似于00.1 x 2n 的形式,需要进行右规,右规只需进行一次。将尾数右移一位、阶码加1(基数2时)。右规时,阶码增加可能导致溢出**
正数为0.1x…×的形式,最大值为0.11…1,最小值为0.10…0,表示范围为1/2 ≤ M ≤ (1 - 2-n)
负数为1.1x…x的形式,最大値为1.10…0,最小値为1.11…1,表示范围为**-(1 - 2-n) ≤ M ≤ -1/2**
基数不同,浮点数的规格化形式也不同。当**浮点数尾数的基数为2时,原码规格化数的尾数最高位一定是1**
IEEE754标准
按照IEEE754标准,常用的浮点数的格式如下所示

IEEE754标准规定常用的浮点数格式有**32位单精度浮点数(短浮点数、float型)和64位双精度浮点数**(⻓浮点数、double型),其基数隐含为2

单精度格式包含**1位符号s、8位阶码e和23位尾数f**
双精度格式包含**1位符号s、11位阶码e和52位尾数f**
基数隐含为2;尾数用原码表示
对于规格化的二进制浮点数,尾数的最高位总是1,为了能使尾数多表示一位有效位,将这个1隐藏,称为隐藏位,因此23位尾数实际表示了24位有效数字
IEEE754规定**隐藏位1的位置在小数点之前**,例如,(12)10 = (1100)2,将它规格化后结果为1.1 × 23,其中整数部分的1将不存储在23位尾数内
注:单精度与双精度浮点数都采用隐藏尾数最高位的方法,因而使浮点数的精度更高
在IEEE754标准中,指数用移码表示,但偏置值并不是通常n位移码所用的2n-1,而是2n-1 - 1
因此,单精度和双精度浮点数的偏置值分别为28-1 - 1 = 127和211-1 - 1 = 1023
在存储浮点数阶码之前,偏置值要先加到阶码真值上(注意是存储,运算过程中是不用加的)
因此,规格化浮点数的真值为:
- 单精度浮点数:(-1)s x 1.f x 2e-127
- 双精度浮点数:(-1)s x 1.f x 2e-1023
IEEE754规格化浮点数的表示范围如下:

对于IEEE754格式的浮点数,解码全为0或1时,有其特别的解释:
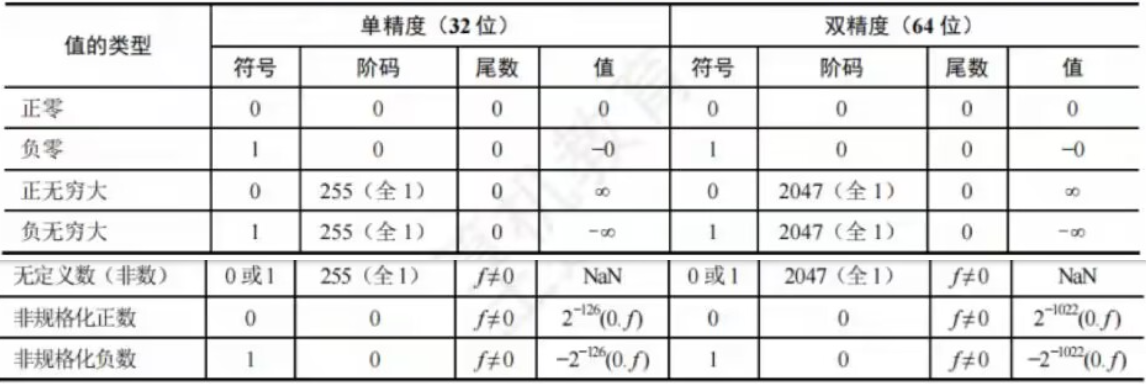
- 全0阶码全0尾数:
+0/-0。零的符号取决于符号s,一般情况下+0和-0是等效的 - 全1阶码全0尾数:
+∞/-∞。+∞在数值上大于所有有限数,-∞则小于所有有限数
引入无穷大数的目的是,在计算过程出现异常的情况下使得程序能继续进行下去 - 全1阶码非0尾数:
NaN。表示一个没有定义的数,称为非数 - 全0阶码非0尾数:
非规格化数。非规格化数的特点是阶码为全0,尾数高位有一个或几个连续的0,但不全为0
因此,非规格化数的隐藏位为0,且单精度和双精度浮点数的指数分别为-126或-1022
非规格化数可以用于处理阶码下溢
举个例子:
32位的浮点数:-8.25
写成二进制:1 1000.01
除去符号位可以表示为:1.00001 x 10^3
因为偏置值为2^(n-1) - 1 = 2^7 - 1 = 127
则阶码为:127 + 3 = 130,用二进制表示为1000 0010
尾数为上面小数点后的数,为00001
即最后的表示为:1 10000010 00001 ... 后面用0补满32位

定点、浮点表示的区別
- 数值的表示范围
若定点数和浮点数的字⻓相同,则**浮点表示法所能表示的数值范围远大于定点表示法** - 精度
对于字⻓相同的定点数和浮点数来说,浮点数虽然扩大了数的表示范围,但精度降低了 - 数的运算
浮点数包括阶码和尾数两部分,运算时不仅要做尾数的运算,还要做阶码的运算,而且运算结果要求规格化,所以浮点运算比定点运算复杂 - 溢出问题
在**定点运算中,当运算结果超出数的表示范围时,发生溢出**
在**浮点运算中,当运算结果超出尾数表示范围不一定溢出,只有规格化后阶码超出所能表示的范围时,才发生溢出**
浮点数的加减运算
浮点数运算的特点是**阶码运算和尾数运算分开进行**,浮点数加减运算分为以下几步:
对阶
对阶的目的是使两个操作数的小数点位置对⻬,即使得两个数的阶码相等
为此,先求阶码差,然后**以小阶码向大阶码看⻬的原则,将阶码小的尾数右移一位(基数为2),阶码加1,直到两个数的阶码相等为止**
尾数右移时,若舍弃有效位会产生误差,影响精度。为了保证运算的精度,尾数右移时,低位移出的位不要丢掉,应保留并参加尾数部分的运算
注:若采用大阶码向小阶码看⻬的原则,则尾数需要左移,敢高有效位被移出,导致结果出错
尾数加減
将对阶后的**尾数按定点原码小数的加(減)运算规则进行运算。因为IEEE754浮点数尾数中有一个隐藏位,因此在进行尾数加减时,必须将隐藏位还原到尾数部分。运算后的尾数不一定是规格化的,因此,浮点数的加减运算需要进一步进行规格化处理**
尾数规格化
IEEE754规格化尾数的形式为±1.x…x
尾数相加減后会得到各种可能结果,例如:
1.x…x + 1.x…x = ±1x.x…x
1.x…x - 1.x…x = ±0.0…01x…x
- 右规:当结果为
±1x.x…x时,需要进行右规。尾数右移一位,阶码加1。尾数右移时,最高位1被移到小数点前一位作为隐藏位,最后一位移出时,要考虑舍入 - 左规:当结果为
±0.0…01x…x时,需要进行左规。尾数每左移一位,阶码减1。可能需要左规多次,直到将第一位1移到小数点左边
注:左规一次相当于乘以2,右规一次相当于除以2;需要右规时,只需进行一次
舍入
在对阶和尾数右规时,可能会对尾数进行右移,为保证运算精度,一般将移出的部分低位保留下来,参加中间过程的运算,最后再将运算结果进行舍入,还原表示成IEEE754格式
IEEE754提供了以下4种可选的舍入模式:
- 就近舍入:
舍入为最近的可表示数
当运算结果是**两个可表示数的非中间值时,实际上是0舍1入方式(类似于十进制的“四舍五入”法)
当运算结果正好在两个可表示数的中间时,则选择结果为偶数**
如:1.24 × 105 + 5.04 × 102 (假定科学记数法的精度保留两位小数)
则结果是1.2400 × 105 + 0.0050 × 105 = 1.2450 × 105
结果在两个可表示数1.24 × 105和1.25 × 105的中间,采用就近舍入方式到偶数,则结果应该是1.24 × 105
又如:假定上述计算采用3位保留位
则结果是1.24000 ×105 + 0.00504 × 105 = 1.24504 × 105
结果就不在1.24 × 105和1.25 × 105的中间,而更接近于1.25 × 105,采用就近舍入方式,则结果应该是1.25 × 105
- 正向舍入:
朝数轴+∞方向舍入,即取右边最近的可表示数 - 负向舍入:
朝数轴-∞方向舍入,即取左边最近的可表示数 - 截断法:
直接截取所需位数,丢弃后面的所有位,这种舍入处理最简单,但同样相比于其他方法误差最大。对正数或负数来说,都是取更接近原点的那个可表示数,是一种趋向原点的舍入
溢出判断
在尾数规格化和尾数舍入时,可能会对结果的阶码执行加/减运算。因此,必须考虑指数溢出问题
若一个**正指数超过了最大允许值(127或1023),则发生指数上溢,产生异常**
若一个**负指数超过了最小允许值(-149或-1074),则发生指数下溢,通常把结果按机器零处理**
- 右规和尾数舍入。数值很大的尾数舍入时,可能因为末位加1而发生尾数溢出,此时需要通过右规来调整尾数和阶码。右规时阶码加1,导致**
阶码增大,因此需要判断是否发生了指数上溢**
如:当调整前的阶码11111110时,加1后,会变成11111111而发生指数上溢 - 左规。左规时阶码减1,导致**
阶码减小,因此需要判断是否发生了指数下溢**。其判断规则与指数上溢类似,左规一次,阶码减1,然后判断阶码是杏为全0来确定指数是否下溢
浮点数的溢出并不是以尾数溢出来判断的,尾数溢出可以通过右规操作得到纠正。运算结果是否溢出主要看结果的指数是否发生了上溢,因此是由指数上溢来判断的
注:某些题目中可能会指定尾数或阶码采用补码表示。通常可以采用双符号位,当尾数求和结果溢出(如尾数为 10.xx…× 或 01.xx…x)时,需右规一次;当结果出现 00.0xx…× 或 11.1xx…× 时,需要左规,直到尾数变为 00.1xx…× 或 11.0xx…x
C语言中的浮点数类型
在C程序中,等式的赋值和判断会导致强制类型转换,以**char -> int -> long -> double和float -> double最为常⻅,从前到后范围和精度都从小到大,转换过程没有损失**
不同类型数的混合运算时,遵循的原则是“类型提升”,即**较低类型转换为较高类型**
如long型与int型一起运算时,需先将int型转换为long型,然后进行运算,结果为long型
若float型和double型一起运算,虽然两者同浮点型,但精度不同,则仍需先将float型转换为double型后再进行运算,结果亦为double型
所有这些转换都是系统自动进行的,这种转换称为隐式类型转换
int型转换float型时,虽然不会发生溢出,但float型尾数连隐藏位共24位,当int型数的第24~31位非0时,无法精确转换成24位浮点数的尾数,需舍入处理,影响精度int型或float型转换为double型时,因double型的有效位数更多,因此**能保留精确值**double型转换为float型时,因**float型的表示范围更小,因此大数转换时可能会发生溢出**。此外,由于尾数有效位数变少,因此高精度数转换时会发生舍入float型或double型转换为int型时,因**int型没有小数部分,因此数据会向0方向截断(仅保留整数部分)**,发生舍入
数据的大小端和对⻬存储
数据的“大端方式”和“小端方式”存储
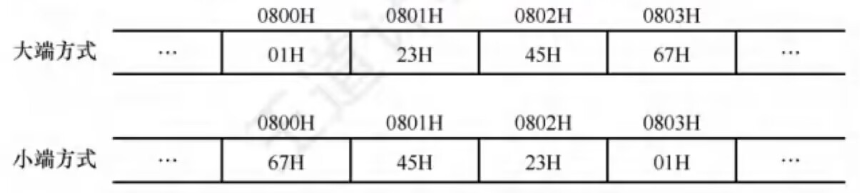
在存储数据时,数据从低位到高位可以按从左到右排列,也可以按从右到左排列。因此,无法用最左或最右来表征数据的最高位或最低位,通常用**最低有效字节(LSB)和最高有效字节(MSB)**来分别表示数据的低位和高位
例如,在32位计算机中,一个int型变量;的机器数为01234567H,其最高有效字节MSB = 01H,最低有效字节LSB = 67H
现代计算机基本都采用**字节编址,即每个地址编号中存放1字节。不同类型的数据占用的字节数不同,如int型和float型占4字节,double型占8字节等,而程序中对每个数据只给定一个地址,根据数据中各字节在连续字节序列中的排列顺序不同,可以采用两种排列方式:大端方式和小端方式**
- 大端方式:
先存储高位字节,后存储低位字节。字中的字节顺序和原序列的相同 - 小端方式:
先存储低位字节,后存储高位字节。字中的字节顺序和原序列的相反
数据按“边界对⻬”方式存储
现代计算机都是按字节编址的,假设字⻓为32位,数据按边界对⻬方式存放要求其存储地址是自身大小的整数倍,半字地址一定是2的整数倍,字地址一定是4的整数倍,这样无论所取的数据是字节、半字还是字,均可一次访存取出
当所存数据不满足上述要求时,可通过填充空白字节使其符合要求。这样做虽然会浪费一些存储空间,但可以**提高存取数据的速度**
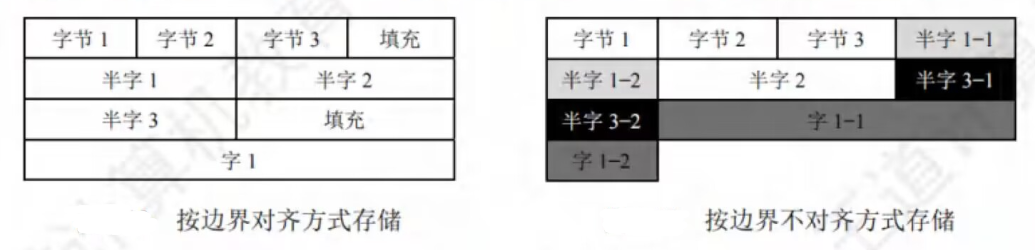
在C语言的struct类型中,“边界对⻬”有个重要要求:
- 每个成员按其类型的大小对⻬,char型的对⻬值为1,short型的对⻬值为2,int型的对⻬值为4,单位为字节
struct的⻓度必须是成员中最大对⻬值的整数倍(不够就补空字节)。这样就能保证struct数组的每项都满足边界对⻬的条件
举个例子:
struct A{
int a;
char b;
short c;
}
struct B{
char b;
int a;
short c;
}
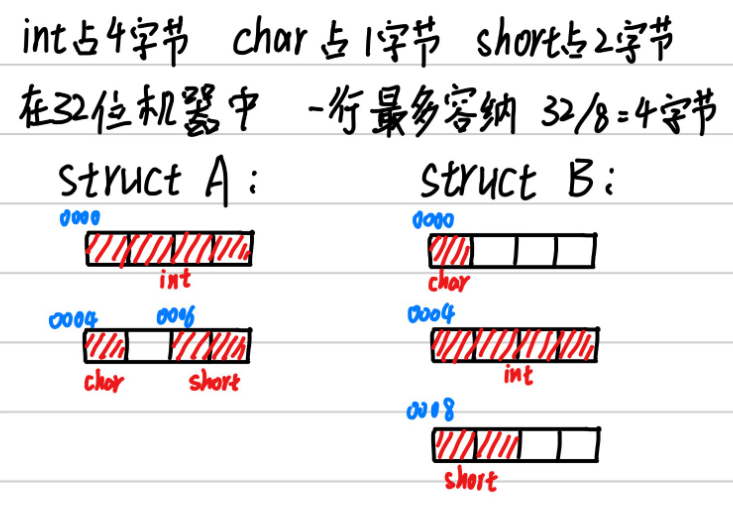
结构体成员在空间上对⻬:
- 每个成员存储的**
起始地址 % 该成员的⻓度 = 0**,而结构体中的成员都是按定义的先后顺序排放的 - 结构体的⻓度也必须是最大成员⻓度的整数倍,即**
结构体也要对⻬排放**
提醒:
1、补码的规格化表示时小数点后一位与符号位不同
2、原码表示的规格化小数是小数点后2位(基数为4,用2位表示)不全为0的小数
3、对阶是将较小解码调整到与较大的阶码一致,因此不存在阶码减小,尾数左移的情况
4、最小规格化负数为阶码取最大值2^1023(1023 = 2^(11-1) -1);尾数最大值2 - 2^-52(有隐藏位要+1),符号位为负
5、第一位为1,对于浮点数、原码、补码都为负,移码为正
6、位数相同的条件下,移码和补码的表示范围是相同的,阶码表示范围不变,即浮点数的表示范围不变,只是改变了浮点数的表示形式
7、舍入是浮点数的概念,定点数没有摄入的概念。浮点数摄入的情况有两种:对阶、右规
8、舍入不一定产生误差,如11.00到11.0无误差产生
9、小端方式最低有效字节在最小位置
本章小结
字长相同的情况下,浮点数和定点数的表示范围与精度有什么区别?
字长相同时,浮点数取字长的一部分作为阶码,所以表示范围比定点数要大,而取一部分作为阶码也就代表着尾数部位的有效位数减少,而定点数字长的全部位都用来表示数值本身,精度要比同字长的浮点数更大
用移码表示浮点数的阶码有什么好处?
1、浮点数进行加减运算时,要比较阶码的大小,移码比较大小更方便
2、检验移码的特殊值(0和max)时比较容易
阶码以移码编码时的特殊值如下
0:表示指数为负无穷大,相当于分数分母无穷大,整个数无穷接近0,在尾数也为0时可用来表示0;尾数不为零表示未规格化的数
max:表示指数正无穷大,若尾数为0,则表示浮点数超出表示范围(正负无穷大);尾数不为0,则表示浮点数运算错误
如何表示一个数值数据?计算机中的数值数据都是二进制数吗?
在计算机内部,数值数据的表示方法有以下两大类:
1、直接用二进制数表示。分为有符号数和无符号数,有符号数又分为定点数表示和浮点数表示。无符号数用来表示无符号整数(如地址等信息)
2、二进制编码的十进制数,一般采用BCD码表示,用来表示整数
所以,计算机中的数值数据虽然都用二进制表示,但不全是二进制,也有用十进制表示的
例如在指令类型中,就分别有二进制加法指令和十进制加法指令
什么称为无符号整数的“溢出”?
对于无符号定点整数来说,若寄存器位数不够,则计算机运算过程中一般保留低n位,舍弃高位
这样,会产生以下两种结果:
1、保留的低n位数不能正确表示运算结果。在这种情况下,意味着运算的结果超出了计算机所能表达的范围,有效数值进到了第n+1位,称此时发生了“溢出”现象
2、保留的低n位数能正确表达计算结果,即高位的舍去并不影响其运算结果
如何判断一个浮点数是否是规格化数?
为了使浮点数能尽量多地表示有效位数,一般要求运算结果用规格化数形式表示
规格化浮点数的尾数小数点后的第一位一定是个非零数
因此,对于原码编码的尾数来说,只要看尾数的第一位是否为1就行;对于补码表示的尾数,只要看符号位和尾数最高位是否相反
需要注意的是,IEEE754标准的浮点数尾数是用原码编码的
对于位数相同的定点数和浮点数,可表示的浮点数个数比定点数个数多吗?
可表示的数据个数取决于编码所采用的位数
编码位数一定,编码出来的数据个数就是一定的。n位编码只能表示2^n个数,所以对于相同位数的定点数和浮点数来说,可表示的数据个数应该一样多(有时可能因为一个值有两个或多个编码对应,编码个数会有少量差异)
现代计算机中是否要考虑原码加减运算?如何实现?
现代计算机中的浮点数采用IEEE754标准,所以在进行两个浮点数的加減运算时,必须考虑原码的加减运算,因为IEEE754标准的浮点数尾数都采用原码表示
原码的加減运算可以有以下两种实现方式:
1、转换为补码后,用补码加減法实现,结果再转换为原码
2、直接用原码进行加减运算,符号位和数值位分开处理



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









