







一、Spark Core
1.1 Spark 简介
1.1.1 简介
Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
Apache Spark is a unified analytics engine for large-scale data processing。(Apache Spark 是一个统一的大规模数据处理分析引擎)
发展历程:Spark 于 2009 年诞生于伯克利大学的 AMPLab 实验室,于2010 年伯克利大学正式开源了 Spark 项目,于2013 年 6 月Spark 成为了 Apache 基金会下的项目,于2014 年 2 月Spark 以飞快的速度成为了 Apache 的顶级项目,于2015 年至今Spark 变得愈发火爆,大量的国内公司开始重点部署或者使用 Spark。相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升,因此它成为继 MapReduce 之后,最为广泛使用的分布式计算框架
1.1.2 Spark特点
MapReduce缺点:
1、不能迭代式开发,只能是MR--MR
2、MR计算过程中数据会落盘,效率低
3、MR程序强制排序,会影响性能
4、MR程序只有map和reduce两个操作,操作单一
5、MR程序是基于进程的,进程开销大
Spark的优点:
1、迭代式开发
2、spark的计算是基于内存和磁盘的,优先使用内存
3、spark不会强制排序
4、操作算子丰富,高达80多个
5、spark是基于线程的,开销小
特点:
- 速度快(Apache Spark通过使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了批处理(离线计算)和流数据(实时计算)的高性能。)
- 易使用(Spark提供了80多个高级操作符,可以轻松构建并行应用程序。您可以从Java、Scala、Python、R和SQL、shell交互式地使用它。)
- 通用性(Spark支持一系列库,包括SQL和DataFrames、用于机器学习的MLlib、GraphX和SparkStreaming。您可以在同一个应用程序中无缝地组合这些库。)
- 到处运行(Spark可以运行在Hadoop、Apache Mesos、Kubernetes、 Standalone,也可以运行在云上。它可以访问不同的数据源,如 HDFS,Alluxio,Cassandra,HBase,Hive 以及数百个其他数据源中的数据。)

1.1.3 Spark集群架构
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
| Term(术语) | Meaning(含义) |
|---|---|
| Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
| Driver program | 主运用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
| Cluster manager | 集群资源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 执行计算任务的工作节点 |
| Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
| Task | 被发送到 Executor 中的工作单元 |
如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。

执行过程:
- 用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;
- Driver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
- Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
1.1.4 核心模块

Spark 基于 Spark Core 扩展了四个核心组件,分别用于满足不同领域的计算需求。
1.1.4.1 Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL、
Spark Streaming、GraphX、MLlib 都是在 Spark Core 的基础上进行扩展的。
1.1.4.2 Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。其具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC;
- 支持 HiveQL 语法以及用户自定义函数 (UDF),允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性,以提高查询效率。
1.1.4.3 Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理
数据流的 API。支持从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,并进行处理。

Spark Streaming 的本质是微批处理,它将数据流进行极小粒度的拆分,拆分为多个批处理,从而达到接近于流处理的效果。

1.1.4.4 MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等
额外的功能,还提供了一些更底层的机器学习原语。
它提供了以下工具:
| 工具 | 作用 |
| 常见的机器学习算法 | 如分类,回归,聚类和协同过滤 |
| 特征化 | 特征提取,转换,降维和选择 |
| 管道 | 用于构建,评估和调整 ML 管道的工具 |
| 持久性 | 保存和加载算法,模型,管道数据 |
| 实用工具 | 线性代数,统计,数据处理等 |
1.1.4.5 Graphx
GraphX 是 Spark 面向图计算提供的框架与算法库。
1.2 Spark 开发环境搭建
1.2.1 安装Spark
1.2.1.1 下载并解压
官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载
解压安装包:
# tar -zxvf spark-2.4.8-bin-hadoop2.7.tgz -C ../apps/
1.2.1.2 创建软连接
# ln -s spark-2.4.8-bin-hadoop2.7/ spark1.2.1.3 配置环境变量
# vim /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.4.8-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile1.2.1.4 修改配置
[usr@hadoop001 conf]$ mv spark-env.sh.template spark-env.sh
[usr@hadoop001 conf]$ vim spark-env.sh
export JAVA_HOME=/home/hadoop/apps/jdk1.2.1.5 运行shell
$ spark-shellLocal 模式是最简单的一种运行方式,它采用单节点多线程方式运行,不用部署,开箱即用,适合日常测试开发。
# 启动spark-shell
spark-shell --master local[2]
- local:只启动一个工作线程;
- local[k]:启动 k 个工作线程;
- local[*]:启动跟 cpu 数目相同的工作线程数。

进入 spark-shell 后,程序已经自动创建好了上下文 SparkContext,等效于执行了下面的 Scala 代码:
val conf = new SparkConf().setAppName("Spark shell").setMaster("local[2]")
val sc = new SparkContext(conf)
1.2.2 词频统计案例
安装完成后可以先做一个简单的词频统计例子,感受 spark 的魅力。准备一个词频统计的文件样本 wc.txt,内容如下:
hadoop,spark,hadoop
spark,flink,flink,spark
hadoop,hadoop
在 scala 交互式命令行中执行如下 Scala 语句:
val file = spark.sparkContext.textFile("file:///usr/app/wc.txt")
val wordCounts = file.flatMap(line => line.split(",")).map((word => (word, 1))).reduceByKey(_ + _)
wordCounts.collect
执行过程如下,可以看到已经输出了词频统计的结果:

同时还可以通过 Web UI 查看作业的执行情况,访问端口为 4040:

退出本地模式,按键 Ctrl+C 或输入 Scala 指令:
:quit1.2.3 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
101) --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱
们自己打的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
1.2.4 Standalone 模式
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的
集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的
独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式。
集群规划:
| hadoop01 | hadoop02 | hadoop03 | |
| Spark | Woker Master | Woker | Woker |
1.2.4.1 解压缩文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩在指定位置
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone1.2.4.2 修改配置文件
1) 进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
mv slaves.template slaves2) 修改 slaves 文件,添加 work 节点
hadoop01
hadoop02
hadoop033) 修改 spark-env.sh.template 文件名为 spark-env.sh
mv spark-env.sh.template spark-env.sh4) 修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=hadoop01
SPARK_MASTER_PORT=7077注意:7077 端口,相当于 hadoop3 内部通信的 8020 端口,此处的端口需要确认自己的 Hadoop
配置
5) 分发 spark-standalone 目录
xsync spark-standalone1.2.4.3 启动集群
1) 执行脚本命令:
sbin/start-all.sh2) 查看三台服务器运行进程
================hadoop01================
3330 Jps
3238 Worker
3163 Master
================hadoop02================
2966 Jps
2908 Worker
================hadoop03================
2978 Worker
3036 Jps3) 查看 Master 资源监控 Web UI 界面: http://hadoop01:8080
1.2.4.4 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
101) --class 表示要执行程序的主类
2) --master spark://hadoop01:7077 独立部署模式,连接到 Spark 集群
3) spark-examples_2.12-3.0.0.jar 运行类所在的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
执行任务时,会产生多个 Java 进程

执行任务时,默认采用服务器集群节点的总核数,每个节点内存 1024M。

1.2.4.5 提交参数说明
在提交应用中,一般会同时提交一些参数
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]| 参数 | 解释 | 可选值举例 |
| --class | Spark 程序中包含主函数的类 | |
| --master | Spark 程序运行的模式(环境) | 模式:local[*]、spark://linux1:7077、Yarn |
| --executor-memory 1G | 指定每个 executor 可用内存为 1G | 符合集群内存配置即可,具体情况具体分析。 |
| --total-executor-cores 2 | 指定所有executor使用的cpu核数为 2 个 | ...... |
| --executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用 jar,包含依赖。这 个 URL 在集群中全局可见。比 如 hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的 path 都包含同样的 jar | |
| application-arguments | 传给 main()方法的参数 |
1.2.4.6 配置历史服务器
由于 spark-shell 停止掉后,集群监控 linux1:4040 页面就看不到历史任务的运行情况,所以
开发时都配置历史服务器记录任务运行情况。
1) 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf2) 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:8020/directory注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
sbin/start-dfs.sh
hadoop fs -mkdir /directory3) 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop01:8020/directory
-Dspark.history.retainedApplications=30"⚫ 参数 1 含义:WEB UI 访问的端口号为 18080
⚫ 参数 2 含义:指定历史服务器日志存储路径
⚫ 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序
信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4) 分发配置文件
xsync conf5) 重新启动集群和历史服务
sbin/start-all.sh
sbin/start-history-server.sh6) 重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
7) 查看历史服务:http://hadoop01:18080
1.2.4.7 配置高可用(HA)
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以
为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master
发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用
Zookeeper 设置
集群规划:
| hadoop01 | hadoop02 | hadoop03 | |
| Spark | Master Zookeeper Worker | Master Zookeeper Worker | Zookeeper |
1) 停止集群
sbin/stop-all.sh2) 启动 Zookeeper
zk.sh start3) 修改 spark-env.sh 文件添加如下配置
#注释如下内容:
#SPARK_MASTER_HOST=hadoop01
#SPARK_MASTER_PORT=7077
#添加如下内容:
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自
定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop01,hdoop02,hadoop03
-Dspark.deploy.zookeeper.dir=/spark"4) 分发配置文件
xsync conf/5) 启动集群
sbin/start-all.shhttp://hadoop01:8989

6) 启动 hadoop02 的单独 Master 节点,此时 hadoop02 节点 Master 状态处于备用状态
[root@hadoop02 spark-standalone]# sbin/start-master.shhttp://hadoop02:8989

7) 提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077,hadoop02:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
108) 停止 hadoop01 的 Master 资源监控进程

kill -9 6703
9) 查看 hadoop2 的 Master 资源监控 Web UI,稍等一段时间后,hadoop02 节点的 Master 状态
提升为活动状态
http://hadoop02:8989

1.2.5 Yarn 模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这
种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主
要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是
和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的 Yarn 环境
下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
1.2.5.1 解压缩文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 linux 并解压缩,放置在指定位置。
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn1.2.5.2 修改配置文件
1) 修改 hadoop 配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml, 并分发
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>2) 修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
mv spark-env.sh.template spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop1.2.5.3 启动 HDFS 以及 YARN 集群
1.2.5.4 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
101.2.5.5 配置历史服务器
1) 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
2) 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux1:8020/directory
注意:需要启动 hadoop 集群,HDFS 上的目录需要提前存在。
[root@linux1 hadoop]# sbin/start-dfs.sh
[root@linux1 hadoop]# hadoop fs -mkdir /directory
3) 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://linux1:8020/directory
-Dspark.history.retainedApplications=30"
⚫ 参数 1 含义:WEB UI 访问的端口号为 18080
⚫ 参数 2 含义:指定历史服务器日志存储路径
⚫ 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序
信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4) 修改 spark-defaults.conf
spark.yarn.historyServer.address=linux1:18080
spark.history.ui.port=18080
5) 启动历史服务
sbin/start-history-server.sh
6) 重新提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10

7) Web 页面查看日志:http://hadoop02:8088
8) 查看历史服务的Web UI :http://hadoop01:18080
1.2.6 部署模式对比
| 模式 | Spark 安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3及以上 | Master 及 Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn 及 HDFS | Hadoop | 混合部署 |
1.2.7 端口号
➢ Spark 查看当前 Spark-shell 运行任务情况端口号:4040(计算)
➢ Spark Master 内部通信服务端口号:7077
➢ Standalone 模式下,Spark Master Web 端口号:8080(资源)
➢ Spark 历史服务器端口号:18080
➢ Hadoop YARN 任务运行情况查看端口号:8088
1.2.8 Scala开发环境配置
Spark 是基于 Scala 语言进行开发的,分别提供了基于 Scala、Java、Python 语言的 API,如果你想使用 Scala 语言进行开发,则需要搭建 Scala 语言的开发环境。
1.2.8.1 前置条件
Scala 的运行依赖于 JDK,所以需要你本机有安装对应版本的 JDK,最新的 Scala 2.12.x 需要 JDK 1.8+。
1.2.8.2 安装Scala插件
IDEA 默认不支持 Scala 语言的开发,需要通过插件进行扩展。打开 IDEA,依次点击 File => settings=> plugins 选项卡,搜索 Scala 插件 (如下图)。找到插件后进行安装,并重启 IDEA 使得安装生效。

1.2.8.3 创建Scala项目
在 IDEA 中依次点击 File => New => Project 选项卡,然后选择创建 Scala—IDEA 工程:

1.2.8.4 下载Scala SDK
1. 方式一
此时看到 Scala SDK 为空,依次点击 Create => Download ,选择所需的版本后,点击 OK 按钮进行下载,下载完成点击 Finish 进入工程。

2. 方式二
方式一是 Scala 官方安装指南里使用的方式,但下载速度通常比较慢,且这种安装下并没有直接提供 Scala 命令行工具。所以个人推荐到官网下载安装包进行安装,下载地址:https://www.scala-lang.org/download/
这里我的系统是 Windows,下载 msi 版本的安装包后,一直点击下一步进行安装,安装完成后会自动配置好环境变量。

由于安装时已经自动配置好环境变量,所以 IDEA 会自动选择对应版本的 SDK。

1.2.8.5 创建Hello World
在工程 src 目录上右击 New => Scala class 创建 Hello.scala。输入代码如下,完成后点击运行按钮,成功运行则代表搭建成功。

1.2.8.6 切换Scala版本
在日常的开发中,由于对应软件(如 Spark)的版本切换,可能导致需要切换 Scala 的版本,则可以在 Project Structures 中的 Global Libraries 选项卡中进行切换。

1.2.8.7 可能出现的问题
1.在 IDEA 中有时候重新打开项目后,在工程 src/main目录上右键单击,new > Directory 命名为scala,接着标记为Sources Root如下图:

右击 New => Scala class 创建类发现找不到Sclass class 此时需要对项目Add Framework Support 如下图:

在左边框找到Scala勾选,点击ok,就可以问题解决。

2.在 IDEA 中有时候重新打开项目后,右击并不会出现新建 scala 文件的选项,或者在编写时没有 Scala 语法提示,此时可以先删除 Global Libraries 中配置好的 SDK,之后再重新添加:

另外在 IDEA 中以本地模式运行 Spark 项目是不需要在本机搭建 Spark 和 Hadoop 环境的。
1.3 弹性分布式数据集 RDD
1.3.1 RDD简介
RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD 转换而来,它具有以下特性:
- 一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,则默认采用程序所分配到的 CPU 的核心数;
- RDD 拥有一个用于计算分区的函数 compute;
- RDD 会保存彼此间的依赖关系,RDD 的每次转换都会生成一个新的依赖关系,这种 RDD 之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算;
- Key-Value 型的 RDD 还拥有 Partitioner(分区器),用于决定数据被存储在哪个分区中,目前 Spark 中支持 HashPartitioner(按照哈希分区) 和 RangeParationer(按照范围进行分区);
- 一个优先位置列表 (可选),用于存储每个分区的优先位置 (prefered location)。对于一个 HDFS 文件来说,这个列表保存的就是每个分区所在的块的位置,按照“移动数据不如移动计算”的理念,Spark 在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理数据块的存储位置。
RDD[T] 抽象类的部分相关代码如下:
// 由子类实现以计算给定分区
def compute(split: Partition, context: TaskContext): Iterator[T]
// 获取所有分区
protected def getPartitions: Array[Partition]
// 获取所有依赖关系
protected def getDependencies: Seq[Dependency[_]] = deps
// 获取优先位置列表
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
// 分区器 由子类重写以指定它们的分区方式
@transient val partitioner: Option[Partitioner] = None1.3.2 创建RDD
RDD 有两种创建方式,分别介绍如下:
(1)由现有集合创建
这里使用 spark-shell 进行测试,启动命令如下:
spark-shell --master local[4]启动 spark-shell 后,程序会自动创建应用上下文,相当于执行了下面的 Scala 语句:
val conf = new SparkConf().setAppName("Spark shell").setMaster("local[4]")
val sc = new SparkContext(conf)由现有集合创建 RDD,你可以在创建时指定其分区个数,如果没有指定,则采用程序所分配到的 CPU 的核心数:
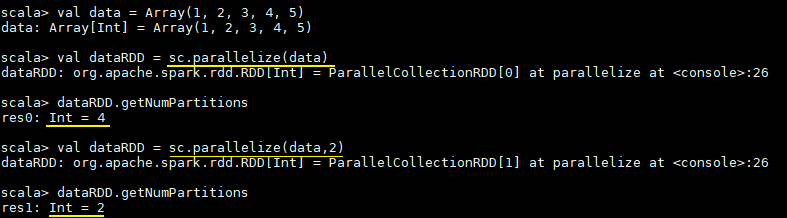
val data = Array(1, 2, 3, 4, 5)
// 由现有集合创建 RDD,默认分区数为程序所分配到的 CPU 的核心数
val dataRDD = sc.parallelize(data)
// 查看分区数
dataRDD.getNumPartitions
// 明确指定分区数
val dataRDD = sc.parallelize(data,2)执行结果如下:
1.3.3 引用外部存储系统中的数据集
引用外部存储系统中的数据集,例如本地文件系统,HDFS,HBase 或支持 Hadoop InputFormat 的任何数据源。
val fileRDD = sc.textFile("/usr/file/emp.txt")
// 获取第一行文本
fileRDD.take(1)使用外部存储系统时需要注意以下两点:
- 如果在集群环境下从本地文件系统读取数据,则要求该文件必须在集群中所有机器上都存在,且路径相同;
- 支持目录路径,支持压缩文件,支持使用通配符。
1.3.4 textFile & wholeTextFiles
两者都可以用来读取外部文件,但是返回格式是不同的:
- textFile:其返回格式是
RDD[String],返回的是就是文件内容,RDD 中每一个元素对应一行数据; - wholeTextFiles:其返回格式是
RDD[(String, String)],元组中第一个参数是文件路径,第二个参数是文件内容; - 两者都提供第二个参数来控制最小分区数;
- 从 HDFS 上读取文件时,Spark 会为每个块创建一个分区。
def textFile(path: String,minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {...}
def wholeTextFiles(path: String,minPartitions: Int = defaultMinPartitions): RDD[(String, String)]={..}1.4 操作RDD
RDD 支持两种类型的操作:transformations(转换,从现有数据集创建新数据集)和 actions(在数据集上运行计算后将值返回到驱动程序)。RDD 中的所有转换操作都是惰性的,它们只是记住这些转换操作,但不会立即执行,只有遇到 action 操作后才会真正的进行计算,这类似于函数式编程中的惰性求值。
val list = List(1, 2, 3)
// map 是一个 transformations 操作,而 foreach 是一个 actions 操作
sc.parallelize(list).map(_ * 10).foreach(println)
// 输出: 10 20 301.5 缓存RDD
1.5.1 缓存级别
Spark 速度非常快的一个原因是 RDD 支持缓存。成功缓存后,如果之后的操作使用到了该数据集,则直接从缓存中获取。虽然缓存也有丢失的风险,但是由于 RDD 之间的依赖关系,如果某个分区的缓存数据丢失,只需要重新计算该分区即可。
Spark 支持多种缓存级别 :
| Storage Level (存储级别) | Meaning(含义) |
|---|---|
MEMORY_ONLY | 默认的缓存级别,将 RDD 以反序列化的 Java 对象的形式存储在 JVM 中。如果内存空间不够,则部分分区数据将不再缓存。 |
MEMORY_AND_DISK | 将 RDD 以反序列化的 Java 对象的形式存储 JVM 中。如果内存空间不够,将未缓存的分区数据存储到磁盘,在需要使用这些分区时从磁盘读取。 |
MEMORY_ONLY_SER | 将 RDD 以序列化的 Java 对象的形式进行存储(每个分区为一个 byte 数组)。这种方式比反序列化对象节省存储空间,但在读取时会增加 CPU 的计算负担。仅支持 Java 和 Scala 。 |
MEMORY_AND_DISK_SER | 类似于 MEMORY_ONLY_SER,但是溢出的分区数据会存储到磁盘,而不是在用到它们时重新计算。仅支持 Java 和 Scala。 |
DISK_ONLY | 只在磁盘上缓存 RDD |
MEMORY_ONLY_2,MEMORY_AND_DISK_2, etc | 与上面的对应级别功能相同,但是会为每个分区在集群中的两个节点上建立副本。 |
OFF_HEAP | 与 MEMORY_ONLY_SER 类似,但将数据存储在堆外内存中。这需要启用堆外内存。 |
启动堆外内存需要配置两个参数:
- spark.memory.offHeap.enabled :是否开启堆外内存,默认值为 false,需要设置为 true;
- spark.memory.offHeap.size : 堆外内存空间的大小,默认值为 0,需要设置为正值。
1.5.2 使用缓存
缓存数据的方法有两个:persist 和 cache 。cache 内部调用的也是 persist,它是 persist 的特殊化形式,等价于 persist(StorageLevel.MEMORY_ONLY)。示例如下:
// 所有存储级别均定义在 StorageLevel 对象中
fileRDD.persist(StorageLevel.MEMORY_AND_DISK)
fileRDD.cache()1.5.3 移除缓存
Spark 会自动监视每个节点上的缓存使用情况,并按照最近最少使用(LRU)的规则删除旧数据分区。当然,你也可以使用 RDD.unpersist() 方法进行手动删除。
1.6 理解shuffle
1.6.1 shuffle介绍
在 Spark 中,一个任务对应一个分区,通常不会跨分区操作数据。但如果遇到 reduceByKey 等操作,Spark 必须从所有分区读取数据,并查找所有键的所有值,然后汇总在一起以计算每个键的最终结果 ,这称为 Shuffle。
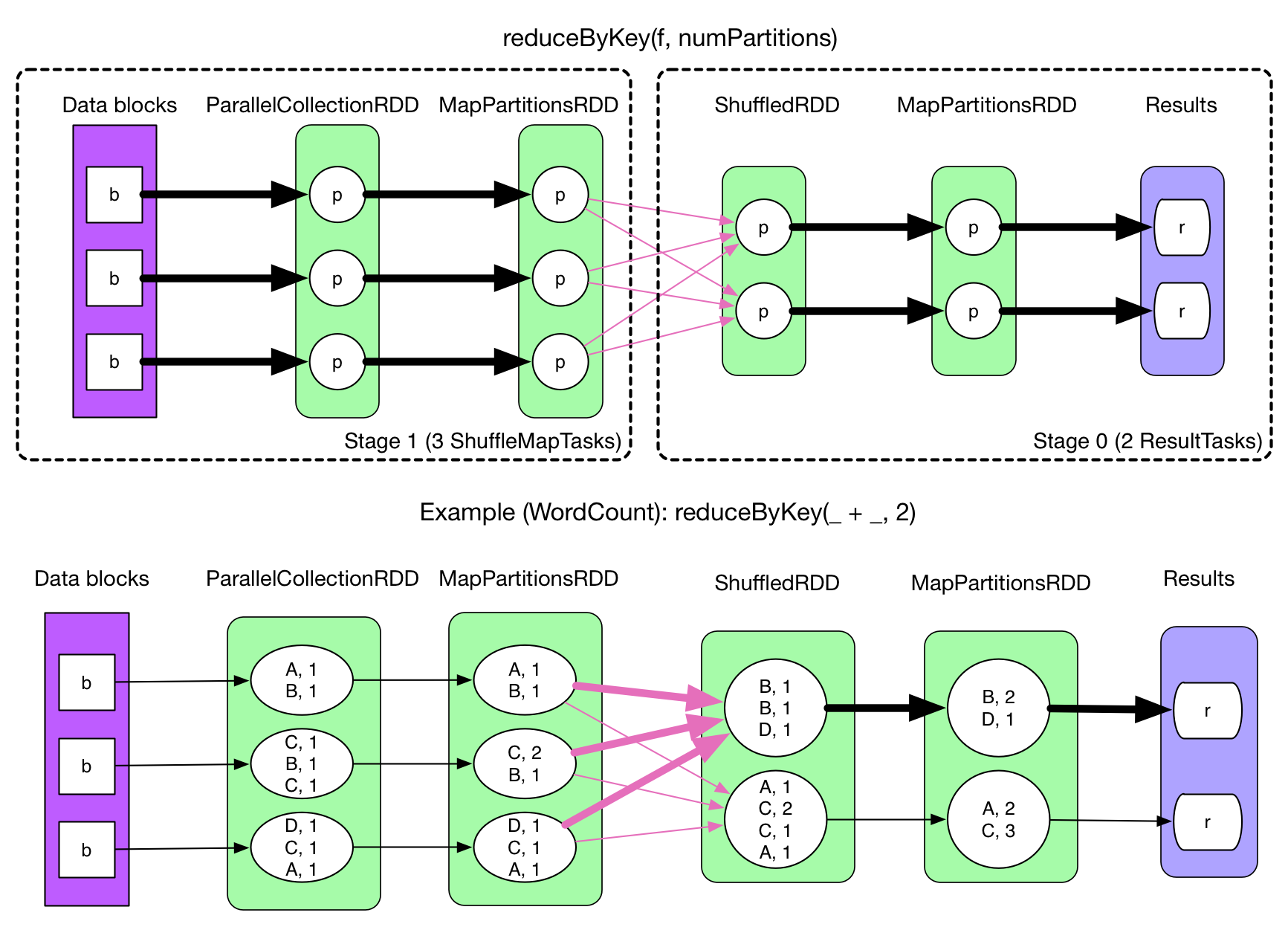
1.6.2 Shuffle的影响
Shuffle 是一项昂贵的操作,因为它通常会跨节点操作数据,这会涉及磁盘 I/O,网络 I/O,和数据序列化。某些 Shuffle 操作还会消耗大量的堆内存,因为它们使用堆内存来临时存储需要网络传输的数据。Shuffle 还会在磁盘上生成大量中间文件,从 Spark 1.3 开始,这些文件将被保留,直到相应的 RDD 不再使用并进行垃圾回收,这样做是为了避免在计算时重复创建 Shuffle 文件。如果应用程序长期保留对这些 RDD 的引用,则垃圾回收可能在很长一段时间后才会发生,这意味着长时间运行的 Spark 作业可能会占用大量磁盘空间,通常可以使用 spark.local.dir 参数来指定这些临时文件的存储目录。
1.6.3 导致Shuffle的操作
由于 Shuffle 操作对性能的影响比较大,所以需要特别注意使用,以下操作都会导致 Shuffle:
- 涉及到重新分区操作: 如
repartition和coalesce; - 所有涉及到 ByKey 的操作:如
groupByKey和reduceByKey,但countByKey除外; - 联结操作:如
cogroup和join。
1.7 宽依赖和窄依赖
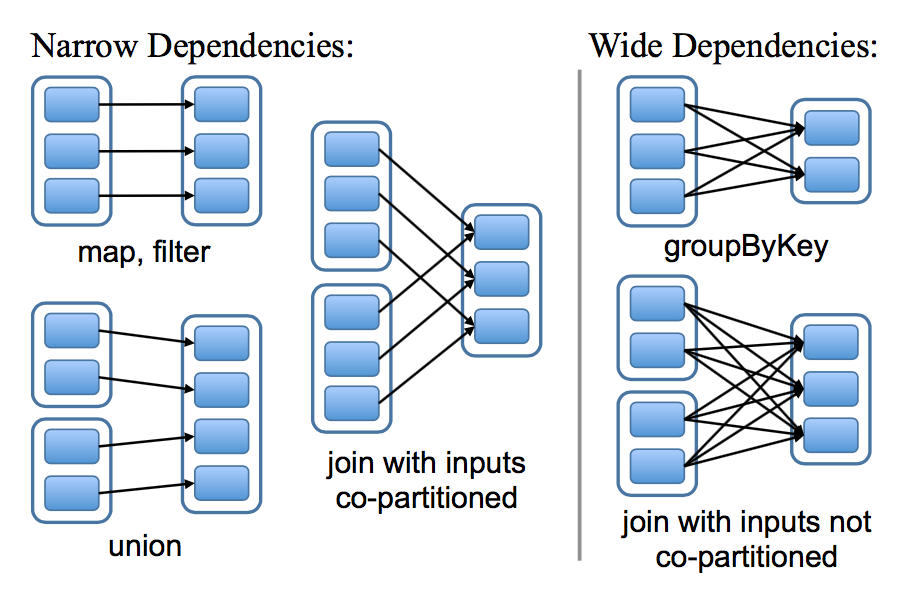
RDD 和它的父 RDD(s) 之间的依赖关系分为两种不同的类型:
- 窄依赖 (narrow dependency):父 RDDs 的一个分区最多被子 RDDs 一个分区所依赖;
- 宽依赖 (wide dependency):父 RDDs 的一个分区可以被子 RDDs 的多个子分区所依赖。
如下图,每一个方框表示一个 RDD,带有颜色的矩形表示分区:
区分这两种依赖是非常有用的:
- 首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)对父分区数据进行计算,例如先执行 map 操作,然后执行 filter 操作。而宽依赖则需要计算好所有父分区的数据,然后再在节点之间进行 Shuffle,这与 MapReduce 类似。
- 窄依赖能够更有效地进行数据恢复,因为只需重新对丢失分区的父分区进行计算,且不同节点之间可以并行计算;而对于宽依赖而言,如果数据丢失,则需要对所有父分区数据进行计算并再次 Shuffle。
1.8 DAG的生成
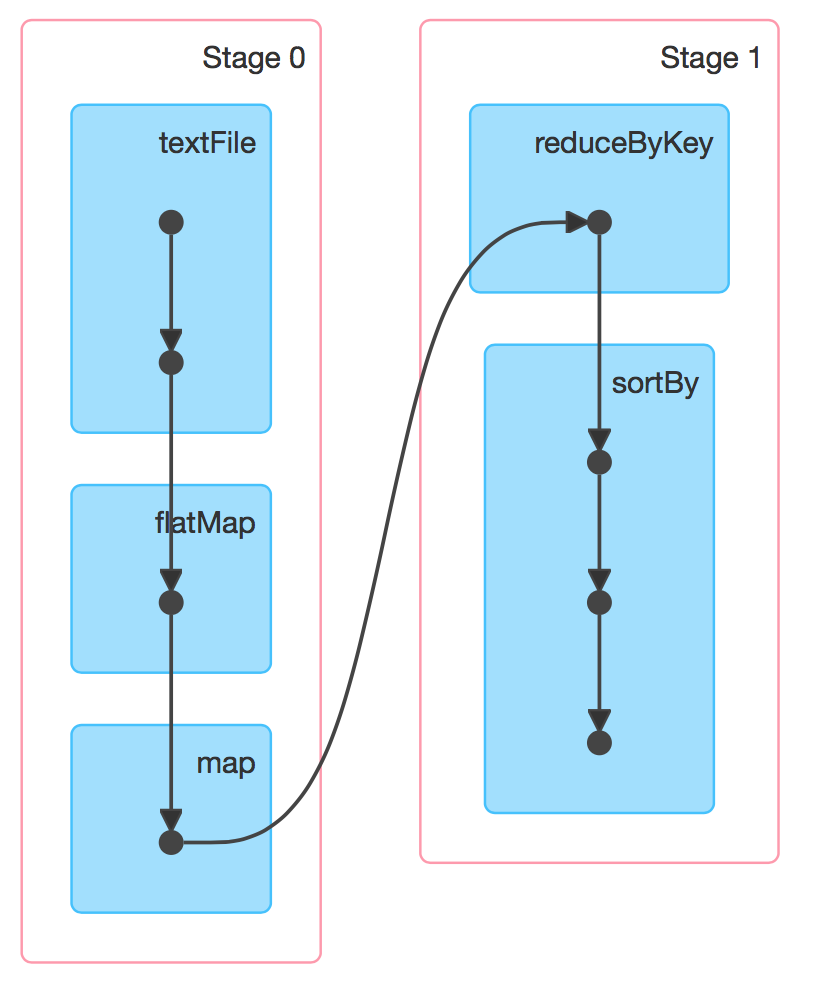
RDD(s) 及其之间的依赖关系组成了 DAG(有向无环图),DAG 定义了这些 RDD(s) 之间Lineage(血统) 关系,通过血统关系,如果一个 RDD 的部分或者全部计算结果丢失了,也可以重新进行计算。那么 Spark 是如何根据 DAG 来生成计算任务呢?主要是根据依赖关系的不同将 DAG 划分为不同的计算阶段 (Stage):
- 对于窄依赖,由于分区的依赖关系是确定的,其转换操作可以在同一个线程执行,所以可以划分到同一个执行阶段;
- 对于宽依赖,由于 Shuffle 的存在,只能在父 RDD(s) 被 Shuffle 处理完成后,才能开始接下来的计算,因此遇到宽依赖就需要重新划分阶段。
参考资料
- 张安站 . Spark 技术内幕:深入解析 Spark 内核架构设计与实现原理[M] . 机械工业出版社 . 2015-09-01
- RDD Programming Guide
- RDD:基于内存的集群计算容错抽象
1.4 RDD 常用算子详解
Transformation 和 Action 常用算子
Transformation
spark 常用的 Transformation 算子如下表:
| Transformation 算子 | Meaning(含义) |
|---|---|
| map(func) | 对原 RDD 中每个元素运用 func 函数,并生成新的 RDD |
| filter(func) | 对原 RDD 中每个元素使用func 函数进行过滤,并生成新的 RDD |
| flatMap(func) | 与 map 类似,但是每一个输入的 item 被映射成 0 个或多个输出的 items( func 返回类型需要为 Seq )。 |
| mapPartitions(func) | 与 map 类似,但函数单独在 RDD 的每个分区上运行, func函数的类型为 Iterator\ => Iterator\ ,其中 T 是 RDD 的类型,即 RDD[T] |
| mapPartitionsWithIndex(func) | 与 mapPartitions 类似,但 func 类型为 (Int, Iterator\) => Iterator\ ,其中第一个参数为分区索引 |
| sample(withReplacement, fraction, seed) | 数据采样,有三个可选参数:设置是否放回(withReplacement)、采样的百分比(fraction)、随机数生成器的种子(seed); |
| union(otherDataset) | 合并两个 RDD |
| intersection(otherDataset) | 求两个 RDD 的交集 |
| distinct([numTasks])) | 去重 |
| groupByKey([numTasks]) | 按照 key 值进行分区,即在一个 (K, V) 对的 dataset 上调用时,返回一个 (K, Iterable\) Note: 如果分组是为了在每一个 key 上执行聚合操作(例如,sum 或 average),此时使用 reduceByKey 或 aggregateByKey 性能会更好Note: 默认情况下,并行度取决于父 RDD 的分区数。可以传入 numTasks 参数进行修改。 |
| reduceByKey(func, [numTasks]) | 按照 key 值进行分组,并对分组后的数据执行归约操作。 |
| aggregateByKey(zeroValue,numPartitions)(seqOp, combOp, [numTasks]) | 当调用(K,V)对的数据集时,返回(K,U)对的数据集,其中使用给定的组合函数和 zeroValue 聚合每个键的值。与 groupByKey 类似,reduce 任务的数量可通过第二个参数进行配置。 |
| sortByKey([ascending], [numTasks]) | 按照 key 进行排序,其中的 key 需要实现 Ordered 特质,即可比较 |
| join(otherDataset, [numTasks]) | 在一个 (K, V) 和 (K, W) 类型的 dataset 上调用时,返回一个 (K, (V, W)) pairs 的 dataset,等价于内连接操作。如果想要执行外连接,可以使用 leftOuterJoin, rightOuterJoin 和 fullOuterJoin 等算子。 |
| cogroup(otherDataset, [numTasks]) | 在一个 (K, V) 对的 dataset 上调用时,返回一个 (K, (Iterable\, Iterable\)) tuples 的 dataset。 |
| cartesian(otherDataset) | 在一个 T 和 U 类型的 dataset 上调用时,返回一个 (T, U) 类型的 dataset(即笛卡尔积)。 |
| coalesce(numPartitions) | 将 RDD 中的分区数减少为 numPartitions。 |
| repartition(numPartitions) | 随机重新调整 RDD 中的数据以创建更多或更少的分区,并在它们之间进行平衡。 |
| repartitionAndSortWithinPartitions(partitioner) | 根据给定的 partitioner(分区器)对 RDD 进行重新分区,并对分区中的数据按照 key 值进行排序。这比调用 repartition 然后再 sorting(排序)效率更高,因为它可以将排序过程推送到 shuffle 操作所在的机器。 |
下面分别给出这些算子的基本使用示例:
1.1 map
val list = List(1,2,3)
sc.parallelize(list).map(_ * 10).foreach(println)
// 输出结果: 10 20 30 (这里为了节省篇幅去掉了换行,后文亦同)1.2 filter
val list = List(3, 6, 9, 10, 12, 21)
sc.parallelize(list).filter(_ >= 10).foreach(println)
// 输出: 10 12 211.3 flatMap
flatMap(func) 与 map 类似,但每一个输入的 item 会被映射成 0 个或多个输出的 items( func 返回类型需要为 Seq)。
val list = List(List(1, 2), List(3), List(), List(4, 5))
sc.parallelize(list).flatMap(_.toList).map(_ * 10).foreach(println)
// 输出结果 : 10 20 30 40 50flatMap 这个算子在日志分析中使用概率非常高,这里进行一下演示:拆分输入的每行数据为单个单词,并赋值为 1,代表出现一次,之后按照单词分组并统计其出现总次数,代码如下:
val lines = List("spark flume spark",
"hadoop flume hive")
sc.parallelize(lines).flatMap(line => line.split(" ")).
map(word=>(word,1)).reduceByKey(_+_).foreach(println)
// 输出:
(spark,2)
(hive,1)
(hadoop,1)
(flume,2)1.4 mapPartitions
与 map 类似,但函数单独在 RDD 的每个分区上运行, func函数的类型为 Iterator<T> => Iterator<U> (其中 T 是 RDD 的类型),即输入和输出都必须是可迭代类型。
val list = List(1, 2, 3, 4, 5, 6)
sc.parallelize(list, 3).mapPartitions(iterator => {
val buffer = new ListBuffer[Int]
while (iterator.hasNext) {
buffer.append(iterator.next() * 100)
}
buffer.toIterator
}).foreach(println)
//输出结果
100 200 300 400 500 6001.5 mapPartitionsWithIndex
与 mapPartitions 类似,但 func 类型为 (Int, Iterator<T>) => Iterator<U> ,其中第一个参数为分区索引。
val list = List(1, 2, 3, 4, 5, 6)
sc.parallelize(list, 3).mapPartitionsWithIndex((index, iterator) => {
val buffer = new ListBuffer[String]
while (iterator.hasNext) {
buffer.append(index + "分区:" + iterator.next() * 100)
}
buffer.toIterator
}).foreach(println)
//输出
0 分区:100
0 分区:200
1 分区:300
1 分区:400
2 分区:500
2 分区:6001.6 sample
数据采样。有三个可选参数:设置是否放回 (withReplacement)、采样的百分比 (fraction)、随机数生成器的种子 (seed) :
val list = List(1, 2, 3, 4, 5, 6)
sc.parallelize(list).sample(withReplacement = false, fraction = 0.5).foreach(println)1.7 union
合并两个 RDD:
val list1 = List(1, 2, 3)
val list2 = List(4, 5, 6)
sc.parallelize(list1).union(sc.parallelize(list2)).foreach(println)
// 输出: 1 2 3 4 5 61.8 intersection
求两个 RDD 的交集:
val list1 = List(1, 2, 3, 4, 5)
val list2 = List(4, 5, 6)
sc.parallelize(list1).intersection(sc.parallelize(list2)).foreach(println)
// 输出: 4 51.9 distinct
去重:
val list = List(1, 2, 2, 4, 4)
sc.parallelize(list).distinct().foreach(println)
// 输出: 4 1 21.10 groupByKey
按照键进行分组:
val list = List(("hadoop", 2), ("spark", 3), ("spark", 5), ("storm", 6), ("hadoop", 2))
sc.parallelize(list).groupByKey().map(x => (x._1, x._2.toList)).foreach(println)
//输出:
(spark,List(3, 5))
(hadoop,List(2, 2))
(storm,List(6))1.11 reduceByKey
按照键进行归约操作:
val list = List(("hadoop", 2), ("spark", 3), ("spark", 5), ("storm", 6), ("hadoop", 2))
sc.parallelize(list).reduceByKey(_ + _).foreach(println)
//输出
(spark,8)
(hadoop,4)
(storm,6)1.12 sortBy & sortByKey
按照键进行排序:
val list01 = List((100, "hadoop"), (90, "spark"), (120, "storm"))
sc.parallelize(list01).sortByKey(ascending = false).foreach(println)
// 输出
(120,storm)
(100,hadoop)
(90,spark)按照指定元素进行排序:val list02 = List(("hadoop",100), ("spark",90), ("storm",120))
sc.parallelize(list02).sortBy(x=>x._2,ascending=false).foreach(println)
// 输出
(storm,120)
(hadoop,100)
(spark,90)1.13 join
在一个 (K, V) 和 (K, W) 类型的 Dataset 上调用时,返回一个 (K, (V, W)) 的 Dataset,等价于内连接操作。如果想要执行外连接,可以使用 leftOuterJoin, rightOuterJoin 和 fullOuterJoin 等算子。
val list01 = List((1, "student01"), (2, "student02"), (3, "student03"))
val list02 = List((1, "teacher01"), (2, "teacher02"), (3, "teacher03"))
sc.parallelize(list01).join(sc.parallelize(list02)).foreach(println)
// 输出
(2,(student02,teacher02))
(1,(student01,teacher01))
(3,(student03,teacher03))1.14 cogroup
在一个 (K, V) 对的 Dataset 上调用时,返回多个类型为 (K, (Iterable\, Iterable\)) 的元组所组成的 Dataset。
val list01 = List((1, "a"),(1, "a"), (2, "b"), (3, "e"))
val list02 = List((1, "A"), (2, "B"), (3, "E"))
val list03 = List((1, "[ab]"), (2, "[bB]"), (3, "eE"),(3, "eE"))
sc.parallelize(list01).cogroup(sc.parallelize(list02),sc.parallelize(list03)).foreach(println)
// 输出: 同一个 RDD 中的元素先按照 key 进行分组,然后再对不同 RDD 中的元素按照 key 进行分组
(1,(CompactBuffer(a, a),CompactBuffer(A),CompactBuffer([ab])))
(3,(CompactBuffer(e),CompactBuffer(E),CompactBuffer(eE, eE)))
(2,(CompactBuffer(b),CompactBuffer(B),CompactBuffer([bB])))1.15 cartesian
计算笛卡尔积:
val list1 = List("A", "B", "C")
val list2 = List(1, 2, 3)
sc.parallelize(list1).cartesian(sc.parallelize(list2)).foreach(println)
//输出笛卡尔积
(A,1)
(A,2)
(A,3)
(B,1)
(B,2)
(B,3)
(C,1)
(C,2)
(C,3)1.16 aggregateByKey
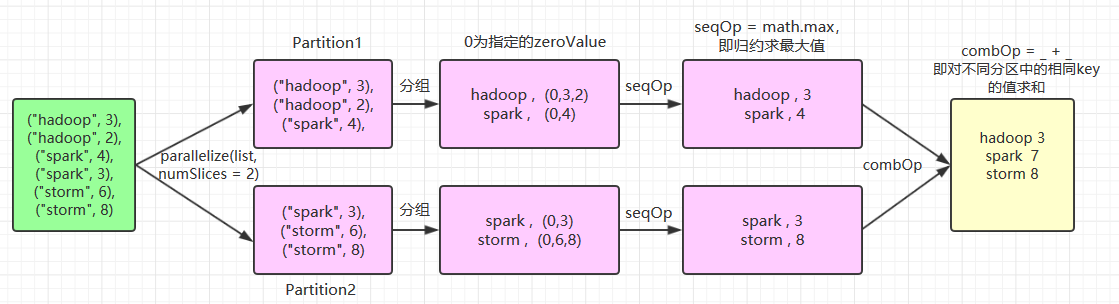
当调用(K,V)对的数据集时,返回(K,U)对的数据集,其中使用给定的组合函数和 zeroValue 聚合每个键的值。与 groupByKey 类似,reduce 任务的数量可通过第二个参数 numPartitions 进行配置。示例如下:
// 为了清晰,以下所有参数均使用具名传参
val list = List(("hadoop", 3), ("hadoop", 2), ("spark", 4), ("spark", 3), ("storm", 6), ("storm", 8))
sc.parallelize(list,numSlices = 2).aggregateByKey(zeroValue = 0,numPartitions = 3)(
seqOp = math.max(_, _),
combOp = _ + _
).collect.foreach(println)
//输出结果:
(hadoop,3)
(storm,8)
(spark,7)这里使用了 numSlices = 2 指定 aggregateByKey 父操作 parallelize 的分区数量为 2,其执行流程如下:
基于同样的执行流程,如果 numSlices = 1,则意味着只有输入一个分区,则其最后一步 combOp 相当于是无效的,执行结果为:
(hadoop,3)
(storm,8)
(spark,4)同样的,如果每个单词对一个分区,即 numSlices = 6,此时相当于求和操作,执行结果为:
(hadoop,5)
(storm,14)
(spark,7)aggregateByKey(zeroValue = 0,numPartitions = 3) 的第二个参数 numPartitions 决定的是输出 RDD 的分区数量,想要验证这个问题,可以对上面代码进行改写,使用 getNumPartitions 方法获取分区数量:
sc.parallelize(list,numSlices = 6).aggregateByKey(zeroValue = 0,numPartitions = 3)(
seqOp = math.max(_, _),
combOp = _ + _
).getNumPartitions
Action
Spark 常用的 Action 算子如下:
| Action(动作) | Meaning(含义) |
|---|---|
| reduce(func) | 使用函数func执行归约操作 |
| collect() | 以一个 array 数组的形式返回 dataset 的所有元素,适用于小结果集。 |
| count() | 返回 dataset 中元素的个数。 |
| first() | 返回 dataset 中的第一个元素,等价于 take(1)。 |
| take(n) | 将数据集中的前 n 个元素作为一个 array 数组返回。 |
| takeSample(withReplacement, num, [seed]) | 对一个 dataset 进行随机抽样 |
| takeOrdered(n, [ordering]) | 按自然顺序(natural order)或自定义比较器(custom comparator)排序后返回前 n 个元素。只适用于小结果集,因为所有数据都会被加载到驱动程序的内存中进行排序。 |
| saveAsTextFile(path) | 将 dataset 中的元素以文本文件的形式写入本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。Spark 将对每个元素调用 toString 方法,将元素转换为文本文件中的一行记录。 |
| saveAsSequenceFile(path) | 将 dataset 中的元素以 Hadoop SequenceFile 的形式写入到本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。该操作要求 RDD 中的元素需要实现 Hadoop 的 Writable 接口。对于 Scala 语言而言,它可以将 Spark 中的基本数据类型自动隐式转换为对应 Writable 类型。(目前仅支持 Java and Scala) |
| saveAsObjectFile(path) | 使用 Java 序列化后存储,可以使用 SparkContext.objectFile() 进行加载。(目前仅支持 Java and Scala) |
| countByKey() | 计算每个键出现的次数。 |
| foreach(func) | 遍历 RDD 中每个元素,并对其执行fun函数 |
2.1 reduce
使用函数func执行归约操作:
val list = List(1, 2, 3, 4, 5)
sc.parallelize(list).reduce((x, y) => x + y)
sc.parallelize(list).reduce(_ + _)
// 输出 152.2 takeOrdered
按自然顺序(natural order)或自定义比较器(custom comparator)排序后返回前 n 个元素。需要注意的是 takeOrdered 使用隐式参数进行隐式转换,以下为其源码。所以在使用自定义排序时,需要继承 Ordering[T] 实现自定义比较器,然后将其作为隐式参数引入。
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
.........
}自定义规则排序:
// 继承 Ordering[T],实现自定义比较器,按照 value 值的长度进行排序
class CustomOrdering extends Ordering[(Int, String)] {
override def compare(x: (Int, String), y: (Int, String)): Int
= if (x._2.length > y._2.length) 1 else -1
}
val list = List((1, "hadoop"), (1, "storm"), (1, "azkaban"), (1, "hive"))
// 引入隐式默认值
implicit val implicitOrdering = new CustomOrdering
sc.parallelize(list).takeOrdered(5)
// 输出: Array((1,hive), (1,storm), (1,hadoop), (1,azkaban)2.3 countByKey
计算每个键出现的次数:
val list = List(("hadoop", 10), ("hadoop", 10), ("storm", 3), ("storm", 3), ("azkaban", 1))
sc.parallelize(list).countByKey()
// 输出: Map(hadoop -> 2, storm -> 2, azkaban -> 1)2.4 saveAsTextFile
将 dataset 中的元素以文本文件的形式写入本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。Spark 将对每个元素调用 toString 方法,将元素转换为文本文件中的一行记录。
val list = List(("hadoop", 10), ("hadoop", 10), ("storm", 3), ("storm", 3), ("azkaban", 1))
sc.parallelize(list).saveAsTextFile("/usr/file/temp")














 3214
3214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











