






24届互联网秋招差不多结束了,从背八股文、刷算法题、准备项目,到暑期实习,最后到秋招,经历了几十场面试,拿到了五六个offer,也终于签约了比较满意的offer,本人的秋招之旅也算圆满结束。
下面分享我在面试过程中遇到的一些场景题
Github地址
1.定时任务调度器
因为我简历上的项目是分布式定时任务管理平台Crony ,所以很多面试官(百度、滴滴、小红书、美团等)都会问我如何去实现一个定时任务调度器
请实现一个定时任务调度器,有很多任务,每个任务都有一个时间戳,任务会在该时间点开始执行。 定时执行任务是一个很常见的需求,例如订单未支付超时取消等。简单来说只需要实现一个有序结构(优先队列、跳表、红黑树、堆等)+轮询
方案1: PriorityBlockingQueue + Polling (轮询)
我们很快可以想到第一个办法:
用一个java.util.concurrent.PriorityBlockingQueue来作为优先队列。因为我们需要一个优先队列,又需要线程安全,用PriorityBlockingQueue再合适不过了。你也可以手工实现一个自己的PriorityBlockingQueue,用java.util.PriorityQueue + ReentrantLock,用一把锁把这个队列保护起来,就是线程安全的啦
对于生产者,可以用一个while(true),造一些随机任务塞进去 对于消费者,起一个线程,在 while(true)里每隔几秒检查一下队列,如果有任务,则取出来执行。
这个方案的确可行,总结起来就是轮询(polling)。轮询通常有个很大的缺点,就是时间间隔不好设置,间隔太长,任务无法及时处理,间隔太短,会很耗CPU。
方案2: PriorityBlockingQueue + 时间差
可以把方案1改进一下,while(true)里的逻辑变成: 偷看一下堆顶的元素,但并不取出来,如果该任务过期了,则取出来 如果没过期,则计算一下时间差,然后 sleep()该时间差 不再是 sleep() 一个固定间隔了,消除了轮询的缺点。 稍等!这个方案其实有个致命的缺陷,导致它比 PiorityBlockingQueue + Polling 更加不可用,这个缺点是什么呢?。。。
假设当前堆顶的任务在100秒后执行,消费者线程peek()偷看到了后,开始sleep 100秒,这时候一个新的任务插了进来,该任务在10秒后应该执行,但是由于消费者线程要睡眠100秒,这个新任务无法及时处理
方案3:Go语言time包下的定时器实现方案
golang使用最小堆(最小堆是满足除了根节点以外的每个节点都不小于其父节点的堆、四叉小顶堆)实现的定时器。golang []*****timer结构如下:
golang存储定时任务结构
addtimer在堆中插入一个值,然后保持最小堆的特性,其实这个结构本质就是最小优先队列的一个应用,然后将时间转换一个绝对时间处理,通过睡眠和唤醒找出定时任务
当我们通过 NewTimer、NewTicker 等方法创建定时器时,返回的是一个 Timer 对象。这个对象里有一个 runtimeTimer 字段的结构体,它在最后会被编译成 src/runtime/time.go 里的 timer 结构体。
而这个 timer 结构体就是真正有着定时处理逻辑的结构体。
一开始,timer 会被分配到一个全局的 timersBucket 时间桶。每当有 timer 被创建出来时,就会被分配到对应的时间桶里了。
为了不让所有的 timer 都集中到一个时间桶里,Go 会创建 64 个这样的时间桶,然后根据 当前 timer 所在的 Goroutine 的 P 的 id 去哈希到某个桶上:
// assignBucket 将创建好的 timer 关联到某个桶上
func (t *timer) assignBucket() *timersBucket {
id := uint8(getg().m.p.ptr().id) % timersLen
t.tb = &timers[id].timersBucket
return t.tb
}
接着 timersBucket 时间桶将会对这些 timer 进行一个最小堆的维护,每次会挑选出时间最快要达到的 timer。
如果挑选出来的 timer 时间还没到,那就会进行 sleep 休眠。
如果 timer 的时间到了,则执行 timer 上的函数,并且往 timer 的 channel 字段发送数据,以此来通知 timer 所在的 goroutine。
如果timer的时间还不到,但此时又添加另一个timer,此时会重新唤醒线程
方案4: 时间轮(HashedWheelTimer)
时间轮(HashedWheelTimer)其实很简单,就是一个循环队列,如下图所示,
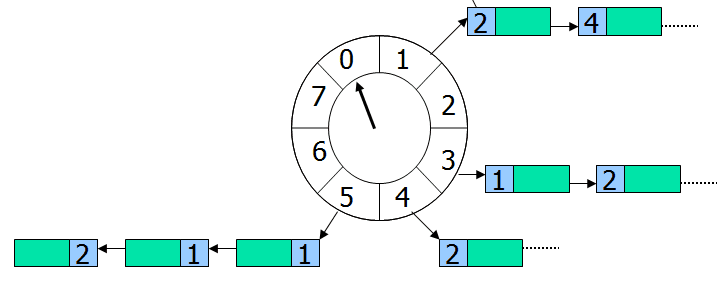
上图是一个长度为8的循环队列,假设该时间轮精度为秒,即每秒走一格,像手表那样,走完一圈就是8秒。每个格子指向一个任务集合,时间轮无限循环,每转到一个格子,就扫描该格子下面的所有任务,把时间到期的任务取出来执行。
举个例子,假设指针当前正指向格子0,来了一个任务需要4秒后执行,那么这个任务就会放在格子s4下面,如果来了一个任务需要20秒后执行怎么?由于这个循环队列转一圈只需要8秒,这个任务需要多转2圈,所以这个任务的位置虽然依旧在格子4(20%8+0=4)下面,不过需要多转2圈后才执行。因此每个任务需要有一个字段记录需圈数,每转一圈就减1,减到0则立刻取出来执行。 怎么实现时间轮呢?Netty中已经有了一个时间轮的实现, HashedWheelTimer.java,可以参考它的源代码。 时间轮的优点是性能高,插入和删除的时间复杂度都是O(1)。
Linux 内核中的定时器采用的就是这个方案。
Follow up: 如何设计一个分布式的定时任务调度器呢? 答: Redis ZSet, RabbitMQ等
2.有一个10G大小的文件,里面每一行是一个unsigned int的整数(类似于qq号),然后再给一个数,如何快速判断这个数是否在文件当中?加问:如何快速查找出现次数大于等于2的整数?
oppo二面
方法一:分治+HashMap
用Hash映射将文件里的整数映射到多个小文件中,对于每一次query,先Hash映射到对应的小文件,然后遍历一遍小文件,查看这个数是否在文件中。
那么如何快速查找出现次数大于等于2的整数呢,这时候只需要使用HashMap统计每个小文件里大于等于2的整数,最后汇总即可
方法二:位图法
如果对布隆过滤器有了解的同学一定记得位图是什么,布隆过滤器在面试中也是经常问到的,下面简单说一下什么是位图?
简单来说,位图就是,用每一位来存放某种状态,通常是用来判断某个数据存不存在的。位图可以用数组实现的,数组的每一个元素的每一个二进制位都可以表示一个数据在或者不在,0表示数据存在,1表示数据不存在。如下,表示0-6中的元素,0-6中只有7个数,所以用7bit足以表示,例如5可以表示为
[0,0,0,0,0,1,0]
那为什么要使用位图,使用位图有什么好处呢?
使用位图可以大大缩短存储空间,一个int占用4byte,1byte=8bit,也就说本来4byte只能存1个整数,而现在4type可以存32个整数。
回到本题,要找出不重复的整数,那么一个整数可以有三种状态,即不存在、存在1次、存在多次,根据题目需要找出的是存在多次的
对于三种状态只用0或1肯定是表示不了的,所以可以用两位来表示整数的状态,00表示不存在,01表示存在1次,10表示存在多次。
具体做法,首先遍历大文件,查看对应位图中对应的位,如果是 00,则变为 01,如果是 01 则变为 10,如果是 10 则保持不变。最后遍历位图,找出01对应的整数,即为大文件中出现多次的整数
3.Top k频繁项
深信服二面
寻找数据流(或者大文件)中出现最频繁的k个元素(find top k frequent items in a data stream)。这个问题也称为 Heavy Hitters. 这题也是从实践中提炼而来的,例如搜索引擎的热搜榜,找出访问网站次数最多的前10个IP地址,等等。
方案1: HashMap + Heap
用一个 HashMap,存放所有元素出现的次数,用一个小根堆,容量为k,存放目前出现过的最频繁的k个元素,
- 每次从数据流来一个元素,如果在HashMap里已存在,则把对应的计数器增1,如果不存在,则插入,计数器初始化为1
- 在堆里查找该元素,如果找到,把堆里的计数器也增1,并调整堆;如果没有找到,把这个元素的次数跟堆顶元素比较,如果大于堆丁元素的出现次数,则把堆丁元素替换为该元素,并调整堆
- 空间复杂度O(n)。HashMap需要存放下所有元素,需要O(n)的空间,堆需要存放k个元素,需要O(k)的空间,跟O(n)相比可以忽略不计,总的时间复杂度是O(n) 时间复杂度O(n)。每次来一个新元素,需要在HashMap里查找一下,需要O(1)的时间;然后要在堆里查找一下,O(k)的时间,有可能需要调堆,又需要O(logk)的时间,总的时间复杂度是O(n(k+logk)),k是常量,所以可以看做是O(n)。
如果元素数量巨大,单机内存存不下,怎么办? 有两个办法,见方案2和3。
方案2: 多机HashMap + Heap
- 可以把数据进行分片。假设有8台机器,第1台机器只处理hash(elem)%80的元素,第2台机器只处理hash(elem)%81的元素,以此类推。
- 每台机器都有一个HashMap和一个 Heap, 各自独立计算出 top k 的元素
- 把每台机器的Heap,通过网络汇总到一台机器上,将多个Heap合并成一个Heap,就可以计算出总的 top k 个元素了
4.分布式ID生成器
小红书、百度提前批、tplink
因为我简历上有个IM即时通讯的项目,关于聊天消息ID的生成一般面试官都会问
如何设计一个分布式ID生成器(Distributed ID Generator),并保证ID按时间粗略有序? 应用场景(Scenario) 现实中很多业务都有生成唯一ID的需求,例如: 用户ID、微博ID、聊天消息ID、帖子ID 、订单ID需求等
这个ID往往会作为数据库主键,所以需要保证全局唯一。数据库会在这个字段上建立聚集索引(Clustered Index,参考 MySQL InnoDB),即该字段会影响各条数据再物理存储上的顺序。 ID还要尽可能短,节省内存,让数据库索引效率更高。基本上64位整数能够满足绝大多数的场景,但是如果能做到比64位更短那就更好了。需要根据具体业务进行分析,预估出ID的最大值,这个最大值通常比64位整数的上限小很多,于是我们可以用更少的bit表示这个ID。
查询的时候,往往有分页或者排序的需求,所以需要给每条数据添加一个时间字段,并在其上建立普通索引(Secondary Index)。但是普通索引的访问效率比聚集索引慢,如果能够让ID按照时间粗略有序,则可以省去这个时间字段。为什么不是按照时间精确有序呢?因为按照时间精确有序是做不到的,除非用一个单机算法,在分布式场景下做到精确有序性能一般很差。
这就引出了ID生成的三大核心需求:
-
全局唯一(unique)
-
按照时间粗略有序(sortable by time)
-
尽可能短
下面介绍一些常用的生成ID的方法。
UUID
用过MongoDB的人会知道,MongoDB会自动给每一条数据赋予一个唯一的ObjectId,保证不会重复,这是怎么做到的呢?实际上它用的是一种UUID算法,生成的ObjectId占12个字节,由以下几个部分组成,
4个字节表示的Unix timestamp,
3个字节表示的机器的ID
2个字节表示的进程ID
3个字节表示的计数器
UUID是一类算法的统称,具体有不同的实现。UUID的优点是每台机器可以独立产生ID,理论上保证不会重复,所以天然是分布式的,缺点是生成的ID太长,不仅占用内存,而且索引查询效率低。
多台MySQL服务器
既然MySQL可以产生自增ID,那么用多台MySQL服务器,能否组成一个高性能的分布式发号器呢? 显然可以。
假设用8台MySQL服务器协同工作,第一台MySQL初始值是1,每次自增8,第二台MySQL初始值是2,每次自增8,依次类推。前面用一个 round-robin load balancer 挡着,每来一个请求,由 round-robin balancer 随机地将请求发给8台MySQL中的任意一个,然后返回一个ID。
Flickr就是这么做的,仅仅使用了两台MySQL服务器。可见这个方法虽然简单无脑,但是性能足够好。不过要注意,在MySQL中,不需要把所有ID都存下来,每台机器只需要存一个MAX_ID就可以了。这需要用到MySQL的一个REPLACE INTO特性。
这个方法跟单台数据库比,缺点是ID是不是严格递增的,只是粗略递增的。不过这个问题不大,我们的目标是粗略有序,不需要严格递增。
Twitter Snowflake
比如 Twitter 有个成熟的开源项目,就是专门生成ID的,Twitter Snowflake 。Snowflake的核心算法如下
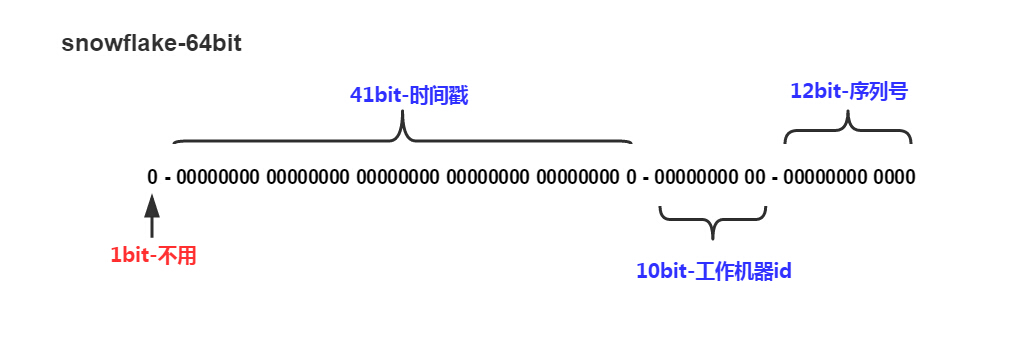
最高位不用,永远为0,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。
Instagram用了类似的方案,41位表示时间戳,13位表示shard Id(一个shard Id对应一台PostgreSQL机器),最低10位表示自增ID,怎么样,跟Snowflake的设计非常类似吧。这个方案用一个PostgreSQL集群代替了Twitter Snowflake 集群,优点是利用了现成的PostgreSQL,容易懂,维护方便。
IM即时通讯消息序列号ID的生成
微信、美团的IM都是采用这个方法(预分配中间层)生成的,我做的IM项目也是借鉴这个方法实现的
微信技术分享:微信的海量IM聊天消息序列号生成实践(算法原理篇) - 腾讯云开发者社区-腾讯云 (tencent.com)
1)内存中储存最近一个分配出去的sequence:cur_seq,以及分配上限:max_seq;
2)分配sequence时,将cur_seq++,同时与分配上限max_seq比较:如果cur_seq > max_seq,将分配上限提升一个步长max_seq += step,并持久化max_seq;
3)重启时,读出持久化的max_seq,赋值给cur_seq。
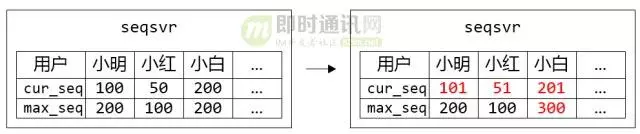
▲ 图2:小明、小红、小白都各自申请了一个sequence,但只有小白的max_seq增加了步长100
这样通过增加一个预分配 sequence 的中间层,在保证 sequence 不回退的前提下,大幅地提升了分配 sequence 的性能。实际应用中每次提升的步长为10000,那么持久化的硬盘IO次数从之前~10^7 QPS降低到~10^3 QPS,处于可接受范围。在正常运作时分配出去的sequence是顺序递增的,只有在机器重启后,第一次分配的 sequence 会产生一个比较大的跳跃,跳跃大小取决于步长大小。
理论上步长越长,性能越好
优化:分号段共享存储
当然,当用户量非常大的时候,每次重启加载最大序列号的磁盘IO也非常大,花费大量时间数据传输,造成一段时间服务不可用
请求带来的硬盘IO问题解决了,可以支持服务平稳运行,但该模型还是存在一个问题:重启时要读取大量的max_seq数据加载到内存中。
我们可以简单计算下,以目前 uid(用户唯一ID)上限2^32个、一个 max_seq 8bytes 的空间,数据大小一共为32GB,从硬盘加载需要不少时间。另一方面,出于数据可靠性的考虑,必然需要一个可靠存储系统来保存max_seq数据,重启时通过网络从该可靠存储系统加载数据。如果max_seq数据过大的话,会导致重启时在数据传输花费大量时间,造成一段时间不可服务。
为了解决这个问题,我们引入号段 Section 的概念,uid 相邻的一段用户属于一个号段,而同个号段内的用户共享一个 max_seq,这样大幅减少了max_seq 数据的大小,同时也降低了IO次数。
有的面试官会问,如何让ID可以粗略的按照时间排序?上面的这种格式的ID,含有时间戳,且在高位,恰好满足要求。如果面试官又问,如何保证ID严格有序呢?在分布式这个场景下,是做不到的,要想高性能,只能做到粗略有序,无法保证严格有序。
5.设计一个订单超时未支付关闭订单的解决方案
字节二面
注意订单超时并不仅仅只是关闭订单,还需要减库存、通知等一些列操作
方法一:扫表轮询
此方案比较简单,我们只需要开一个定时任务扫描订单表,获取待支付状态的订单数据,判断订单是否超时,如果超时则关闭订单并进行减库存等操作。

缺点:
- 大量数据集,对服务器内存消耗大。
- 数据库频繁查询,订单量大的情况下,IO是瓶颈。
- 存在延迟,间隔短则耗资源,间隔长则时效性差,两者是一对矛盾。
- 不易控制,随着定时业务的增多和细化,每个业务都要对订单重复扫描,引发查询浪费
方法二:懒删除
我们只在用户查询订单的时候进行一个订单的校验,判断是否超时

缺点:
如果用户一直不查询订单,那么订单会被一直挂起,没有支付也没有取消,库存依旧占着。如果再业务上这种延迟操作不能接收,那么此方案也用不了
方法三:消息队列
通过消息队列中的延迟队列实现

优点:
- 可以随时在队列移除,实现实时取消订单,及时恢复订单占用的资源(如商品)
- 消息存储在mq中,不占用应用服务器资源
- 异步化处理,一旦处理能力不足,consumer集群可以很方便的扩容
缺点:
- 可能会导致消息大量堆积
- mq服务器一旦故障重启后,持久化的队列过期时间会被重新计算,造成精度不足
- 死信消息可能会导致监控系统频繁预警
方法四:Redis实现
利用redis的notify-keyspace-events,该选项默认为空,改为Ex开启过期事件,配置消息监听。每下一单在redis中放置一个key(如订单id),并设置过期时间

优点:
- 消息都存储在Redis中,不占用应用内存
- 外部redis存储,应用down机不会丢失数据
- 做集群扩展相当方便
- 依赖redis超时,时间准确度高
缺点:
- 订单量大时,每一单都要存储redis内存,需要大量redis服务器资源
6.一共有N颗石头,每次最多取3颗最少取1颗,甲,乙轮流取(甲先),谁最后拿完石头谁就获胜,请问最后谁会获胜?
滴滴提前批三面,只不过面试官把石头换成五子棋,从每次只能取1颗类比到每次最多取1到3颗,最后拿完石头谁就获胜,问最后谁会获胜
- 假设3>=N,那么甲一次就把石子拿完了,甲胜
- 假设3<N,如果N可以被4整除时,甲失败,如果N不可以被4整除时,甲胜
具体分析:
如果N可以被4整除时,无论甲怎么拿,乙都会保持拿完后石子的数量为4的倍数,到最后只剩4个,甲无论怎么拿,乙都会在下一次把石子拿完。
如果N不可以被4整除时,甲可以保证自己拿完剩下的石子数量一定是4的倍数,同理,甲胜。

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









