







本系列文章内容全部来自尚硅谷教学视频,仅作为个人的学习笔记
Spark只是一个数据处理框架和计算引擎,它必须要在一个特定的环境中才能运行。常用的运行环境有如下三种
一、开发环境
当我们在idea中开发时,只需要在maven中引入spark的相关依赖,就可以编写运行调试spark代码了
如下,在Maven项目中引入Spark3.0的spark-core依赖,2.12对应的Scala版本
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
二、本地环境(Local模式)
Local模式是指不需要任何其它节点资源就可以在本地执行Spark代码的环境,不需要额外的进程进行资源管理,所有程序都运行在本地的一个进程环境中(如jvm),使用多线程来模拟集群,一般用于教学,调试,演示等。在 IDEA 中运行代码的环境我们称之为开发环境,不太一样。
如果要在本地终端中运行spark项目,则需在本地机器中下载Spark 下载地址
例如下载spark-3.1.3-bin-hadoop3.2.tgz(表示的是基于3.2版本的Hadoop编译的spark,如果要用到Hadoop的组件的话则需安装3.2版本的Hadoop)
下载spark然后解压到任意位置,将其bin目录配置到环境变量,然后在终端中使用spark-shell命令即可启动local环境,或者直接使用spark-submit提交运行spark项目的jar包
spark-submit --master local[*] testSpark-1.0-SNAPSHOT.jar

三、集群环境
Local模式是在本地使用多线程模拟集群的环境,我们实际运行spark项目时通常都是在真实的集群环境中运行。
首先要准备一个服务器集群,并确保集群节点之间能够互相免密登录,每个节点上都安装了jdk
1. 部署Standalone模式
Standalone模式是Spark自带的一种集群模式,使用了分布式计算中的master-slave模型对集群资源进行管理和调度
master是集群中含有Master进程的节点
slave是集群中含有Executor进程的Worker节点
主节点Master:管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
从节点Worker:管理每个机器的资源,分配对应的资源来运行Task;
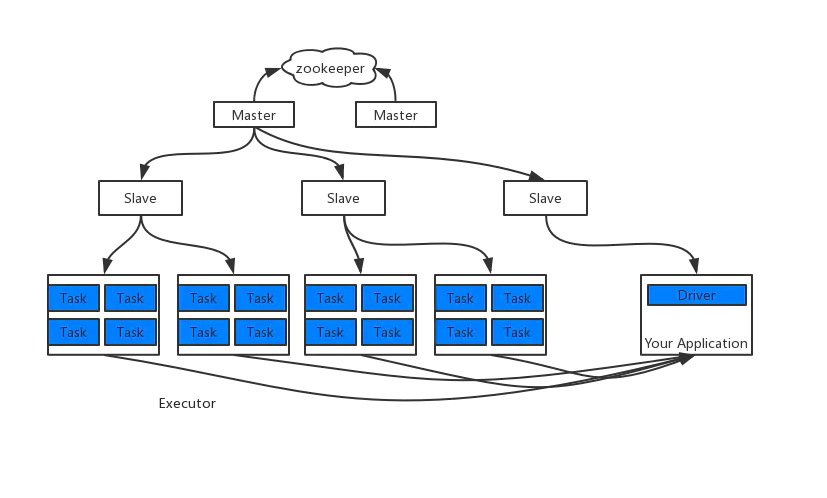
将spark-3.1.3-bin-hadoop3.2.tgz解压到一个节点,先在此节点上完成如下配置
设置master节点:
进入spark的conf 目录,修改 spark-env.sh.template 文件名为 spark-env.sh
mv spark-env.sh.template spark-env.sh
修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=linux1
SPARK_MASTER_PORT=7077
设置worker节点:
在conf目录中修改 slaves.template 文件名为 slaves
mv slaves.template slaves
修改 slaves 文件,添加 work 节点(linuxi为hosts文件中配置的集群中每个节点ip的映射名称)
linux1
linux2
linux3
最后将spark文件夹分发到每个集群节点的相同位置(使用scp或rsync命令)。这样就完成了spark的集群部署
启动集群:在集群任意节点的spark的sbin目录下执行脚本命令start-all.sh就能直接启动所有节点的spark,然后就可以使用bin目录下的spark-submit命令提交任务到集群运行了
配置高可用(HA)
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper 设置
2. 部署Yarn模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,并且Spark通常要依赖外部的分布式文件系统作为数据源,比如Hadoop系统的HDFS。所以Spark还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的 Yarn 环境下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
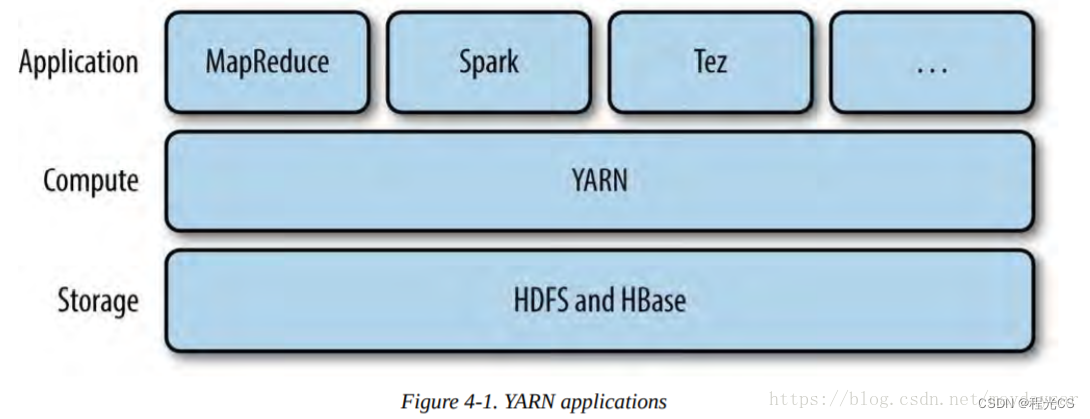
HDFS和Yarn都是Hadoop中的组件,因此我们还需要在集群中安装对应3.2版本的Hadoop 下载地址
(1)配置hadoop
假设有hadoop102,hadoop103,hadoop104三台机器构成的集群,要按照如下规划进行部署

先将hadoop-3.2.4.tar.gz解压到一个节点,先在此节点上完成如下配置。在hadoop安装目录下的etc/hadoop目录下修改core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml,workers
核心配置文件core-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定HDFS的NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.2.4/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
</configuration>
HDFS 配置文件hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- HDFS的namenode数据存储地址-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/dfs/name</value>
</property>
<!-- HDFS的datanode数据存储地址-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/dfs/data</value>
</property>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
YARN 配置文件yarn-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 环境变量的继承 3.1以上版本不需要配置-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
根据集群情况调优yarn可使用资源
<!-- 单个container可申请的最多物理内存量,默认是8192(MB)
对于spark一个executor就是一个container-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>10240</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>30</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>3</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>6</value>
</property>
<!-- 每个yarn node节点可使用内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>57344</value>
</property>
<!-- 单个container最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>57344</value>
</property>
yarn配置调优参考:
- yarn-site.xml 基本配置参考
- https://hadoop.apache.org/docs/r2.7.3/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
MapReduce 配置文件mapred-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
集群节点配置文件workers:
hadoop102
hadoop103
hadoop104
hadoop环境变量文件hadoop_env.sh
指定hadoop用户,我这里是root,在hadoop_env.sh中添加:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
上述六个文件配置完成后将hadoop安装文件夹分发到集群每个节点的相同位置。这样就完成了hadoop的集群部署
启动yarn集群:
如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode
hdfs namenode -format
然后启动 HDFS。(若报错找不到JAVA_HOME,参考:解决)
sbin/start-dfs.sh
最后在在配置了 ResourceManager 的节点(hadoop103)启动 YARN
sbin/start-yarn.sh
(2)配置spark
将spark-3.1.3-bin-hadoop3.2.tgz解压到一个节点,先在此节点上完成如下配置
修改 conf/spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
将spark文件夹分发到每个集群节点的相同位置
就可以直接将任务提交到yarn集群上去运行了
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar
(3) 配置命令的环境变量
配置命令的环境变量使得在任意路径下都可以直接使用hadoop或spark的命令。
在/etc/profile中配置对所有用户生效,在~/.bashrc中配置只对当前用户生效,根据自己的需要添加配置
export HADOOP_HOME=/home/syc/hadoop-3.2.2
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export SPARK_HOME=/home/syc/spark-3.2.3-bin-hadoop3.2
export SPARK_CONF_DI=$SPARK_HOME/conf
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:$PYTHONPATH
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$SPARK_HOME/python:$PATH
参考资料:
1.What is the difference between Spark Standalone, YARN and local mode?














 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









